Xử lý hình ảnh trong y khoa luôn là lĩnh vực cần có sự chính xác cao cũng như khả năng diễn giải một cách tường mình nhất để đảm bảo rằng kết quả thu được là chính xác nhất. Trong bài báo Reading Race: AI Recognises Patient’s Racial Identity In Medical Images nhóm tác gả đã chỉ ra rằng các mô hình AI có thể học cách phát hiện chủng tộc của ai đó từ nhiều phương thức xử lý hình ảnh khác nhau (bao gồm cả chụp X-quang ngực trắng và đen) và điều này thật kỳ lạ, bởi vì ngay cả những bác sĩ chuyên môn cũng không thể làm được điều này. Để bảo vệ luận điểm đó, nhóm tác giả đã thực hiện một lượng lớn các thứ thí nghiệm trước khi rút ra kết luận cuối cùng và trong bài viết này, chúng ta sẽ tìm hiểu xem vấn đề ở đây thực sự là gì và nhóm tác giả đã thực hiện các thí nghiệm như thế nào để rút ra kết luận trên
Giới thiệu chung
Thành kiến và phân biệt đối xử về chủng tộc có nhiều trong ảnh y tế và có thể sẽ ảnh hưởng đến hiệu suất mô hình và đã được chứng minh thông qua nhiều paper nhưng chưa có nghiên cứu nào nói về nhưng không có dấu hiệu sinh học hình ảnh y tế đáng tin cậy nào được biết đến tương quan với nhận dạng chủng tộc. Nói cách khác, trong khi có thể quan sát các dấu hiệu nhận dạng chủng tộc trong các bức ảnh và video, các chuyên gia lâm sàng không thể dễ dàng xác định chủng tộc của bệnh nhân từ các hình ảnh y tế.
Với khả năng gây hại do phân biệt đối xử trong một hệ thống được cho là bất khả tri đối với chủng tộc, việc hiểu rõ chủng tộc đóng vai trò như thế nào trong các mô hình hình ảnh y tế có tầm quan trọng cao. Câu hỏi này đặc biệt đúng lúc vì các thuật toán y tế đang được FDA và các cơ quan quản lý khác sử dụng, bao gồm các hệ thống sử dụng hình ảnh y tế (chẳng hạn như phim X-quang, chụp CT, v.v.) làm đầu vào chính. Các cơ quan quản lý này đã đưa ra các khuyến nghị để báo cáo các nghiên cứu về AI, nhưng các tài liệu quản lý công khai của các công ty được FDA chấp thuận không cho thấy kết quả trên các phân nhóm nhân khẩu học và lâm sàng có liên quan.
Chủng tộc và bản dạng chủng tộc có thể là những thuộc tính khó định lượng và nghiên cứu trong nghiên cứu chăm sóc sức khỏe, và thường bị nhầm lẫn với các khái niệm sinh học như tổ tiên di truyền. Trong công trình này, ta định nghĩa bản sắc chủng tộc là một cấu trúc xã hội, chính trị và luật pháp có liên quan đến sự tương tác giữa nhận thức bên ngoài (tức là “làm thế nào để người khác nhìn thấy tôi?”) và nhận dạng bản thân, và đặc biệt tận dụng chủng tộc tự báo cáo của bệnh nhân trong tất cả các thí nghiệm.
Trong khi các nghiên cứu trước đây đã chứng minh sự tồn tại của khả năng xác định chủng tộc, cơ chế của những khác biệt này trong hình ảnh y tế vẫn chưa được khám phá. Một nghiên cứu trước đó đã lưu ý rằng một mô hình AI được thiết kế để dự đoán mức độ nghiêm trọng của viêm xương khớp bằng cách sử dụng tia X đầu gối không thể xác định chủng tộc của bệnh nhân, trong khi một đánh giá khác về chụp X-quang ngực cho thấy các thuật toán AI có thể dự đoán giới tính, phân biệt giữa bệnh nhân người lớn và bệnh nhi và phân biệt giữa bệnh nhân Mỹ và Trung Quốc. Trong nhãn khoa, hình ảnh quét võng mạc đã được sử dụng để dự đoán giới tính, tuổi tác và các dấu hiệu tim mạch như tăng huyết áp và tình trạng hút thuốc. Điều này tạo ra rủi ro lớn cho tất cả các triển khai mô hình trong hình ảnh y tế: nếu một mô hình AI sử dụng khả năng phát hiện danh tính chủng tộc làm một yếu tố để đưa ra các quyết định y tế, nhưng khi làm như vậy đã phân loại sai tất cả bệnh nhân thuộc một chủng tộc nào đó, bác sĩ X quang lâm sàng (những người thường không có quyền truy cập chủng tộc thông tin nhân khẩu học) sẽ không thể phát hiện và điều chỉnh nhãn dữ liệu để chính xác hơn.
