Giới thiệu
Bài toán semantic segmentation là một trong những bài toán rất quan trọng trong lĩnh vực computer vision, nhiệm vụ của bài toán là phân loại từng pixel trong ảnh. Sự phát triển của deep learning dẫn tới các bài toán segmentation thường dựa chủ yếu trên kiến trúc fully
convolutional networks (FCNs) và U-Net cùng với một số sự cải tiến. Để giải quyết bài toán semantic segmentation hiệu quả, các mô hình thường sử dụng một backbone mạnh để làm encoder và phần decoder sẽ cố gắng phối kết hợp các feature map ở nhiều mức khác nhau, cách làm này nhằm mục đích để tổng hợp được nhiều loại đặc trưng khác nhau, cả đặc trưng toàn cục và đặc trưng cục bộ, từ đó nâng cao hiệu năng của mô hình. Gần đây, rất nhiều những kiến trúc Transformer đang dần dần trở nên phổ biến trong các bài toán về computer vision, bài viết này sẽ giới thiệu sơ lược về kiến trúc và cách hoạt động của SegFormer – một mô hình đơn giản, hiệu quả và đạt hiệu năng cao trong bài toán semantic segmentation. Tóm gọn lại, SegFormer có những điểm đáng chú ý như sau:
- Đề xuất mạng Backbone mới là Mix Transformer (MiT) output ra các feature ở nhiều mức khác nhau, phù hợp với bài toán segmentation. Đây là điểm mấu chốt của phương pháp.
- Phần decoder để đưa ra segmentation map được thiết kế đơn giản, hiệu quả.
Phương pháp
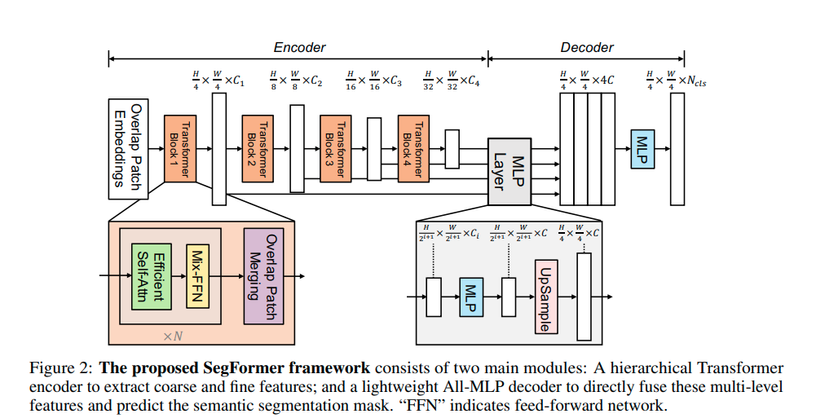
Hình ảnh trên được lấy trong paper gốc và mô tả kiến trúc tổng quát của SegFormer gồm 2 thành phần chính: (1) là kiến trúc Transformer phân tầng (hierarchical Transformer) để trích chọn đặc trưng và ouput ra multi scale feature, (2) là lightweight All-MLP decoder có nhiệm vụ phối kết hợp các multi scale feature từ backbone Transformer (1) và đưa ra kết quả segmentation.
- Mô hình nhận ảnh đầu vào có kích thước HxWx3, ảnh được chia thành các patch giống các mô hình Transformer khác, mỗi patch kích thước 4×4 (do bài toán segmentation yêu cầu dense prediction nên kích thước 1 patch sẽ nhỏ để “giữ lại chi tiết” cho từng pixel phục vụ cho việc phân loại ở bước sau), quá trình này tương ứng với bước Patch Embedding đầu tiên trên hình vẽ.
- Đưa ảnh qua backbone gồm 4 block, mỗi block output ra lần lượt các feature map có kích thước bằng 1/4, 1/8, 1/16, 1/32 so với ảnh đầu vào, đầu ra của block trước là đầu vào của block sau.
- Phần decoder là mạng MLP có nhiệm vụ phối kết hợp 4 output từ encoder để đưa ra segmentation mask có kích thước H/4 x W/4 x N_cls, sau đó sẽ được upsampling 4 lần theo H và W để đưa về ảnh gốc, N_cls là số class.
Encoder
Backbone của SegFormer có tên gọi Mix Transformer (MiT), gồm 5 phiên bản từ MiT B0 đến MiT B5, các phiên bản có kiến trúc giống nhau, chỉ khác về kích thước. MiT B0 là phiên bản nhẹ nhất, tốc độ nhanh nhất và MiT B5 là phiên bản nặng nhất, cho hiệu năng cao nhất. Nhìn chung, MiT có ý tưởng thiết kế giống Vision Transformer nhưng có vài điểm điều chỉnh để phù hợp hơn cho bài toán segmentation.
