Mở đầu
Đây là một paper khá hay phân tích về việc làm thế nào để thiết kế một model thực sự là hiệu quả về mặt tốc độ, điện năng tiêu thụ và độ chính xác. Nó đạp đổ toàn bộ những mạng nơ-ron tự xưng là cực nhẹ và tốc độ cao ra đời trước đó như MobileNet, ShuffleNet,… bổ sung thêm những kiến thức cần thiết cho việc thiết kế một model nhẹ. Hơn nữa, mình thấy paper này có những cách đặt vấn đề và suy luận rất hay, rất đáng để học hỏi: từ việc đặt ra giả thuyết, đi chứng minh giả thuyết, phân tích sự không tốt của model trước đó và đưa ra hướng cải tiến. Lưu ý nhỏ, bài viết này liên quan khá nhiều đến phần cứng
Lưu ý nhỏ, bài viết này liên quan khá nhiều đến phần cứng
Kiến thức cần biết
Model này dựa trên DenseNet khá nhiều, nên các bạn cần nắm khá chắc DenseNet để có thể hiểu được bài này tốt nhất.
ResNet
Chắc hẳn các bạn ai cũng quen thuộc với ResNet rồi nhỉ, các block tạo nên ResNet được biểu thị ở Hình 1.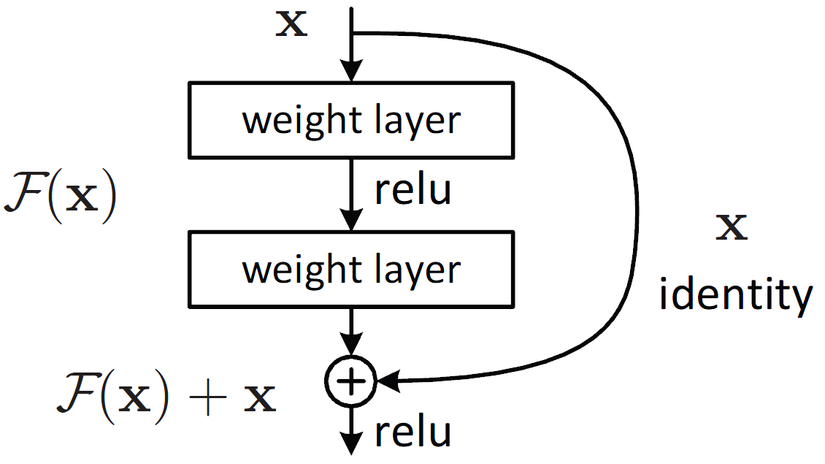
Nhắc lại cho bạn nào quên Residual Block hoạt động như nào chút. Trong Residual Block, ta sẽ có một skip connection (nhánh lồi ra ở Hình 1). Lúc này, Residual Block sẽ gồm 2 nhanh: 1 nhánh phụ lồi ra là skip connection, nhánh thẳng còn lại gọi là Residual. Vì vậy, khi một block muốn học một hàm ánh xạ: H(x)H(x), thay vì học H(x)H(x), ta chỉ phải học một F(x)F(x) dễ hơn H(x)H(x), và sau đó, H(x)=F(x)+xH(x) = F(x) + x.
Tại sao học F(x)F(x) lại dễ hơn H(x)H(x)? Vì ở những layer sâu, khi xx được học đã tốt, để muốn giữ lại feature xx, ta phải học một hàm ánh xạ H(x)H(x) sao cho H(x)=xH(x) = x. Lúc này, với Residual Block, học một F(x)=0F(x) = 0 sẽ dễ hơn rất nhiều.