Đóng góp của nhóm tác giả
Trên cơ sở trình bày vấn đề như trên, bằng việc huấn luyện các mô hình phân loại dựa trên CNN với cả tập dữ liệu, kịch bản và kĩ thuật khác nhau, nhóm tác giả đã có những đóng góp như sau:
- Sử dụng các phương pháp học sâu tiêu chuẩn cho từng thí nghiệm phân tích hình ảnh, đào tạo nhiều mô hình phổ biến phù hợp với các tác vụ để chứng minh rằng các mô hình AI có thể dự đoán chủng tộc qua nhiều phương thức hình ảnh, nhiều bộ dữ liệu khác nhau và các nhiệm vụ lâm sàng đa dạng. Mức hiệu suất cao vẫn tồn tại trong quá trình xác nhận bên ngoài của các mô hình này trên một loạt các trung tâm học thuật và quần thể bệnh nhân ở Hoa Kỳ, cũng như khi các mô hình được tối ưu hóa để thực hiện các tác vụ có động cơ lâm sàng.
Thực hiện cắt bỏ để chứng minh rằng việc phát hiện này không phải do các proxy tầm thường, chẳng hạn như thói quen cơ thể, tuổi tác, mật độ mô hoặc các yếu tố gây nhiễu hình ảnh tiềm năng khác cho chủng tộc chẳng hạn như phân bố bệnh cơ bản trong dân số. - Chỉ ra rằng các đặc điểm đã học có vẻ liên quan đến tất cả các vùng của phổ tần số và hình ảnh, cho thấy rằng các nỗ lực giảm thiểu sẽ gặp nhiều thách thức.
- Nhấn mạnh rằng bản thân khả năng dự đoán danh tính chủng tộc của AI không phải là vấn đề quan trọng, mà vấn đề là khả năng này được học thông thường và do đó có khả năng xuất hiện trong nhiều mô hình phân tích hình ảnh y tế, cung cấp véc tơ trực tiếp cho việc tái tạo hoặc trầm trọng thêm sự khác biệt về chủng tộc đã tồn tại trong thực hành y tế. Nguy cơ này còn tăng thêm do các chuyên gia về con người không thể xác định tương tự danh tính chủng tộc từ các hình ảnh y tế, có nghĩa là sự giám sát của con người đối với các mô hình AI chỉ được sử dụng hạn chế để nhận ra và giảm thiểu vấn đề này.
Cách thức thực hiện
Để chứng minh cho luận điểm của mình, nhóm tác giả đã thực hiện các nhóm một số các bộ dữ liệu hình ảnh y khoa phổ biến và dữ liệu về chủng tộc được sử dụng dựa trên các bộ dữ liệu không công khai đi kèm được liệt kê ở hình dưới đâ1y.
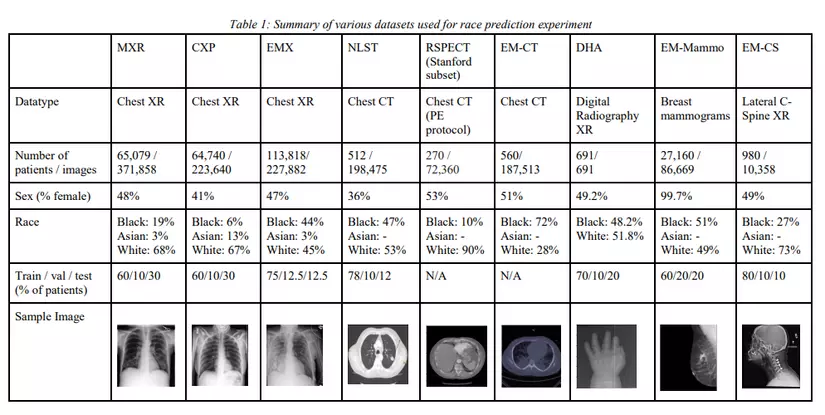
Để điều tra nguyên nhân của sự chênh lệch hiệu suất được thiết lập trước đây theo chủng tộc bệnh nhân,nhóm tác giả đã nghiên cứu một số giả thuyết và thực hiện ba nhóm thử nghiệm như sau:
Khả năng phát hiện chủng tộc của các mô hình học sâu
Để khảo sát khả năng của hệ thống học sâu trong việc khám phá chủng tộc từ hình ảnh X quang, nhóm đã tiến hành các thí nghiệm sau:
-
Phát triển các mô hình để phát hiện danh tính chủng tộc trên ba tập dữ liệu X quang lớn với xác thực tập dữ liệu bên ngoài để thiết lập hiệu suất cơ bản của hệ thống AI cho nhiệm vụ phát hiện chủng tộc.
