I. Mở đầu:
Một ngày đẹp trời lướt lướt trên nhóm tuyển dụng CNTT nọ thì thấy có job thu thập dữ liệu comments trên các Fanpage lớn, chắc là crawl data về làm AI rồi nè ( Adobe Illustrator ^^) , hôm nay rảnh rỗi và cũng từng làm mấy con Crawler như thế này rồi nên mình viết bài này để hướng dẫn mọi người có thể tự mình làm ra con tool đơn giản, xịn xò, crawl được data trên FACEBOOK phục vụ nhu cầu trong công việc và học tập nhé.
II. Tech sử dụng :
- [Selenium] : Đây là 1 framework kiểm thử tự động ( Automation Testing ) cho phép chúng ta điều khiển trình duyệt một cách tự động theo kịch bản có sẵn, mô phỏng hành vi, thao tác trên trình duyệt. Nếu mọi người chưa tiếp cận thì có thể tìm hiểu sơ qua rồi tiếp tục phần dưới nhé ^^
- [Python] – Sử dụng ngôn ngữ lập trình Python
III. Cài đặt Selenium trên Linux:
- Precondition :Máy đã cài python3 và pip3 nhé
- Step 1 – Install Selenium
pip3 install selenium
- Step 2 – Install Google Chrome
sudo curl -sS -o - https://dl-ssl.google.com/linux/linux_signing_key.pub | apt-key add