DenseNet
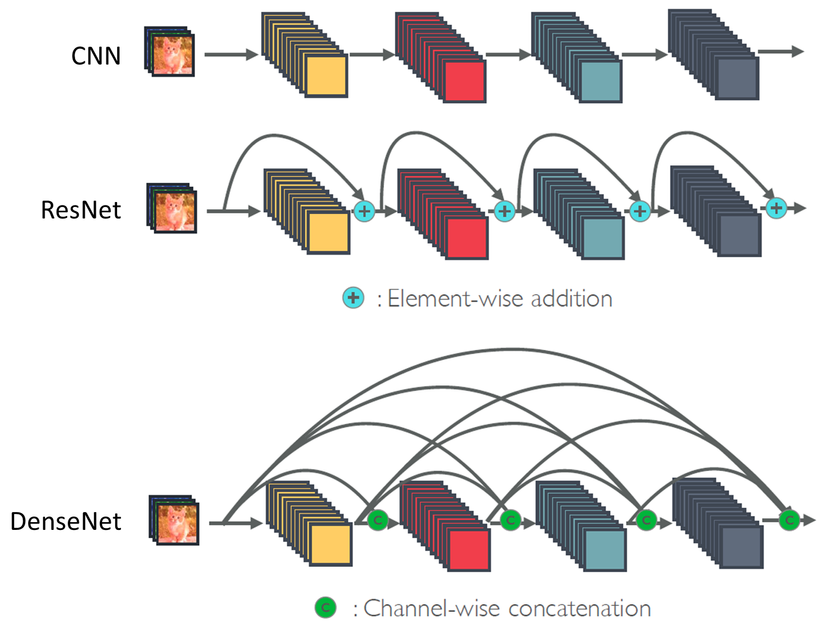
DenseNet tận dụng ý tưởng của ResNet nhưng đưa nó lên một tầm cao mới.
DenseNet cho rằng việc sử dụng toán tử cộng để kết hợp layer trước với layer sau sẽ làm giảm dòng chảy thông tin trong mạng. Khi kết hợp theo toán tử cộng, feature từ phía đằng trước có thể bị mất đi. Vì vậy, DenseNet thay toán tử cộng thành toán tử concatenate cho việc kết hợp, vừa giữ lại được thông tin cần thiết xx từ layer trước, mà còn vừa học thêm được F(x)F(x), kết hợp lại với nhau làm tăng số lượng thông tin học được. Phép concatenate trong DenseNet được thực hiện trên chiều channel.
Trong ResNet, thông tin ở layer hiện tại sẽ được kết hợp với thông tin ở 1 layer trước đó. Còn trong DenseNet, thông tin ở layer hiện tại sẽ được kết hợp với thông tin ở toàn bộ layer phía trước (Hình 2).
Về biểu diễn toán học, Residual Block trong ResNet sẽ được biểu diễn như sau:
xl=xl−1+Fl(xl−1)x_l = x_{l-1} + F_l(x_{l-1})
Còn DenseBlock trong DenseNet sẽ được biểu diễn như sau:
xl=Fl([xl−1,xl−2,…,x0])x_l = F_l([x_{l-1}, x_{l-2}, …, x_0])
với […][…] là toán tử concatenate.
Mỗi khi thực hiện concatenate, số lượng channels trong feature maps sẽ tăng lên. Để kiểm soát số lượng tăng trưởng channels, DenseNet sử dụng một hyper-parameter gọi là growth rate(kk). Số lượng channel sau mỗi layer sẽ tăng lên kk channels (Hình 3).
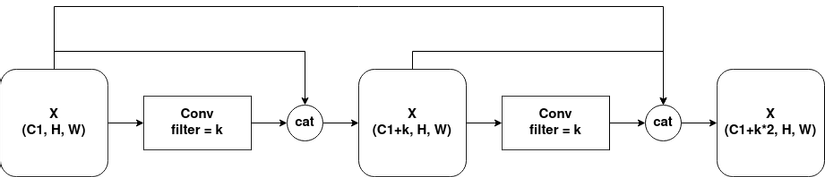
Tuy nhiên, nếu cứ liên tục concatenate như vậy thì số lượng channels sẽ tăng lên cực kì khủng khiếp, khiến việc tính toán trở nên nặng vô cùng. Vì vậy, sau một số lần concatenate, DenseNet sẽ sử dụng một 1×11 times 1 Conv để giảm số channels lại xuống một con số nhất định, giữ cho số channels trong Dense Block không trở nên quá lớn. Một lượt các concatenate được thực hiện trước khi đi qua Transition Layer gọi là một Dense Block. (Hình 4).
