Việc khắc phục các truy vấn không hợp lệ và giải quyết các vấn đề về hiệu suất có thể đòi hỏi hàng giờ (hoặc hàng ngày) nghiên cứu và thử nghiệm. Đôi khi chúng ta có thể nhanh chóng cắt giảm thời gian đó bằng cách xác định các mẫu thiết kế phổ biến cho thấy TSQL hoạt động kém.
Việc phát triển khả năng nhận dạng mẫu cho những trường hợp dễ phát hiện này có thể cho phép chúng ta tập trung ngay lập tức vào những gì có khả năng xảy ra vấn đề nhất. Trong khi việc điều chỉnh hiệu suất thường có thể bao gồm hàng giờ thu thập các sự kiện mở rộng, dấu vết, kế hoạch thực hiện và thống kê, việc có thể xác định các cạm bẫy tiềm ẩn một cách nhanh chóng có thể làm ngắn mạch tất cả công việc đó.
Mặc dù chúng ta nên thực hiện thẩm định và chứng minh rằng bất kỳ thay đổi nào mà chúng ta thực hiện là tối ưu, nhưng việc biết bắt đầu từ đâu có thể giúp tiết kiệm thời gian rất nhiều!
Các mẹo và thủ thuật
1. OR trong JOIN/WHERE trên nhiều Columns
SQL Server có thể lọc tập dữ liệu một cách hiệu quả bằng cách sử dụng indexes thông qua mệnh đề WHERE hoặc bất kỳ tổ hợp điều kiện nào được phân tách bằng toán tử AND. Phép AND lấy dữ liệu và chia nó thành các phần nhỏ dần dần, cho đến khi chỉ còn lại tập kết quả.
OR là một câu chuyện khác, SQL Server không thể xử lý nó trong một hoạt động duy nhất. Thay vào đó, mỗi thành phần của OR phải được đánh giá độc lập. Khi hoạt động tốn kém này được hoàn thành, kết quả sau đó có thể được kết hợp và trả về.
Tình huống OR hoạt động kém nhất là khi nhiều cột hoặc bảng có liên quan. Không chỉ cần đánh giá từng thành phần của mệnh đề OR, mà cần đi theo đường dẫn đó thông qua các bộ lọc và bảng khác trong truy vấn. Ngay cả khi chỉ có một vài bảng hoặc cột được tham gia, hiệu suất có thể trở nên tồi tệ một cách đáng kinh ngạc.
Dưới đây là một ví dụ rất đơn giản về cách OR có thể khiến hiệu suất trở nên tồi tệ hơn nhiều so với những gì bạn từng tưởng tượng:
SELECT DISTINCT
PRODUCT.ProductID,
PRODUCT.Name
FROM Production.Product PRODUCT
INNER JOIN Sales.SalesOrderDetail DETAIL
ON PRODUCT.ProductID = DETAIL.ProductID
OR PRODUCT.rowguid = DETAIL.rowguid;
Truy vấn đủ đơn giản: 2 bảng và một phép nối kiểm tra cả ProductID và rowguid . Ngay cả khi không có cột nào trong số này được lập chỉ mục, kỳ vọng của chúng ta sẽ là scan bảng Product và SalesOrderDetail. Đây là hiệu suất kết quả của truy vấn này:
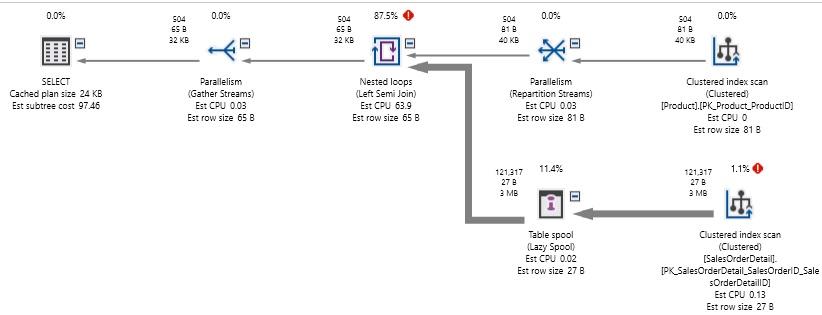

Chúng ta đã scan cả hai bảng, nhưng việc xử lý OR tốn một lượng sức mạnh tính toán vô lý. 1,2 triệu lượt đọc đã được thực hiện trong nỗ lực này! Xem xét rằng Sản phẩm chỉ chứa 504 hàng và SalesOrderDetail chứa 121317 hàng, như vậy chúng ta đọc nhiều dữ liệu hơn toàn bộ nội dung của mỗi bảng này. Ngoài ra, truy vấn mất khoảng 2 giây để thực thi trên một máy tính để bàn hỗ trợ SSD tương đối nhanh.
Điểm rút ra từ bản demo đáng sợ này là SQL Server không thể dễ dàng xử lý một điều kiện OR trên nhiều cột. Cách tốt nhất để đối phó với một OR là loại bỏ nó (nếu có thể) hoặc chia nó thành các truy vấn nhỏ hơn. Việc chia một truy vấn ngắn và đơn giản thành một truy vấn dài hơn, hấp dẫn hơn có vẻ “không thanh lịch”, nhưng khi giải quyết các vấn đề OR, đó thường là lựa chọn tốt nhất:
SELECT
PRODUCT.ProductID,
PRODUCT.Name
FROM Production.Product PRODUCT
INNER JOIN Sales.SalesOrderDetail DETAIL
ON PRODUCT.ProductID = DETAIL.ProductID
UNION
SELECT
PRODUCT.ProductID,
PRODUCT.Name
FROM Production.Product PRODUCT
INNER JOIN Sales.SalesOrderDetail DETAIL
ON PRODUCT.rowguid = DETAIL.rowguid
Trong lần viết lại này, chúng ta đã lấy từng thành phần của OR và biến nó thành câu lệnh SELECT của riêng nó. UNION nối tập kết quả và loại bỏ các bản sao. Đây là hiệu suất kết quả:
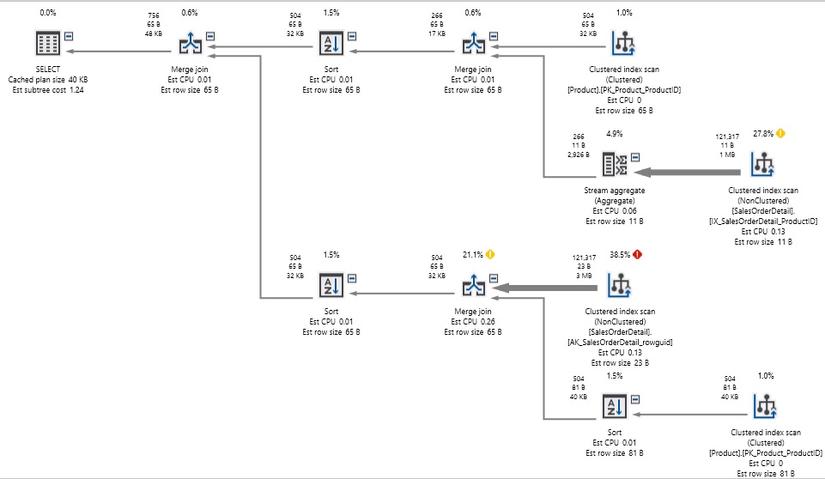

Kế hoạch thực thi trở nên phức tạp hơn đáng kể, vì truy vấn mỗi bảng hai lần, thay vì một lần, nhưng chúng tôi không còn cần phải chơi pin-the-tail-on-the-donkey với các bộ kết quả như trước. Số lượt đọc đã được cắt giảm từ 1,2 triệu xuống còn 750 và truy vấn được thực hiện trong vòng chưa đầy một giây, thay vì trong 2 giây.
