Mở bài
Trong tất cả các loại Neural Network, em thích nhất là Convolutional Neural Network. Vì vậy hôm nay em sẽ làm một bài văn miêu tả về Receptive field là gì, tại sao chúng ta cần phải hiểu nó nếu muốn hiểu rõ cách CNN hoạt động.
Như chúng ta đã biết NN được lấy cảm hứng từ hệ thần kinh não bộ của con người với receptive field cũng không ngoại lệ, vậy nên mình sẽ lấy một ví dụ về hệ thống thị giác của con người cho mọi người dễ hình dung. Khi mà bạn tập trung nhìn vào một vật thể ở trước mặt thì khu vực nhìn thấy của mắt người sẽ được gọi là receptive field (field of view). Hệ thống thị giác của chúng ta có hàng triệu tế bào thần kinh vì vậy với mỗi tế bào thần kinh nó sẽ phụ trách receptive field một phần hoặc một khu vực nhỏ trên tổng thế reptive field nhìn thấy (total field of view). Hay nói cách khác thì mỗi neuron thần kinh sẽ được phép truy cập vào một khu vực và khu vực này được gọi là trường tiếp nhận của tế bào (cell’s receptive field). Mọi người có thể hình dung rõ hơn với hình minh họa phía dưới.
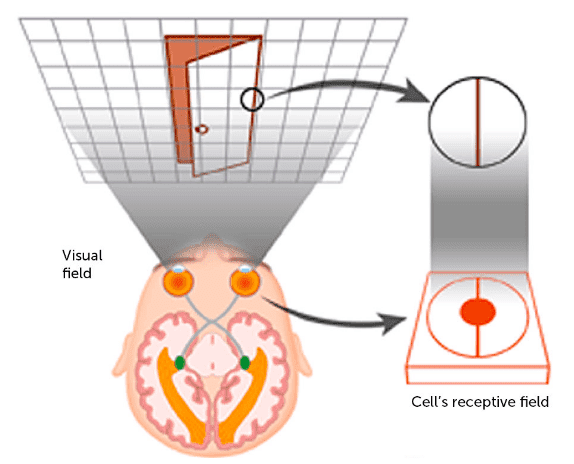
Oke. Sau khi mọi người đã mường tượng ra receptive field nó nà cái dì dồi thì chúng ta cùng đi vào chi tiết xem nó có tác dụng gì đối với CNN. Gét gô…
Thân bài
Receptive field
- Khái niệm:
Receptive field trong deep learning được định nghĩa là kích thước của một vùng (region) trong không gian đầu vào (input space) được nhìn thấy bởi pixel output qua một kernel/filter. Không giống với mạng fully connected network khi mà mỗi node trong layer phụ thuộc vào toàn bộ input đầu vào của mạng, thì đối với CNN nó chỉ phụ thuộc vào một vùng của input. Vùng này trong input được gọi là receptive field.
- Tại sao lại cần receptive field:
Oke. Để dễ hình dung mình sẽ lấy một ví dụ cụ thể, như chúng ta đã biết trong bài toán image segmentation nhiệm vụ là đi dự đoán từng pixel tương ứng ở input xem nó đang thuộc class tương ứng nào. Vậy điều chúng ta mong muốn nhất ở đây sẽ là làm sao cho việc dự đoán pixel đó thuộc true class là cao nhất. Mà điều kiện lý tưởng nhất cho điều này là tại mỗi output pixel nó có một receptive field thật lớn. Điều này giúp cho việc model không bị bỏ qua những chi tiết quan trọng trong quá trình dự đoán. Như bạn thấy ở hình bên dưới, với ouput pixel bạn muốn dự đoán thuộc khu vực chiếc ô tô thì bạn muốn receptive field là màu cam hay màu xanh? Options nào sẽ mang lại nhiều thông tin cho output hơn?
