Panda is a library for manipulating with data in Python. Quick facts:
| Fact | Description |
|---|---|
| Homepage | https://pandas.pydata.org |
| API doc | https://pandas.pydata.org/docs/reference/index.html |
| Initial year | Aug 05, 2009 (13 years ago). https://github.com/pandas-dev/pandas/commit/ec1a0a2a2 |
| Source code | https://github.com/pandas-dev/pandas |
| Stack Overflow tag | https://stackoverflow.com/questions/tagged/pandas |
| Latest stable version | 1.4.2 (02 April, 2022) |
Development environment
Install pandas

Version of Python
(pythonProject1) C:Usersdonhu>python --version
Python 3.10.0
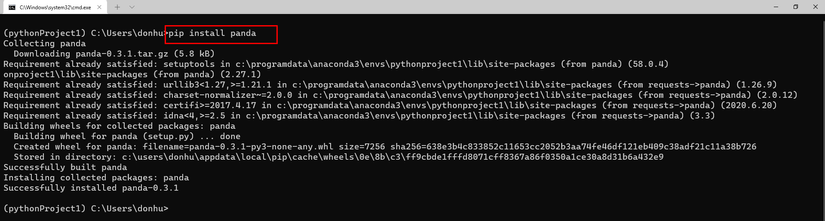
Install
Properties and Method with panda object
import pandas as pd
df = pd.DataFrame({"Name":["Braund, Mr. Owen Harris","Allen, Mr. William Henry","Bonnell, Miss. Elizabeth",],"Age":[22,35,58],"Sex":["male","male","female"],})print("n01-----------------")print(df)print()print("n02-----------------")print(df["Age"])print("n03-----------------")
ages = pd.Series([22,35,58], name="Age")print(ages)print("n04-----------------")print(df["Age"].max())print("n05-----------------")print(ages.max())print("n06-----------------")print(df.describe())# https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csvprint("n07-----------------")
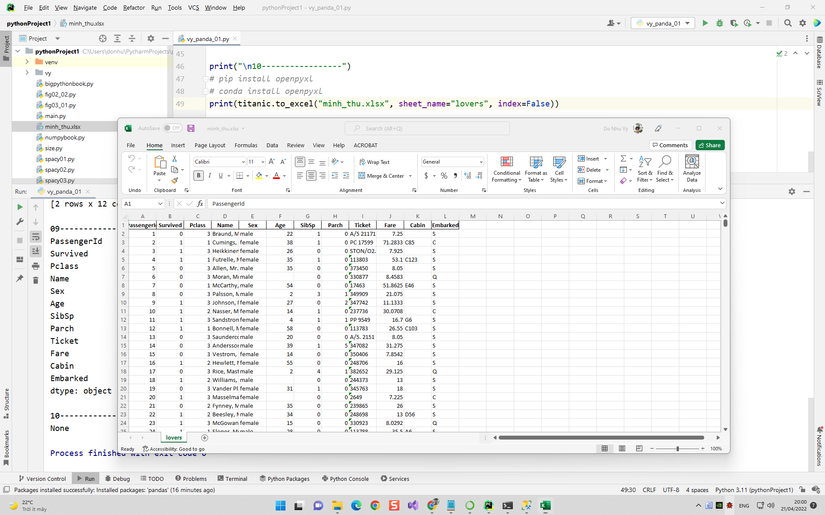
titanic = pd.read_csv("vy/titanic.csv")print(titanic)print("n08-----------------")print(titanic.head(2))print("n09-----------------")print(titanic.dtypes)print("n10-----------------")# pip install openpyxl# conda install openpyxlprint(titanic.to_excel("minh_thu.xlsx", sheet_name="lovers", index=False))print("n11-----------------")
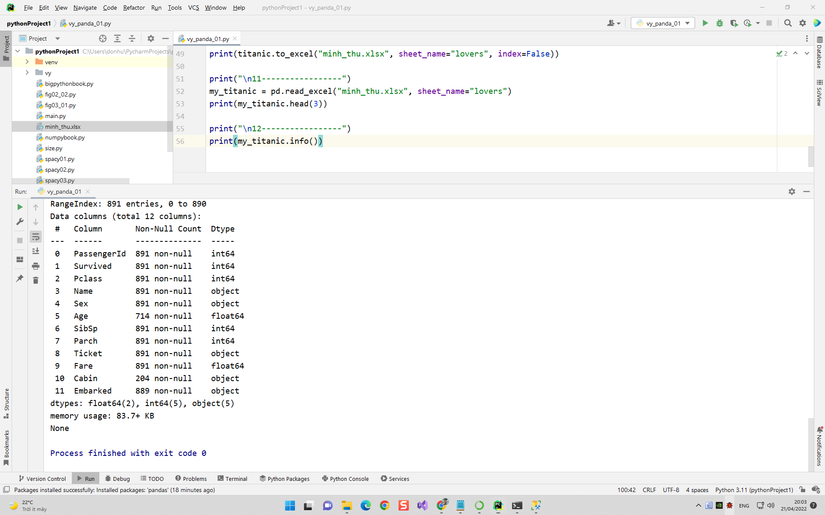
my_titanic = pd.read_excel("minh_thu.xlsx", sheet_name="lovers")print(my_titanic.head(3))print("n12-----------------")print(my_titanic.info())# https://raw.githubusercontent.com/pandas-dev/pandas/main/pandas/tests/io/data/csv/tips.csv
url =("https://raw.github.com/pandas-dev""/pandas/main/pandas/tests/io/data/csv/tips.csv")
tips = pd.read_csv(url)print("n12b-----------------")print(tips)print("n14-----------------")
sorted_df = tips.sort_values(by='total_bill')print(sorted_df)print("n15-----------------")
sorted_df = tips.sort_values(by='total_bill', ascending=False)print(sorted_df)result
C:ProgramDataAnaconda3envspythonProject1python.exe C:/Users/donhu/PycharmProjects/pythonProject1/vy_panda_01.py
01-----------------
Name Age Sex
0 Braund, Mr. Owen Harris 22 male
1 Allen, Mr. William Henry 35 male
2 Bonnell, Miss. Elizabeth 58 female
02-----------------
0 22
1 35
2 58
Name: Age, dtype: int64
03-----------------
0 22
1 35
2 58
Name: Age, dtype: int64
04-----------------
58
05-----------------
58
06-----------------
Age
count 3.000000
mean 38.333333
std 18.230012
