Trong phần này sẽ mô tả phần mà hầu hết các sách giáo khoa về SQL không nói đến, truy vấn với tham số.
Các bạn có thể xem đầy đủ các phần tại đây nhé
Nếu các bạn chưa đọc bài trước có thể đọc tại link
Các phép toán lớn hơn (>) nhỏ hơn (<) và BETWEEN cũng có thể sử dụng index giống toán tử bằng (=), thậm chí kể cả toán tử LIKE cũng có thể dùng được trong một số trường hợp. Việc dùng index kiểu này có giới hạn nếu đánh index trong một index chứa nhiều cột và chọn cột nào trước, cột nào sau. Nhiều khi không thể chọn được thứ tự đúng.
Đầu tiên chúng ta đi vào trường hợp truy vấn theo Lớn Hơn, Nhỏ Hơn, và BETWEEN.
Vấn đề lớn nhất với truy vấn kiểu này chính là việc duyệt theo leaf node. Quy tắc vàng của việc đánh index chính là giữ cho việc duyệt qua các cục index càng ít càng tốt, chứ đánh index mà tìm từ đầu tới cuối thì có ý nghĩa gì nữa. Bạn có thể tự ước lượng trong đầu khi nào bắt đầu duyệt và kết thúc duyệt index.
Nếu câu lệnh cho phép tìm theo điều kiện bắt đầu và kết thúc rõ ràng như câu lệnh sau thì đơn giản
SELECT first_name, last_name, date_of_birth
FROM employees
WHERE date_of_birth >= TO_DATE(?, 'YYYY-MM-DD')
AND date_of_birth <= TO_DATE(?, 'YYYY-MM-DD')
Một index trên trường date_of_birth sẽ duyệt trên một khoảng dữ liệu. Nó bắt đầu ở date đầu tiên và kết thúc ở date cuối cùng. Chúng ta không thể thu hẹp phạm vi quét được nữa.
Giả sử có thêm một cột nữa trong câu truy vấn thì sẽ như thế nào? Lúc này câu chuyện sẽ khác, giả sử ta có câu lệnh như dưới đây
SELECT first_name, last_name, date_of_birth
FROM employees
WHERE date_of_birth >= TO_DATE(?, 'YYYY-MM-DD')
AND date_of_birth <= TO_DATE(?, 'YYYY-MM-DD')
AND subsidiary_id = ?
Trong trường hợp này một index lý tưởng sẽ chứa cả hai cột, nhưng câu hỏi là theo thứ tự nào?
Hình dưới sẽ chỉ ra việc thứ tự trong index ảnh hưởng thế nào tới các câu truy vấn theo kiểu scanned index range ( duyệt index theo khoảng). Giả sử chúng ta cần tìm tất cả nhân viên có subsidiary_id là 27 có ngày sinh trong khoảng từ tháng 1/1 tới 9/1 năm 1971
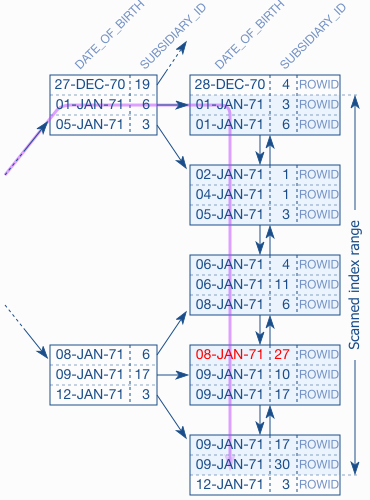
Hình trên mô tả trường hợp đánh index theo thứ tự trường date_of_birth trước và subsidiary_id sau. Nhìn trên hình các bạn sẽ thấy index được sắp thứ tự theo date_of_birth và subsidiary_id chỉ có ý nghĩa khi date_of_birth có giá trị bằng nhau. Vì vậy câu truy vấn index thực hiện theo DATE_OF_BIRTH, và SUBSIDIARY_ID được sử dụng rất hạn chế khi duyệt cây. Bạn có thể thấy trên hình ở leaf node có chứa bản ghi có SUBSIDIARY_ID bằng 27, nhưng ở node cành không hề có. Vì vậy trong trường hợp này điều kiện để dừng việc duyệt theo index chỉ phụ thuộc vào DATE_OF_BIRTH. Nó duyệt qua 5 leaf node như hình bên trên.
Bây giờ ta thử đổi thứ tự của index đưa subsidiary_id trước và date_of_birth sau.