Tiến vào VoVNet
Vấn đề của DenseNet và các mạng nơ-ron nhẹ “trên lý thuyết”
Tác giả của VoVNet muốn hướng tới một mạng nơ-ron nhanh, tiết kiệm điện năng và có độ chính xác cao. DenseNet, trên lý thuyết, đã làm rất tốt công việc của mình so với ResNet. Ít hơn hẳn ResNet về số lượng parameters và FLOPs, độ chính xác thì cao hơn rất nhiều. Tuy nhiên, thực tế, các mạng Object Detection sử dụng backbone là ResNet lại sử dụng ít năng lượng và thời gian inference ngắn hơn so với các mạng Object Detection sử dụng backbone là DenseNet. Vì vậy, có những yếu tố khác ngoài số lượng parameters và FLOPs ảnh hưởng đến tốc độ và tiêu thụ năng lượng của mạng.
Trước tiên, Memory Access Cost (MAC – chi phí truy cập bộ nhớ), dùng để truy cập đến feature maps trung gian là một yếu tố quan trọng ảnh hưởng đến điện năng/ tốc độ. Như đã thấy trong Hình 2, vì các feature maps ở phía sau đều cần phải truy cập đến feature maps ở đằng trước, MAC của chúng ta tăng lên theo hàm bậc 2 tỉ lệ với độ sâu của mạng, dẫn đến việc tốn điện/ năng lượng hơn.
Thứ hai, DenseNet đã tự bóp bản thân với việc lạm dụng 1×11 times 1 Conv vì không tận dụng triệt để cơ chế parallel computing (tính toán song song) của GPU. Nói ngắn gọn thì, parallel computing của GPU được tận dụng tối đa khi các toán hạng lớn. Tuy nhiên, vì số channels tăng quá nhanh của DenseNet dẫn đến việc sử dụng 1×11 times 1 Conv để kìm hãm channels lại, ta vô tình làm tăng số lượng layer lên đồng thời tính toán với các toán hạng có giá trị không lớn. Số layer tăng lên khiến GPU phải thực hiện nhiều sequential computing (tính toán lần lượt).
Các yếu tố để thiết kế một mạng nơ-ron hiệu quả
Khi thiết kế các mạng nơ-ron hiệu quả, các nghiên cứu như MobileNet, ShuffleNet, Pelee đều tập trung vào giảm FLOPs và độ nặng model sử dụng depthwise convolution (DWConv) và 1×11 times 1 Convolution (BottleNeck). Tuy nhiên, việc giảm FLOPs và độ nặng model không phải lúc nào cũng tăng tốc độ inference trên GPU và giảm lượng điện tăng tiêu thụ. ShuffleNet v2 dù có chung FLOPs với MobileNet v2 nhưng tốc độ lại nhanh hơn rất nhiều trên GPU. SqueezeNet nhẹ hơn AlexNet tới 50 lần nhưng lượng điện năng tiêu thụ lại nhiều hơn AlexNet. Các hiện tượng trên cho thấy FLOPs và độ nặng model không phải là metrics thực tế khi đem vào thiết kế một mạng nơ-ron hiệu quả. Ta cần đưa thêm vào các metrics thực tế hơn như lượng điện năng tiêu thụ khi đưa 1 ảnh vào model và FPS, ngoài FLOPs và độ nặng model.
