Để một mô hình học máy có thể khái quát hóa tốt, người ta cần đảm bảo rằng các quyết định của nó được hỗ trợ bởi các mẫu có ý nghĩa trong dữ liệu đầu vào. Tuy nhiên, điều kiện tiên quyết là để mô hình có thể tự giải thích, ví dụ: bằng cách làm nổi bật các đặc trưng đầu vào mà nó sử dụng để hỗ trợ dự đoán của nó thông qua một số phương pháp chẳng hạn như Layer-Wise Relevance Propagation. Mặc đã từng viết một bài liên quan đến chủ đề này với tên gọi Giải thích cách thức mô hình hoạt động với Layer-Wise Relevance Propagation nhưng có vẻ nói không hợp với thị hiếu của đại đa số đọc giả cho lắm tại vì toàn chữ là chữ cho nên tôi xin hân hạnh mang đến cho quý đọc giả bài viết cũng về Layer-Wise Relevance Propagation nhưng mà ít chữ và nhiều ví dụ hơn.
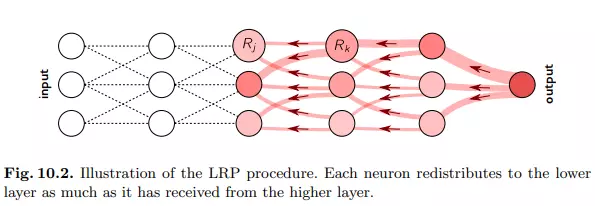
Layer-Wise Relevance Propagation
Tuy vậy trước khi bắt đầu, ta nhắc lại một chút về khái niệm của phương pháp này. Dành cho các quý đọc giả chưa có cơ hội tiếp xúc thì Layer-Wise Relevance Propagation (LRP) là một kỹ thuật giải thích áp dụng cho các mô hình có cấu trúc như mạng nơ-ron, trong đó đầu vào có thể là ví dụ: hình ảnh, video hoặc văn bản. LRP hoạt động bằng cách truyền ngược dự đoán f(x)f (x) trong mạng nơron, bằng các quy tắc lan truyền cục bộ được thiết kế có chủ đích.
Gọi jj và kk là các nơron ở hai lớp liên tiếp của mạng nơ-ron. Việc truyền điểm liên quan (Rk)k(R_k)_k tại một lớp nhất định lên các nơ-ron của lớp dưới đạt được bằng cách áp dụng quy tắc:
Rj=∑zjk∑jzjkRk.R_j =sum frac{z_{jk}}{sum_j z_{jk}} R_k.
Trong đó, zjkz_{jk} mô hình hóa mức độ mà nơron jj đã đóng góp để làm cho nơron kk có liên quan trong khi việc sử dụng mẫu số là tổng zjkz_{jk} với mọi jj được thực hiện nhằm đảm bảo việc bảo toàn thông tin. Quá trình truyền kết thúc khi đã truyền đến các đặc trưng đầu vào. Nếu sử dụng quy tắc trên cho tất cả các nơron trong mạng, ta có thể dễ dàng xác minh thuộc tính bảo toàn theo lớp ∑jRj=∑kRksum_j R_j = sum_k R_k và bằng cách mở rộng thuộc tính bảo toàn toàn cục ∑iRi=f(x)sum_i R_i = f (x).
