Lời mở đầu
- Thứ nhất, bài viết này tham khảo từ W&B documentation, có sửa đổi một chút: chắt lọc các thông tin, chức năng quan trọng của W&B mà người dùng cần
- Thứ hai, bài viết này mới chỉ cover được 2/7 phần của W&B, nếu có gì thiếu sót xin mọi người bỏ qua cho. Trong thời gian tới tôi sẽ cập nhật các phần tiếp theo

- Thứ ba, bài viết này khá dài, mọi người có thể tìm phần mình cảm thấy hứng thú qua mục lục bên tay phải màn hình nếu không muốn đọc hết
- Thứ tư, mời đọc kỹ 3 mục trên bởi người viết đã cảnh báo trước
Cám ơn các bạn đã đọc tới dòng này, như vậy chứng tỏ là các bạn đã đọc hết các mục trên, không dông dài nữa người viết sẽ giải thích tất tần tật WanDB bên dưới
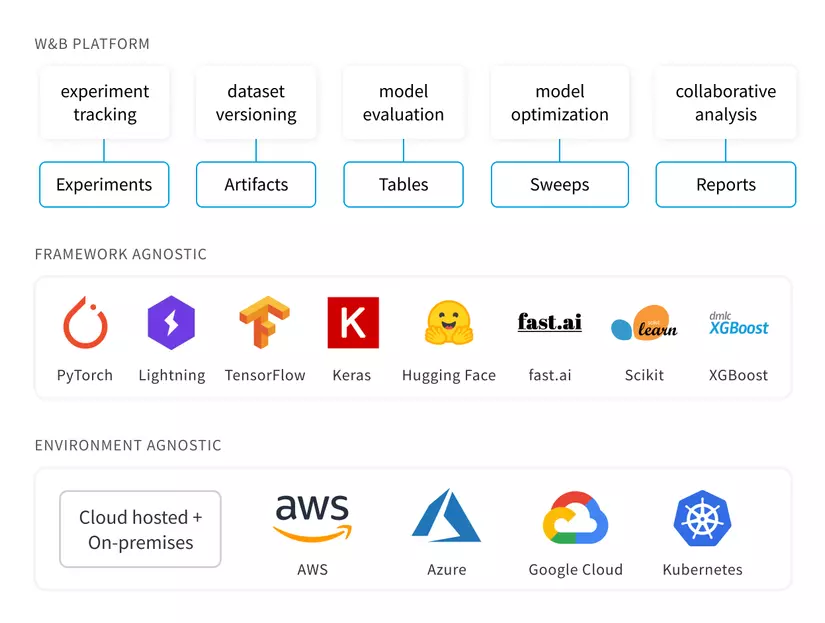
WanDB là gì ?
Hãy thử ghé qua git repo của wandb và bạn sẽ thấy lời giới thiệu của họ bằng tiếng anh như sau:
A tool for visualizing and tracking your machine learning experiments. This repo contains the CLI and Python API.
Hiểu đơn giản thì đây là 1 công cụ dùng để visualize và tracking các thí nghiệm học máy.
Nếu các bạn không biết thì việc quản lý mô hình học máy ( visualize, tracking, monitoring, model registry, … ) là bước đầu tiên trong MLOps . Và tôi hôm nay ở đây sẽ giới thiệu các bạn về wandb chi tiết nhất có thể
WanDB hay còn gọi là Weight & Biases ( các siêu tham số quan trọng trong AI ) là công cụ hữu ích, hỗ trợ việc xây dựng mô hình nhanh chóng. Công cụ này sẽ track và visualize từng phần trong ML pipeline của bạn, từ việc xử lý dữ liệu đến biến mô hình thành sản phẩm.
Dưới đây là một số công dụng của wandb :
- Hiển thị kết quả theo thời gian thực, dưới dạng bảng biểu và được quản lý bằng giao diện web đơn giản, dễ nhìn
- Giúp bạn tập trung vào xây dựng mô hình, đỡ tốn thời gian tracking kết quả bằng text hay excel.
- Lưu lại các phiên bản của dữ liệu bằng W&B Artifacts khi có sự thay đổi của bản ghi, xem xét mức độ ảnh hưởng của nó tới kết quả mô hình
- Sao lưu mô hình ( code, hyperparameters, launch commands, input data, weight, metric, config, … )
Một số thuật ngữ tôi sẽ sử dụng trong bài để mọi người dễ hiểu:
- visualize: hiển thị trực quan
- tracking, monitoring: theo dõi, giám sát
- registry model: cở sở dữ liệu các phiên bản mô hình
- hyperparameters: siêu tham số
- input data: dữ liệu đầu vào
- weight: trọng số
- launch commands: câu lệnh chạy
- metric: phương thức đánh giá, chỉ số, …
- config: tham số cài đặt
Cài đặt
Do wandb code bằng python (~97%) nên việc cài đặt cũng khá đơn giản. Yêu cầu: python >= 3.6
Các bạn có thể cài bằng pip
pip install wandb
Để sử dụng wandb, bạn cần phải lập một tài khoản tại đây: https://wandb.com/
Sau một đống step thì bạn sẽ được dẫn đến giao diện này
Copy lại cái API key, để đấy đã. Trên terminal, dùng lệnh
wandb login

Paste lại api code vừa nãy vào terminal là xong, api key được lưu vào máy để lần sau tự động đăng nhập lại @@
Thực hành
Ok, giờ chúng ta cùng làm quen cách viết của wandb bằng ví dụ thực tế đi.
Ví dụ 1: Thử nghiệm bằng cách giả lập quá trình huấn luyện, nói không với các thư viện học máy nổi tiếng
import random
total_runs =5for run inrange(total_runs):
wandb.init(
project="basic-intro",
name=f"experiment_{run}",
config={"learning_rate":0.02,"architecture":"CNN","dataset":"CIFAR-100","epochs":10,})
epochs =10
offset = random.random()/5for epoch inrange(2, epochs):
acc =1-2**-epoch - random.random()/ epoch - offset
loss =2**-epoch + random.random()/ epoch + offset
wandb.log({"acc": acc,"loss": loss})
wandb.finish()Cùng bóc tách đoạn code bên trên nào:
- Bước 1: khởi tạo wandb bằng câu lệnh
wandb.init(), câu lệnh này sẽ lưu trữ cấu hình huấn luyện của mô hình như siêu tham số, tên bộ dữ liệu, loại mô hình, …Việc này giúp bạn phân tích các thử nghiệm và tái sử dụng mô hình dễ dàng hơn.
Các tham số của init dùng trong đoạn code trên như project dùng để tạo 1 dự án trong dashboard, name dùng để đặt tên cho mỗi lần thí nghiệm
Các bạn có thể tham khảo chi tiết về các tham số mà wandb.init cung cấp ở link dưới:
https://docs.wandb.ai/ref/python/init
- Bước 2: Trong quá trình huấn luyện, cứ qua một epoch, tôi sẽ bọc kết quả ( độ chính xác và hàm mất mát ) của mô hình bằng
wandb.log(). Hàm log này còn được dùng ở nhiều chỗ khác, tôi sẽ nhắc tới bên dưới. - Bước 3: Sau khi huấn luyện xong thì kết thúc wandb bằng
wandb.finish()
Biến total_runs tượng trưng cho số lần huấn luyện mô hình, cụ thể ở đây là 5 lần tương ứng 5 experiments ( thí nghiệm ) .
Để xem kết quả của 5 lần thử một cách trực quan nhất, bạn có thể đăng nhập trang wandb.ai trên trình duyệt.
