1. Giới thiệu
Tiếp tục về YOLO series sẽ là sự giới thiệu và trình bày về YOLOv3. YOLOv3 đưa ra những sự điều chỉnh nhỏ so với phiên bản trước đó, không có điều gì thực sự mang tính đột phá hay thú vị cả. Điều này được thể hiện rõ ràng qua tiêu đề bài báo của nó: ”YOLOv3: An Incremental Improvement”.
YOLOv3 hầu hết lấy các ý tưởng từ những công trình khác. Ngoài ra, nó cũng huấn luyện một classifier network mới mang lại kết quả tốt hơn so với những mạng cũ trước đó.
2. Chi tiết
2.1. Dự đoán bounding box
YOLOv2 đều dự đoán hai việc trên sử dụng hàm sigmoid. YOLOv3 sẽ dự đoán bounding box với objectness score bằng các phương pháp khác nhau.
-
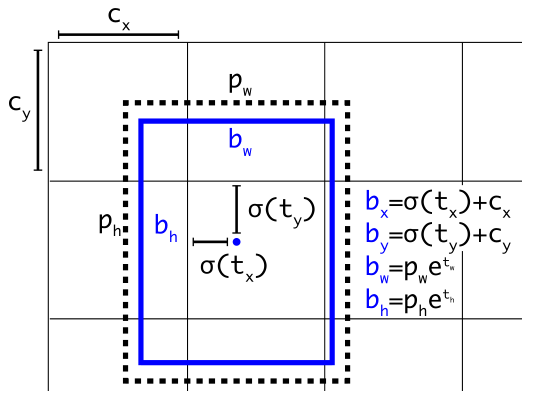
YOLOv3 vẫn tiếp tục dự đoán bounding box giống YOLOv2. Xem lại hình dưới đây ở YOLOv2:
![]()
-
YOLOv3 dự đoán objectness score cho mỗi bounding box bằng logistic regression thay vì hàm sigmoid của YOLOv2. Ý tưởng này được lấy từ Faster R-CNN:
- Giá trị này sẽ bằng 1 (positive label) nếu anchor box dùng để dự đoán bounding box đó có độ trùng khớp (overlap) so với ground truth box lớn hơn tât cả những bounding box khác.
- Nếu một bounding box không phải là tốt nhất nhưng có độ trùng khớp với ground truth box lớn hơn một ngưỡng (threshold) nào đó, thì ta sẽ bỏ qua dự đoán bounding box đó trong quá trình huấn luyện. YOLOv3 sử dụng threshold bằng 0.5
- Ngược lại, giá trị này sẽ bằng 0 (negative label) nếu anchor box dùng để dự đoán bounding box đó có giá trị IoUIoU nhỏ hơn ngưỡng 0.5.
Ngoài ra, YOLOv3 còn thực hiện một số điều chỉnh nhỏ so với Faster R-CNN:
- Chỉ gán một anchor box cho mỗi ground truth object.
- Nếu một anchor box không được gán cho bất cứ ground truth object nào thì nó sẽ không gây ra mất mát (loss) gì cho giá trị tọa độ hay dự đoán class mà chỉ gây ra mất mát cho objectness (có object hay không).
2.2. Dự đoán class
Mỗi bounding box sẽ dự đoán các class sử dụng phương pháp Multilabel Classification. Hàm softmax không còn được sử dụng nữa do nhận thấy nó không mang lại performance tốt. Thay vào đó, independent logistic classifiers được sử dụng thay cho hàm softmax.
Trong quá trình huấn luyện, hàm mất mát Binary Cross-Entropy được sử dụng cho việc dự đoán các class.
Việc làm trên sẽ mang lại hiệu quả khi ta chuyển đến các tập dữ liệu phức tạp hơn như Open Images Dataset (OID). Trong tập dữ liệu này, có rất nhiều overlapping labels (tức một object có thể có nhiều hơn một label (class), ví dụ như Women và Person, Dog và Animal). Hàm softmax giả định rằng mỗi box chỉ có duy nhất một class, và nó sẽ fail trong trường hợp overlapping labels ở trên. Do đó, việc sử dụng phương pháp multilabel sẽ mô hình hóa dữ liệu tốt hơn.
2.3. Dự đoán ở các độ phân giải khác nhau
YOLOv3 dự đoán các bounding box tại 3 scale (độ phóng đại) khác nhau của feature map.
Model sẽ trích xuất features từ các scale này sử dụng cơ chế tương tự như mạng Feature Pyramid Networks (FPN). Cơ chế này được mô tả như sau:
-
Từ base feature extractor, một vài Convolutional Layers được thêm vào. Convolutional layer cuối cùng sẽ dự đoán một tensor 33 chiều chứa thông tin về bounding box, objectness, và class predictions.