-
Đào tạo các mô hình phát hiện danh tính chủng tộc cho các hình ảnh không phải ảnh X quang từ nhiều vị trí cơ thể để đánh giá xem hiệu suất của mô hình có bị giới hạn ở dữ liệu chụp X quang phổi hay không
-
Đào tạo các mô hình phát hiện bệnh lý và xác định lại bệnh nhân và đánh giá hiệu suất dự đoán chủng tộc của họ để xác định xem các mô hình học sâu có thể học cách xác định danh tính chủng tộc khi được đào tạo để thực hiện các nhiệm vụ khác hay không
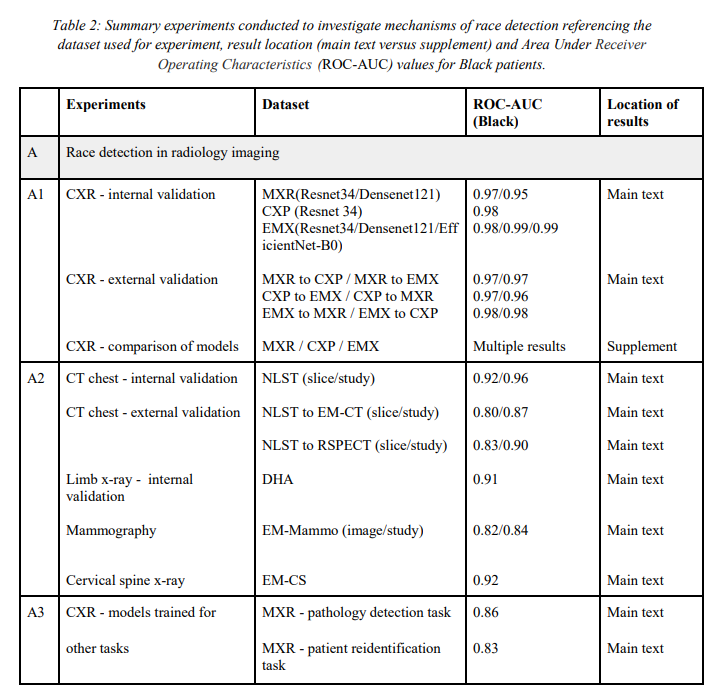
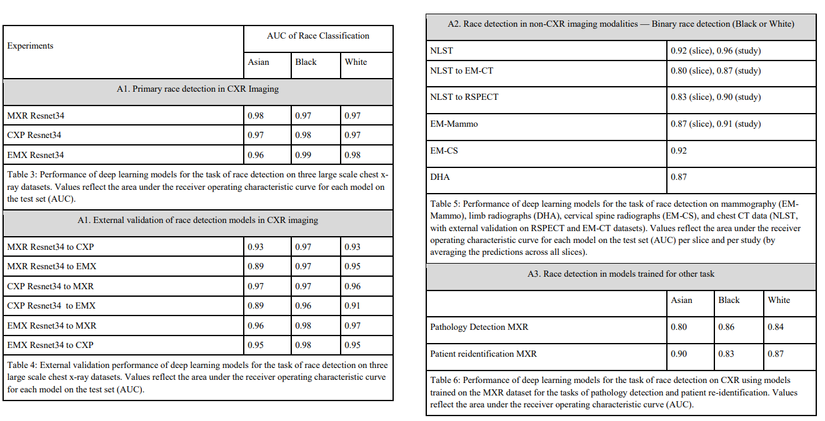
Kết quả cho thấy rằng các mô hình học sâu đều thể hiện mức hiệu suất cao trong nhiệm vụ phát hiện chủng tộc trên chụp X-quang ngực, với hiệu suất cao được duy trì trên các phương thức khác và các bộ validations across datasets như được thể hiện ở ảnh dưới đây
Thí nghiệm về các yếu tố gây nhiễu giải phẫu và kiểu hình
Sau khi thiết lập mô hình học sâu dung lượng cao (CNN) có thể xác định chủng tộc của bệnh nhân trong dữ liệu hình ảnh y tế, nhóm tác giả đã tạo ra một loạt các giả thuyết cạnh tranh để giải thích điều này có thể xảy ra như thế nào:
-
Sự khác biệt về đặc điểm thể chất giữa các bệnh nhân thuộc các nhóm chủng tộc khác nhau, ví dụ, thói quen cơ thể hoặc mật độ vú.