- Hierarchical Feature Representation: Không giống với Vision Transformer chỉ output ra 1 scale duy nhất, backbone MiT được thiết kế để output ra multi scale feature, từ đó tăng hiệu năng của bài toán segmentation. Như đã trình bày ở trên, MiT gồm 4 block và output của từng block là H2i+1×W2i+1×Cifrac{H}{2^{i+1}} times frac{W}{2^{i+1}} times C_{i} với Ci+1>CiC_{i+1} > C_{i} (số channel tăng dần sau mỗi block).
- Overlapped Patch Merging: Ở trong Vision Transformer, ảnh sẽ được chia thành các patch (16×16 pixel) và các patch đó không chồng lấn (overlap) lên nhau. Trong Mix Transformer encoder, ảnh sẽ được chia làm các patch có chồng lấn (overlap) lên nhau, cách chia các patch overlap lên nhau như này được tác giả giải thích là để “bảo tồn được thông tin về vị trí cục bộ giữa các patch”. Cách thực hiện chia ảnh thành các patch có chồng lấn (overlap) lên nhau được định nghĩa bằng 3 tham số K, S và P, trong đó K là kích thước 1 patch, S là stride – khoảng cách giữa 2 patch liền nhau, P là padding. Việc sinh các overlap patch này giống với cách trượt của kernel trong mạng CNN. Trong thực nghiệm, tác giả đặt K = 7, S = 4, P = 3 cho Block 1 và K = 3, S = 2, P = 1 cho Block 2, 3, 4.
- Efficient Self-Attention: Việc tính toán self attention như đã biết sẽ có nhiều head, mỗi head có 3 ma trận Q, K, V cùng kích thước (N, C), với N = WxH là độ dài của sequence khi đưa vào Transformer, công thức tính self attention như sau: Attention(Q,K,V)=Softmax(QKdhead)VAttention(Q, K, V) = Softmax(frac{QK^{}}{sqrt{d_{head}}})V
- Chi phí tính toán sẽ là O(N^2) và khi ảnh có độ phân giải cao sẽ không hợp lý. Giải pháp được đề xuất để khắc phục là sử dụng một hệ số R nhằm giảm số chiều của độ dài sequence:
-
K^=Reshape(NR,C⋅R)(K)hat{K} = Reshape(frac{N}{R}, Ccdot R)(K)
-
K=Linear(C⋅R,C)(K^)K = Linear(Ccdot R, C)(hat{K})
-
- Bằng cách này chi phí tính toán self attention giảm từ O(N2)O(N^{2}) còn O(N2R)O(frac{N^{2}}{R}). Thực nghiệm, hệ số R được đặt là 64, 16, 4, 1 tương ứng với 4 block.
- Chi phí tính toán sẽ là O(N^2) và khi ảnh có độ phân giải cao sẽ không hợp lý. Giải pháp được đề xuất để khắc phục là sử dụng một hệ số R nhằm giảm số chiều của độ dài sequence:
- Mix-FFN: Vision Transformer sử dụng positional encoding để lưu lại thông tin về vị trí từng pixel trong ảnh, tuy nhiên kích thước của positional encoding thường cố định và khi các ảnh train và test có kích thước khác nhau, ta phải thực hiện thuật toán nội suy (interpolate) để đưa kích thước positional encoding phù hợp với kích thước ảnh. Việc thêm positional encoding theo một cách “không thống nhất” như vậy vô tình gây nhiễu cho ảnh đầu vào và làm giảm hiệu năng của mô hình. SegFormer sử dụng Mix-FFN kết hợp Convolution với Feed forward network mà không cần positional encoding, công thức như sau:
-
xout=MLP(GELU(Conv3x3(MLP(xin)))+xinx_{out} = MLP(GELU(Conv_{3×3}(MLP(x_{in})))+x_{in}
- Trong đó, xinx_{in} là đầu ra của lớp self attention. Thực nghiệm chỉ ra sử dụng depth-wise convolution với kernel size = 3×3 là phù hợp về hiệu năng và hiệu quả tính toán.
-
Decoder
Theo tác giả, do kiến trúc Mix Transformer đã làm tốt phần việc encoder nên phần decoder chỉ cần sử dụng mạng MLP (hay dưới góc nhìn khác, MLP thực chất là 1 lớp Conv có kernel size = 1) để kết hợp các output feature từ encoder thay vì cần phải sử dụng các mô đun kết hợp đặc trưng phức tạp khác. Phần decoder đề xuất có tên gọi Lightweight All-MLP Decoder gồm 4 bước:
- Đầu tiên, 4 output feature từ 4 block MiT sẽ được đưa qua mạng MLP để có cùng số channel.
- Sau đó, 4 output feature đấy sẽ được upsampling về kích thước (H/4, W/4) và được concat lại.
- Kế tiếp là một mạng MLP giảm số chiều về C = 256
- Cuối cùng lại là 1 mạng MLP, nhận đầu vào 256 chiều và trả về số chiều bằng số class của bài toán. Kích thước trả về cuối cùng là (H/4, W/4, N_cls) sau đó sẽ được upsampling 4 lần để đưa về kích thước ảnh gốc.