Để xem chi tiết thí nghiệm, bạn có thể ấn vào tên thí nghiệm trên hình, wandb sẽ cung cấp cho bạn thông tin về độ chính xác, hàm loss dưới dạng biểu đồ, lượng tài nguyên mà mô hình đã sử dụng ( network traffic, dung lượng ổ cứng, CPU, GPU, … )
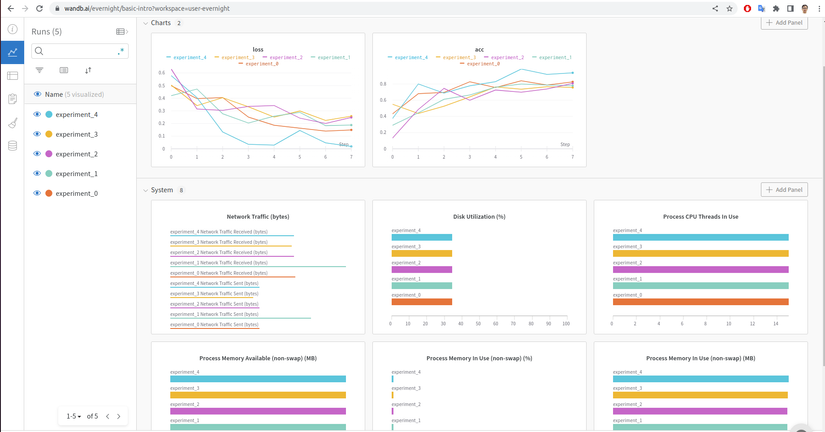
Trên đây là một ví dụ đơn giản về wandb, tiếp theo tôi sẽ giới thiệu các chức năng chính của wandb
Triển khai WanDB ( Private-Hosting )
Nếu bạn muốn dùng server bảo mật thay thế cho cloud server của wandb thì bên wandb cũng có hỗ trợ các phương thức: The W&B Server, private cloud.
- The W&B Server: Các bước khởi tạo local web server
I. Tải wandb/local image về và chạy wandb-local container bằng câu lệnh bên dưới
wandb server start --upgrade --port xxxx
# Or
docker pull wandb/local
docker stop wandb-local
docker run --rm -d -v wandb:/vol -p 8080:8080 --name wandb-local wandb/local
II. Bạn cần giấy phép của wandb để cập nhật cấu đầy đủ cấu hình của W&B Server. Nhận giấy phép thông qua đây: https://deploy.wandb.ai/deploy
III. Mở trình duyệt, vào web server localhost:your_port ( mặc định là localhost:8080 ) . Vào phần cài đặt để cập nhật giấy phép
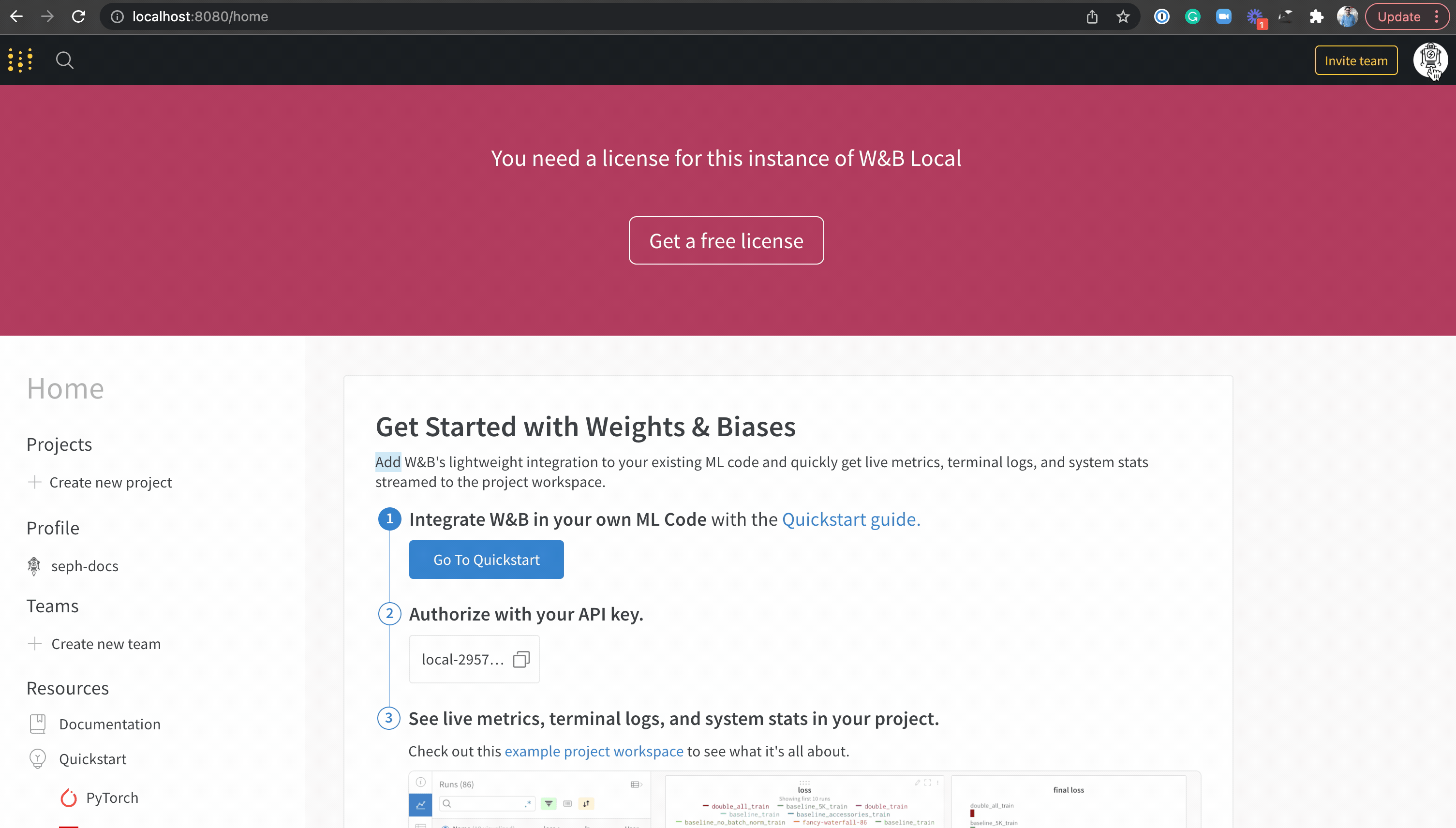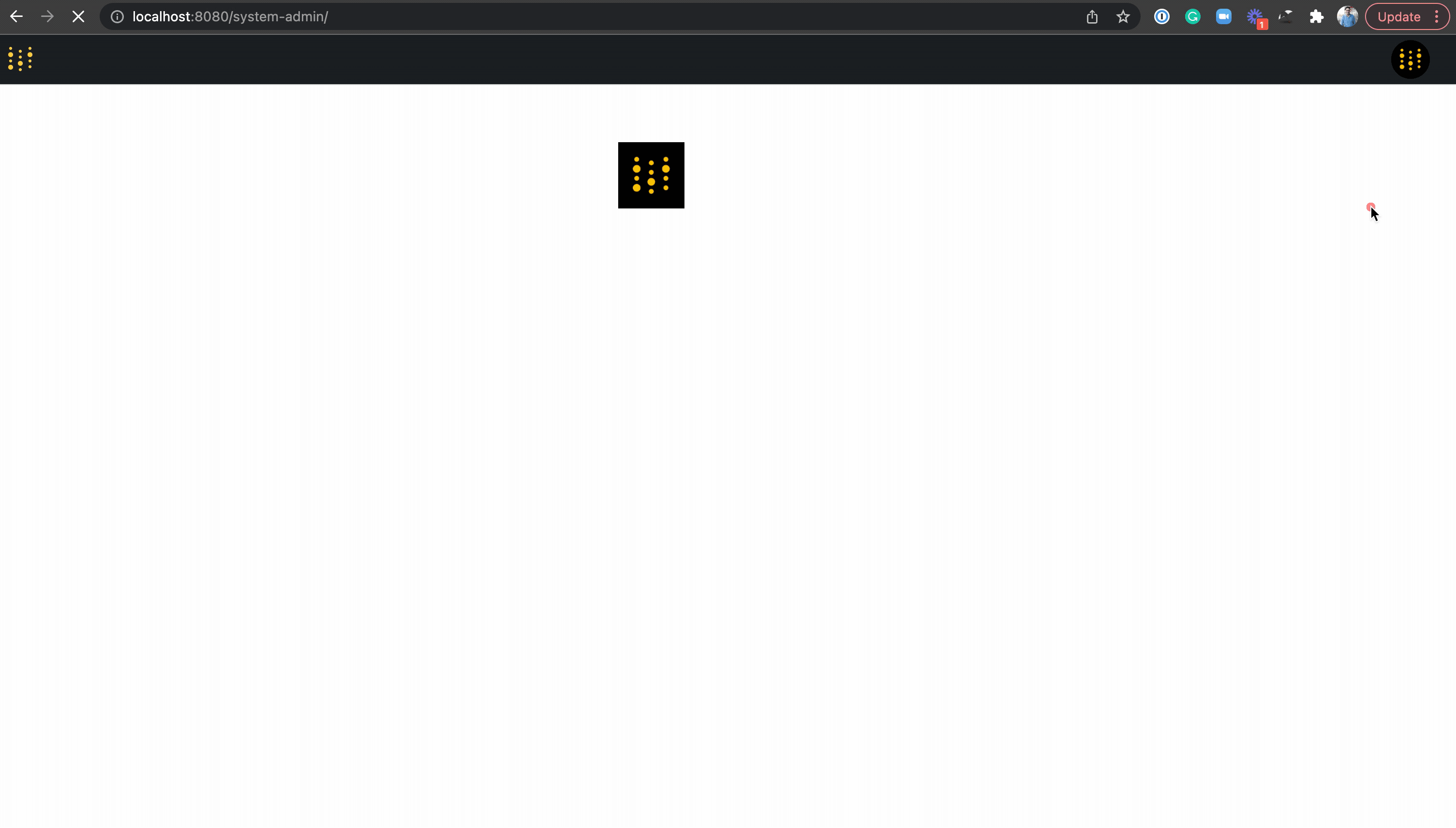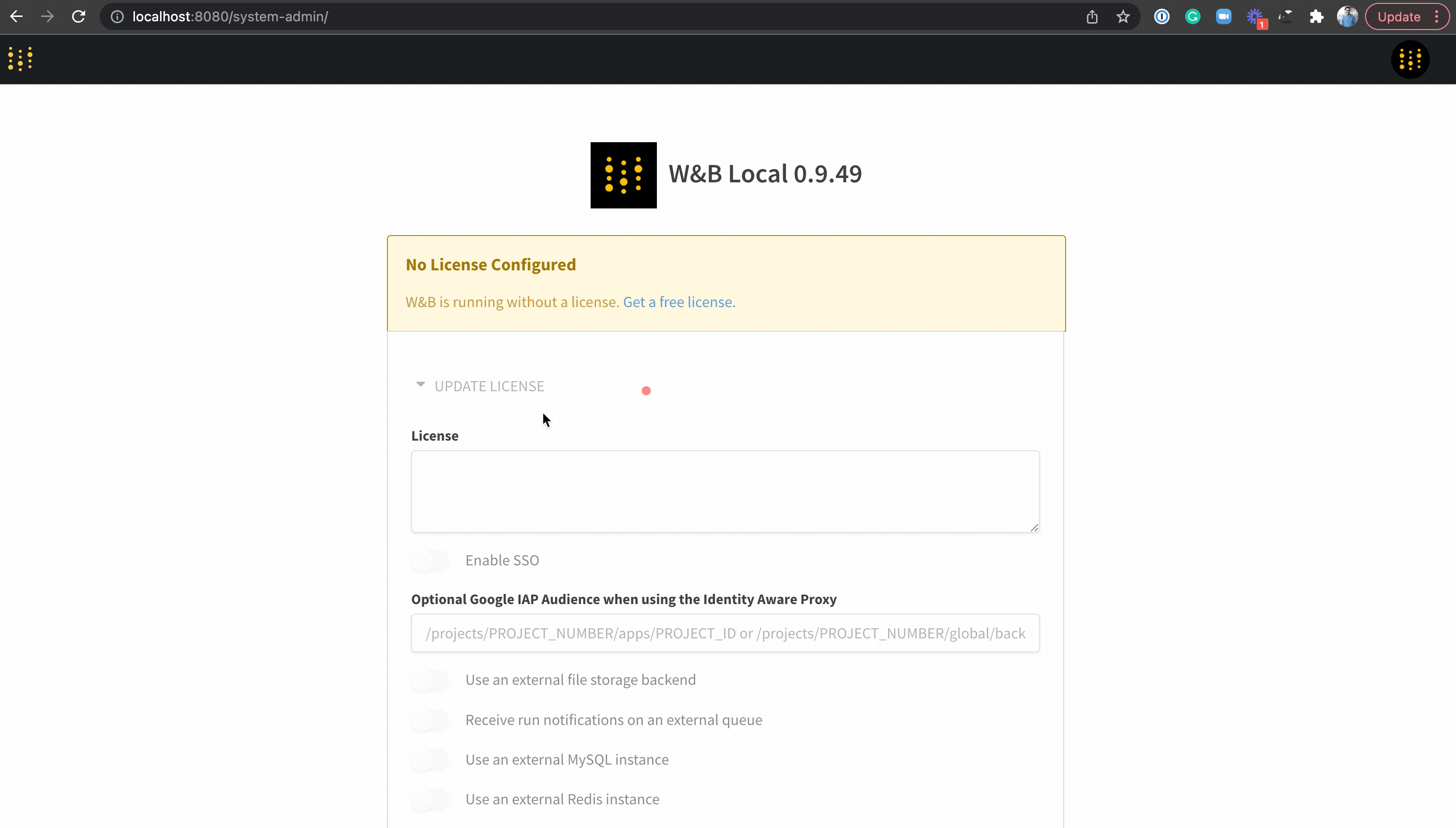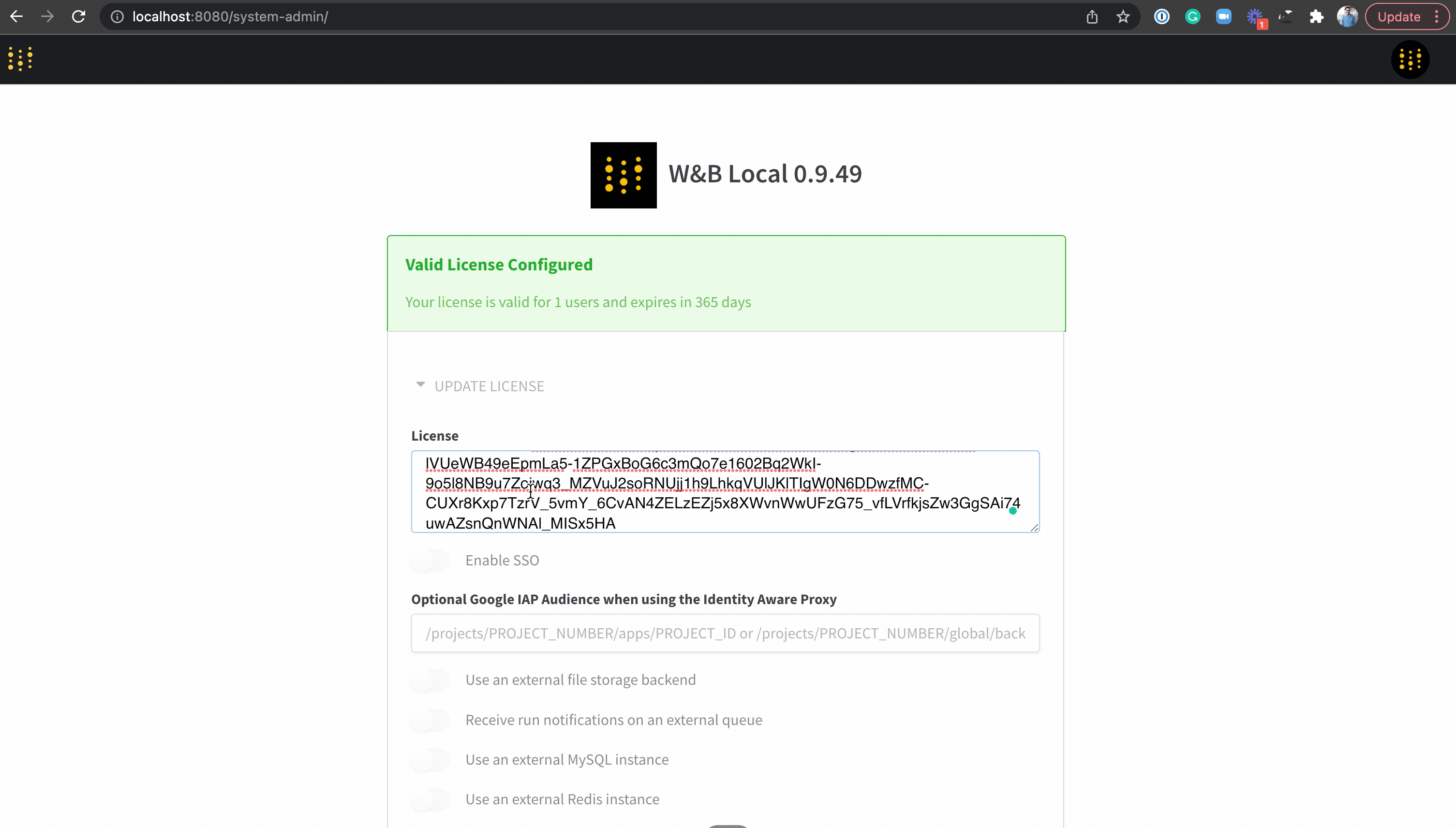
!!! Một vài lưu ý:
a. Tất cả các file và metadata được lưu vào thư mục /vol. Nếu không mount thư mục này với một thư mục trong máy thì khi container chết, dữ liệu trong container sẽ mất hết.
b. Giải pháp này không phù hợp khi triển khai sản phẩm. Nếu định triển khai sản phẩm mời xem cách thứ 2
c. Nếu trong lúc thử nghiệm bạn muốn chuyển sang dùng wandb cloud server thì có thể đăng nhập lại
wandb login --cloud
Ngược lại, bạn cũng có thể từ cloud server chuyển sang host khác bằng cách thay đổi tài khoản
wandb login --host http://localhost:8080
d. Hiện tại phương thức này đang gặp lỗi đăng nhập, chi tiết các bạn có thể đọc ở 2 issues này: https://github.com/wandb/local/issues/59 và https://github.com/wandb/local/issues/64 .
- Private Cloud: cách này dựa trên các cloud server có sẵn như AWS, Azure, GCP, … Bạn sẽ phải viết terraform file để khởi tạo cơ sở hạ tầng cho cloud server, cũng như triển khai wandb trên đây. Do khá dài cũng như không có tài khoản cloud nên tôi xin thôi, ai có hứng thú thì tự thân vận động vậy @@
Yêu cầu:
a. A Kubernetes cluster (EKS or GKE)
b. A SQL database (RDS, Google Cloud SQL, or Azure MySQL)
c. A object store (S3, GCS, or Azure Blob Store)
https://www.youtube.com/watch?v=bYmLY5fT2oA
- Local Server: tương tự cách 1 nhưng cách này cho phép bạn tùy biến cơ sở dữ liệu, mở rộng bằng Kubernetes, điều chỉnh cấu hình mạng, thiết lập lớp bảo vệ, … Các bạn có thể tham khảo link này: https://docs.wandb.ai/guides/self-hosted/setup/on-premise-baremetal