sudo echo "deb [arch=amd64] http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google-chrome.list
sudo apt-get -y update
sudo apt-get -y install google-chrome-stable
- Step 3 – Install ChromeDriver
wget https://chromedriver.storage.googleapis.com/2.41/chromedriver_linux64.zip
unzip chromedriver_linux64.zip
You can find the latest ChromeDriver on its official download page. Now execute below commands to configure ChromeDriver on your system.
sudo mv chromedriver /usr/bin/chromedriver
sudo chown root:root /usr/bin/chromedriver
sudo chmod +x /usr/bin/chromedriver
Sau khi cài xong Selenium Python thì triển luôn nhé:
IV. Kịch bản:
- Tự động mở trình duyệt Chrome, login vào FACEBOOK bằng COOKIE (Mọi người tham khảo bài viết này để lấy cookie trên FB nhé ).
- Vào một Fanpage bất kỳ, crawl id bài viết trên page.
- Vào từng bài viết dựa vào id đã crawl được.
- Tiến hành Crawl nội dung comment của bài viết.
IV. Viết Script:
1. Tự động mở trình duyệt Chrome, login vào FACEBOOK bằng COOKIE:
- Viết một đoạn script nhỏ nhỏ để mở trình duyệt chrome và tự động login vào Facebook bằng cookie nhé.
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import os
from time import sleep
def initDriver():
CHROMEDRIVER_PATH = '/usr/bin/chromedriver'
WINDOW_SIZE = "1920,1080"
chrome_options = Options()
#chrome_options.add_argument("--headless")
chrome_options.add_argument("--window-size=%s" % WINDOW_SIZE)
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument("--disable-blink-features=AutomationControllered")
chrome_options.add_experimental_option('useAutomationExtension', False)
prefs = {"profile.default_content_setting_values.notifications": 2}
chrome_options.add_experimental_option("prefs", prefs)
chrome_options.add_argument("--start-maximized") # open Browser in maximized mode
chrome_options.add_argument("--disable-dev-shm-usage") # overcome limited resource problems
chrome_options.add_experimental_option("excludeSwitches", ["enable-automation"])
chrome_options.add_argument('disable-infobars')