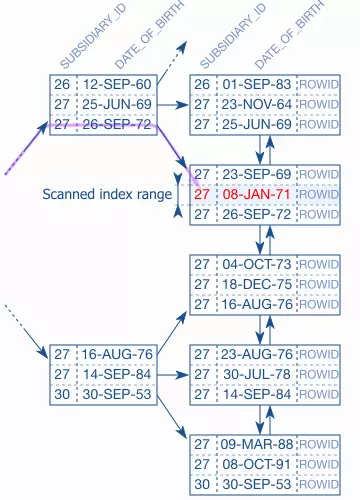
Như hình trên có thể thấy việc tìm kiếm bản ghi được thực hiện ngay lập tức không cần duyệt qua nhiều leaf node. Tại sao lại như vậy? Bởi vì đầu tiên so sánh bằng sẽ lấy ra các bản ghi có giá trị SUBSIDIARY_ID=27 đã được lấy ra, việc tiếp theo là duyệt index để tìm giá trị DATE_OF_BIRTH trong khoảng phù hợp. Vì giá trị SUBSIDIARY_ID=27 bằng nhau cho các giá trị được lấy ra lúc này việc sort theo DATE_OF_BIRTH trở lên có giá trị. Lúc này không cần phải duyệt ngược lại để tìm kiếm giá trị phù hợp, bởi vì trên branch node bạn đã thấy không có bản ghi nào lớn hơn giá trị 26/06/1969 trên leaf node trước đó. Lúc này database sẽ duyệt trực tiếp vào node thứ hai (Từ cục 23-SEP-69 đến cục 26-SEP-72) và kết thúc luôn việc duyệt.
Rule of thumb: Luôn index cho giá trị truy vấn trong toán tử bằng trước, sau đó đến range
Sự khác biệt về hiệu năng của việc thứ tự index khi tìm kiếm phụ thuộc vào dữ liệu và tiêu chí tìm kiếm của các bạn. Sự khác biệt có thể không đáng kể nếu như DATE_OF_BIRTH tìm theo khoảng nhỏ hơn, hoặc dữ liệu giống giống nhau ( Nếu thay bằng trường khác kiểu năm sinh chả hạn, chỉ ngày sinh, hoặc chỉ tháng sinh chả hạn). Phạm vi tìm kiếm theo range càng lớn thì hiệu năng càng khác biệt nhau.
Có một lời đồn rằng nên chọn những cột có độ selective lớn ( độ khác biệt lớn) để vào bên trái index. Trong ví dụ trên cả hai đều có selectivity như nhau là 13 bản ghi nhưng kết quả vẫn khác nhau. Những trường hợp thế này cần phải cân nhắc vì có trường hợp truy vấn chỉ theo DATE_OF_BIRTH hay có trường hợp truy vấn chỉ theo SUBSIDIARY_ID hoặc còn xem truy vấn theo range hay theo giá trị bằng.
Để tối ưu hiệu năng, một điều quan trọng là bạn phải biết cách scanned index range hoạt động. Hầu hết database hỗ trợ điều đó qua execution plan. Dưới đấy là execution plan khi thực hiện truy vấn theo index EMP_TEST bắt đầu với trường DATE_OF_BIRTH trong ORACLE database.
--------------------------------------------------------------
|Id | Operation | Name | Rows | Cost |
--------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 4 |
|*1 | FILTER | | | |
| 2 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 1 | 4 |
|*3 | INDEX RANGE SCAN | EMP_TEST | 2 | 2 |
--------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(:END_DT >= :START_DT)
3 - access(DATE_OF_BIRTH >= :START_DT
AND DATE_OF_BIRTH <= :END_DT)
filter(SUBSIDIARY_ID = :SUBS_ID)
Thông tìn trong Predicate cung cấp các gợi ý cho chúng ta, nó định nghĩa filter (duyệt trên leaf node) hay access (mô tả điều kiện bắt đầu hoặc kết thúc việc duyệt trên leaf node). Có thể thấy được trên ví dụ trên DATE_OF_BIRTH được sử dụng trong access còn SUBSIDIARY_ID được sử dụng trong filter.
Access predicates: là điều kiện bắt đầu hoặc kết thúc việc tìm kiếm theo index. Nó xác định phạm vi index được quét.
Index filter predicates: chỉ được áp dụng khi duyệt theo leaf node. Nó không giới hạn phạm vi index được quét.
Bây giờ thử execution plan khi đổi lại thứ tự index
| Id | Operation | Name | Rows | Cost |
---------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 3 |
|* 1 | FILTER | | | |
| 2 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 1 | 3 |
|* 3 | INDEX RANGE SCAN | EMP_TEST2 | 1 | 2 |
---------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(:END_DT >= :START_DT)
3 - access(SUBSIDIARY_ID = :SUBS_ID
AND DATE_OF_BIRTH >= :START_DT
AND DATE_OF_BIRTH <= :END_T)
Trong trường hợp này execution plan chạy hoàn toàn theo access, vì vậy sẽ có hiệu năng tốt hơn.
Có cách nào để viết câu lệnh bên trên gọn hơn không? Bạn có thể dùng lệnh BETWEEN nhé! Hai câu lệnh sau là tương tương. Bạn cũng nên để ý là BETWEEN chứa cả giá trị hai biên trong câu lệnh nhé!
DATE_OF_BIRTH BETWEEN '01-JAN-71'
AND '10-JAN-71'
và
DATE_OF_BIRTH >= ’01-JAN-71′
AND DATE_OF_BIRTH <= ’10-JAN-71′
Giờ cũng sang năm mới rồi, chúc các bạn năm con Hổ tràn đầy thành công và hạnh phúc!
Nguồn: viblo.asia