Trong các bài viết trước là Giới thiệu về GraphQL và Tìm hiểu về GraphQL – Phần 2, mình đã giới thiệu về GraphQL, ưu nhược điểm cũng như cách triển khai một ứng dụng với GraphQL. Đúng như những gì đã giới thiệu, GraphQL được ra đời để giải quyết những gì mà Restful API còn thiếu cũng như chưa đáp ứng được. Nhìn chung thì có thể đánh giá rằng, so với Restful API thì nó tốt hơn rất nhiều. Tuy nhiên, đã bao giờ chúng ta thắc mắc là GraphQL nó sẽ có những điểm bất lợi gì chưa và performance của nó có thực sự tốt hơn GraphQL như những gì nó đã giới thiệu không. Thật ra thì rất khó để đánh giá được cụ thể performance của nó so với Restfull API vì mỗi ứng dụng có một độ phức tạp khác nhau. Thường sử dụng GraphQL thì có thể giúp chúng ta hạn chế việc phải xây dựng nhiều API để trả về nhiều loại dữ liệu cần thiết cho Client hoặc một số ứng dụng có mạng lưới dữ liệu phức tạp mà Restful API khó có thể đáp ứng được tốt. Vì vậy để nhận ra được vấn đề sẽ gặp phải và chắc chắn gặp phải trong quá trình làm việc với GraphQL thì hãy theo dõi bài viết của mình dưới đây nhé.
Để dễ hiểu hơn thì mình sẽ đưa ra một ví dụ đơn giản với GraphQL nhé. Mình sẽ xây dựng một chức năng lấy ra danh sách tất cả các quyển sách và thông tin tác giả của chúng và trả về cho Client bằng GraphQL nhé. Để hoàn thành các chức năng này thì mình sẽ làm các bước như sau. Phần xây dựng base code và setting project mình sẽ không nói chi tiết ở bài viết này vì mỗi dự án sử dụng các công nghệ cũng như cấu trúc khác nhau nên mình sẽ chỉ tập trung vào đưa ra ví dụ vào giải quyết vấn đề trong GraphQL nhé.
Đầu tiên mình sẽ sử dụng Postgresql để tạo ra 2 bảng là book và author. Vì nhiều quyển sách có thể có chung một tác giả nên mình sẽ thiết kế cơ sở dữ liệu theo cấu trúc như sau:
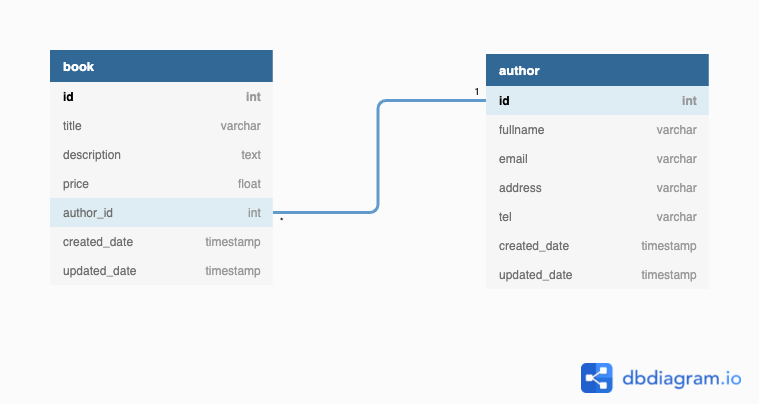
Sau khi thiết kế và setting database mình init data cho 2 bảng để có thông tin tác giả và các cuốn sách như sau:
Dữ liệu trong bảng book:
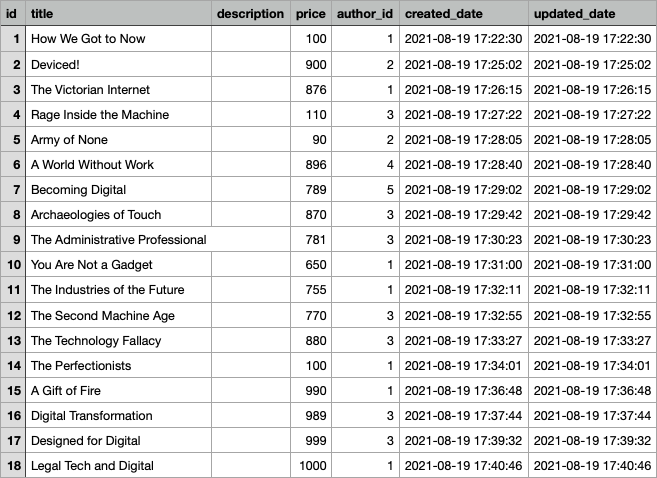
Dữ liệu trong bảng author:
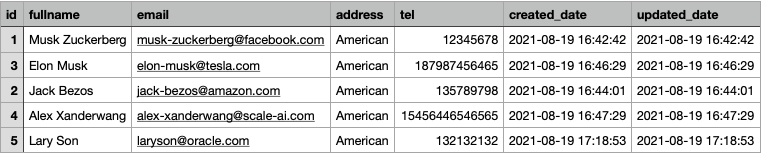
Như bạn đã thấy nhiều quyển sách sẽ có chung một tác giả. Bây giờ mình sẽ xây dựng query GraphQL để lấy thông tin list book và author của nó nhé. Trong bài viết trước mình đã hướng dẫn và giới thiệu về các khái niệm trong GraphQL cũng như cách xây dựng chúng nên ví dụ dưới đây mình sẽ không giải thích chi tiết nữa để tránh dài dòng. Các bạn có thể xem 2 bài viết trước nếu chưa tìm hiểu nhiều về GraphQL nhé.
Bây giờ mình sẽ thực hiện define entity và repository cho author và book:
//Author.kt@EntitydataclassAuthor(@Id@GeneratedValue(strategy = GenerationType.IDENTITY)@Column(nullable =false)var id: Int,@Column(name ="fullname", nullable =false)var fullname: String,@Column(name ="email", nullable =false, unique =true)var email: String,@Column(name ="address", nullable =false)var address: String,@Column(name ="author_id", nullable =false)var authorId: String,@Column(name ="created_date", nullable =false)var createdDate: LocalDateTime,@Column(name ="updated_date", nullable =false)var updatedDate: LocalDateTime,): Serializable