-
Sự khác biệt về phân bố bệnh tật giữa các bệnh nhân thuộc các nhóm chủng tộc khác nhau, ví dụ, bệnh nhân da đen có tỷ lệ mắc một số bệnh như tiểu đường, bệnh thận và bệnh tim cao hơn
-
Sự khác biệt về kiểu hình hoặc giải phẫu theo vị trí cụ thể hoặc mô cụ thể, ví dụ: người da đen có mật độ khoáng xương được điều chỉnh cao hơn người da trắng và tốc độ suy giảm mật độ khoáng xương hàng năm được điều chỉnh theo độ tuổi chậm hơn
-
Tác động tích lũy của thành kiến xã hội và căng thẳng môi trường, ví dụ, sức khỏe của bệnh nhân da đen nói chung là tồi tệ hơn
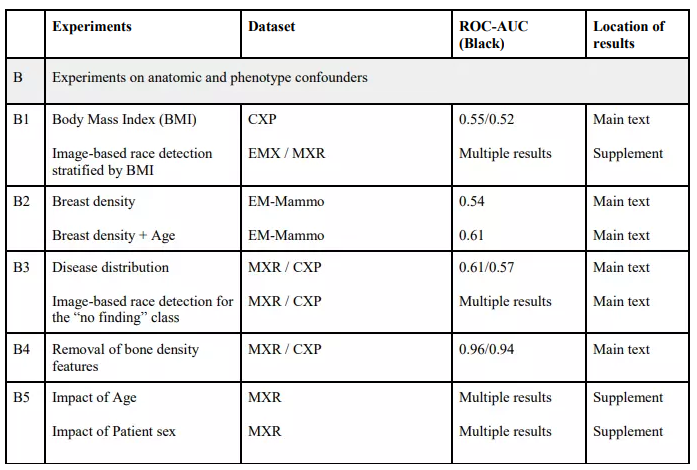
Kết quả thu được cho thấy rằng khả năng phát hiện chủng tộc không bị ảnh hưởng bởi các yếu tố giải phẫu và kiểu hình khi mà hiệu suất của các mô hình được đào tạo dựa trên các thông tin này kém hơn rất nhiều khi so sánh với kết quả được đề cập ở trên. Kết quả chi tiết vui lòng đọc thêm tại bài báo.
Điều tra về các cơ chế cơ bản mà các mô hình AI có thể nhận ra chủng tộc
Nhóm tác giả điều tra các cơ chế cơ bản mà các mô hình AI có thể nhận ra chủng tộc bằng cách:
-
Điều tra những đóng góp tương đối của các đặc điểm cấu trúc quy mô lớn và các đặc điểm cấu trúc nhỏ bằng cách thực hiện đào tạo và thử nghiệm trên bộ dữ liệu được thay đổi bằng cách lọc phổ tần số của hình ảnh trong MXR. Điều này đã được bằng cách áp dụng lọc thông thấp (LPF), lọc thông cao (HPF), lọc thông dải (BF) và lọc rãnh (NF) sau đó áp dụng phép biến đổi Fourier ngược trên phổ được lọc để thu được phiên bản đã thay đổi của hình ảnh gốc và sau đó đào tạo các mô hình trên các tập dữ liệu bị xáo trộn này để quan sát ảnh hưởng đến khả năng dự đoán chủng tộc của mô hình.
-
Thay đổi kích thước hình ảnh MXR thành nhiều độ phân giải khác nhau và đào tạo mô hình Resnet34. Để kiểm tra xem nhiễu ảnh có ảnh hưởng đến việc phát hiện chủng tộc hay không, nhóm tác giả đã làm cho ảnh thử nghiệm trong tập dữ liệu MXR bị nhiễu và bị mờ bằng cách thêm nhiễu Gauss (trung bình = 0, phương sai = 0,1) và áp dụng bộ lọc gaussian cho chúng.