Quá trình này có thể mô tả bằng công thức sau đây:
-
F^i=Linear(Ci,C)(Fi),∀i=1,2,3,4hat{F}_{i} = Linear(C_{i}, C)(F_{i}), forall i = 1, 2, 3, 4
-
F^i=Upsample(H4,W4)(F^i),∀i=1,2,3,4hat{F}_{i} = Upsample(frac{H}{4}, frac{W}{4})(hat{F}_{i}), forall i = 1, 2, 3, 4
-
F=Linear(4C,C)(Concat(F^i)),∀iF = Linear(4C, C)(Concat(hat{F}_{i})), forall i
-
M=Linear(C,Ncls)(F)M = Linear(C, N_{cls})(F)
Effective Receptive Field Analysis
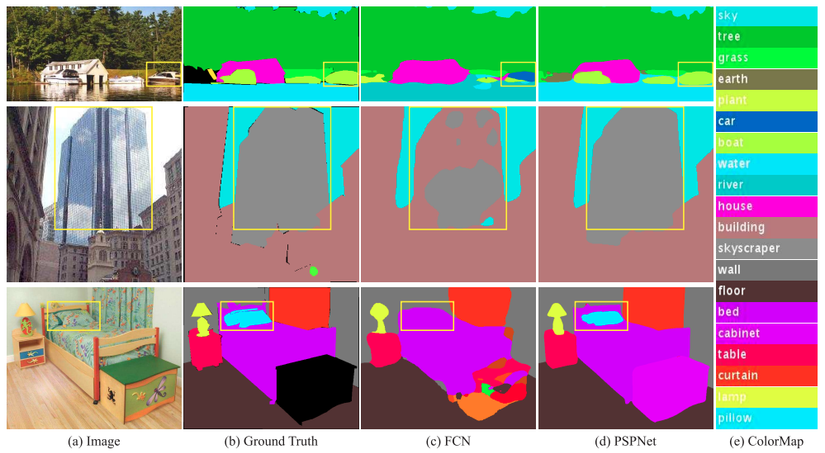
Đối với bài toán segmentation, việc mở rộng receptive field là vô cùng quan trọng. Hình minh họa ở trên trích từ paper Pyramid Scene Parsing Network, tại ảnh thứ nhất, dễ thấy mô hình không có receptive field tốt sẽ nhận nhầm con thuyền (boat) với ô tô (car), còn mô hình có receptive field tốt sẽ nắm bắt được thông tin ngữ nghĩa của bức ảnh tốt hơn, mô hình sẽ hiểu quang cảnh là vùng nước và class cần nhận dạng ở đây là con thuyền chứ không phải ô tô.
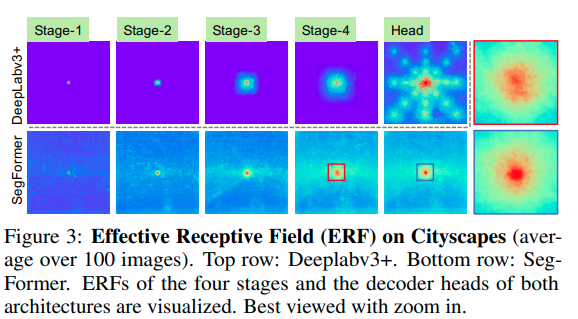
Hình minh họa trên trích từ paper SegFormer, tác giả vẽ lại receptive field của SegFormer và một mô hình segmentation khác là DeepLabv3+. Dễ thấy receptive field của SegFormer tại output từ các encoder block lớn hơn nhiều so với DeepLab, điều này lý giải tại sao tác giả không cần thiết kế phần decoder phức tạp mà chỉ sử dụng mạng MLP đơn giản cũng đạt được hiệu năng tốt, còn đối với mô hình DeepLab, receptive field tại phần encoder tương đối kém và phải sử dụng decoder “phức tạp hơn” nhằm kết hợp các đặc trưng ở nhiều mức khác nhau, từ đó mới có được receptive field tốt.
Tại ô vuông nhỏ ở Stage 4 và Head của SegFormer trên ảnh, ta có thể nhận thấy có sự khác biệt giữa ô vuông màu đỏ (Stage 4) và xanh (Head), điều này chứng minh việc phần decoder đơn giản sử dụng mạng MLP làm rất tốt phần việc của mình đó là phối kết hợp thêm đặc trưng cục bộ tại những Stage đầu và đặc trưng toàn cục tại Stage 4. Thực nghiệm cũng chỉ ra nếu chỉ sử dụng Stage 4 mà không phối kết hợp các đặc trưng từ Stage 1, 2, 3 thì kết quả kém hơn (chi tiết trong paper gốc).
Trên đây là phần giới thiệu ngắn gọn về SegFomer, hy vọng sẽ giúp ích cho các bạn. Nếu có câu hỏi hoặc bài viết có sai sót, các bạn vui lòng để lại comment ở phần bình luận. Cảm ơn các bạn đã đọc bài!
Nguồn: viblo.asia