min 22.000000
25% 28.500000
50% 35.000000
75% 46.500000
max 58.000000
07-----------------
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 NaN S
3 4 1 1 ... 53.1000 C123 S
4 5 0 3 ... 8.0500 NaN S
.. ... ... ... ... ... ... ...
886 887 0 2 ... 13.0000 NaN S
887 888 1 1 ... 30.0000 B42 S
888 889 0 3 ... 23.4500 NaN S
889 890 1 1 ... 30.0000 C148 C
890 891 0 3 ... 7.7500 NaN Q
[891 rows x 12 columns]
08-----------------
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
1 2 1 1 ... 71.2833 C85 C
[2 rows x 12 columns]
09-----------------
PassengerId int64
Survived int64
Pclass int64
Name object
Sex object
Age float64
SibSp int64
Parch int64
Ticket object
Fare float64
Cabin object
Embarked object
dtype: object
10-----------------
None
11-----------------
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 NaN S
[3 rows x 12 columns]
12-----------------
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
None
12b-----------------
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
.. ... ... ... ... ... ... ...
239 29.03 5.92 Male No Sat Dinner 3
240 27.18 2.00 Female Yes Sat Dinner 2
241 22.67 2.00 Male Yes Sat Dinner 2
242 17.82 1.75 Male No Sat Dinner 2
243 18.78 3.00 Female No Thur Dinner 2
[244 rows x 7 columns]
14-----------------
total_bill tip sex smoker day time size
67 3.07 1.00 Female Yes Sat Dinner 1
92 5.75 1.00 Female Yes Fri Dinner 2
111 7.25 1.00 Female No Sat Dinner 1
172 7.25 5.15 Male Yes Sun Dinner 2
149 7.51 2.00 Male No Thur Lunch 2
.. ... ... ... ... ... ... ...
182 45.35 3.50 Male Yes Sun Dinner 3
156 48.17 5.00 Male No Sun Dinner 6
59 48.27 6.73 Male No Sat Dinner 4
212 48.33 9.00 Male No Sat Dinner 4
170 50.81 10.00 Male Yes Sat Dinner 3
[244 rows x 7 columns]
15-----------------
total_bill tip sex smoker day time size
170 50.81 10.00 Male Yes Sat Dinner 3
212 48.33 9.00 Male No Sat Dinner 4
59 48.27 6.73 Male No Sat Dinner 4
156 48.17 5.00 Male No Sun Dinner 6
182 45.35 3.50 Male Yes Sun Dinner 3
.. ... ... ... ... ... ... ...
149 7.51 2.00 Male No Thur Lunch 2
111 7.25 1.00 Female No Sat Dinner 1
172 7.25 5.15 Male Yes Sun Dinner 2
92 5.75 1.00 Female Yes Fri Dinner 2
67 3.07 1.00 Female Yes Sat Dinner 1
[244 rows x 7 columns]
Process finished with exit code 0
Pandas Excel API
Need install pandas and openpyxl inside Miniconda before practice. This is read excel function.
import pandas as pd
found_url =("https://m.hvtc.edu.vn/Portals/0/01_2018/01.DS%20TN_9.2021%20.xlsx")
hehe = pd.read_excel(found_url)
hehe
Result
Without header
hihi = pd.read_excel(found_url, index_col=None, header=None)
hihi
rb means r + b = read + binary. See https://docs.python.org/3/library/functions.html#open
hoho = pd.read_excel(open('C:\Users\donhu\Desktop\01.DS TN_9.2021 .xlsx','rb'), sheet_name='LC22')
hoho
Nguồn: viblo.asia