Như bài trước đã viết, tốc độ duyệt cây tìm kiếm cân bằng là siêu nhanh, thế mà không hiểu sao mình đã đánh index rồi mà lệnh truy vấn vẫn chậm, mấy thằng cha làm cơ sơ dữ liệu như Larry Ellison nó lừa mình kiếm tiền tỷ phải không? Ngày xửa ngày xưa, từ hồi anh em cây khế còn chơi với nhau, cho tới bây giờ có một giai thoại được truyền tai nhau giữa các dev là index để lâu càng ngày càng chậm, lâu lâu phải rebuild lại index một lần. Thực tế thì không phải như vậy, cây index luôn luôn có một độ sâu cố định và luôn được duy trì ở trạng thái cân bằng. Việc đánh index rồi mà truy vấn vẫn chậm có thể còn hai nguyên nhân nữa.
Đầu tiên ta phải hiểu khi truy vấn dữ liệu theo index gồm 3 bước
- Duyệt cây
- Duyệt theo các leaf node
- Lấy dữ liệu trong bảng
Ta đã thấy bước duyệt cây nhanh rồi, mà index vẫn chậm thì có thể do hai nguyên nhân
-
Bước duyệt theo leaf node chậm

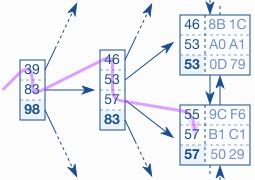
Như hình trên khi duyệt trên leaf node có hai bản ghi có giá trị 57, để chắc chắn lấy hết các bản ghi hợp lý database phải duyệt sang leaf node tiếp theo, trong thực tế có rất nhiều bản ghi thỏa mãn điều kiện như vậy, nên database phải duyệt qua nhiều leaf node. Mỗi leaf node này nằm trên các block khác nhau, không kề nhau như đã trình bày ở bài 2 leaf node Đây là một nguyên nhân gây vấn đề chậm index.
-
Bước lấy dữ liệu trong bảng chậm
Trong trường hợp một leaf node có thể chứa nhiều cục index (thường là hàng trăm) nhưng khi lấy dữ liệu từ bảng thì mỗi cục dữ liệu trong bảng có thể nằm trên nhiều block khác nhau:
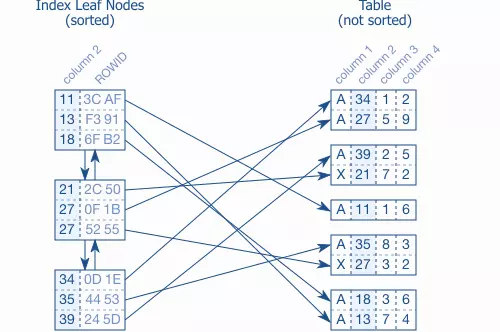
Như trên hình bên, hai cục có giá trị là 27 nằm trên cùng một leaf node, nhưng dữ liệu trong bảng lại lưu ở các block khác nhau, dẫn tới việc đọc dữ liệu tới các block này chậm ( chú ý đây là hình minh họa còn trong thực tế có hàng trăm cục như cục 27 có thể lưu ở bất cứ chỗ nào).
Mọi người thường nghĩ index chậm là do duyệt cây, và index chậm là do cây bị hỏng hoặc không cân bằng. Thực tế thì không phải như vậy. Oracle giải thích về các kiểu duyệt cơ bản khi tìm kiếm theo index như sau:
INDEX UNIQUE SCAN: Kiểu này là chỉ có duyệt cây thôi, kiểu này được dùng khi tìm kiếm trong một trường có ràng buộc unique đảm bảo rằng có duy nhất một bản ghi thỏa mãn. Ví dụ
SQL> select empno from emp where empno=10;
Execution Plan
----------------------------------------------------------
Plan hash value: 4008335093
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 4 | 0 (0)| 00:00:01 |
|* 1 | INDEX UNIQUE SCAN| PK_EMP | 1 | 4 | 0 (0)| 00:00:01 |
----------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("EMPNO"=10)
INDEX RANGE SCAN: Kiểu này sẽ là vừa duyệt cây vừa duyệt theo leaf node để tìm tất cả bản ghi thỏa mãn, chạy khi có khả năng có nhiều bản ghi thỏa mãn kết quả tìm kiếm. Ví dụ
SQL> select empno,ename from emp where empno > 7876 order by empno;
Execution Plan
----------------------------------------------------------
Plan hash value: 2449469783
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 10 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 10 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | PK_EMP | 1 | | 1 (0)| 00:00:01 |
--------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("EMPNO">7876)
Trường hợp trên lấy những bản ghi lớn hơn 7876 nên có thể có nhiều dữ liệu, INDEX RANGE SCAN được chạy, chú ý có cả TABLE ACCESS BY INDEX ROWID bởi vì có lấy thêm trường ename không có trong index
TABLE ACCESS BY INDEX ROWID: Kiểu này để lấy các dòng dữ liệu trong table , thao tác này thường được thực hiện với các bản ghi phù hợp từ các thao tác trước đó.
SQL> select empno,ename from emp where empno=10;
Execution Plan
----------------------------------------------------------
Plan hash value: 4066871323
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 10 | 1 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 10 | 1 (0)| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN | PK_EMP | 1 | | 0 (0)| 00:00:01 |
--------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("EMPNO"=10)
Trong đoạn trên do có lấy trường ename không có trong index, database phải đọc trong bảng nến cần dùng đến TABLE ACCESS BY INDEX ROWID
Điểm quan trọng là INDEX RANGE SCAN có thể đọc rất nhiều index , và mỗi index đều phải chọc vào bảng để lấy dữ liệu thì câu truy vấn có thể chậm dù có dùng index đi chăng nữa.
Phần sau mình sẽ đi chi tiết vẫn để này trong phần Câu Lệnh Where với toán tử bằng (=) các bạn chờ đọc nhé!
Nguồn: viblo.asia