Lưu ý rằng vẫn còn một lượng lớn các lần quét chỉ mục trong kế hoạch thực thi, nhưng mặc dù cần phải quét các bảng bốn lần để đáp ứng truy vấn nhưng hiệu suất đã tốt hơn nhiều so với trước đây.
Hãy thận trọng khi viết các truy vấn với mệnh đề OR. Kiểm tra và xác minh rằng hiệu suất là đủ và bạn không vô tình giới thiệu một quả bom hiệu suất tương tự như ở trên. Nếu một ứng dụng hoạt động kém và chạy trên OR trên các cột hoặc bảng khác nhau, thì hãy tập trung vào đó như một nguyên nhân có thể xảy ra. Đây là một mẫu truy vấn dễ xác định thường sẽ dẫn đến hiệu suất kém.
2. Tìm kiếm chuỗi ký tự đại diện (Wildcard String Searches)
Tìm kiếm chuỗi một cách hiệu quả có thể là một thách thức và có nhiều cách để tìm kiếm chuỗi không hiệu quả hơn là hiệu quả. Đối với các cột chuỗi được tìm kiếm thường xuyên, chúng tôi cần đảm bảo rằng:
- Các chỉ mục được đánh trên các cột được tìm kiếm.
- Các chỉ mục đó có thể được sử dụng.
- Nếu không, chúng ta có thể sử dụng các chỉ mục toàn văn (full-text indexes) không?
- Nếu không, chúng ta có thể sử dụng hàm băm, n-gam hoặc một số giải pháp khác không?
Nếu không sử dụng các tính năng bổ sung hoặc xem xét thiết kế, SQL Server không tốt trong việc tìm kiếm chuỗi mờ. Nghĩa là, nếu muốn phát hiện sự hiện diện của một chuỗi ở bất kỳ vị trí nào trong một cột, thì việc lấy dữ liệu đó sẽ không hiệu quả:
SELECT
Person.BusinessEntityID,
Person.FirstName,
Person.LastName,
Person.MiddleName
FROM Person.Person
WHERE Person.LastName LIKE '%For%';
Trong tìm kiếm chuỗi này, chúng tôi đang kiểm tra LastName để tìm bất kỳ sự xuất hiện nào của “For” ở bất kỳ vị trí nào trong chuỗi. Khi “%” được đặt ở đầu một chuỗi, chúng tôi không thể sử dụng bất kỳ chỉ mục tăng dần nào. Tương tự, khi “%” ở cuối chuỗi, việc sử dụng chỉ mục giảm dần cũng không thể thực hiện được. Truy vấn trên sẽ dẫn đến hiệu suất sau:


Như mong đợi, kết quả truy vấn quét trên Person.Person . Cách duy nhất để biết liệu một chuỗi con có tồn tại trong một cột văn bản hay không là lướt qua mọi ký tự trong mỗi hàng, tìm kiếm các lần xuất hiện của chuỗi đó. Trên một bảng nhỏ, điều này có thể chấp nhận được, nhưng đối với bất kỳ tập dữ liệu lớn nào, điều này sẽ chậm và khó chờ đợi.
Có nhiều cách để “tấn coong” tình huống này, bao gồm:
- Đánh giá lại ứng dụng. Chúng ta có thực sự cần thực hiện tìm kiếm theo ký tự đại diện theo cách này không? Người dùng có thực sự muốn tìm kiếm tất cả các phần của cột này cho một chuỗi nhất định không? Nếu không, hãy loại bỏ khả năng này và vấn đề sẽ biến mất!
- Chúng ta có thể áp dụng bất kỳ bộ lọc nào khác cho truy vấn để giảm kích thước dữ liệu trước khi bẻ khóa so sánh chuỗi không? Nếu có thể lọc theo ngày, giờ, trạng thái hoặc một số loại tiêu chí thường được sử dụng khác, có thể giảm dữ liệu cần scan xuống một lượng đủ nhỏ để truy vấn hoạt động có thể chấp nhận được.
- Chúng ta có thể thực hiện tìm kiếm chuỗi đứng đầu, thay vì tìm kiếm theo ký tự đại diện không? Có thể thay đổi “% For%” thành “For%” không?
- Lập chỉ mục toàn văn có phải là một tùy chọn khả dụng không? Chúng ta có thể thực hiện và sử dụng nó không?
- Chúng ta có thể triển khai giải pháp băm hoặc n-gram truy vấn không?
3 tùy chọn đầu tiên ở trên là những cân nhắc về thiết kế / kiến trúc vì chúng là các giải pháp tối ưu hóa.
Lập chỉ mục toàn văn bản là một tính năng trong SQL Server có thể tạo chỉ mục cho phép tìm kiếm chuỗi linh hoạt trên các cột văn bản. Điều này bao gồm tìm kiếm theo ký tự đại diện, nhưng cũng tìm kiếm theo ngôn ngữ sử dụng các quy tắc của một ngôn ngữ nhất định để đưa ra quyết định thông minh về việc một từ hoặc cụm từ có đủ tương tự với nội dung của cột để được coi là phù hợp hay không. Mặc dù linh hoạt, Full-Text là một tính năng bổ sung cần được cài đặt, cấu hình và duy trì. Đối với một số ứng dụng tập trung vào chuỗi, nó có thể là giải pháp hoàn hảo!