-
Điều tra xem liệu thông tin chủng tộc có thể được bản địa hóa cho một khu vực hoặc mô giải phẫu cụ thể hay không bằng cách tạo saliency map cho các trường hợp ngẫu nhiên cho mỗi nhiệm vụ bằng phương pháp Grad-Cam và các vùng này sẽ được đánh giá bởi các chuyên gia y khoa. Tiếp đó, nhóm tác giả đánh giá thêm ý nghĩa của các vùng quan tâm như được chỉ ra bởi saliency map cách che vùng RoI trong mỗi ảnh X quang và sử dụng chúng để kiểm tra với mô hình được đào tạo trên ảnh MXR gốc.
-
Điều tra xem liệu thông tin chủng tộc có thể được tách biệt thành các phần cụ cụ thể trong ảnh chụp x-quang ngực hay không bằng cách chia mỗi hình ảnh thành chín ô vuông 3×3 có kích thước bằng nhau và thử nghiệm với việc đào tạo mô hình dự đoán chủng tộc bằng hai cách tiếp cận khác nhau
- Chọn một trong chín bản vá và xóa hoàn toàn tất cả thông tin khỏi bản vá bằng cách đặt tất cả các pixel trong bản vá thành 0
- Chọn một trong các chín bản vá, chia tỷ lệ nó trở lại kích thước của hình ảnh gốc và chỉ sử dụng bản vá này để huấn luyện mô hình
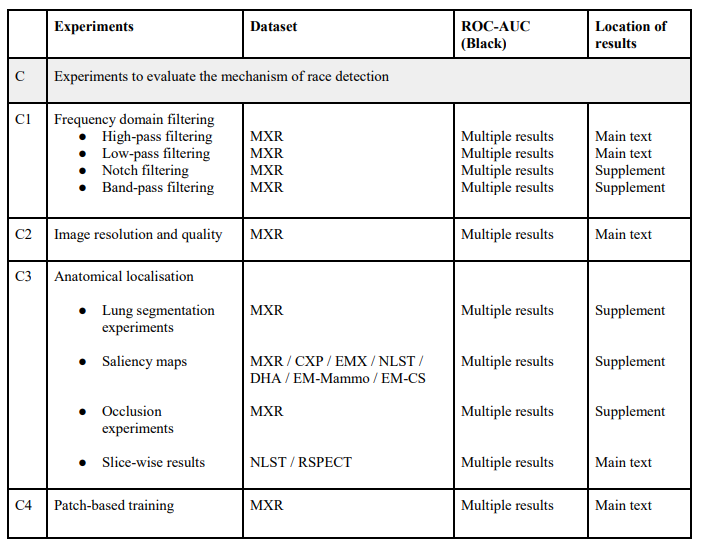
Sau khi thực hiện thí nghiệm, nhóm tác giả thu được kết quả như sau:
- Thông tin về chủng tộc được chứa trên miền tần số : Trong hình dưới đây ta có thể quan sát thấy rằng bộ lọc thông thấp dẫn đến hiệu suất bị suy giảm đáng kể ở khoảng đường kính 10, tương ứng với mức độ mà hình ảnh bị suy giảm đáng kể về mặt trực quan. bộ lọc thông cao duy trì hiệu suất cao lên đến đường kính 100, điều này đáng chú ý là không có các đặc điểm giải phẫu rõ ràng trực quan trong hình ảnh mẫu ngay cả ở các mức bán kính thấp hơn (nghĩa là hiệu suất được duy trì mặc dù hình ảnh bị suy giảm nghiêm trọng về mặt trực quan).