Và thế là hết, để biết thêm chi tiết, quý đọc giả có thể bài viết toàn chữ trước đây của tôi với tên gọi Giải thích cách thức mô hình hoạt động với Layer-Wise Relevance Propagation
Sử dụng Layer-Wise Relevance Propagation với ResNet34
Không dài dòng nữa, phần code sau đây sẽ cung cấp cho các bạn một ví dụ nho nhỏ khi ta sử dụng LRP cho một phần backbone Resnet34 được cung cấp bởi torchvision. Quy tắc lan truyền được sử dụng sẽ là quy tắc Epsilon, bên cạnh quy tắc này còn có một số các quy tắc nữa nhưng tôi chỉ code lại quy tắc này thôi tại vì tôi lười. Công thức của quy tắc này sẽ như sau:
Rj=∑kajwjkϵ+∑0,jajwjkRkR_j = sum_k frac{a_jw_{jk}}{epsilon + sum_{0, j}a_jw_{jk}} R_k
Như mọi khi, bước đầu tiên mà chúng ta cần thực hiện là cài đặt các thư viện. Cho bạn nào có thắc mắc là tại sao lại có albumentations ở đây thì là do tôi bê code ở chỗ khác sang và lười sửa xD
!pip installalbumentations==0.4.6 -q
!pip install torchvision -q
Tiếp theo đó ta import các thư viện cần thiết như sau:
from PIL import Image
import requests
import numpy as np
import cv2
import torch
import albumentations as A
from albumentations.pytorch.transforms import ToTensorV2
import torch.nn as nn
from torchvision.models.resnet import resnet34, BasicBlock
import matplotlib.pyplot as plt
Để explain model liên quan đến thị giác máy thì tất nhiên ta cần đến ảnh sample rồi, dòng code sau sẽ được sử dụng để đọc ảnh thành PIL.image sau đó chuyển ảnh đầu vào trên thành Tensor của Pytorch
im = Image.open(requests.get("https://i.pinimg.com/564x/db/32/23/db32232ee849096679c32d3392a87694.jpg", stream=True).raw)
transform = A.Compose([
A.Normalize((0.7931,0.7931,0.7931),(0.1738,0.1738,0.1738)),
A.ToTensorV2(),])
resnet = resnet34(pretrained=True)
backbone = nn.Sequential(
resnet.conv1,
resnet.bn1,
resnet.relu,
resnet.maxpool,
resnet.layer1,
resnet.layer2,
resnet.layer3,)
backbone.eval()
img = np.array(im)
images_tensor = transform(image=np.array(img))["image"]
images_tensor = images_tensor.unsqueeze(0).float()
Và phần chính của ví dụ là đây, ta sẽ cài đặt quá trình chạy LRP thành hàm cal_lrp như dưới đây. Có vẻ như tôi code hơi ngu nên hàm này chạy khá lâu với ảnh với kích thước lớn, vậy nên các bạn có thể resize ảnh xuống hoặc sửa gì đó trước khi chạy chứ chạy code này mà bị treo máy thì tôi không chịu trách nhiệm 
defcal_lrp(sequential, input_tensor):
layers =list(sequential)
module_length =len(layers)
lrp_outputs =[None]* module_length +[sequential.forward(input_tensor)]
tensors =[input_tensor]for layer in layers:
tensors.append(layer.forward( tensors[-1]))for i,(layer)inlist(enumerate(layers))[::-1]:ifisinstance(layer,torch.nn.BatchNorm2d):
lrp_outputs[i]= lrp_outputs[i+1][0]ifisinstance(lrp_outputs[i+1],list)else lrp_outputs[i+1]elifisinstance(layer, nn.Sequential):
lrp_outputs[i]= cal_lrp(layer, tensors[i])elifisinstance(layer, BasicBlock):
sub_layers =[
layer.conv1,
layer.bn1,
layer.relu,
layer.conv2,
layer.bn2
]
lrp_outputs[i]= cal_lrp(nn.Sequential(*sub_layers
), tensors[i])else:
input_tensor = tensors[i].data.requires_grad_(True)ifhasattr(layer,"inplace"):
layer.inplace =False
z = layers[i].forward(input_tensor)
s =(tensors[i+1]/(z +1e-9)).data
(z * s).sum().backward()
c = input_tensor.grad
lrp_outputs[i]=(input_tensor*c).data
return lrp_outputs
Để thu được kết quả, ta thực thi đoạn mã sau đây:
lrp_outputs = cal_lrp(backbone, images_tensor)
heatmap = lrp_outputs[0].permute(0,2,3,1).numpy()