Một tùy chọn cuối cùng có thể là một giải pháp tuyệt vời cho các cột chuỗi ngắn hơn. N-Grams là các phân đoạn chuỗi có thể được lưu trữ riêng biệt với dữ liệu chúng ta đang tìm kiếm và có thể cung cấp khả năng tìm kiếm các chuỗi con mà không cần phải quét một bảng lớn. Trước khi thảo luận về chủ đề này, điều quan trọng là phải hiểu đầy đủ các quy tắc tìm kiếm được sử dụng bởi một ứng dụng. Ví dụ:
- Có số lượng ký tự tối thiểu hoặc tối đa được phép trong một tìm kiếm không?
- Các tìm kiếm trống (quét bảng) có được phép không?
- Có được phép sử dụng nhiều từ / cụm từ không?
- Chúng ta có cần lưu trữ các chuỗi con ở đầu một chuỗi không? Chúng có thể được thu thập bằng cách tìm kiếm chỉ mục nếu cần.
Khi những cân nhắc này được đánh giá, chúng ta có thể lấy một cột chuỗi và chia nó thành các đoạn chuỗi. Ví dụ: hãy xem xét một hệ thống tìm kiếm có độ dài tìm kiếm tối thiểu là 3 ký tự và từ được lưu trữ “Dinosaur”. Dưới đây là các chuỗi con của Dinosaur có độ dài 3 ký tự trở lên (bỏ qua phần bắt đầu của chuỗi, có thể được tập hợp riêng biệt & nhanh chóng với tìm kiếm chỉ mục dựa trên cột này):
ino, inos, inosa, inosau, inosaur, nos, nosa, nosau, nosaur, osa, osau, osaur, sau, saur, aur.
Nếu chúng ta tạo một bảng riêng biệt lưu trữ từng chuỗi con này (còn được gọi là n-gram), chúng ta có thể liên kết n-gram đó với hàng trong bảng lớn có từ khủng long. Thay vì quét một bảng lớn để tìm kết quả, thay vào đó chúng ta có thể thực hiện tìm kiếm bình đẳng đối với bảng n-gram. Ví dụ: nếu tôi đã thực hiện tìm kiếm theo ký tự đại diện cho “dino”, tìm kiếm của tôi có thể được chuyển hướng đến tìm kiếm trông giống như sau:
SELECT
n_gram_table.my_big_table_id_column
FROM dbo.n_gram_table
WHERE n_gram_table.n_gram_data = 'Dino';
Giả sử n_gram_data được lập chỉ mục, sẽ nhanh chóng trả về tất cả các ID cho bảng lớn có từ Dino ở bất kỳ đâu trong đó. Bảng n-gram chỉ yêu cầu 2 cột và có thể giới hạn kích thước của chuỗi n-gram bằng cách sử dụng các quy tắc ứng dụng đã xác định ở trên. Ngay cả khi bảng này lớn, nó vẫn có khả năng cung cấp khả năng tìm kiếm rất nhanh.
Chi phí của cách tiếp cận này là bảo trì. Chúng ta cần cập nhật bảng n-gram mỗi khi một hàng được chèn, xóa hoặc dữ liệu chuỗi trong đó được cập nhật. Ngoài ra, số lượng n gam trên mỗi hàng sẽ tăng nhanh khi kích thước của cột tăng lên. Do đó, đây là một cách tiếp cận tuyệt vời cho các chuỗi ngắn hơn, chẳng hạn như tên, mã zip hoặc số điện thoại. Đây là một giải pháp rất tốn kém cho các chuỗi dài hơn, chẳng hạn như văn bản email, mô tả và các cột có độ dài MAX hoặc dạng tự do khác.
Tóm tắt lại nhanh chóng: Tìm kiếm chuỗi ký tự đại diện vốn đã rất tốn kém. Vũ khí tốt nhất để chống lại nó dựa trên các quy tắc thiết kế và kiến trúc cho phép loại bỏ “%” hàng đầu hoặc giới hạn cách tìm kiếm theo những cách cho phép triển khai các bộ lọc hoặc giải pháp khác.
3. Thao tác ghi lớn (Large Write Operations)
Sau khi thảo luận về lý do tại sao iterator có thể gây ra hiệu suất kém, bây giờ chúng ta sẽ khám phá một kịch bản trong đó iterator lại NÂNG CAO hiệu suất. Một thành phần của tối ưu hóa chưa được thảo luận ở đây là sự tranh chấp. Khi chúng tôi thực hiện bất kỳ thao tác nào đối với dữ liệu, các khóa sẽ được thực hiện dựa trên một số lượng dữ liệu để đảm bảo rằng kết quả nhất quán và không ảnh hưởng đến các truy vấn khác đang được thực hiện dựa trên cùng dữ liệu của những người khác ngoài chúng tôi.
Khóa và chặn (Locking and blocking) là những điều tốt ở chỗ chúng bảo vệ dữ liệu khỏi bị hỏng và bảo vệ chúng ta khỏi các tập hợp kết quả xấu. Tuy nhiên, khi tranh cãi tiếp tục trong một thời gian dài, các truy vấn quan trọng có thể bị buộc phải chờ đợi, dẫn đến người dùng không hài lòng và dẫn đến khiếu nại về độ trễ.
Các hoạt động ghi lớn là hậu quả để tranh cãi vì chúng thường sẽ khóa toàn bộ bảng trong thời gian cần thiết để cập nhật dữ liệu, kiểm tra các ràng buộc, cập nhật chỉ mục và trình kích hoạt quy trình (nếu có). Lớn như thế nào là lớn? Không có quy tắc nghiêm ngặt nào ở đây. Trên một bảng không có trình kích hoạt hoặc khóa ngoại, số lượng lớn có thể là 50.000, 100.000 hoặc 1.000.000 hàng. Trên một bảng có nhiều ràng buộc và kích hoạt, lớn có thể là 2.000. Cách duy nhất để xác nhận rằng đây là một vấn đề là kiểm tra nó, quan sát nó và phản hồi phù hợp.