//AuthorRepository.kt@Repositoryinterface AuthorRepository : JpaRepository<Author, Int>{}//Book.kt@EntitydataclassBook(@Id@GeneratedValue(strategy = GenerationType.IDENTITY)@Column(nullable =false)var id: Int,@Column(nullable =false)var title: String,@Column(name ="description")var description: String?=null,@Column(name ="price", nullable =false)var price: Double =0.0,@Column(name ="author_id", nullable =false)var authorId: Int,@Column(name ="created_date", nullable =false)var createdDate: LocalDateTime,@Column(name ="updated_date", nullable =false)var updatedDate: LocalDateTime,): Serializable
//BookRepository.kt@Repositoryinterface BookRepository : JpaRepository<Book, Int>{}Sau khi khai báo đầy đủ entity và repository thì mình sẽ tiếp tục thiết kế schema và query để Client và Server có thể giao tiếp được với nhau bằng ngôn ngữ GraphQL nhé. Mình sẽ tạo ra 2 file graphql để khai báo schema type cho author và book:
#author.graphqlstypeAuthor{id:ID!,fullname:String!,email:Email!,address:String!,tel:StringcreatedDate:DateTime,updatedDate:DateTime}#book.graphqlstypeBook{id:ID!,title:String!,description:String,price:Float!,author:Author!,createdDate:DateTime,updatedDate:DateTime}extendtypeQuery{findAllBook:Book}Như schema trên có thể thấy với type là Book thì mình đã định nghĩa luôn trả về thông tin của tác giả và query findAllBook để trả về danh sách tất cả các quyển sách. Tiếp theo mình sẽ xây dựng resolver tương ứng với findAllBook mà mình đã định nghĩa trong file graphqls nhé. Đầu tiên mình cần tạo ra một file service để chuyên xử lý các logic nghiệp vụ cũng như gọi đến repository để truy vấn data trong cơ sở dữ liệu nhé. Mình sẽ định nghĩa một BookService và tại đây sẽ gọi đến BookRepository cũng như AuthorRepository để truy vấn dữ liệu nhé:
//BookService.kt@ServiceclassBookService(privateval bookRepository: BookRepository,privateval authorRepository: AuthorRepository){funfindAllBookWithAuthor(): List<Book>{val books = bookRepository.findAll()return books.map{println(it.authorId)val author = authorRepository.findById(it.authorId!!).get()Book(
it.id,
it.title,
it.description,
it.price,Author(
author.id,
author.fullname,
author.email,
author.address,
author.tel,
author.createdDate,
author.updatedDate
),
it.createdDate,
it.updatedDate
)}}}Tiếp theo chúng ta cần định nghĩa một Resolver để xử lý logic và trả về dữ liệu cho Client:
//BookResolver.kt@ComponentclassBookResolver(privateval bookService: BookService): GraphQLQueryResolver {funfindAllBook(): List<Book>= bookService.findAllBookWithAuthor()}Bây giờ mình sẽ thực hiện viết query để lấy được dữ liệu của book và author như sau:
query FIND_ALL_BOOK {
findAllBook {
id,
title,
description,
price,
author {
id,
fullname,
email,
address,
tel
}
}
}
Sau đó server sẽ trả về cho mình dữ liệu bao gồm book và author như dưới đây:
{
"data": {
"findAllBook": [
{
"id": "1",
"title": "How We Got to Now",
"description": null,
"price": 100.0,
"author": {
"id": "1",
"fullname": "Musk Zuckerberg",
"email": "[email protected]",
"address": "American",
"tel": "12345678"
}
},
{
"id": "2",
"title": "Deviced!",
"description": null,
"price": 900.0,
"author": {
"id": "2",
"fullname": "Jack Bezos",
"email": "[email protected]",
"address": "American",
"tel": "135789798"
}
},
{
"id": "3",
"title": "The Victorian Internet",
"description": "",
"price": 876.0,
"author": {
"id": "1",
"fullname": "Musk Zuckerberg",
"email": "[email protected]",
"address": "American",
"tel": "12345678"
}
},
{
"id": "4",
"title": "Rage Inside the Machine",
"description": null,
"price": 110.0,
"author": {
"id": "3",
"fullname": "Elon Musk",
"email": "[email protected]",
"address": "American",
"tel": "187987456465"
}
},
{
"id": "5",
"title": "Army of None",
"description": null,
"price": 90.0,
"author": {
"id": "2",
"fullname": "Jack Bezos",
"email": "[email protected]",
"address": "American",
"tel": "135789798"
}
},
{
"id": "6",
"title": "A World Without Work",
"description": null,
"price": 896.0,
"author": {
"id": "4",
"fullname": "Alex Xanderwang",
"email": "[email protected]",
"address": "American",
"tel": "15456446546565"
}
},
....
{
"id": "15",
"title": "A Gift of Fire",
"description": null,
"price": 990.0,
"author": {
"id": "1",
"fullname": "Musk Zuckerberg",
"email": "[email protected]",
"address": "American",
"tel": "12345678"
}
},
{
"id": "16",
"title": "Digital Transformation",
"description": null,
"price": 989.0,
"author": {
"id": "3",
"fullname": "Elon Musk",
"email": "[email protected]",
"address": "American",
"tel": "187987456465"
}
},
{
"id": "17",
"title": "Designed for Digital",
"description": null,
"price": 999.0,
"author": {
"id": "3",
"fullname": "Elon Musk",
"email": "[email protected]",
"address": "American",
"tel": "187987456465"
}
},
{
"id": "18",
"title": "Legal Tech and Digital",
"description": null,
"price": 1000.0,
"author": {
"id": "1",
"fullname": "Musk Zuckerberg",
"email": "[email protected]",
"address": "American",
"tel": "12345678"
}
}
]
}
}
Nếu để ý dữ liệu trả về và logic truy vấn trong function findAllBookWithAuthor của BookService thì bạn có thể thấy rất nhiều cuốn sách có chung một tác giả. Nhìn vào logic code bên trên có thể thấy rằng hệ thống đang thực hiện rất nhiều truy vấn giống nhau lên đến 18 lần để lấy cùng dữ liệu trong đó nhiều truy vấn lấy chung dữ liệu của 1 tác giả. Bạn có thể thấy 2 cuốn sách “How We Got to Now” và “The Victorian Internet” đang thực hiện lặp lại truy vấn giống nhau để lấy thông tin tác giả của chúng, điều này là không cần thiết vì nó sẽ gây ảnh hưởng đến performance cũng như lãng phí tài nguyên của hệ thống. Để giải quyết bài toán này thì GraphQL có cung cấp cho chúng ta Dataloaders. Cùng mình tìm hiểu về Dataloaders dưới đây và cách triển khai chúng trong GraphQL nhé.