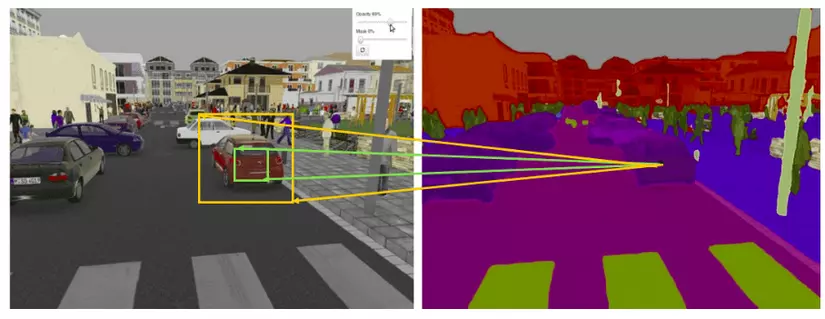
- Tính toán nó như nào:
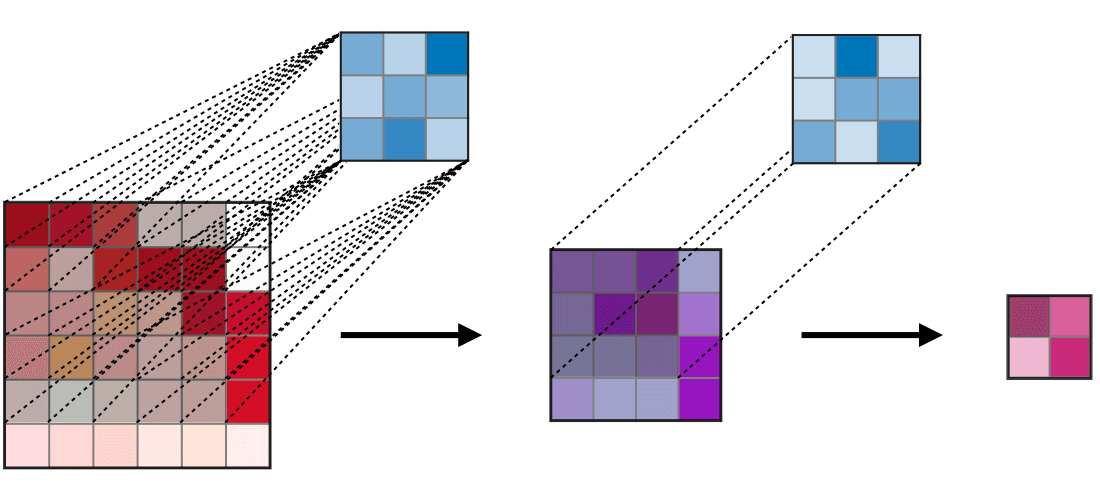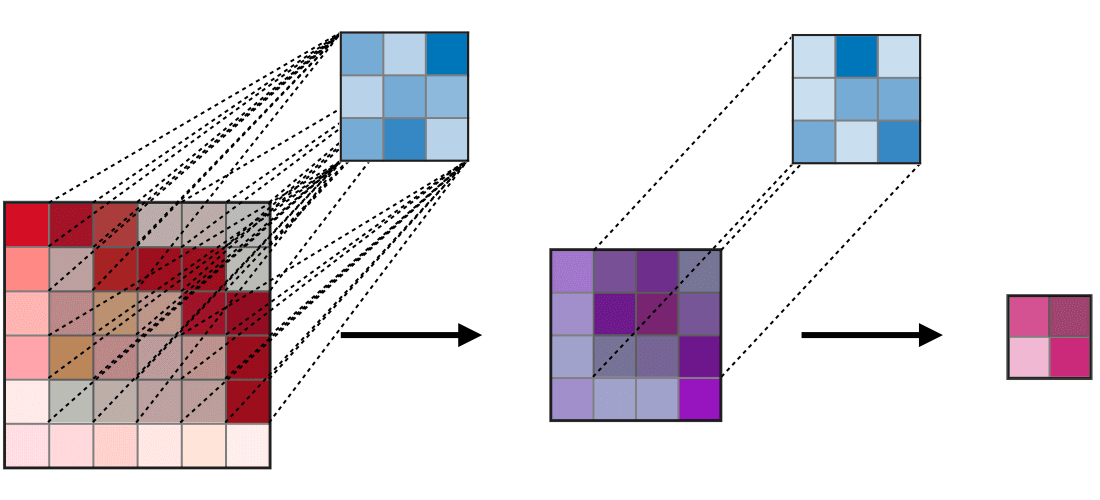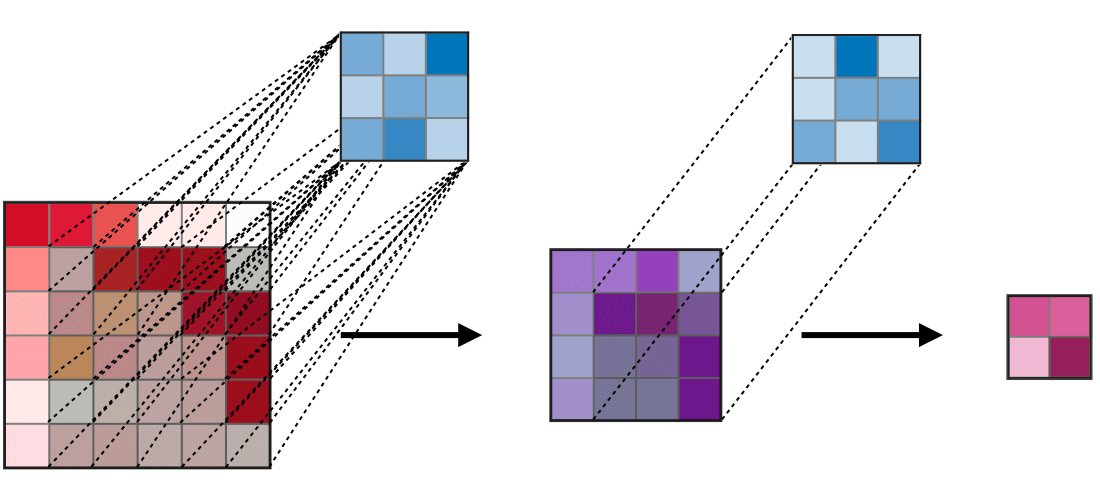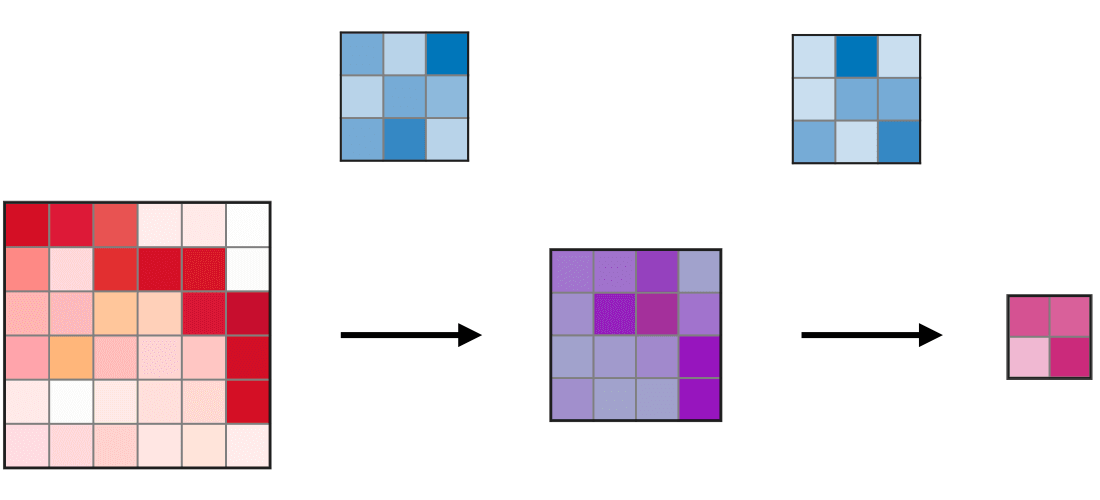
Ở đây mình sẽ lấy một ví dụ như hình bên dưới:
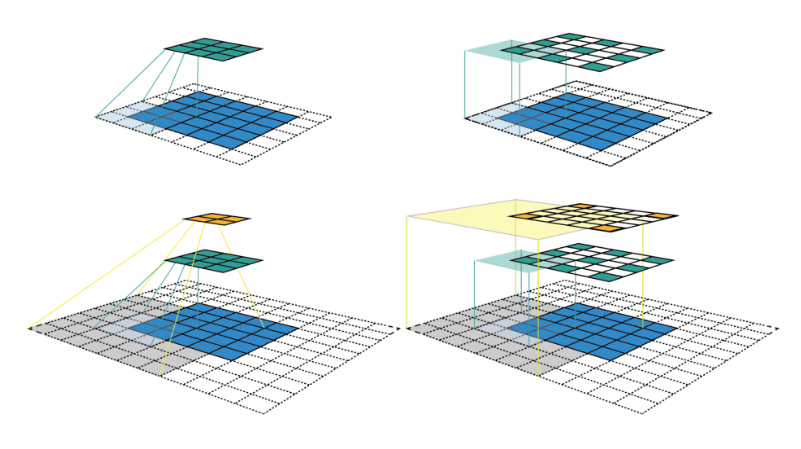
Với feature map được tạo ra bởi layer đầu tiên (màu xanh lục) được tạo ra bởi kernel size = 3×3 với padding = 1 và stride = 2 thì có thể thấy ta sẽ thu được vùng receptive field 3×3 tương ứng bằng với kích thước của kernel size (tại mỗi vùng kernel trượt qua). Tiếp đến, ta sẽ xem xét đối với feature map (màu cam) của layer thứ 2 được tạo ra với thông số S, P và kernel tương tự, lúc này đối với mỗi pixel của feature map mới ta thu được một vùng receptive field 7×7 tương ứng.