Ngoài sự tranh cãi, các toán tử ghi lớn sẽ tạo ra rất nhiều sự phát triển tệp nhật ký. Bất cứ khi nào ghi khối lượng dữ liệu lớn bất thường, hãy theo dõi nhật ký giao dịch và xác minh rằng bạn không có nguy cơ lấp đầy hoặc tệ hơn là lấp đầy vị trí lưu trữ vật lý của nó.
Lưu ý rằng nhiều hoạt động ghi lớn sẽ là kết quả của công việc của chính chúng tôi: Bản phát hành phần mềm, quy trình tải kho dữ liệu, quy trình ETL và các hoạt động tương tự khác có thể cần ghi một lượng rất lớn dữ liệu, ngay cả khi nó được thực hiện không thường xuyên. Chúng ta tùy thuộc vào việc xác định mức độ tranh chấp được phép trong các bảng trước khi chạy các quy trình này. Nếu đang tải một bảng lớn trong thời gian bảo trì khi không có ai khác sử dụng nó, thì có thể tự do triển khai bằng bất kỳ chiến lược nào chúng ta muốn. Thay vào đó, nếu chúng ta ghi một lượng lớn dữ liệu vào một site được sử dụng liên tục, thì việc giảm các hàng được sửa đổi cho mỗi thao tác sẽ là một biện pháp bảo vệ tốt chống lại sự tranh chấp.
Các hoạt động phổ biến có thể dẫn đến ghi lớn là:
- Thêm một cột mới vào bảng và lấp đầy cột đó trên toàn bộ bảng.
- Cập nhật một cột trên toàn bộ bảng.
- Thay đổi kiểu dữ liệu của một cột.
- Nhập một khối lượng lớn dữ liệu mới.
- Lưu trữ hoặc xóa một khối lượng lớn dữ liệu cũ.
Đây có thể không phải là một mối quan tâm về hiệu suất, nhưng hiểu được ảnh hưởng của các hoạt động ghi rất lớn có thể tránh các sự kiện bảo trì quan trọng hoặc các bản phát hành đi chệch hướng một cách bất ngờ.
4. Thiếu chỉ mục (Missing Indexes)
SQL Server, thông qua Management Studio GUI, XML kế hoạch thực thi hoặc các DMV chỉ mục bị thiếu, sẽ cho chúng ta biết khi nào có các chỉ mục bị thiếu có khả năng giúp truy vấn hoạt động tốt hơn:

Cảnh báo này hữu ích ở chỗ nó cho biết rằng có khả năng dễ dàng sửa chữa để cải thiện hiệu suất truy vấn. Nó cũng gây hiểu lầm ở chỗ một chỉ mục bổ sung có thể không phải là cách tốt nhất để giải quyết vấn đề về độ trễ. Văn bản màu xanh lá cây cung cấp cho chúng ta tất cả các chi tiết của một chỉ mục mới, nhưng chúng ta cần thực hiện một chút công việc trước khi xem xét thực hiện lời khuyên của SQL Server:
- Có bất kỳ chỉ mục hiện có nào tương tự như chỉ mục này có thể được sửa đổi để phù hợp với trường hợp sử dụng này không?
- Chúng ta có cần tất cả các cột INCLUDE không? Liệu một chỉ mục chỉ trên các cột sắp xếp có đủ tốt không?
- Mức độ ảnh hưởng của chỉ mục cao như thế nào? Nó sẽ cải thiện truy vấn 98% hay chỉ 5%.
- Chỉ mục này đã tồn tại nhưng vì lý do nào đó mà trình tối ưu hóa truy vấn không chọn nó?
Thông thường, các chỉ mục được đề xuất là quá mức. Ví dụ, đây là câu lệnh tạo chỉ mục cho kế hoạch từng phần được hiển thị ở trên:
CREATE NONCLUSTERED INDEX <Name of Missing Index, sysname,>
ON Sales.SalesOrderHeader (Status,SalesPersonID)
INCLUDE (SalesOrderID,SubTotal)
Trong trường hợp này, đã có một chỉ mục trên SalesPersonID . Trạng thái xảy ra là một cột trong đó bảng chủ yếu chứa một giá trị, có nghĩa là với tư cách là một cột sắp xếp, nó sẽ không cung cấp nhiều giá trị. Tác động của 19% không phải là quá ấn tượng. Cuối cùng, chúng tôi sẽ phải hỏi liệu truy vấn có đủ quan trọng để đảm bảo sự cải thiện này hay không. Nếu nó được thực hiện một triệu lần một ngày, thì có lẽ tất cả công việc này để cải thiện 20% là xứng đáng.
Xem xét một đề xuất chỉ mục thay thế khác:
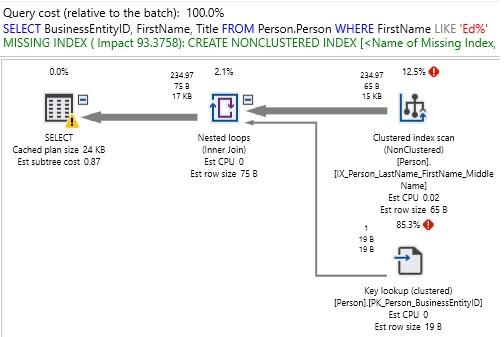
Ở đây, chỉ mục bị thiếu được đề xuất là:
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>]
ON [Person].[Person] ([FirstName])
INCLUDE ([BusinessEntityID],[Title])
Lần này, chỉ mục được đề xuất sẽ cải thiện 93% và xử lý một cột không được lập chỉ mục ( FirstName ). Nếu đây hoàn toàn là một truy vấn được chạy thường xuyên, thì việc thêm chỉ mục này có thể sẽ là một bước đi thông minh. Chúng ta có thêm BusinessEntityID và Title là có cột INCLUDE? Đây là một câu hỏi chủ quan hơn nhiều và chúng ta cần quyết định xem truy vấn có đủ quan trọng để đảm bảo rằng không bao giờ có một tra cứu chính để kéo các cột bổ sung đó trở lại từ chỉ mục được phân cụm hay không. Câu hỏi này là sự lặp lại của, “Làm thế nào để chúng tôi biết khi nào hiệu suất của một truy vấn là tối ưu?”. Nếu chỉ mục không bao phủ đủ tốt, thì việc dừng ở đó sẽ là quyết định chính xác vì nó sẽ tiết kiệm tài nguyên máy tính cần thiết để lưu trữ các cột bổ sung. Nếu hiệu suất vẫn không đủ tốt, thì việc thêm các cột INCLUDE sẽ là bước tiếp theo hợp lý.