driver = webdriver.Chrome(executable_path=CHROMEDRIVER_PATH,
options=chrome_options
)
return driver
def convertToCookie(cookie):
try:
new_cookie = ["c_user=", "xs="]
cookie_arr = cookie.split(";")
for i in cookie_arr:
if i.__contains__('c_user='):
new_cookie[0] = new_cookie[0] + (i.strip() + ";").split("c_user=")[1]
if i.__contains__('xs='):
new_cookie[1] = new_cookie[1] + (i.strip() + ";").split("xs=")[1]
if (len(new_cookie[1].split("|"))):
new_cookie[1] = new_cookie[1].split("|")[0]
if (";" not in new_cookie[1]):
new_cookie[1] = new_cookie[1] + ";"
conv = new_cookie[0] + " " + new_cookie[1]
if (conv.split(" ")[0] == "c_user="):
return
else:
return conv
except:
print("Error Convert Cookie")
def loginFacebookByCookie(driver ,cookie):
try:
cookie = convertToCookie(cookie)
print(cookie)
if (cookie != None):
script = 'javascript:void(function(){ function setCookie(t) { var list = t.split("; "); console.log(list); for (var i = list.length - 1; i >= 0; i--) { var cname = list[i].split("=")[0]; var cvalue = list[i].split("=")[1]; var d = new Date(); d.setTime(d.getTime() + (7*24*60*60*1000)); var expires = ";domain=.facebook.com;expires="+ d.toUTCString(); document.cookie = cname + "=" + cvalue + "; " + expires; } } function hex2a(hex) { var str = ""; for (var i = 0; i < hex.length; i += 2) { var v = parseInt(hex.substr(i, 2), 16); if (v) str += String.fromCharCode(v); } return str; } setCookie("' + cookie + '"); location.href = "https://mbasic.facebook.com"; })();'
driver.execute_script(script)
sleep(5)
except:
print("Error login")
def checkLiveCookie(driver, cookie):
try:
driver.get('https://mbasic.facebook.com/')
sleep(1)
driver.get('https://mbasic.facebook.com/')
sleep(2)
loginFacebookByCookie(driver ,cookie)
return checkLiveClone(driver)
except:
print("check live fail")
cookie = '' // điền cookie ở đây
driver = initDriver()
isLive = checkLiveCookie(driver, cookie)
2. Vào một Fanpage bất kỳ, crawl id bài viết trên page.:
- Viết một đoạn script nhỏ để vào Fanpage bất kỳ, crawl id bài viết trên đó, và lưu vào 1 file nhé:

def getPostIds(driver, filePath = 'posts.csv'):
allPosts = readData(filePath)
sleep(2)
driver.execute_script("window.scrollTo(0, document.body.scrollHeight)")
shareBtn = driver.find_elements_by_xpath('//a[contains(@href, "/sharer.php")]')
if (len(shareBtn)):
for link in shareBtn:
postId = link.get_attribute('href').split('sid=')[1].split('&')[0]
if postId not in allPosts:
print(postId)
writeFileTxt(filePath, postId)
def getnumOfPostFanpage(driver, pageId, amount, filePath = 'posts.csv'):
driver.get("https://touch.facebook.com/" + pageId)
while len(readData(filePath)) < amount:
getPostIds(driver, filePath)
driver = initDriver()
isLive = checkLiveCookie(driver, cookie)
if (isLive):
getnumOfPostFanpage(driver, 'FcThuyTien', 100, 'posts.csv') # Crawl 100 post id trên Fanpage chị Thủy Tiên nhé
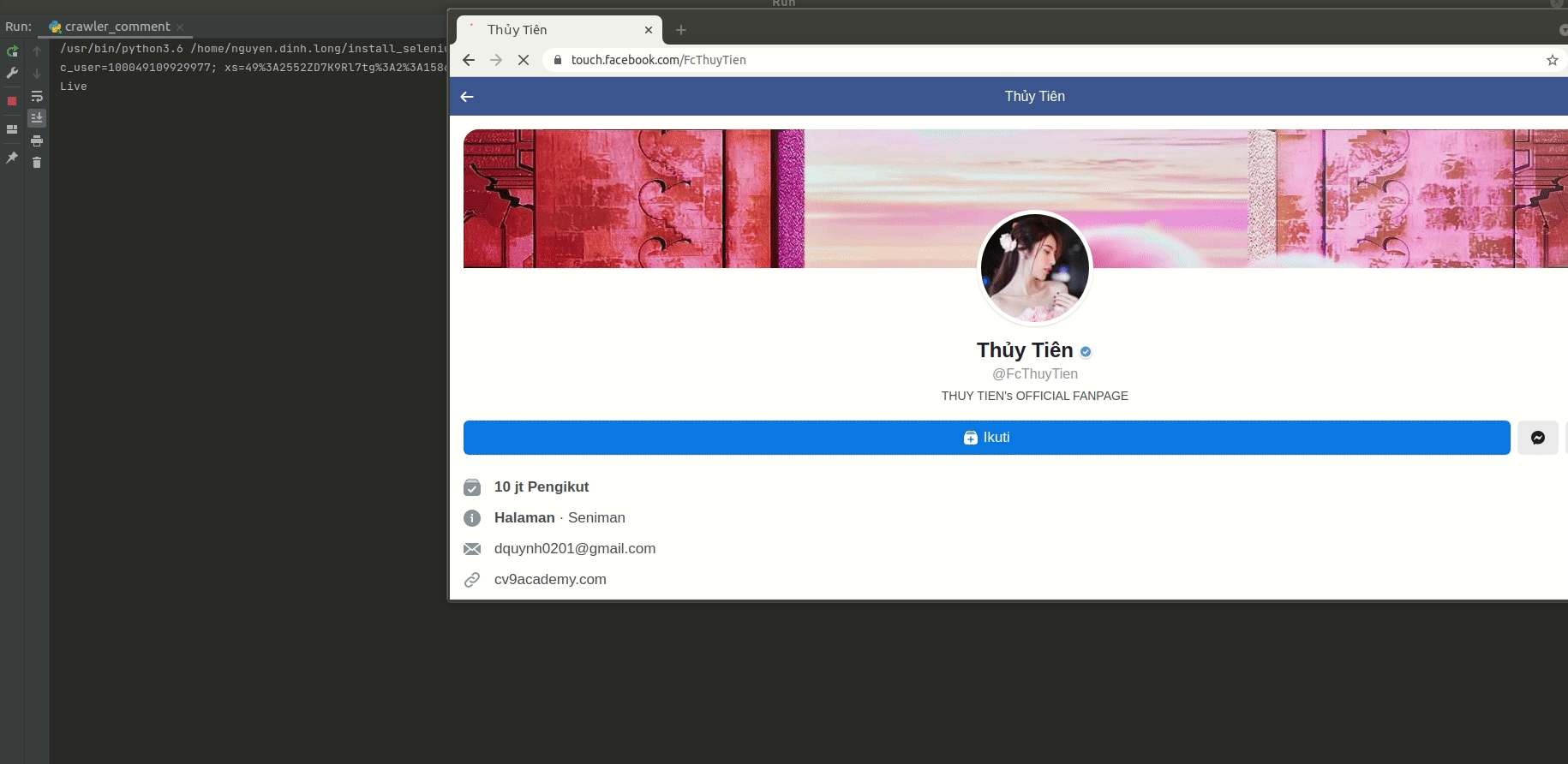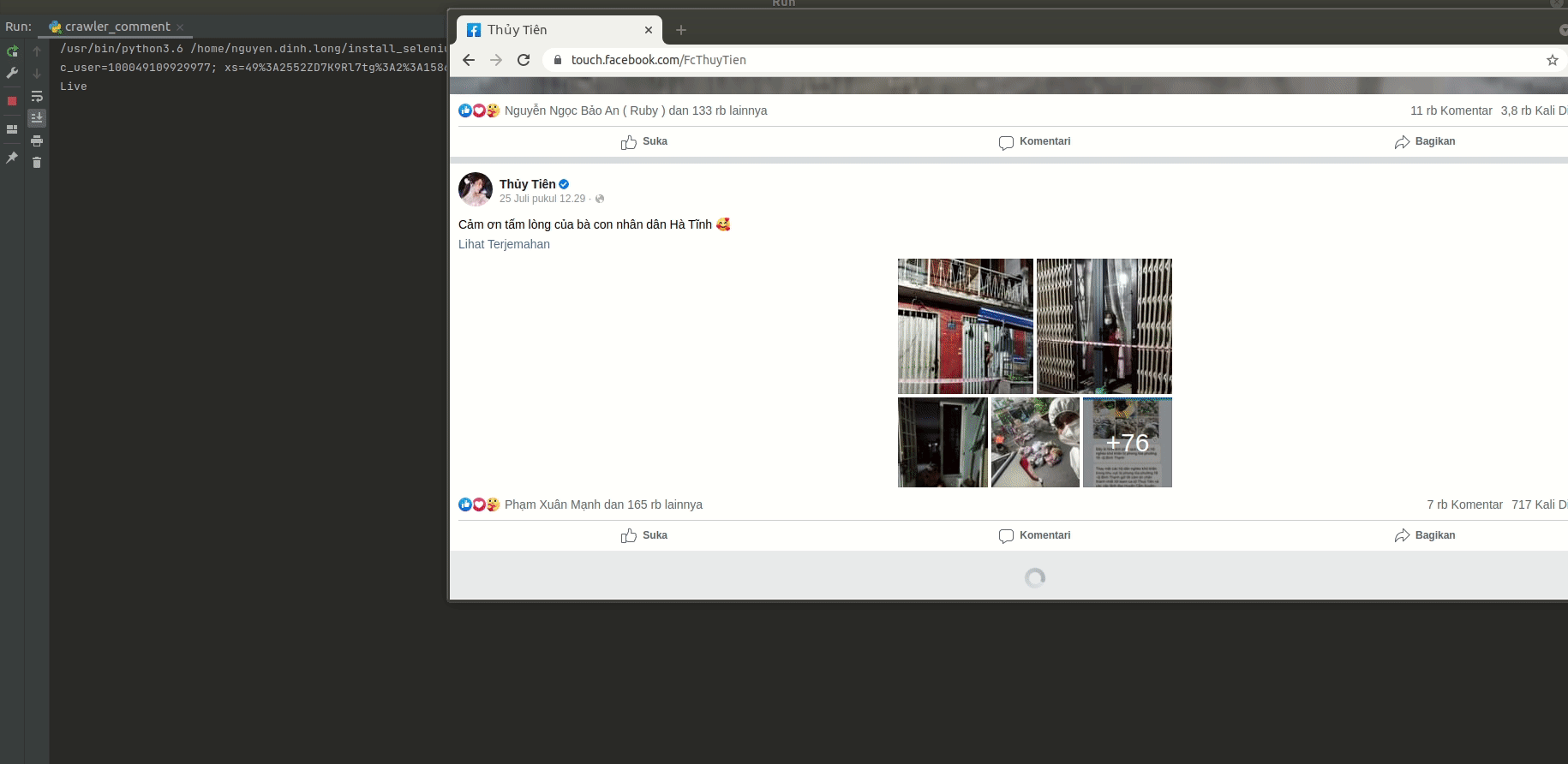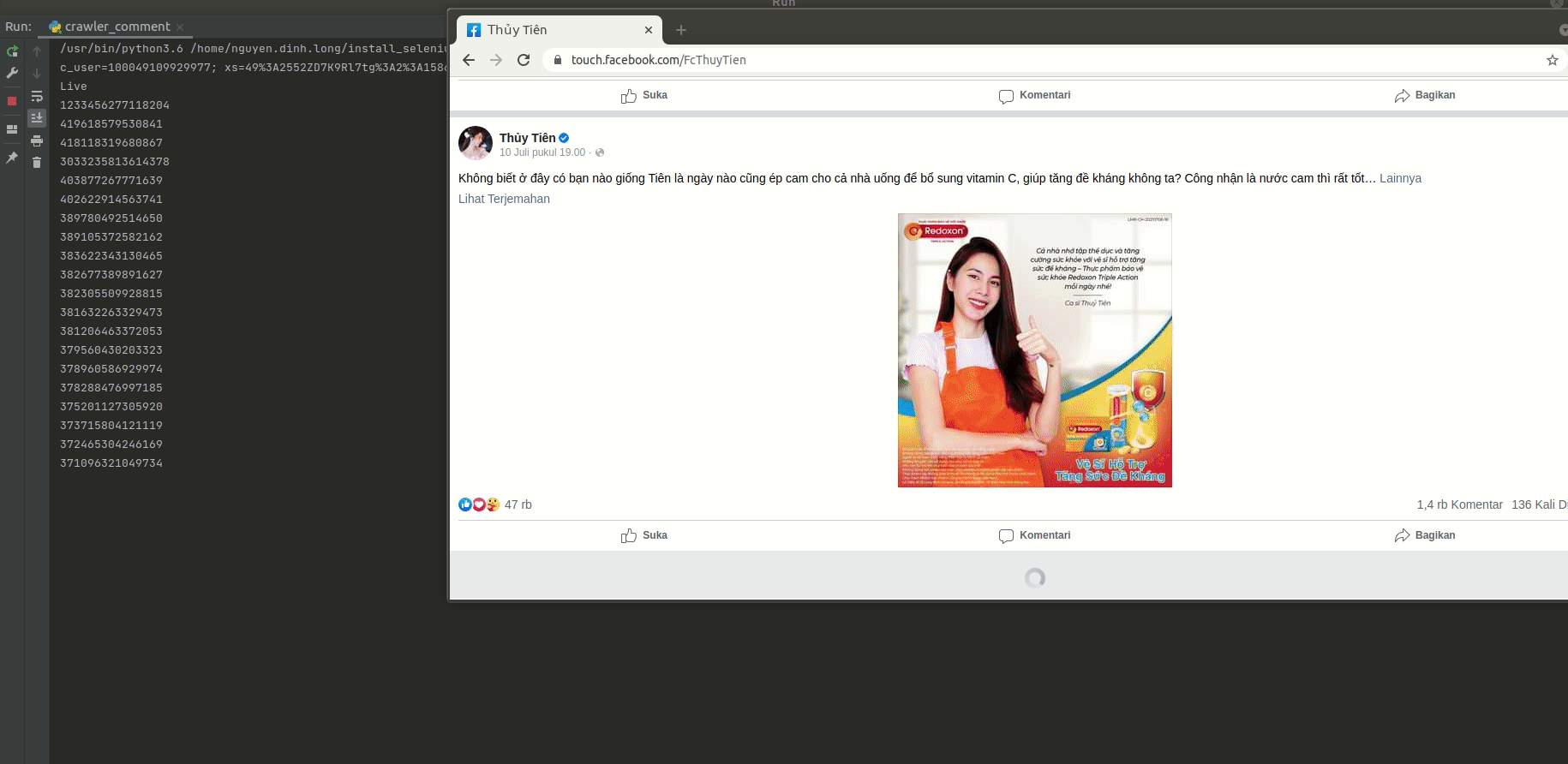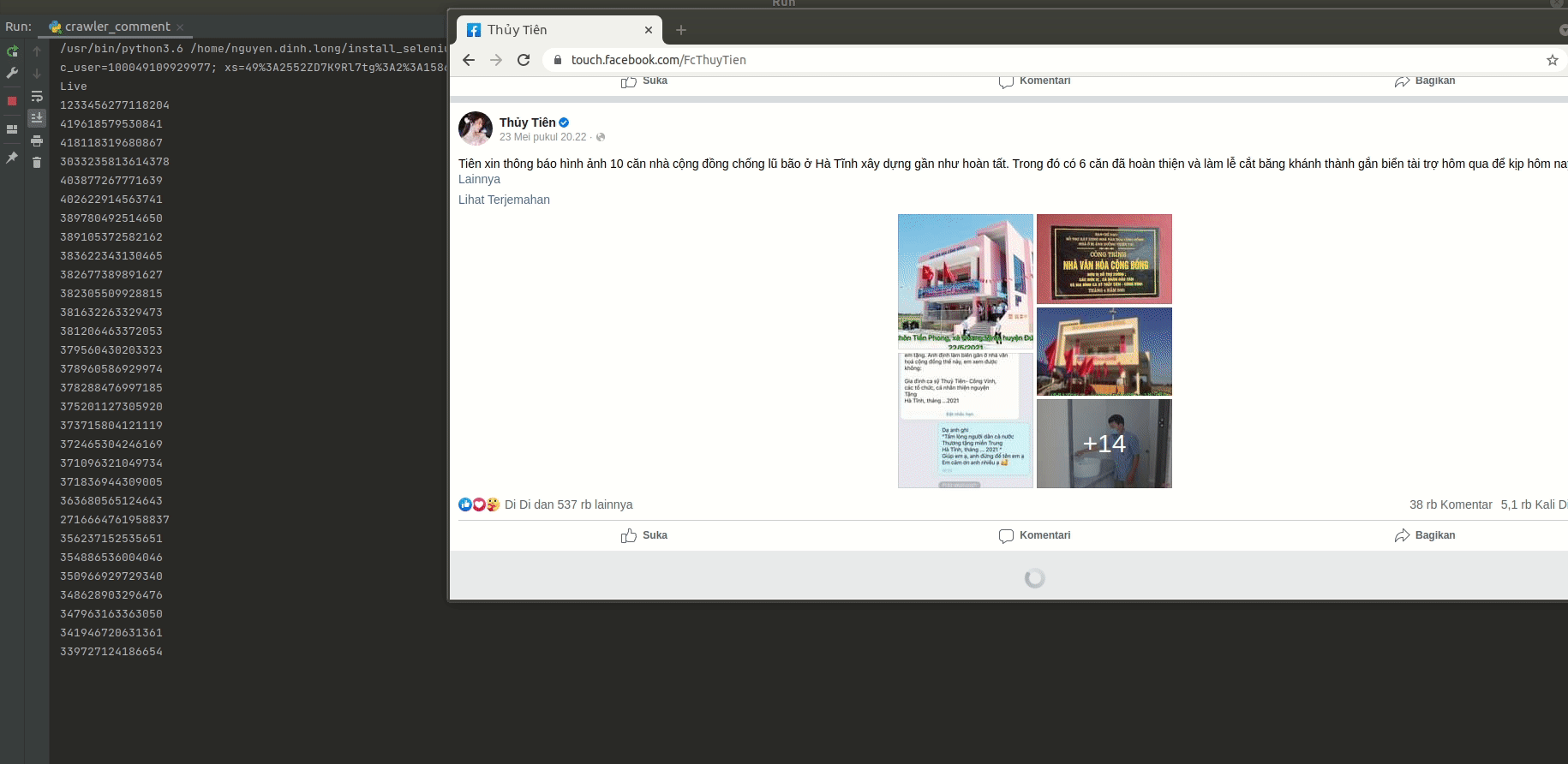