Oke. Để cho dễ hình dung về việc từng pixel trong feature map nó sẽ nhìn thấy một vùng receptive field là bao nhiêu ta sẽ nhìn qua 2 hình nhỏ phía bên phải. Với việc feature map được thay đổi kích thước bằng với kích thước của input. Vùng màu vàng nhạt và vùng màu xanh dương nhạt biểu thị cho vùng receptive field tương ứng của từng pixel trên feature map layer 1 và layer 2. Nhìn vào hình minh họa kia chúng ta có thể đoán rằng, khi mạng càng sâu thì vùng receptive field càng lớn chăng?
Giờ cùng đi vào một tí tính toán cho đỡ nhàm chán nào.😗
Ta có receptive field tại layer k được ký hiệu Rk×RkR_k times R_k. Gọi FjF_j là kích thước của kernel của layer thứ j và SiS_i là giá trị của stride của layer thứ I, ta sẽ tạm để S0S_0 = 1. Từ đó kích thước receptive field tại layer k được tính bằng công thức:
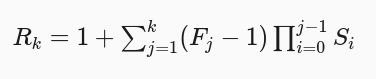
Ở ví dụ phía dưới chúng ta có, F1=F2=3F_1 = F_2 = 3 và S1=S2=1S_1 = S_2 = 1, nên cho ra được R2=1+2.1+2.1=5R_2 = 1 + 2 . 1 + 2 . 1 = 5.
Note: Chú ý rằng việc tính toán bên trên chỉ là vùng theoretical receptive field vì trong thực tế không phải toàn bộ receptive field map đều có đóng góp vào output là như nhau. Bạn sẽ được tìm hiểu về khái niệm effective receptive field ở phần tiếp theo.
- Một số cách tăng receptive field:
- Add thêm nhiều layers hơn: Một cách đơn giản nhất là add thêm nhiều layers hơn tạo cho mạng sâu hơn. Việc này tăng kích thước của receptive field lên theo chiều tuyến tính. Như ở những ví dụ bên trên mình đã đưa ra thì chắc có lẽ mọi người cũng sẽ hình dung ra. Tuy nhiên cách này có một vấn đề xảy ra, khi mà kích thước được tăng sẽ là kích thước theoretical receptive field trong khi kích thước effective receptive field lại bị giảm xuống.