Miễn là chúng ta nhớ rằng các chỉ mục yêu cầu bảo trì và làm chậm hoạt động ghi, chúng ta có thể tiếp cận lập chỉ mục từ góc độ thực dụng và đảm bảo rằng chúng ta không mắc phải bất kỳ sai lầm nào sau đây:
-
Over-Indexing a Table
Khi một bảng có quá nhiều chỉ mục, các thao tác ghi sẽ trở nên chậm hơn vì mọi CẬP NHẬT, XÓA và CHÈN chạm vào cột được lập chỉ mục phải cập nhật các chỉ mục trên đó. Ngoài ra, các chỉ mục đó chiếm không gian lưu trữ cũng như trong các bản sao lưu cơ sở dữ liệu. “Quá nhiều” là mơ hồ, nhưng nhấn mạnh rằng cuối cùng hiệu suất ứng dụng là chìa khóa để xác định xem mọi thứ có tối ưu hay không. -
Under-Indexing a Table
under-indexed table không phục vụ các truy vấn đọc một cách hiệu quả. Lý tưởng nhất, các truy vấn phổ biến nhất được thực thi đối với một bảng sẽ được hưởng lợi từ các chỉ mục. Các truy vấn ít thường xuyên hơn được đánh giá theo nhu cầu của từng trường hợp và được lập chỉ mục khi có lợi. Khi khắc phục sự cố hiệu suất đối với các bảng có ít hoặc không có chỉ mục không phân cụm, thì vấn đề có thể là do lập chỉ mục dưới mức. Trong những trường hợp này, hãy cảm thấy được trao quyền để thêm các chỉ mục để cải thiện hiệu suất khi cần thiết! -
No Clustered Index/Primary Key
Tất cả các bảng phải có một chỉ mục được phân nhóm và một khóa chính. Các chỉ mục được phân cụm hầu như sẽ luôn hoạt động tốt hơn so với heap và sẽ cung cấp cơ sở hạ tầng cần thiết để thêm các chỉ mục không phân cụm một cách hiệu quả khi cần thiết. Khóa chính cung cấp thông tin có giá trị cho trình tối ưu hóa truy vấn giúp trình tối ưu hóa truy vấn đưa ra quyết định thông minh khi tạo kế hoạch thực thi. Nếu bạn gặp phải một bảng không có chỉ mục được phân cụm hoặc không có khóa chính, hãy xem xét các ưu tiên hàng đầu này để nghiên cứu và giải quyết trước khi tiếp tục nghiên cứu thêm.
5. High Table Count – Quá nhiều bảng trong 1 truy vấn
Trình tối ưu hóa truy vấn trong SQL Server phải đối mặt với thách thức giống như bất kỳ trình tối ưu hóa truy vấn quan hệ nào: Nó cần phải tìm ra một kế hoạch thực thi tốt khi đối mặt với nhiều tùy chọn trong một khoảng thời gian rất ngắn. Về cơ bản nó là chơi một trò chơi cờ vua và đánh giá nước đi sau khi nước đi. Với mỗi lần đánh giá, nó sẽ loại bỏ một phần các kế hoạch tương tự như kế hoạch dưới mức tối ưu, hoặc để một bên làm kế hoạch ứng viên. High Table Count trong một truy vấn sẽ tương đương với một bàn cờ lớn hơn. Với nhiều tùy chọn hơn đáng kể có sẵn, SQL Server có nhiều việc phải làm hơn, nhưng không thể mất nhiều thời gian hơn để xác định kế hoạch sử dụng.
Mỗi bảng được thêm vào một truy vấn sẽ làm tăng độ phức tạp của nó lên một lượng giai thừa. Mặc dù trình tối ưu hóa nói chung sẽ đưa ra các quyết định tốt, ngay cả khi đối mặt với nhiều bảng, chúng ta sẽ làm tăng nguy cơ có các kế hoạch không hiệu quả khi mỗi bảng được thêm vào một truy vấn. Điều này không có nghĩa là các truy vấn có nhiều bảng là không tốt, nhưng chúng ta cần thận trọng khi tăng kích thước của một truy vấn. Đối với mỗi tập hợp bảng, nó cần xác định thứ tự nối, kiểu nối và cách / thời điểm áp dụng bộ lọc và tổng hợp.
Dựa trên cách các bảng được nối với nhau, một truy vấn sẽ thuộc một trong hai dạng cơ bản:
- Left-Deep Tree : A join B, B join C, C join D, D join E, v.v. Đây là một truy vấn trong đó hầu hết các bảng được nối tuần tự với nhau.
- Bushy Tree : A join B, A join C, B join D, C join E, v.v. Đây là một truy vấn trong đó các bảng phân nhánh thành nhiều đơn vị logic trong mỗi nhánh của cây.
Đây là một biểu diễn đồ họa của một cây rậm rạp, trong đó nhánh nối trở lên vào tập kết quả:
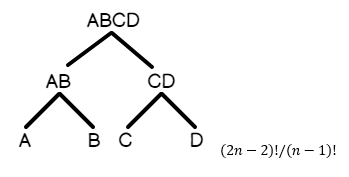
Tương tự, đây là hình đại diện của một cây sâu bên trái trông như thế nào.
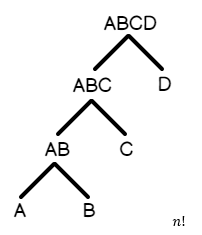
Vì Left-Deep Tree được sắp xếp tự nhiên hơn dựa trên cách các bảng được nối với nhau, nên số lượng kế hoạch thực thi ứng viên cho truy vấn ít hơn đối với Bushy Tree.