WanDB trên Notebook
Phần này dành cho các bạn quen dùng Notebook. Đầu tiên bắt đầu notebook bằng cách cài đặt W&B và link tài khoản
!pip install wandb -qqq
import wandb
wandb.login()Khởi tạo thí nghiệm và tùy chỉnh tham số
wandb.init(project="jupyter-projo",
config={"batch_size":128,"learning_rate":0.01,"dataset":"CIFAR-100",})Mở 1 cell mới và gõ %%wandb để quan sát biểu đồ trực tiếp trên notebook. Nếu nhiều lần chạy cell này, dữ liệu sẽ thêm vào thí nghiệm
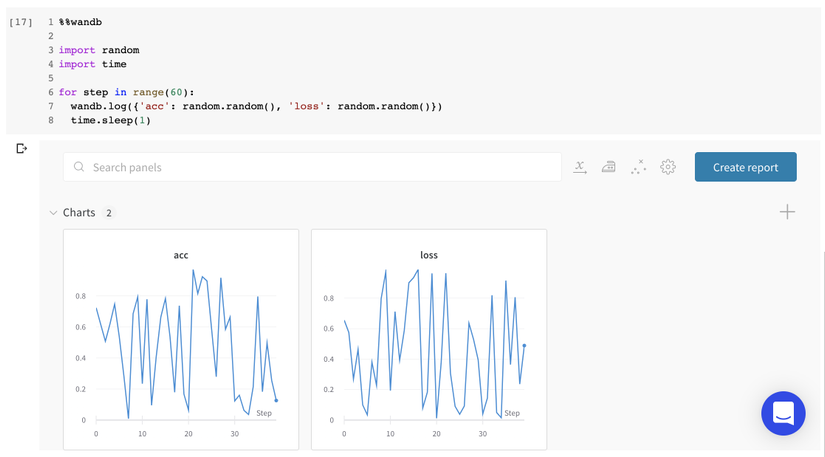
W&B interfaces
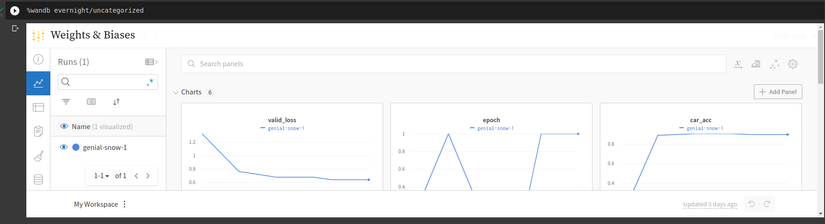
Người dùng có thể xem W&B UI trên notebook bằng %wandb. Ví dụ
%wandb evernight/uncategorized
Dockerized Jupiter
Trên terminal, gõ lệnh wandb docker --jupyter để chạy docker container với port 8888
Theo dõi thí nghiệm ( Experiment Tracking )
Mục tiêu: track và visualize các thử nghiệm theo thời gian thực, so sánh các phiên bản nhưng vẫn đảm bảo tốc độ huấn luyện, …
Dữ liệu được ghi lại
-
Ghi lại tự động: thông số hệ thống ( CPU, GPU, … ), các câu lệnh đã sử dụng ( CLI ), code
-
Ghi lại bằng cơm: bộ dữ liệu, gradient, tham số, siêu tham số, đường dẫn tới bộ dữ liệu, các phương pháp đánh giá mô hình, …
Các hàm mà chức năng này sử dụng:
Wandb.init()
Khởi tạo wandb trong script. Hàm này trả về Run object và tạo 1 thư mục nơi chứa logs và files ( thư mục wandb như hình dưới ), dữ liệu từ các lần chạy sẽ được truyền bất đồng bộ tới máy chủ W&B.