1. Dataloaders là gì?
DataLoader là một tiện ích chung được sử dụng như một phần của lớp tìm nạp dữ liệu của ứng dụng của được phát triển cho GraphQL bởi Facebook. Nó có thể đóng vai trò như một phần không thể thiếu trong lớp dữ liệu của ứng dụng của bạn để cung cấp một API nhất quán qua các đầu cuối khác nhau và giảm chi phí giao tiếp thông báo thông qua phân phối và lưu vào bộ nhớ đệm. Nó được phát triển đầu tiên cho NodeJS và sau đó là các ngôn ngữ khác nhau với mục đích giải quyết vấn đề gọi nhiều truy vấn giống nhau trong cùng 1 lần gọi API. Với Dataloaders bạn có thể xây dựng cơ chế cache data tại thời điểm đó cho dữ liệu sau khi đã tìm nạp dữ liệu và khi một truy vấn khác tại thời điểm đó được gọi, nó sẽ lấy dữ liệu trong Dataloaders để trả về.
2. Cách triển khai một Dataloaders cho API.
Vẫn là ví dụ trên nhưng lần này mình sẽ dùng Dataloaders để giải quyết truy vấn bị lặp lại không cần thiết nhé. Trước khi để sử dụng được Dataloaders thì các bạn cần phải implement lại một GraphQLContext của GraphQL để có thể đưa Dataloaders vào trong Context của GraphQL nhé.
Nói một chút về Context trong GraphQL thì nó như một ngữ cảnh cho phép chúng ta thực hiện một số thao tác nhất định trước khi thực hiện Resolvers như xác thực thông tin, cấu hình kết nối cơ sở dữ liệu và các dịch vụ khác mà bạn sẽ dụng ở Resolvers. Mình sẽ không nói chi tiết về Context nên bạn có thể tìm hiểu ở Bài viết này nhé. Bây giờ mình sẽ hướng dẫn các bạn custom lại Context của GraphQL nhé.
Đầu tiên chúng ta sẽ tạo ra một đối tượng Context, nó sẽ được sử dụng ở các Resolvers:
//GraphQLContext.ktclassGraphQLContext(privateval graphQLServletContext: GraphQLServletContext
): GraphQLServletContext {overridefungetSubject(): Optional<Subject>= graphQLServletContext.subject
overridefungetDataLoaderRegistry(): Optional<DataLoaderRegistry>= graphQLServletContext.dataLoaderRegistry
overridefungetFileParts(): MutableList<Part>= graphQLServletContext.fileParts
overridefungetParts(): MutableMap<String, MutableList<Part>>= graphQLServletContext.parts
overridefungetHttpServletRequest(): HttpServletRequest = graphQLServletContext.httpServletRequest
overridefungetHttpServletResponse(): HttpServletResponse = graphQLServletContext.httpServletResponse
}Sau đó chúng ta cần thực hiện implement lại GraphQLServletContextBuilder của GraphQL để có thể xây dựng Context tuỳ chỉnh cho Http hoặc Websocket. Tại đây chúng ta có thể thực hiện các thao tác cấu hình và trả về một đối tượng GraphQLContext đã custom ở trên cho các Resolvers. Ở ví dụ này mình chỉ làm việc với Http nên chúng ta sẽ làm như sau nhé:
//GraphQLContextBuilder.kt@ConfigurationclassGraphQLContextBuilder(privateval userService: UserService): GraphQLServletContextBuilder {overridefunbuild(
httpServletRequest: HttpServletRequest?,
httpServletResponse: HttpServletResponse?): GraphQLContext {val context = DefaultGraphQLServletContext.createServletContext().with(httpServletRequest).with(httpServletResponse).build()returnGraphQLCustomContext(context)}overridefunbuild(session: Session?, handshakeRequest: HandshakeRequest?): GraphQLContext {throwIllegalStateException("Unsupported!")}overridefunbuild(): GraphQLContext {throwIllegalStateException("Unsupported!")}}Tại AuthorRepository mình sẽ tạo một function truy vấn như sau, nó nhận đầu vào là một List Id của author mà một Resolver cần sử dụng đến và trả về một List Author:
//AuthorRepository.kt@Query("SELECT author FROM Author author "+"WHERE author.id IN :authorIds")funfindAuthorsWithAuthorIds(authorIds: Set<Int>): List<Location>Bây giờ là bước quan trọng nhất, chúng ta sẽ xây dựng một đối tượng DataLoaderRegistryFactory nơi mà sẽ thực hiện xử lý việc truy vấn dữ liệu và cache data cho các Resolver trong 1 lần gọi. Lưu ý rằng sau khi API thực thi xong dữ liệu cũng sẽ được kết thúc và không lưu vào Ram như Memcache hoặc Redis. Ở các lần thực thi sau chúng sẽ lại xử lý truy vấn và cache lại dữ liệu để tránh truy vấn giống nhau trong một lần thực thi nhé. Chúng ta sẽ tạo ra một DataLoaderRegistryFactory để chứa các function thực hiện loader như sau:
@ComponentclassDataLoaderRegistryFactory(privateval authorRepository: AuthorRepository){companionobject{val DATA_LOADER_REGISTRY_AUTHOR ="DATA_LOADER_REGISTRY_AUTHOR"}funcreate(): DataLoaderRegistry {returnDataLoaderRegistry().register(DATA_LOADER_REGISTRY_AUTHOR,loadAuthors())}funloadAuthors(): DataLoader<Int, Author>{return DataLoader.newMappedDataLoader{ authorIds ->
CompletableFuture.supplyAsync({authorRepository.findAuthorsWithAuthorIds(authorIds)},
Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors()))}}}Với BookResolver bạn có thể truyền thêm vào DataFetchingEnvironment để sử dụng được Context:
//BookResolver.ktfunfindAllBook(environment: DataFetchingEnvironment): List<Book>= bookService.findAllBookWithAuthor(environment)Cuối cùng để có thể load được Author từ Dataloaders bạn có thể làm theo như sau:
//BookService.ktfunfindAllBookWithAuthor(): List<Book>{val dataloader = environment.getDataLoader<Int, Author>(DataLoaderRegistryFactory.DATA_LOADER_REGISTRY_AUTHOR)val books = bookRepository.findAll()return books.map{val author = dataloader.load(it.authorId)Book(
it.id,
it.title,
it.description,
it.price,Author(
author.id,
author.fullname,
author.email,
author.address,
author.tel,
author.createdDate,
author.updatedDate
),
it.createdDate,
it.updatedDate
)}}Như các bạn có thể thấy với cách triển khai như trên truy vấn sẽ thực hiện duy nhất một lần, tại function loadAuthors của Dataloaders nó có sử dụng DataLoader.newMappedDataLoader và nhận đầu vào là một List id của author mà dataloader.load(id) đã gọi đến. Sau đó nó gọi đến findAuthorsWithAuthorIds của AuthorRepository để thực hiện truy vấn các Author cần thiết trong cơ sở dữ liệu.
3. Tóm tắt.
Trong bài viết này mình đã giới thiệu cho các bạn Dataloaders cũng như cách triển khai chúng trong một ứng dụng GraphQL. Có thể sẽ khó hiểu nhưng nếu đã làm việc quen với GraphQL thì mình nghĩ việc triển khai một Dataloaders là việc chắc chắn nên làm vì nó sẽ giúp ứng dụng của bạn giảm thiểu các rủi do liên quan đến performance cũng như chi phí tài nguyên. Ở bài viết sau mình sẽ hướng dẫn các bạn triển khai một ứng dụng GraphQL trên Client nhé.
Nguồn: viblo.asia