Để nhấn mạnh tính khổng lồ của phép tính đằng sau số bảng, hãy xem xét một truy vấn truy cập 12 bảng:
SELECT TOP 25
Product.ProductID,
Product.Name AS ProductName,
Product.ProductNumber,
CostMeasure.UnitMeasureCode,
CostMeasure.Name AS CostMeasureName,
ProductVendor.AverageLeadTime,
ProductVendor.StandardPrice,
ProductReview.ReviewerName,
ProductReview.Rating,
ProductCategory.Name AS CategoryName,
ProductSubCategory.Name AS SubCategoryName
FROM Production.Product
INNER JOIN Production.ProductSubCategory
ON ProductSubCategory.ProductSubcategoryID = Product.ProductSubcategoryID
INNER JOIN Production.ProductCategory
ON ProductCategory.ProductCategoryID = ProductSubCategory.ProductCategoryID
INNER JOIN Production.UnitMeasure SizeUnitMeasureCode
ON Product.SizeUnitMeasureCode = SizeUnitMeasureCode.UnitMeasureCode
INNER JOIN Production.UnitMeasure WeightUnitMeasureCode
ON Product.WeightUnitMeasureCode = WeightUnitMeasureCode.UnitMeasureCode
INNER JOIN Production.ProductModel
ON ProductModel.ProductModelID = Product.ProductModelID
LEFT JOIN Production.ProductModelIllustration
ON ProductModel.ProductModelID = ProductModelIllustration.ProductModelID
LEFT JOIN Production.ProductModelProductDescriptionCulture
ON ProductModelProductDescriptionCulture.ProductModelID = ProductModel.ProductModelID
LEFT JOIN Production.ProductDescription
ON ProductDescription.ProductDescriptionID = ProductModelProductDescriptionCulture.ProductDescriptionID
LEFT JOIN Production.ProductReview
ON ProductReview.ProductID = Product.ProductID
LEFT JOIN Purchasing.ProductVendor
ON ProductVendor.ProductID = Product.ProductID
LEFT JOIN Production.UnitMeasure CostMeasure
ON ProductVendor.UnitMeasureCode = CostMeasure.UnitMeasureCode
ORDER BY Product.ProductID DESC;
Với 12 bảng trong một truy vấn kiểu tương đối bận, phép toán sẽ giải ra:
(2n-2)! / (n-1)! = (2 * 12-1)! / (12-1)! = 28.158.588.057.600 kế hoạch thực hiện có thể.
Nếu truy vấn đã xảy ra về bản chất tuyến tính hơn, thì chúng ta sẽ có:
n! = 12! = 479.001.600 kế hoạch thực hiện có thể.
Điều này chỉ dành cho 12 bảng! Hãy tưởng tượng một truy vấn trên 20, 30 hoặc 50 bảng! Trình tối ưu hóa thường có thể cắt những con số đó xuống rất nhanh bằng cách loại bỏ toàn bộ hàng loạt các tùy chọn phụ tối ưu, nhưng khả năng nó có thể làm như vậy và tạo ra một kế hoạch tốt sẽ giảm khi số lượng bảng tăng lên.
Một số cách hữu ích để tối ưu hóa một truy vấn đang bị ảnh hưởng do quá nhiều bảng là gì?
- Di chuyển siêu dữ liệu hoặc bảng tra cứu vào một truy vấn riêng để đặt dữ liệu này vào một bảng tạm thời.
- Các phép join được sử dụng để trả về một hằng số có thể được chuyển đến một tham số hoặc biến.
- Chia một truy vấn lớn thành các truy vấn nhỏ hơn mà các tập dữ liệu của chúng sau này có thể được kết hợp với nhau khi đã sẵn sàng.
- Đối với các truy vấn được sử dụng rất nhiều, hãy xem xét chế độ xem được lập chỉ mục để hợp lý hóa quyền truy cập liên tục vào dữ liệu quan trọng.
- Loại bỏ các bảng, truy vấn con và liên kết không cần thiết.
Việc chia nhỏ một truy vấn lớn thành các truy vấn nhỏ hơn yêu cầu rằng sẽ không có sự thay đổi dữ liệu giữa các truy vấn đó mà sẽ làm mất hiệu lực của tập kết quả bằng cách nào đó. Nếu một truy vấn cần phải là một tập hợp nguyên tử, thì bạn có thể cần sử dụng kết hợp các mức cô lập (isolation level), transactions và locking để đảm bảo tính toàn vẹn của dữ liệu.
Thường xuyên hơn khi chúng ta kết hợp một số lượng lớn các bảng với nhau, chúng ta có thể chia nhỏ truy vấn thành các đơn vị logic nhỏ hơn có thể được thực thi riêng biệt. Đối với truy vấn ví dụ trước đó trên 12 bảng, chúng ta có thể rất dễ dàng loại bỏ một vài bảng không sử dụng và tách truy xuất dữ liệu thành hai truy vấn riêng biệt:
SELECT TOP 25
Product.ProductID,
Product.Name AS ProductName,
Product.ProductNumber,
ProductCategory.Name AS ProductCategory,
ProductSubCategory.Name AS ProductSubCategory,
Product.ProductModelID
INTO #Product
FROM Production.Product
INNER JOIN Production.ProductSubCategory
ON ProductSubCategory.ProductSubcategoryID = Product.ProductSubcategoryID
INNER JOIN Production.ProductCategory
ON ProductCategory.ProductCategoryID = ProductSubCategory.ProductCategoryID
ORDER BY Product.ModifiedDate DESC;
SELECT
Product.ProductID,
Product.ProductName,
Product.ProductNumber,
CostMeasure.UnitMeasureCode,
CostMeasure.Name AS CostMeasureName,
ProductVendor.AverageLeadTime,
ProductVendor.StandardPrice,
ProductReview.ReviewerName,
ProductReview.Rating,
Product.ProductCategory,
Product.ProductSubCategory
FROM #Product Product
INNER JOIN Production.ProductModel
ON ProductModel.ProductModelID = Product.ProductModelID
LEFT JOIN Production.ProductReview
ON ProductReview.ProductID = Product.ProductID
LEFT JOIN Purchasing.ProductVendor
ON ProductVendor.ProductID = Product.ProductID
LEFT JOIN Production.UnitMeasure CostMeasure
ON ProductVendor.UnitMeasureCode = CostMeasure.UnitMeasureCode;
DROP TABLE #Product;
Đây chỉ là một trong nhiều giải pháp khả thi, nhưng là một cách để giảm một truy vấn lớn hơn, phức tạp hơn thành hai truy vấn đơn giản hơn. Như một phần thưởng, chúng ta có thể xem xét các bảng có liên quan và xóa bất kỳ bảng, cột, biến không cần thiết nào hoặc bất kỳ thứ gì khác có thể không cần thiết để trả về dữ liệu mà chúng ta đang tìm kiếm.