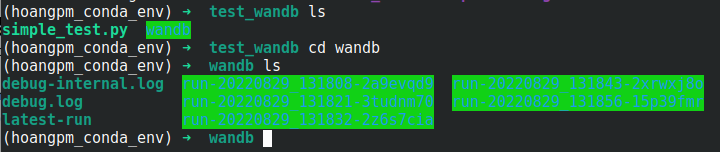
Khởi tạo nhiều Run objects
Trong trường hợp bạn có nhiều mô hình trong 1 script dẫn đến phải tạo nhiều contructor của wandb.init(). Bạn có thể thêm tham số reinit=True trong wandb.init() để các constructors này sẽ gọi cùng 1 script.
import wandb
for x inrange(10):
run = wandb.init(reinit=True)for y inrange(100):
wandb.log({"metric": x+y})
run.finish()Wandb trong distributed training
Trong trường hợp bạn huấn luyện 1 mô hình bằng nhiều máy hoặc nhiều gpu trên 1 máy. Vậy wandb có hỗ trợ hay không thì tôi phải nói là có.
- Cách 1:
wandb.initonrank0process
Trong multi-GPU training, tiến trình rank0 là tiến trình chính, tổng hợp kết quả từ các tiến trình khác. Vì vậy, bạn chỉ cần gọi hàm wandb.init() trong tiến trình này là được, việc còn lại wandb sẽ lo
Khuyết điểm: không ghi lại được một số thông tin ( giá trị loss, các batch, … ) do đầu vào và đầu ra của các tiến trình khác nhau.
if __name__ =="__main__":# Get args
args = parse_args()if args.local_rank ==0:# only on main process# Initialize wandb run
run = wandb.init(
entity=args.entity,
project=args.project,)# Train model with DDP
train(args, run)else:
train(args)- Cách 2: wandb.init on all process
Với cách này, tôi sẽ gọi wandb.init(), wandb.finish() và wandb.log() ở tất cả các tiến trình. Lợi ích của cách này là các bạn có thể ghi lại thông tin sau mỗi lần huấn luyện mô hình. Để sử dụng cách này, các bạn phải nhóm các lần chạy vào 1 group bằng cách thêm tham số group vào wandb.init()
Khuyết điểm: sẽ tạo nhiều lần runs trên web UI
if __name__ =="__main__":# Get args
args = parse_args()# Initialize run
run = wandb.init(
entity=args.entity,
project=args.project,
group="DDP",# all runs for the experiment in one group)# Train model with DDP
train(args, run)Để cải thiện chức năng theo dõi của W&B với các distributed experiments. Tôi khuyến khích bạn dùng wandb service. Trong phiên bản 0.13.0, wandb service sẽ được bật mặc định, còn với các phiên bản >= 0.12.5 thì bạn thêm code như sau:
if __name__ =="__main__":
wandb.require("service")# rest-of-your-script-goes-hereChạy lại wandb
Trong trường hợp bạn muốn tạm dừng việc huấn luyện, rồi sau đó load mô hình để train tiếp. Wandb hỗ trợ việc ghi lại thông tin từ lần chạy cuối cùng bằng cách thêm tham số resume=True vào wandb.init(). Ví dụ:
wandb.init(project="preemptible", resume=True)Có 2 trường hợp bạn có thể sẽ gặp phải:
- Nếu trong khi chạy thí nghiệm, bạn ngừng thí nghiệm không đúng cách thì khi dùng
resume=Truebạn sẽ quay lại đúng lần chạy cuối cùng của thí nghiệm này - Nếu bạn dừng thí nghiệm đúng cách nhưng sau đó muốn huấn luyện tiếp và vẫn muốn wandb ghi tiếp thông tin thì phải truyền id của thí nghiệm cần vào hàm
wandb.init()
wandb.init(id=run_id, resume="must")
Nếu muốn wandb tự sinh ra id cho mỗi lần thử nghiệm thì dùng cách này
wandb.util.generate_id()
Có 2 cách viết: truyền tham số vào wandb.init() hoặc khai báo biến môi trường
# store this id to use it later when resumingid= wandb.util.generate_id()
wandb.init(id=id, resume="allow")# or via environment variables
os.environ["WANDB_RESUME"]="allow"
os.environ["WANDB_RUN_ID"]= wandb.util.generate_id()
wandb.init()Wandb offline
Nếu bạn muốn bảo mật một vài metrics mà không muốn upload lên W&B cloud server hoặc có thể do nhà bạn không có mạng Internet thì có thể làm theo cách sau: khai báo 2 biến môi trường
# API KEY có thể tìm thấy trong setting page trên web UI hoặc bạn có thể tìm thấy theo đường dẫn này: /home/user/.netrc
os.environ["WANDB_API_KEY"]= YOUR_KEY_HERE
os.environ["WANDB_MODE"]="offline"Sau khi apply vào đoạn code ví dụ dưới đây
import wandb
import os
os.environ["WANDB_API_KEY"]= YOUR_KEY_HERE
os.environ["WANDB_MODE"]="offline"
config ={"dataset":"CIFAR10","machine":"offline cluster","model":"CNN","learning_rate":0.01,"batch_size":128,}
wandb.init(project="offline-demo")for i inrange(100):
wandb.log({"accuracy": i})Sẽ thu được kết quả trả về là:
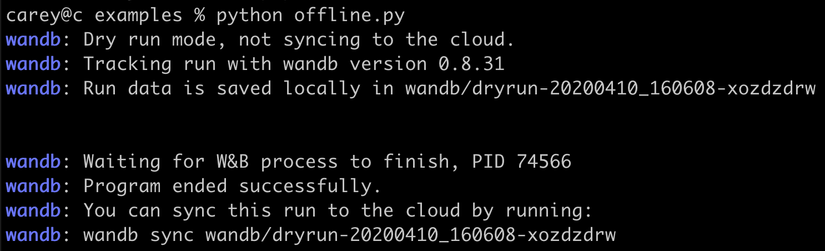
Thông tin về model của bạn được lưu theo đường dẫn này wandb/dryrun-20200410_160608-xozdzdrw. Còn nếu bạn thay đổi ý định muốn upload lại thông tin lên W&B cloud server thì chỉ cần sync folder bằng câu lệnh này là được:
wandb sync wandb/dryrun-folder-name
Trên đây là một vài lưu ý khi dùng wandb.init(), còn một vài thứ nữa nhưng tôi không đề cập tới do không dùng nhiều. Để xem các tham số mà wandb.init() dùng thì bạn có thể tham khảo link này: https://docs.wandb.ai/ref/python/init
Wandb.config
wandb.config là 1 object có tác dụng lưu lại các tham số, siêu tham số, biến môi trường của thí nghiệm. Điều này rất hữu dụng khi bạn muốn phân tích thí nghiệm của bạn, dễ dàng tái hiện lại thí nghiệm, so sánh các configs của từng lần thí nghiệm, …
Cách viết
wandb.config.epochs =4
wandb.config.batch_size =32# Or
wandb.config.update({"lr":0.1,"channels":16})Hoặc thêm tham số config trong wandb.init()
wandb.init(config={"epochs": 4})
Nếu bạn muốn truyền tham số vào command line như thế này python train.py --epoch xxx --lr xxx thì có thể thêm thư viện argparse của python.