Memory Access Cost (MAC)
Yếu tố đầu tiên mà VoVNet đưa vào cân nhắc là Memory Access Cost (MAC). Lượng tiêu thụ điện năng của CNN tập trung chủ yếu ở việc truy cập bộ nhớ hơn là các phép tính toán. Cụ thể, truy cập dữ liệu từ DRAM (Dynamic Random Access Memory) để thực hiện một phép tính thì tốn năng lượng hơn rất nhiều việc thực hiện phép tính. Hơn nưa, lượng thời gian sử dụng để truy cập dữ liệu chiếm phần lớn và gây nên một nút nghẽn cổ chai trong GPU.
Một yếu tố gây nên sự khác biệt giữa độ nặng model và MAC đó chính là intermediate activation memory footprint (xin lỗi bản thân mình không biết vietsub như nào cho hay, các bạn có thể hiểu nôm na là sự thực hiện tính toán trên các feature maps có ảnh hưởng tới bộ nhớ :v). Memory footprint này chịu ảnh hưởng từ parameters và feature maps. Các model, có cùng số parameters, nhưng feature maps của một model lớn, thì model đó có MAC lớn. Vì vậy, MAC là một metrics tốt được đưa vào để đánh giá. Công thức tính MAC cho lớp Convolution như sau:
MAC=hw(ci+co)+k2cicoMAC = hw(c_i + c_o) + k^2 c_i c_o
với k,h,w,ci,cok, h, w, c_i, c_o lần lượt là kernel size, height/width, input channels và output channels của feature maps.
Độ hiệu quả khi tính toán trên GPU
Các kiến trúc mà giảm FLOPs để tối ưu tốc độ chỉ dựa trên ý tưởng là mọi floating point operations đều có cùng một tốc độ trên thiết bị phần cứng. Tuy nhiên, điều này là không đúng khi model của chúng ta ở trên GPU. Bởi vì GPU có cơ chế parallel computing, GPU có thể xử lý nhiều floating point operations cùng lúc, nên ta cần tận dụng tốt cơ chế này.
Sức mạnh parallel computing của GPU được phát huy tốt hơn khi tensor được sử dụng để tính toán lớn. Việc tách một phép convolution thành các phép tính toán nhỏ là một việc làm thiếu hiệu quả khi tính toán trên GPU bởi sẽ có ít phép tính toán được thực hiện song song. Vì vậy, ta cần thiết kế một mạng có ít layers nếu các phép tính toán của chúng là như nhau.
Theo đó, các kĩ thuật như DWConv và 1×11 times 1 Conv có thể giảm FLOPs, nó không hề tận dụng tốt khả năng tính toán của GPU, nó khiến GPU thực hiện nhiều phép tính nhỏ và tuần tự thay vì các phép tính lớn và song song. VoVNet thêm một metrics mới khi thiết kế model hiệu quả gọi là FLOP/s, được tính toàn bằng việc chia thời gian inference của GPU cho FLOPs. FLOP/s cao nghĩa là model tối ưu GPU hiệu quả hơn.
Rethinking Dense Connection
Dense Connection (ý tưởng của DenseNet) tổng hợp các feature trung gian sẽ gây ra sự thiếu hiệu quả, số channels trong feature maps cứ thế lớn dần, dẫn đến việc input channels vào một layer cứ thế lớn dần. Ta có thể thấy việc Dense Connection chỉ tạo ra một lượng nhỏ các feature map mới (growth rate). Tức là, DenseNet đánh đổi số lượng feature maps lấy chất lượng của feature maps mới. Mặc dù độ chính xác mà DenseNet mang lại cho thấy việc đánh đổi này là hợp lý, nhưng xét hiệu năng của năng lượng và tốc độ thì không tốt lắm.
Thứ nhất, Dense Connection gây ra MAC lớn. MAC tối ưu nhất khi mà số channels đầu vào của một lớn Conv bằng với số channels đầu ra. Dense Block có đầu vào tăng dần (ci+k∗ic_i + k * i, với cic_i là số channels đầu vào gốc, kk là growth rate, ii là độ sâu) nhưng đầu ra thì lại luôn giữ nguyên là kk.