3. Tiến hành Crawl nội dung comment của các bài viết trên Fanpage.
- Đoạn Script mà mình viết dưới đây sẽ crawl nội dung các comment trên từng bài viết nhé:

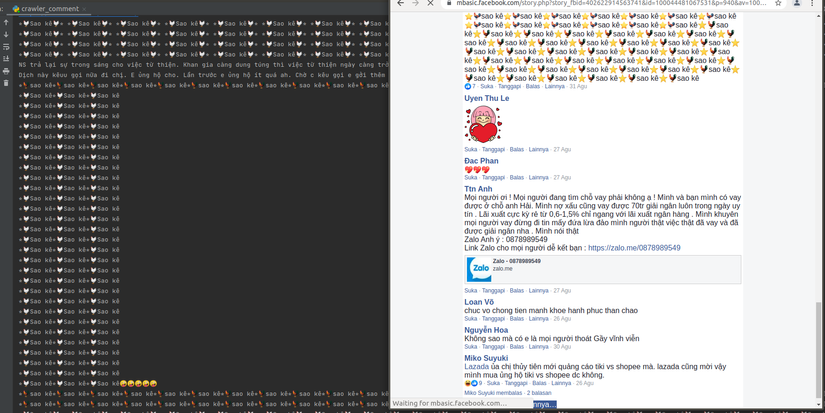
def getContentComment(driver): # get nội dung comment
try:
links = driver.find_elements_by_xpath('//a[contains(@href, "comment/replies")]')
ids = []
if (len(links)):
for link in links:
takeLink = link.get_attribute('href').split('ctoken=')[1].split('&')[0]
textCommentElement = driver.find_element_by_xpath(('//*[@id="' + takeLink.split('_')[1] + '"]/div/div[1]'))
if (takeLink not in ids):
print(textCommentElement.text)
writeFileTxt('comments.csv', textCommentElement.text)
ids.append(takeLink)
return ids
except:
print("error get link")
def getAmountOfComments(driver,postId, numberCommentTake): # truyền vào số lượng comment cần lấy trên mỗi post nhé
try:
driver.get("https://mbasic.facebook.com/" + str(postId))
sumLinks = getContentComment(driver)
while(len(sumLinks) < numberCommentTake):
try:
nextBtn = driver.find_elements_by_xpath('//*[contains(@id,"see_next")]/a')
if (len(nextBtn)):
nextBtn[0].click()
sumLinks.extend(getContentComment(driver))
else:
break
except:
print('Error when cralw content comment')
except:
print("Error get cmt")
if (isLive):
getnumOfPostFanpage(driver, 'FcThuyTien', 100, 'posts.csv') # Crawl 100 post id trên Fanpage chị Thủy Tiên nhé
for postId in readData('posts.csv'):
getAmountOfComments(driver, postId, 1000)
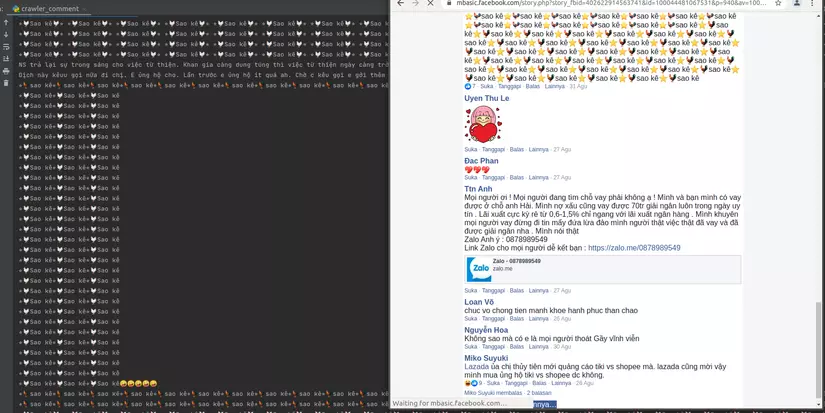
V. Thành quả:
-
Full HD CLIP 1080 ở đây nhé:
-
Ở đây là toàn bộ script và vì không có thời gian rảnh để treo máy nên mình crawl được hơn 200 nghìn comments, hi vọng sẽ giúp ích cho các bạn trong quá trình làm việc và học tập (yay^^)
Code : github
Data: Vào đây
Cảm ơn mọi người đã ghé đọc bài viết ^^
Nguồn: viblo.asia