-
Tiếp theo, ta lấy feature map từ 2 layer trước đó và upsample nó lên gấp đôi. Ta cũng lấy một feature map từ lớp trước nữa trong network và hợp nhất nó với feature map được upsample ban nãy, sử dụng phép nối (concatenation). Điều này giúp ta thu được:
- Nhiều thông tin ngữ nghĩa (semantic information) có ý nghĩa hơn từ upsampled feature map
- Thông tin có độ chi tiết hơn (finer-grained information) từ feature map ở lớp trước đó.
Sau đó, ta thêm một vài Convolutional Layers để xử lý feature map thu được từ phép nối ở trên, cho ra kết quả dự đoán là một tensor tương tự như ở trên, nhưng với kích thước được tăng gấp đôi.
-
Ta thực hiện bước tương tự như trên một lần nữa để dự đoán bounding box ở scale cuối cùng. Như vậy, dự đoán cho scale thứ 3 sẽ được hưởng lợi từ tất cả các tính toán trước đó cũng như các đặc trưng chi tiết (fine-grained features) từ các layer trước đó của network.
Trong thí nghiệm với tập dữ liệu COCO, YOLOv3 dự đoán 3 bounding box tại mỗi scale, vì thế nên tensor dự đoán sẽ có kích thước là N×N×[3×(4+1+80)]N times N times [3 times (4 + 1 + 80)], trong đó:
- 44 tọa độ của bounding box: tx,ty,tw,tht_x, t_y, t_w, t_h
- 11 objectness score
- 8080 dự đoán class
2.4. Feature Extractor
YOLOv3 sử dụng một network mới để thực hiện feature extraction – được gọi là Darknet-53 – bao gồm 53 Convolutional Layers, lớn hơn đáng kể so với Darknet-19 của YOLOv2 – chỉ bao gồm 19 Convolutional Layers. Network mới này là một phương pháp lai (hybrid) giữa Darknet-19 của YOLOv2 và Residual Network. Darknet-53 sử dụng các Convolutional Layers kích thước 3×33 times 3 và 1×11 times 1 kế tiếp nhau, và thêm vào một số shortcut connections.
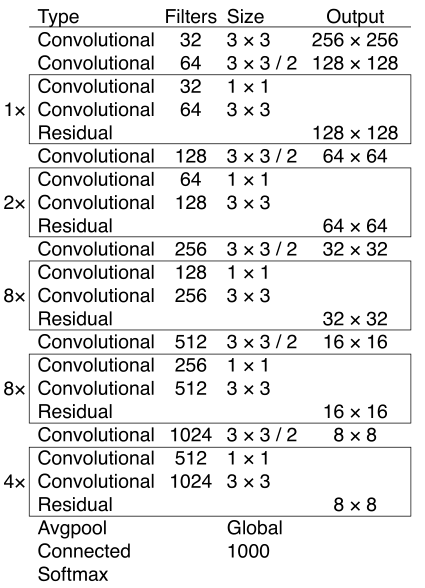
Darknet-53 mạnh hơn nhiều so với Darknet-19 của YOLOv2 nhưng vẫn hiệu quả (efficient) hơn ResNet-101 và ResNet-152. Hình dưới đây với kết quả trên tập dữ liệu ImageNet:
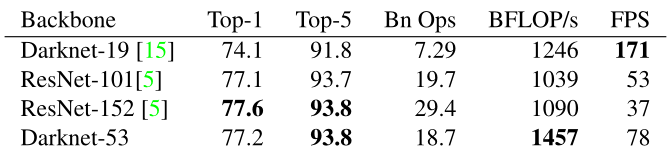
Nhìn vào hình trên, có thể thấy được Darknet-53 đạt được kết quả ngang hàng với các classifiers hàng đầu khác (ResNet-101 và ResNet-152), nhưng với số lượng phép toán (Bn Ops) ít hơn và tốc độ (BFLOP/s) tốt hơn. Cụ thể:
- Darknet-53 có performance tốt hơn ResNet-101 và nhanh hơn 1.5 lần.
- Darknet-53 có performance ngang với ResNet-152 và nhanh hơn 2 lần.
Darknet-53 cũng đạt được BFLOP/s lớn nhất (billions floating point operations per second) (1457 – cột 3 hàng 3). Điều này cho thấy network structure của Darknet-53 sử dụng GPU tốt hơn, giúp cho việc đánh giá tốt hiệu quả hơn và nhanh hơn.
3. Kết quả
Dựa vào bảng dưới đây, ta đưa ra một số nhận xét sau đây:
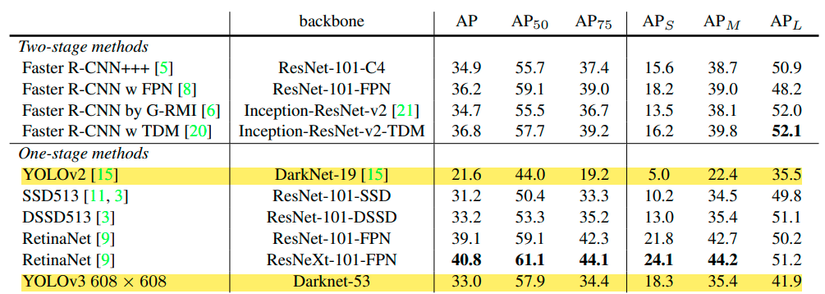
- YOLOv3 cho kết quả vượt trội so với YOLOv2 ở tất cả các metric.