Thứ hai, DenseNet sử dụng 1×11 times 1 Conv làm giảm độ hiệu quả tính toán của GPU. Vấn đề channels tăng dần theo độ sâu của DensNet được sử dụng 1×11 times 1 Conv để kìm hãm lại. Mặc dù cách làm này giảm FLOPs và parameters, nó không tốt cho GPU vì phải thực hiện nhiều phép tính tuần tự.
Để cải tiến độ hiệu quả của DenseNet, ta cần phải hiểu xem Dense Connection thực sự tổng hợp feature như nào.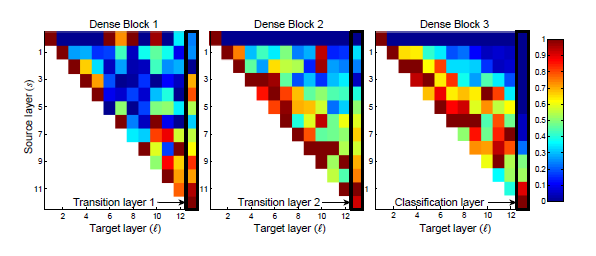
Ta có thể thấy, trong Dense Block 3, các tín hiệu kết nối mạnh xuất hiện dọc đường chéo của biểu đồ, tức là các lớp ở tầm giữa giữa Dense Block với nhau có một kết nối mạnh mẽ. Tuy nhiên, các kết nối từ các lớp giữa giữa đến Classification Layer không hề mạnh, và Classification Layer chỉ kết nối mạnh với layer ngay trước nó. Trong Dense Block 1 thì hành vi lại ngược lại, các lớp giữa giữa không hề kết nối mạnh mẽ với nhau, mà kết nối từ các lớp giữa giữa tới Transition Layer lại khá mạnh. VoVNet kết luận rằng, việc các kết nối ở các lớp giữa giữa với nhau có ảnh hưởng đối nghịch với việc kết nối của các lớp giữa giữa tới lớp cuối (Transition Layer và Classification Layer). Điều này có thể là do Dense Connection của các lớp giữa giữa trong Dense Block sinh ra các feature tốt hơn nhưng lại không quá nhiều khác biệt với các lớp trước chúng. Do đó, lớp cuối cùng ở trong Dense Block không cần thiết phải học feature tổng hợp toàn bộ từ đầu tới cuối vì chúng khá là thừa thãi. Ảnh hưởng của các lớp giữa tới lớp cuối là không đáng kể nếu chúng kết nối mạnh mẽ với nhau từ giữa, và ngược lại, nếu chúng không kết nối mạnh mẽ với nhau từ giữa thì lớp cuối cần sự ảnh hưởng từ nhiều lớp trước đó.
Với việc có các Dense Connection ở các lớp giữa với nhau làm tăng đáng kể MAC, VoVNet muốn loại bỏ chúng, và tổng hợp các kết nối từ các lớp trước vào lớp cuối một lượt luôn. Ý tưởng của việc này tới từ hành vi của Dense Block 1, các layer khác nhau trong Dense Block sẽ học các feature khác nhau, không có tương quan cao tới nhau, từ đó, chỉ cần một kết nối từ toàn bộ các layer trước vào layer cuối là thông tin sẽ được tổng hợp một cách trọn vẹn.