Số lượng bảng là một yếu tố đóng góp lớn cho các kế hoạch thực thi kém vì nó buộc trình tối ưu hóa truy vấn sàng lọc qua một tập kết quả lớn hơn và loại bỏ các kết quả có khả năng hợp lệ hơn để tìm kiếm một kế hoạch tuyệt vời trong vòng chưa đầy một giây. Nếu bạn đang đánh giá một truy vấn hoạt động kém có số lượng bảng rất lớn, hãy thử chia nó thành các truy vấn nhỏ hơn. Chiến thuật này có thể không phải lúc nào cũng cung cấp một cải tiến đáng kể, nhưng thường hiệu quả khi các cách khác đã được khám phá và có nhiều bảng đang được đọc cùng nhau trong một truy vấn.
Gợi ý truy vấn – Query Hints
Gợi ý truy vấn là một hướng rõ ràng đối với trình tối ưu hóa truy vấn. Chúng ta đang bỏ qua một số quy tắc được sử dụng bởi trình tối ưu hóa để buộc nó hoạt động theo những cách mà nó thường không làm. Về mặt này, nó giống như một chỉ thị hơn là một gợi ý.
Gợi ý truy vấn thường được sử dụng khi gặp sự cố về hiệu suất và thêm gợi ý sẽ khắc phục nó một cách nhanh chóng và kỳ diệu. Có khá nhiều gợi ý có sẵn trong SQL Server ảnh hưởng đến mức độ cô lập, kiểu nối, khóa bảng và hơn thế nữa. Mặc dù các gợi ý có thể có những mục đích sử dụng hợp pháp, nhưng chúng gây nguy hiểm cho hiệu suất vì nhiều lý do:
-
Những thay đổi trong tương lai đối với dữ liệu hoặc giản đồ có thể dẫn đến một gợi ý không còn áp dụng được nữa và trở thành trở ngại cho đến khi bị loại bỏ.
-
Các gợi ý có thể che khuất các vấn đề lớn hơn, chẳng hạn như thiếu chỉ mục, yêu cầu dữ liệu quá lớn hoặc logic nghiệp vụ bị hỏng. Giải quyết gốc rễ của một vấn đề tốt hơn là giải quyết một triệu chứng.
-
Các gợi ý có thể dẫn đến hành vi không mong muốn, chẳng hạn như dữ liệu xấu từ các lần đọc bẩn thông qua việc sử dụng NOLOCK.
-
Việc áp dụng gợi ý để giải quyết trường hợp cạnh có thể làm giảm hiệu suất cho tất cả các trường hợp khác.
Nguyên tắc chung là áp dụng gợi ý truy vấn càng ít càng tốt, chỉ sau khi đã tiến hành nghiên cứu đầy đủ và chỉ khi chúng tôi chắc chắn sẽ không có tác động xấu của thay đổi. Chúng nên được sử dụng như một con dao mổ khi tất cả các lựa chọn khác không thành công. Một số lưu ý về các gợi ý thường được sử dụng: -
NOLOCK : Trong trường hợp dữ liệu bị khóa, điều này sẽ yêu cầu SQL Server đọc dữ liệu từ giá trị đã biết cuối cùng có sẵn, còn được gọi là đọc bẩn. Vì có thể sử dụng một số giá trị cũ và một số giá trị mới, tập dữ liệu có thể chứa những điểm không nhất quán. Không sử dụng điều này ở bất kỳ nơi nào mà chất lượng dữ liệu là quan trọng.
-
RECOMPILE : Thêm điều này vào cuối truy vấn sẽ dẫn đến một kế hoạch thực thi mới được tạo mỗi khi truy vấn này được thực thi. Điều này không nên được sử dụng trên một truy vấn được thực thi thường xuyên, vì chi phí để tối ưu hóa một truy vấn là không nhỏ. Tuy nhiên, đối với các báo cáo hoặc quy trình không thường xuyên, đây có thể là một cách hiệu quả để tránh sử dụng lại kế hoạch không mong muốn. Điều này thường được sử dụng như một dải băng khi số liệu thống kê đã lỗi thời hoặc đang xảy ra đánh giá thông số.
-
MERGE / HASH / LOOP : Điều này yêu cầu trình tối ưu hóa truy vấn sử dụng một loại liên kết cụ thể như một phần của hoạt động kết hợp. Điều này là siêu rủi ro vì phép kết hợp tối ưu sẽ thay đổi khi dữ liệu, lược đồ và tham số phát triển theo thời gian. Mặc dù điều này có thể khắc phục sự cố ngay bây giờ, nhưng nó sẽ giới thiệu một yếu tố nợ kỹ thuật sẽ vẫn tồn tại trong thời gian dài như gợi ý.
-
OPTIMIZE FOR : Có thể chỉ định một giá trị tham số để tối ưu hóa truy vấn. Điều này thường được sử dụng khi chúng ta muốn hiệu suất được kiểm soát cho một trường hợp sử dụng rất phổ biến để các ngoại lệ không gây “ô nhieemx” bộ nhớ cache của kế hoạch. Tương tự như các gợi ý tham gia, điều này là mong manh và khi logic nghiệp vụ thay đổi, cách sử dụng gợi ý này có thể trở nên lỗi thời.