- Sub-sampling and diated convolutions: Đây là một cách khác giúp tăng receptive field lên nhiều lần. Cụ thể hơn đây là một kỹ thuật mở rộng kernel bằng cách chèn các hố (holes) vào giữa các phần tử của kernel. Nói cách khác nó giống như việc tính convolutions nhưng bỏ qua pixel (kiểu nhảy cóc =)) ) giúp cho việc mở rộng input ra một vùng lớn hơn.
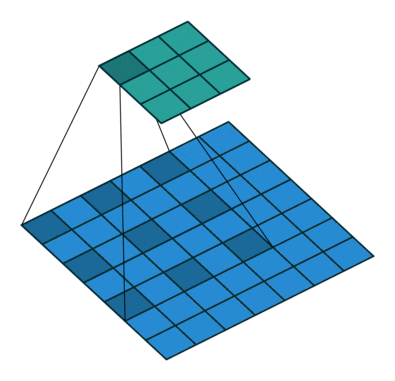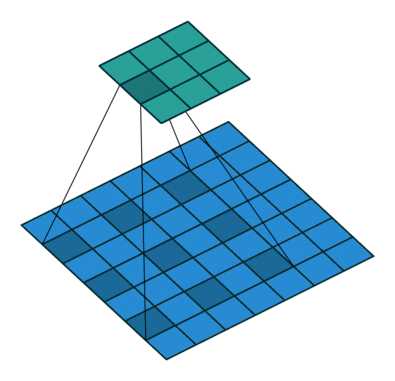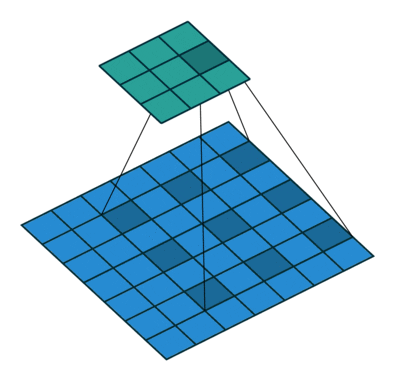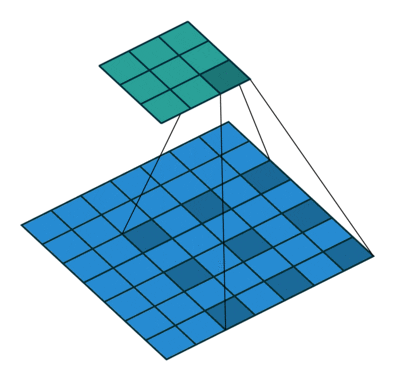
Effective receptive field
- Vấn đề của theoretical receptive field:
Như tác giả ở paper này đã phân tích và chỉ ra rằng khu vực effective nằm trong receptive field có tác động lớn đến output của layer (khu vực này được gọi là effective receptive field) chỉ chiếm một phần nhỏ trên toàn bộ theoretical receptive field. Và đặc biệt nó còn suy giảm nhanh chóng từ tâm theo phân phối Gaussian.
Vậy nên tiếp theo chúng ta sẽ cùng đi tìm cách để tính toán xem liệu những pixel nào nằm trong receptive field có tác động lớn đến output của layer.