One-shot Aggregation (Tổng hợp một phát)
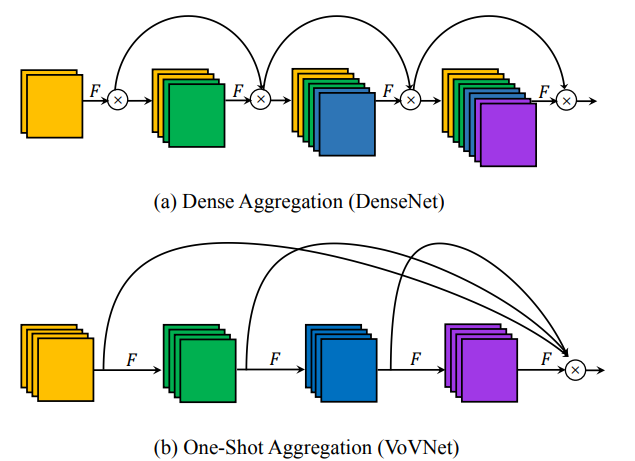
Với những phân tích bên trên, VoVNet tạo ra One-shot Aggregation (OSA) module (Hình 6) tổng hợp toàn bộ feature trong 1 phát. Mỗi lớp Conv sẽ có 2 đường kết nối, 1 đường thông thường nối từ lớp Conv này với lớp Conv ngay trước nó, 1 đường còn lại nối vào feature map cuối cùng. Lúc này, Conv layer trong OSA module sẽ nhận số channel đầu vào và số channel đầu ra là như nhau, làm giảm đáng kể MAC. Để kiểm chứng sự hiệu quả của OSA module so với Dense Connection, tác giả thử thay toàn bộ Dense Connection trong DenseNet bằng OSA module, tức là một Dense Block gồm 12 lớp Conv, mỗi lớp sinh ra feature maps với 12 channels, được kết nối với nhau bằng OSA module thay vì Dense Connection. Thử nghiệm với DenseNet-40 + OSA module đạt 93.6% accuracy trên CIFAR 10, chỉ giảm 1.2% accuracy so với DenseNet-40. Tác giả kiểm tra ảnh hưởng của từng kết nối của DenseNet-40 + OSA module (Hình 7).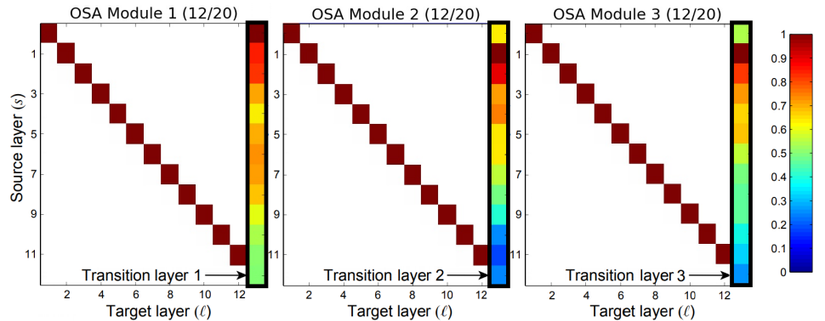
Nhìn vào Hình 7, ta có thể thấy các kết nối tới lớp cuối trong từng Dense Block đã được trải đều hơn, gần giống với hành vi trong Dense Block 1 của DenseNet. Điều này đã chứng minh giả thuyết phía trên của tác giả là đúng. Tuy nhiên, tác giả nhận thấy một điểm hơi ngược so với Dense Block 3 của DenseNet, đó là, các kết nối ở các lớp gần cuối tới lớp cuối trong Dense Block có vẻ không mạnh lắm. Vì vậy, tác giả thử rút ngắn Dense Block lại, chỉ sử dụng 5 lớp với 43 channels mỗi lớp. Lúc này, độ chính xác đã đạt gần ngang với DenseNet, 5.44% error rate so với 5.24% error rate của DenseNet. Tuy nhiên, độ hiệu quả về điện năng và tốc độ thì không thể bàn cãi. Thay Dense Connection bằng OSA module và sử dụng Dense Block ngắn (5 lớp), MAC giảm từ 3.7M xuống 2.5M. MAC giảm như vậy là do số channels đầu vào và