Hãy xem xét truy vấn tìm kiếm tên của chúng ta từ trước đó:
SELECT
e.BusinessEntityID,
p.Title,
p.FirstName,
p.LastName
FROM HumanResources.Employee e
INNER JOIN Person.Person p
ON p.BusinessEntityID = e.BusinessEntityID
WHERE FirstName LIKE 'E%'
Chúng ta có thể buộc một MERGE JOIN trong vị từ nối:
SELECT
e.BusinessEntityID,
p.Title,
p.FirstName,
p.LastName
FROM HumanResources.Employee e
INNER MERGE JOIN Person.Person p
ON p.BusinessEntityID = e.BusinessEntityID
WHERE FirstName LIKE 'E%'
Khi làm như vậy, chúng ta có thể quan sát thấy hiệu suất tốt hơn trong một số trường hợp nhất định, nhưng cũng có thể quan sát thấy hiệu suất rất kém ở những người khác:
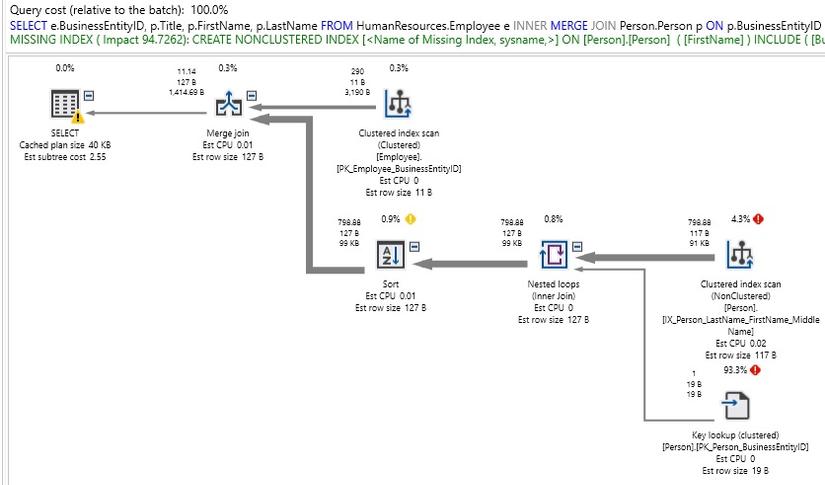

Đối với một truy vấn tương đối đơn giản, điều này là khá xấu! Cũng xin lưu ý rằng loại join có việc sử dụng chỉ mục hạn chế và kết quả là chúng ta nhận được một đề xuất chỉ mục mà chúng ta có thể không cần. Trên thực tế, buộc MERGE JOIN đã thêm các toán tử bổ sung vào kế hoạch thực thi của chúng ta để sắp xếp các đầu ra một cách thích hợp để sử dụng trong việc giải quyết tập kết quả của chúng ta. Chúng ta có thể buộc một HASH JOIN tương tự:
SELECT
e.BusinessEntityID,
p.Title,
p.FirstName,
p.LastName
FROM HumanResources.Employee e
INNER HASH JOIN Person.Person p
ON p.BusinessEntityID = e.BusinessEntityID
WHERE FirstName LIKE 'E%'
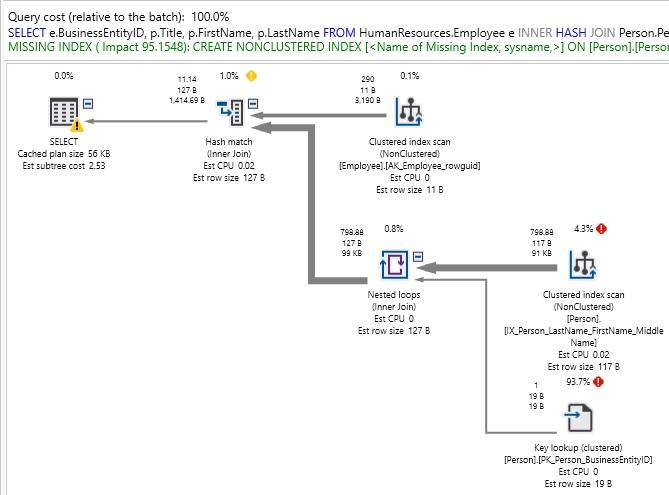

Một lần nữa, kế hoạch không đẹp! Lưu ý cảnh báo trong tab đầu ra cho biết rằng thứ tự tham gia đã được thực thi theo lựa chọn tham gia của chúng tôi. Điều này rất quan trọng vì nó cho biết kiểu kết hợp mà chúng ta đã chọn cũng hạn chế các cách có thể để sắp xếp các bảng trong quá trình tối ưu hóa. Về cơ bản, chúng ta đã loại bỏ nhiều công cụ hữu ích có sẵn cho trình tối ưu hóa truy vấn và buộc nó hoạt động với ít hơn mức cần thiết để thành công.
Nếu chúng ta xóa các gợi ý, thì trình tối ưu hóa sẽ chọn một tham gia NESTED LOOP và nhận được hiệu suất như sau:
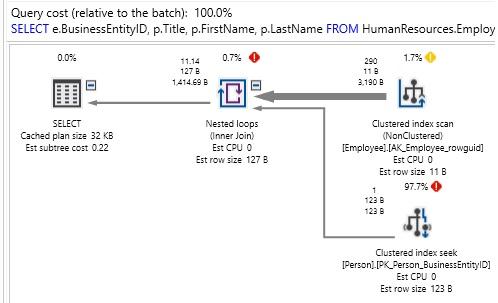

Các gợi ý thường được sử dụng như các bản sửa lỗi nhanh chóng cho các vấn đề phức tạp hoặc lộn xộn. Mặc dù có những lý do hợp pháp để sử dụng gợi ý, nhưng chúng thường được coi là phương án cuối cùng. Gợi ý là các phần tử truy vấn bổ sung yêu cầu bảo trì và xem xét theo thời gian khi mã ứng dụng, dữ liệu hoặc lược đồ thay đổi. Nếu cần, hãy nhớ ghi lại kỹ lưỡng việc sử dụng chúng! Không chắc rằng một DBA hoặc nhà phát triển sẽ biết lý do tại sao bạn sử dụng một gợi ý trong 3 năm trừ khi bạn ghi nhận nhu cầu của nó rất tốt.
Kết luận
Trong bài viết này, chúng ta đã thảo luận về nhiều lỗi truy vấn phổ biến có thể dẫn đến hiệu suất kém. Vì chúng tương đối dễ xác định mà không cần nghiên cứu sâu rộng, chúng ta có thể sử dụng kiến thức này để cải thiện thời gian phản hồi của mình đối với các trường hợp khẩn cấp về độ trễ hoặc hiệu suất. Đây chỉ là phần nổi của tảng băng chìm, nhưng cung cấp một điểm khởi đầu tuyệt vời để tìm ra điểm yếu trong một kịch bản.
Cho dù bằng cách làm sạch các phép nối và mệnh đề WHERE hay bằng cách chia một truy vấn lớn thành các phần nhỏ hơn, việc tập trung vào quá trình đánh giá, thử nghiệm và QA sẽ cải thiện chất lượng kết quả của chúng tôi, ngoài việc cho phép chúng ta hoàn thành các dự án này nhanh hơn.
Mọi người đều có bộ công cụ mẹo và thủ thuật riêng cho phép họ làm việc nhanh hơn VÀ thông minh hơn. Bạn có bất kỳ mẹo truy vấn nhanh, vui nhộn hoặc thú vị nào không? Cho tôi biết! Tôi luôn tìm kiếm những cách mới hơn để tăng tốc TSQL và tránh những ngày tìm kiếm khó chịu!
Tài liệu tham khảo
Nguồn: viblo.asia