Để tính toán thí nghiệm tác giả chỉ lấy duy nhất một điểm y0,0y_{0,0} là pixel trung tâm tại feature map và sau đó tính toán tác động của các điểm xi,jx_{i,j} lên nó. Oke bắt đầu nào…
Cho mỗi pixel trên mỗi layer có index là (i,j)(i, j), vơi tâm của chúng là (0,0)(0, 0). Biểu thị pixel thứ (i,j)(i, j) của layer thứ p là xi,jp{x_{i,j}^p} với xi,j0{x_{i,j}^0} là pixel input của mạng, và yi,j=xi,jny_{i,j} = {x_{i,j}^n} là output của layer thứ n. Nhiệm vụ của chúng ta là sẽ đo lường xem mỗi giá trị của xi,j0{x_{i,j}^0} sẽ đóng góp bao nhiêu vào y0,0y_{0,0}
Để tính được cái này chúng ta sẽ sử dụng đạo hàm riêng ∂y0,0∂xi,j0frac{partial y_{0,0}}{partial x_{i,j}^0} và được tính toán qua back-propagation. Với việc back-propagation sẽ lan truyền ngược lỗi đạo hàm(sai số giữa giá trị output và labels) với hàm số loss nhất định. Ở đây, giả sử chúng ta có hàm số loss ll khi đó sử dụng chain rule để tính đạo hàm chúng ta sẽ có ∂l∂xi,j0=∑i′,j′∂l∂yi′,j′.∂yi′,j′∂xi,j0frac{partial l}{partial x_{i,j}^0} = sumnolimits_{i’,j’} frac{partial l}{partial y_{i’,j’}} . frac{partial y_{i’,j’}}{partial x_{i,j}^0}
Để lấy được ∂y0,0∂xi,j0frac{partial y_{0,0}}{partial x_{i,j}^0}, chúng ta chỉ cần set ∂l∂y0,0=1frac{partial l}{partial y_{0,0}} = 1 và ∂l∂yi,j=0frac{partial l}{partial y_{i,j}} = 0 cho tất cả những vị trí i≠0i neq 0 và j≠0j neq 0. Sau đó thì việc lan chuyền ngược của mạng như bình thường ta sẽ được kết quả ∂l∂xi,j0frac{partial l}{partial x_{i,j}^0} bằng với ∂y0,0∂xi,j0frac{partial y_{0,0}}{partial x_{i,j}^0}
- Vậy cái gì sẽ tác động đến sự thay đổi của ERF?
-
Dropout:
Đối với dropout sẽ không làm thay đổi kích thước của ERF. Điều này được xác thực trong paper -
Sub-sampling & Diated convolutions:
Như ta có thể thấy việc sub-sample và dialted tác động lên ERF là rất lớn khi so sánh với việc chỉ sử dụng Conv đơn thuần
![]()
-
Activation:
Như ở hình bên dưới có thể thấy việc add ReLU activation làm cho ERF giảm thiểu hiện tượng Gaussian xuống một chút
![]()
-
Trong quá trình training:
Ở đây tác giả có sử dụng 2 task, một là classification và segmentation để làm thí nghiệm. Như ta có thể thấy thì trước và sau khi training ERF có thấy đổi rất lớn. Điều này có thể dự đoán rằng sau khi training model đã learn tốt hơn và biết cách sử dụng nhiều thuộc tính ở trên input hơn.
![]()



- Một số chiến lược giúp tăng quy mô của ERF:
Như đã nói ERF là một dạng Gaussian distribution, vì vậy nó sẽ bị suy giảm nhanh chóng từ tâm. Điều này là không mong muốn. Vậy làm sao để giảm thiểu tổn thất do Gaussian gây lên?
New Initialization: Khởi tạo một bộ trọng số ngẫu nhiên sao cho trọng số ở trung tâm của kernel có tỉ lệ nhỏ hơn trọng số ở bên ngoài, điều này làm cho việc khuếch tán trọng số ở trung tâm ra ngoại vi. Trong thực tế, chúng ta có thể làm điều này bằng cách khởi tạo trọng số như thông thường, sau đó chỉ cần chia tỉ lệ trọng số theo một phân phối với tỉ lệ ở trung tâm thấp hơn tỉ lệ bên ngoài.
Có một lưu ý rằng cho dù chúng ta có thay đổi W như nào đi nữa thì ERF vẫn có phân phối theo Gaussian, phương pháp trên chỉ có thể làm giảm thiểu được vấn đề này.
Architectural changes: Đây có lẽ là cách đơn giản hơn cách trên. Việc thay đổi kiến trúc của mạng sẽ giúp chúng ta thay đổi được ERF một cách cơ bản nhất. Ở đây ví dụ chúng ta có thể sử dụng Sub-sampling hay dialted convolution.
Kết bài
Không phải là yếu tố duy nhất quyết định hiệu suất của của model deep learning. Nhưng không thể phủ nhận được việc receptive field có tác động rất lớn đến output của mạng. Nếu chúng ta hiểu được tầm quan trọng của nó và sử dụng một số phương pháp giúp tăng được kích thước của receptive field lên sẽ giúp cho model tăng hiệu suất đáng kể.
References:
Nguồn: viblo.asia