wandb.init(config={"lr":0.1})
wandb.config.epochs =4
parser = argparse.ArgumentParser()
parser.add_argument('-b','--batch-size',type=int, default=8, metavar='N',help='input batch size for training (default: 8)')
args = parser.parse_args()
wandb.config.update(args)# adds all of the arguments as config variablesCòn để quản lý tiện hơn thì bạn nên tạo 1 file chứa các biến configs này configs.yaml, sau đó load file yaml dưới dạng python dict
# sample config defaults fileepochs:desc: Number of epochs to train over
value:100batch_size:desc: Size of each mini-batch
value:32import yaml
config_dictionary = yaml.load("configs.yaml")
wandb.init(config=config_dictionary)Định danh bộ dữ liệu
Trong trường hợp bạn có nhiều bộ dữ liệu hoặc 1 bộ dữ liệu có nhiều phiên bản thì có thể đặt tên bộ dữ liệu mà bạn dùng trong thí nghiệm.
Ví dụ:
wandb.config.update({"dataset":"ab131"})Wandb.log()
Wandb sẽ làm nhiệm vụ thu thập thông tin cũng như liên tục ghi lại các metrics ( loss, accuracy, … ) trong mỗi epoch của thí nghiệm bằng hàm wandb.log().
Dưới đây là cách viết đơn giản của hàm này
wandb.log({"loss":0.314,"epoch":5,"inputs": wandb.Image(inputs),"logits": wandb.Histogram(ouputs),"captions": wandb.Html(captions)})Cách thức vận hành của Logging
W&B sẽ theo dõi các thông tin được ghi lại theo thời gian, khi vẽ biểu đồ ta sẽ quan sát được lịch sử của một lần thí nghiệm. Nhưng đôi khi trong một vài trường hợp đặc biệt, bạn chỉ muốn ghi lại thông tin ở một thời điểm cụ thể nào đó trong thí nghiệm chẳng hạn, vậy bạn phải ghi nhớ index của thời điểm đó và truyền vào hàm wandb.log() như sau:
wandb.log({'loss':0.2}, step=step)Index của các thời điểm cũng tương tự index trong python list: 0, 1, 2, …
Các dạng dữ liệu có thể log
W&B hỗ trợ nhiều dạng dữ liệu có thể ghi lại như ảnh, video, audio, … , giúp bạn dễ dàng so sánh các lần thí nghiệm, các phiên bản của mô hình và bộ dữ liệu. Do khá nhiều dạng dữ liệu mà trên document của wandb đọc cũng dễ hiểu nên tôi không viết thêm cho dài @@
Các bạn có thể xem các dạng dữ liệu mà W&B hỗ trợ ở đây: https://docs.wandb.ai/ref/python/data-types
Còn đây là một vài đoạn code ví dụ mọi người có thể thử trên colab: https://colab.research.google.com/github/wandb/examples/blob/master/colabs/wandb-log/Log_(Almost)_Anything_with_W%26B_Media.ipynb
Dưới đây là một số ảnh minh họa khi ghi lại các dạng dữ liệu khác nhau:
-
Plots
![]()
-
Histograms
![]()
-
Ảnh
![]()
-
Video
![]()
-
Audio
![]()
-
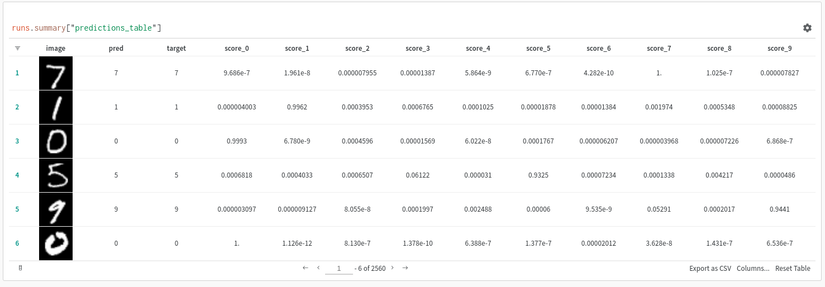
Table
![]()
-
HTML
![]()


Tôi sẽ liệt kê một số mục quan trọng của W&B logging mà mọi người thường hay sử dụng bên dưới
Log Images
Image Overlays
Nếu bạn đang vọc vạch các segmentation model, phần này sẽ giúp ích cho bạn rất nhiều. Giả sử trong một ảnh của bạn có nhiều vật thể, W&B sẽ chia các vật thể ra thành nhiều lớp (masks), các lớp có màu sắc khác nhau để dễ phân biệt, bạn có thể thay đổi độ trong suốt, quan sát theo thời gian, …
Do code khá dài nên tôi cũng không tiện post lên đây, các bạn có thể thử nghiệm code tại colab @@ : https://colab.research.google.com/drive/1SOVl3EvW82Q4QKJXX6JtHye4wFix_P4J
P/s: nếu bạn dính N lỗi trong lúc vọc colab thì thêm mấy dòng này
!pip install fastapi==1.0.57
!pip install torch==1.4.0
!pip install torchvision==0.5.0Và sửa dòng wandb.init() nếu bị lỗi InitStartError: Error communicating with wandb process
wandb.init(settings=wandb.Settings(start_method="thread"))Nếu vẫn không được thì bạn restart runtime của colab + mấy đoạn code trên là ok
Ví dụ minh họa

Cách tránh trùng ảnh khi upload lên W&B server
- Bước 1: Thêm ảnh vào Artifact
wandb.init()
art = wandb.Artifact("my_images","dataset")for path in IMAGE_PATHS:
art.add(wandb.Image(path), path)
wandb.log_artifact(art)- Logging bằng Artifact bên trên
wandb.init()
art = wandb.use_artifact("my_images:latest")
img_1 = art.get(PATH)
wandb.log({"image": img_1})Liên quan đến khái niệm của Artifact tôi sẽ đề cập sau
Log Plots
Chi tiết bạn có thể xem ở đây: https://docs.wandb.ai/guides/track/log/plots
Basic Charts
W&B hỗ trợ các dạng biểu đồ cơ bản: Line, Scatter, Bar, Histogram, Multi-line
Model Evaluation Charts
Ngoài các dạng biểu đồ cơ bản, W&B còn hỗ trợ các biểu đồ đánh giá mô hình như precision-recall, ROC, Confusion Matrix
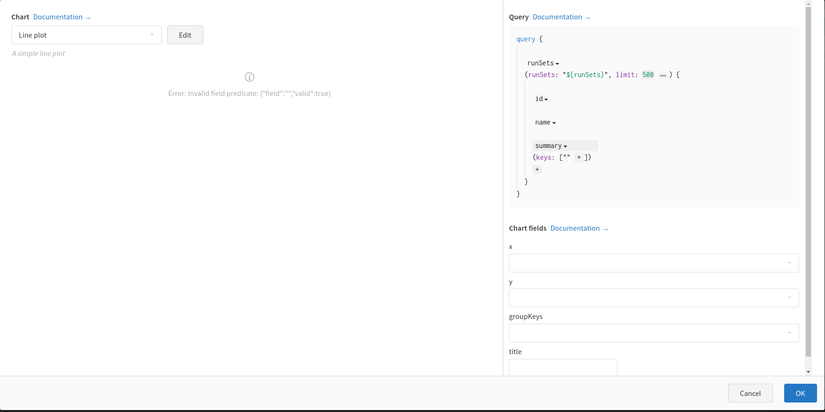
Interactive Custom Charts
Nếu bạn không muốn sử dụng các biểu đồ có sẵn thì W&B cũng cung cấp việc tùy chỉnh biểu đồ ngay trên web UI.