channels đầu ra của một lớp Conv là như nhau. Đặc biệt, với các bài toán Object Detection hay Segmentation, yêu cầu ảnh đầu vào to hơn rất nhiều so với Classification, MAC càng giảm hơn nữa, chứng tỏ hiệu quả tuyệt vời của OSA module. Không chỉ cải thiện MAC, DenseNet + OSA module còn không thèm sử dụng 1×11 times 1 Conv trong Dense Block như DenseNet, đồng thời sử dụng ít lớp hơn, cho thấy việc tính toán với GPU đạt hiệu năng cực kì cao, tận dụng tốt cơ chế tính toán song song của GPU. Với OSA module làm nền tảng, VoVNet ra đời (Bảng 1).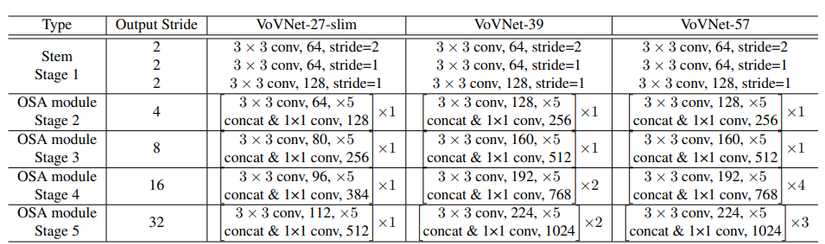
Kết quả
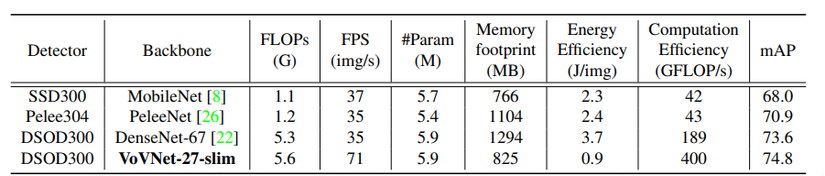
Các thử nghiệm
VoVNet có làm kha khá các thử nghiệm khác để chứng minh cho giả thuyết đề ra về sự hiệu quả của model. Tuy nhiên, mình sẽ chỉ trình bày 1 thử nghiệm duy nhất về 1×11 times 1 Conv vì mình thấy nó là thú vị nhất.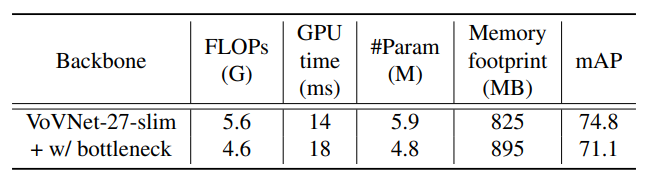
Tác giả thêm vào 1×11 times 1 Conv vào sau mỗi layer ở trong từng Stage của VoVNet, với đầu ra của 1×11 times 1 Conv chỉ là một nửa số channels so với đầu vào. Ta có thể thấy dù FLOPs và Params giảm một đống, nhưng Memory footprint lại tăng lên và thời gian inference trên GPU cũng tăng lên. Điều này chứng tỏ giả thuyết về 1×11 times 1 Conv là không hề tối ưu với GPU của tác giả là cực kì chính xác.
TL;DR
[W]hat
- Một backbone mới cực kì tối ưu về tốc độ cũng như là lượng điện tăng tiêu thụ
[W]hy
- Ừ thì ai mà chả muốn có một model nhẹ mà ít tốn điện :v
- Chứng tỏ rằng các nghiên cứu thiết kế các model nhẹ như MobileNet, ShuffleNet, Pelee,… là chưa tối ưu, và VoVNet mới là sự tối ưu trong thiết kế.
Ho[W]
- Nghiên cứu những điểm được và chưa được của DenseNet
- Thay Dense Connection bằng One-shot Aggregation, thay vì kết nối lằng nhằng toàn bộ các layer với nhau thì kết nối một phát vào layer cuối
Nguồn: viblo.asia