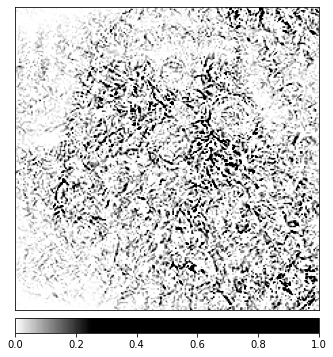
plt.imshow(heatmap[0])Sau vài giây đợi chờ thì ta sẽ thu được ảnh heatmap như dưới đây. Tôi cũng không rõ là mình code đúng không nhưng mà có vẻ như trong ảnh heatmap này thì các đặc trưng của mấy con mòe cũng được tô đậm lên khá nhiều

Model Interpretation cho ResNet
Bên cạnh việc code lại ví dụ trên, tôi cũng cũng có tìm được một thư viện khá chỉnh chu để explain các mô hình phát triển dựa trên PyTorch có tên là Captum. Nội dung tiếp theo của tôi sẽ giới thiệu một ví dụ cũng sử dụng với ResNet được cung cấp bởi chính thư viện này (chủ yếu là để bài viết dài hơn :v )
Đầu tiên như thường lệ, ta cài đặt thư viện và import chúng qua đoạn code sau
pip install captum
import torch
import torch.nn.functional as F
from PIL import Image
import os
import json
import numpy as np
from matplotlib.colors import LinearSegmentedColormap
import torchvision
from torchvision import models
from torchvision import transforms
from captum.attr import IntegratedGradients
Mô hình được sử dụng sẽ là resnet18 và đồng thời với đó ta cũng transform và chuyển ảnh đầu vào thành Tensor thông qua đoạn code sau:
model = models.resnet18(pretrained=True)
model = model.eval()
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor()])
transform_normalize = transforms.Normalize(
mean=[0.485,0.456,0.406],
std=[0.229,0.224,0.225])
transformed_img = transform(im)input= transform_normalize(transformed_img)input=input.unsqueeze(0)Cuối cùng, ta inference mô hình với ảnh đầu vào cũng như visualize color map thông qua đoạn mã sau
output = model(input)
output = F.softmax(output, dim=1)
prediction_score, pred_label_idx = torch.topk(output,1)integrated_gradients = IntegratedGradients(model)
attributions_ig = integrated_gradients.attribute(input, target=pred_label_idx, n_steps=200)default_cmap = LinearSegmentedColormap.from_list('custom blue',[(0,'#ffffff'),(0.25,'#000000'),(1,'#000000')], N=256)
_ = viz.visualize_image_attr(np.transpose(attributions_ig.squeeze().cpu().detach().numpy(),(1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(),(1,2,0)),
method='heat_map',
cmap=default_cmap,
show_colorbar=True,
sign='positive',
outlier_perc=1)Sau một khoảng thời gian thì ta thu được ảnh color map như dưới đâu. Có thể thấy nó khá khó nhìn hơn với kết quả khi chạy với LRP ở trên, có thể phần LRP ở trên tôi code đúng thật.
Tổng kết
Như đã trình bày ở trên thay vì cung cấp một bài viết có một tỉ ký tự đập vào mặt quý đọc giả như trước thì tôi đã chuẩn bị một bài viết ít chữ hơn cũng như cung cấp hai ví dụ sử dụng hai phương pháp thường gặp để thể hiện cách mà thông tin đặc trưng được trích xuất từ ảnh đầu vào. Trong thời gian tới tôi sẽ cố gắng viết một số bài viết liên quan đến việc sử dụng các phương pháp explain mô hình với các mô hình OCR chẳng hạn (trong trường hợp tôi code được). Bài viết đến đây là kết thúc, cảm ơn mọi người đã dành thời gian đọc.
Tài liêu tham khảo
- Layer-wise Relevance Propagation for Neural Networks with Local Renormalization Layers
- Layer-Wise Relevance Propagation: An Overview
- Explaining Convolutional Neural Networks using Softmax Gradient Layer-wise Relevance Propagation
- albermax/innvestigate: A toolbox to iNNvestigate neural networks predictions!
- Model Interpretation for Pretrained ResNet Model
- On Pixel-Wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation
- Layer Wise Relevance Propagation In Pytorch
Nguồn: viblo.asia