Cụ thể click vào một project -> Add Panel -> Custom Chart
Matplotlib
Giả dụ bạn không muốn dùng wandb.plot, bạn cũng có thể tạo và hiển thị biểu đồ trên Web UI bằng matplotlib
import matplotlib.pyplot as plt
plt.plot([1,2,3,4])
plt.ylabel("some interesting numbers")
wandb.log({"chart": plt})Import CSV
Nếu trước giờ bạn lưu thông số, các logs của mô hình trên csv và giờ muốn hiển thị trực quan bằng đồ thị, biểu đồ trên W&B web UI thì chỉ cần khởi tạo thí nghiệm (mỗi thí nghiệm tương ứng một RUN object), sau đó thêm log các hàng của file csv bởi run là được.
Cụ thể như sau: Tôi có 1 file csv experiments.csv có các cột và hàng như sau:
| Experiment | Notes | Tags | Num Layers | Final Train Acc | Final Val Acc | Training Losses |
|---|---|---|---|---|---|---|
| Experiment 1 | Overfit way too much on training data | [latest] | 300 | 0.99 | 0.90 | [0.55, 0.45, 0.44, 0.42, 0.40, 0.39] |
Tôi đọc file csv này bằng thư viện pandas, tôi đọc từng hàng của file csv rồi trích xuất thông tin các cột và lưu vào một dict, khởi tạo run object bằng wandb.init(), object này có nhiệm vụ ghi lại thông tin của mỗi hàng, sau đó cập nhật vào summary.
import pandas as pd
import wandb
FILENAME ="experiments.csv"
loaded_experiment_df = pd.read_csv(FILENAME)
PROJECT_NAME ="Converted Experiments"
EXPERIMENT_NAME_COL ="Experiment"
NOTES_COL ="Notes"
TAGS_COL ="Tags"
CONFIG_COLS =["Num Layers"]
SUMMARY_COLS =["Final Train Acc","Final Val Acc"]
METRIC_COLS =["Training Losses"]for i, row in loaded_experiment_df.iterrows():
run_name = row[EXPERIMENT_NAME_COL]
notes = row[NOTES_COL]
tags = row[TAGS_COL]
config ={}for config_col in CONFIG_COLS:
config[config_col]= row[config_col]
metrics ={}for metric_col in METRIC_COLS:
metrics[metric_col]= row[metric_col]
summaries ={}for summary_col in SUMMARY_COLS:
summaries[summary_col]= row[summary_col]
run = wandb.init(project=PROJECT_NAME, name=run_name,
tags=tags, notes=notes, config=config)for key, val in metrics.items():ifisinstance(val,list):for _val in val:
run.log({key: _val})else:
run.log({key: val})
run.summary.update(summaries)
run.finish()Thực ra còn một cách nữa: biến đổi file CSV thành định dạng wandb.Table
new_iris_dataframe = pd.read_csv("iris_dataframe.csv")
iris_table = wandb.Table(dataframe=new_iris_dataframe)Để scale up giới hạn số lượng row trên wandb.Table cần lưu vào artifact, nếu wandb.Table giới hạn 10000 row thì artifact sẽ tăng mức giới hạn lên 200000
iris_table_artifact = wandb.Artifact("iris_artifact",type="dataset")
iris_table_artifact.add(iris_table,"iris_table")
iris_table_artifact.add_file("iris_dataframe.csv")
run = wandb.init(project="Tables-Quickstart")
run.log({"iris": iris_table})
run.log_artifact(iris_table_artifact)
run.finish()Wandb.alert()
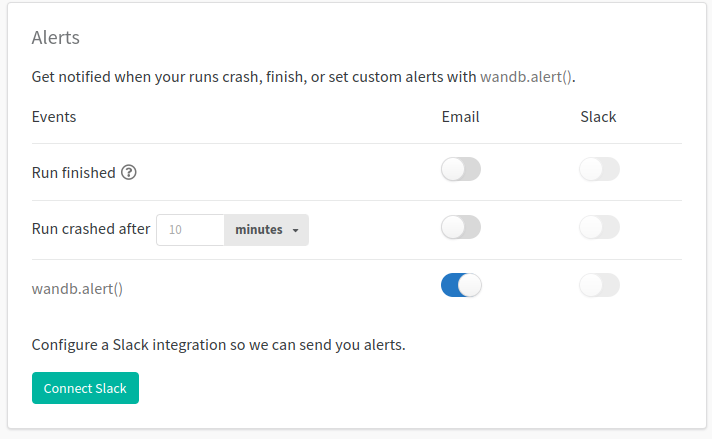
W&B Alerts sẽ thông báo cho bạn khi thí nghiệm đang chạy của bạn tự nhiên đứt hay loss trong khi huấn luyện bị NaN hoặc một bước nào đó trong ML pipeline của bạn hoàn thành thông qua email hoặc Slack
Để sử dụng chức năng này, bạn làm theo các bước sau:
-
Bật chức năng Alerts trong W&B User Settings trên web UI
![]()
-
Thêm
wandb.alert()trong code
import wandb
from wandb import AlertLevel
if acc < threshold:
wandb.alert(
title="Low accuracy",
text=f"Accuracy {acc} is below the acceptable theshold {threshold}",
level=AlertLevel.WARN,
wait_duration=300)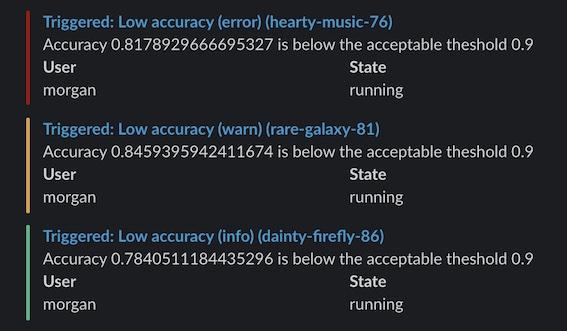
Public API
Khi dùng W&B, chúng ta sẽ bắt gặp nhiều trường hợp phải truy xuất dữ liệu làm báo cáo hay tùy chỉnh kết quả của các lần thí nghiệm nên W&B có cung cấp W&B API hỗ trợ những tác vụ trên. Và việc cần làm của một lập trình viên như tôi là thành thạo việc dùng API này
Bước đầu tiên cần làm là khởi tạo biến api
import wandb
api = wandb.Api()Khởi tạo biến runs, biến này trả về Runs object có định dạng list. Tôi sẽ cần có entity: tên người dùng và project: tên dự án để lấy thông tin thí nghiệm. Mặc định giới hạn thí nghiệm có thể lấy là 50, nhưng nếu bạn muốn lấy nhiều hơn có thể thêm thông số per_page
entity, project ="<entity>","<project>"
runs = api.runs(entity +"/"+ project)Dưới đây tôi sẽ liệt kê các chức năng quan trọng mà API hỗ trợ.
Query và Export thí nghiệm
Trong trường hợp cần xuất ra thông tin thí nghiệm ( cài đặt, mô hình, kết quả, … ) , đoạn code dưới đây minh họa cho việc tôi lấy các thông tin thí nghiệm rồi lưu lại bằng csv.