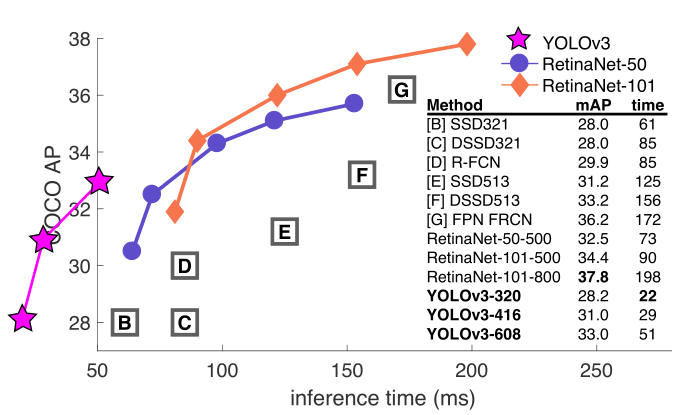
- Trên metric APAP: YOLOv3 cho kết quả ngang hàng với 2 biến thể của SSD (33.0 so với 31.2, 33.2) nhưng nhanh hơn 3 lần. Tuy nhiên, kết quả vẫn khá xa so với các model khác, ví dụ như RetinaNet (33.0 so với 40.8), nhưng tốc độ lại nhanh hơn khoảng 3.8 lần.
- Trên metric AP50AP_{50}: YOLOv3 tốt hơn hẳn so với các biến thể của SSD và ngang hàng với RetinaNet. Điều này cho thấy rằng YOLOv3 rất giỏi trong việc tạo ra các bounding box có độ khớp vừa phải với object.
- Tuy nhiên, khi giá trị IoUIoU cao hơn (AP75)AP_{75}), thì performance giảm đáng kể, điều này cho thấy YOLOv3 gặp khó khăn trong việc căn chỉnh các bounding box sao cho khớp một cách hoàn hảo với object.
- APSAP_S: với việc dự đoán trên nhiều scale khác nhau, YOLOv3 cho kết quả khá cao trong việc dự đoán các vật thể nhỏ, gần tiếp cận được đến RetinaNet. (18.3 so với 24.1).
- APMAP_M và APLAP_L: performance kém hơn so với tất cả các model khác (trừ YOLOv2) trong việc dự đoán các object kích thước vừa và lớn.
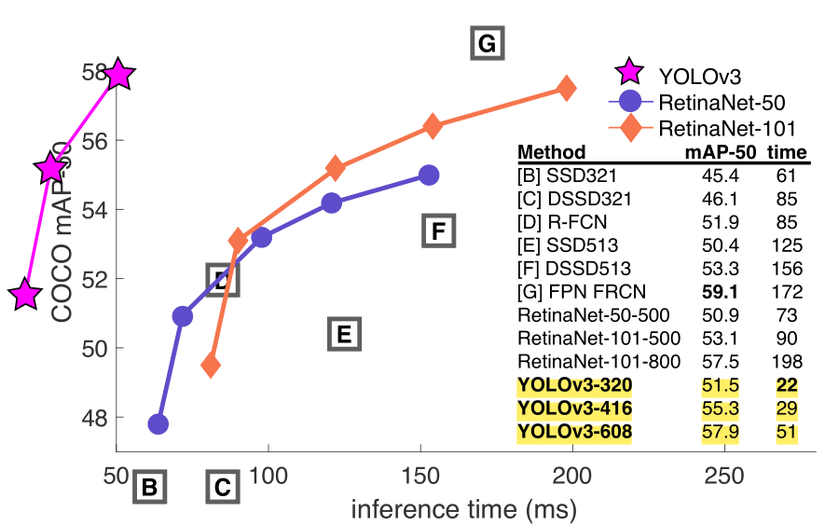
Hình trên là đồ thị accuray-speed của các model trên metric AP50AP_{50}. Ta có thể thấy ngay rằng YOLOv3 nhanh hơn và tốt hơn hẳn các model khác.
4. Kết luận
YOLOv3 là một detector tốt, tốt hơn hẳn so với YOLOv2 như ta vừa phân tích ở trên. Nó cho kết quả rất tốt trên metric AP50AP_{50}. Mặc dù vậy, khi nhìn vào bảng phân tích ở trên, ta thấy rõ ràng YOLOv3 cần phải cải thiện rất nhiều để có thể vượt trội hơn các model khác.
5. Tài liệu tham khảo
Nguồn: viblo.asia