- summary: chứa các metrics ( loss, accuracy, … ) có định dạng json: key – value
- config: chứa siêu tham số ( epoch, learning_rate, … )
- name: tên thí nghiệm
import pandas as pd
import wandb
api = wandb.Api()
entity, project ="<entity>","<project>"
runs = api.runs(entity +"/"+ project)
summary_list, config_list, name_list =[],[],[]for run in runs:
summary_list.append(run.summary._json_dict)
config_list.append({k: v for k,v in run.config.items()ifnot k.startswith('_')})
name_list.append(run.name)
runs_df = pd.DataFrame({"summary": summary_list,"config": config_list,"name": name_list
})
runs_df.to_csv("project.csv")Lấy các metrics của thí nghiệm
Tôi sẽ lấy timestamp và accuracy của một thí nghiệm qua đoạn code dưới đây. Bởi một dự án có rất nhiều thí nghiệm nên cần phải có id để truy cập đúng thí nghiệm mong muốn
import wandb
api = wandb.Api()
run = api.run("<entity>/<project>/<run_id>")if run.state =="finished":for i, row in run.history().iterrows():print(row["_timestamp"], row["accuracy"])Nếu bạn không nhớ id của thí nghiệm thì bạn cũng có thể truy cập thí nghiệm thông qua thời gian chạy chẳng hạn. Truy xuất các thí nghiệm chạy trong một khoảng thời gian cụ thể thông qua MongoDB Query Language.
runs = api.runs('<entity>/<project>',{"$and":[{'created_at':{"$lt":'YYYY-MM-DDT##',"$gt":'YYYY-MM-DDT##'}}]})Lấy toàn bộ metrics từ lịch sử thí nghiệm
Mặc định run.history() sẽ chỉ trả về 500 mẫu. Nhưng bạn cũng có thể lấy toàn bộ kết quả qua run.scan_history().
import wandb
api = wandb.Api()
run = api.run("<entity>/<project>/<run_id>")
history = run.scan_history()
losses =[row["loss"]for row in history]So sánh 2 thí nghiệm
Sẽ có trường hợp bạn cần phải so sánh các thí nghiệm để phân tích và lựa chọn kết quả phù hợp theo mong muốn. Ở đây tôi sẽ xuất kết quả 2 thí nghiệm ra file csv để tiện quan sát
import pandas as pd
import wandb
api = wandb.Api()
run1 = api.run("<entity>/<project>/<run_id>")
run2 = api.run("<entity>/<project>/<run_id>")
df = pd.DataFrame([run1.config, run2.config]).transpose()
df.columns =[run1.name, run2.name]print(df[df[run1.name]!= df[run2.name]])Khi xuất ra sẽ có định dạng như sau:
c_10_sgd_0.025_0.01_long_switch base_adam_4_conv_2fc
batch_size 32 16
n_conv_layers 5 4
optimizer rmsprop adam
Cập nhật metrics và configs sau thí nghiệm
Sau khi chạy xong một lần thí nghiệm mà bạn muốn cập nhật lại config và metrics thì có thể dùng API.
import wandb
api = wandb.Api()
run = api.run("username/project/run_id")# Cập nhật configs
run.config["foo"]=32
run.update()# Cập nhật metrics
run.summary["accuracy"]=0.9
run.summary["accuracy_histogram"]= wandb.Histogram(numpy_array)
run.summary.update()# Cập nhật tên metric
run.summary['new_name']="new_acc"del run.summary['old_name']
run.summary.update()Export thông tin tài nguyên hệ thống đã sử dụng sau khi chạy thí nghiệm
import wandb
run = wandb.Api().run("<entity>/<project>/<run_id>")
system_metrics = run.history(stream="events")
system_metrics.to_csv("sys_metrics.csv")Lấy thời gian bắt đầu chạy thí nghiệm
import wandb
api = wandb.Api()
run = api.run("entity/project/run_id")
start_time = run.created_at
Download và upload file trong thí nghiệm
import wandb
api = wandb.Api()# Download model
run = api.run("<entity>/<project>/<run_id>")
run.file("model-best.h5").download()# Upload file
run = api.run("entity/project/run_id")
run.upload_file("file_name.extension")Download tất cả files của thí nghiệm
import wandb
api = wandb.Api()
run = api.run("<entity>/<project>/<run_id>")forfilein run.files():file.download()Xóa tất cả files của thí nghiệm
import wandb
api = wandb.Api()
run = api.run("<entity>/<project>/<run_id>")
extension =".png"
files = run.files()forfilein files:iffile.name.endswith(extension):file.delete()Lấy câu lệnh chạy thí nghiệm
import wandb
api = wandb.Api()
run = api.run("<entity>/<project>/<run_id>")
meta = json.load(run.file("wandb-metadata.json").download())
program =["python"]+[meta["program"]]+ meta["args"]Save & Restore Files
Để lưu file trên cloud, tôi dùng wandb.save và để load lại file thì dùng wandb.restore, khá giống với joblib, numpy, pickle, …
Saving files
Đôi khi, ngoài việc ghi lại dữ liệu như số, chuỗi, image, video, … , bạn còn phải ghi lại trọng số mô hình, source code. Vì vậy W&B hỗ trợ 2 cách để lưu file
- Dùng
wandb.save(filename) - Nhét file vào folder dự án wandb ở local ( file sẽ tự động upload sau khi chạy thí nghiệm )
# Save a model file from the current directory
wandb.save('model.h5')# Save all files that currently exist containing the substring "ckpt"
wandb.save('../logs/*ckpt*')# Save any files starting with "checkpoint" as they're written to
wandb.save(os.path.join(wandb.run.dir,"checkpoint*"))Tùy từng trường hợp mà bạn có thể tùy chỉnh việc lưu file theo ý muốn
- live ( mặc định ): cập nhật file lên server ngay lập tức khi có bất kỳ thay đổi
- now: cập nhật file ngay lập tức nhưng khi có thay đổi thì sẽ không cập nhật
- end: chỉ cập nhật sau khi chạy xong thí nghiệm
Restoring files
Sau khi dùng wandb.save, file của bạn sẽ được lưu lại trên cloud server, nên cho dù bạn có xóa file đấy ở local ( trên máy tính cá nhân ) thì khi dùng wandb.restore vẫn sẽ hồi phục lại file này. Tác dụng thường thấy của việc hồi file:
- Load lại cấu trúc mô hình, trọng số mô hình
- Load lại mô hình kể từ lần training cuối ( last checkpoint ) trong trường hợp fail
best_model = wandb.restore('model-best.h5', run_path="username/project_name/run_name")
weights_file = wandb.restore('weights.h5')
my_predefined_model.load_weights(weights_file.name)Ignore files
Trong trường hợp bạn muốn bỏ qua một file nào đấy thì có thể dùng biến environment WANDB_IGNORE_GLOBS
os.environ['WANDB_IGNORE_GLOBS']='__pycache__/'Remove duplicate files
Nếu bạn đã cập nhật files lên cloud server của W&B thì có thể dùng lệnh wandb sync --clean để xóa các local files.
Environment Variables
Bạn có thể điều chỉnh các thiết lập của W&B qua biến môi trường. Chi tiết bạn có thể tham khảo tại đây: https://docs.wandb.ai/guides/track/advanced/environment-variables
WANDB_API_KEY=$YOUR_API_KEY
WANDB_NAME="My first run"
WANDB_NOTES="Smaller learning rate, more regularization."...
os.environ['WANDB_MODE']='offline'...Lời kết
Thực ra tôi cũng muốn viết dài thêm nhưng chán quá nên tạm dừng ở đây trước đã, khi nào lấy lại tinh thần tôi sẽ viết tiếp phần 2, có thể phần 3 … không biết chừng. Mong các bạn tiếp tục ủng hộ. Cám ơn vì đã ngó qua bài viết này
References
Nguồn: viblo.asia