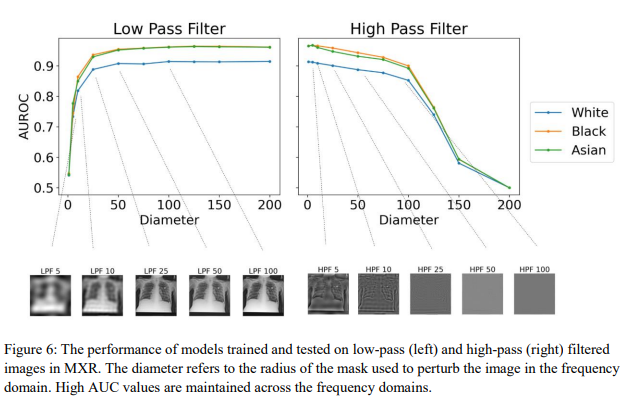
- Thông tin về chủng tộc vẫn tồn tại ở độ phân giải hình ảnh bị suy giảm và chất lượng hình ảnh thấp: Hình dưới đây cho thấy AUC của các độ phân giải hình ảnh khác nhau từ độ phân giải 4×4 đến hình ảnh 512×512, cho thấy AUC> 0,95 đối với hình ảnh ở độ phân giải 160 X 160 hoặc lớn hơn. Ta có thể ghi nhận sự sụt giảm hiệu suất đối với hình ảnh dưới độ phân giải này nhưng chứng minh rằng thông tin chủng tộc vẫn tồn tại nhiều hơn cơ hội ngẫu nhiên ngay cả ở độ phân giải nhỏ như 4×4. Kết quả tương tự cũng được quan sát đối với hình ảnh nhiễu
- Thông tin về chủng tộc không được bản địa hóa cho một khu vực giải phẫu cụ thể hoặc phân đoạn cơ thể: Sau khi thực hiện thí nghiệm, nhóm nhận thấy rằng không có đóng góp rõ ràng nào từ một phân đoạn giải phẫu cụ thể bằng cách sử dụng nhiều thí nghiệm. Ta có hiệu suất cao của các mô hình được thử nghiệm trên các phân đoạn không phải phổi (so với phân đoạn phổi), nhưng các dự đoán phân đoạn thấp hơn so với dự đoán hình ảnh ban đầu. Và do đó thông tin về chủng tộc có thể là sự kết hợp thông tin từ tất cả các phân đoạn hình ảnh phổi và không phổi. Kết quả tương tự được quan sát từ phân tích lát cắt CT trong đó hiệu suất theo từng lát của mô hình là tương tự trong suốt các lát ở trên cùng, giữa và dưới ngực.
Thảo luận
Kết quả mà các mô hình học sâu có thể dự đoán chủng tộc tự báo cáo của bệnh nhân chỉ từ các hình ảnh y tế là đáng ngạc nhiên, đặc biệt là nhiệm vụ này không thể thực hiện đối với các chuyên gia về con người. Bằng cách thực hiện các thí nghiệm của mình trên nhiều môi trường lâm sàng khác nhau, phương thức hình ảnh y tế và quần thể bệnh nhân, nhóm tác giả xác nhận cho thấy rằng các mô hình này không dựa vào các biến số của quy trình bệnh viện hoặc sự khác biệt đặc trưng của địa phương trong cách thực hiện các nghiên cứu hình ảnh cho bệnh nhân bản sắc chủng tộc khác nhau.
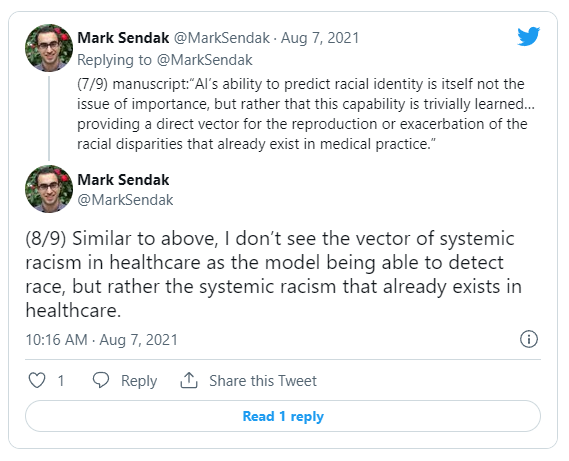
Có một số cuộc tranh luận về ý nghĩa của điều này. Một trong những tác giả của bài báo: Luke Oakden-Rayner tin rằng khả năng phát hiện chủng tộc quá dễ dàng của AI là rất tệ và có thể dẫn đến sự thiên vị tuy nhiên một số khác cho rằng không thấy khả năng này là đáng báo động, thông tin chi tiết có thể xem tại đây:
Tổng kết
Bài viết này giới thiệu về báo Reading Race: AI Recognises Patient’s Racial Identity In Medical Images cũng như trình bày một cách ngắn gọn nhất các nội dung được trình bày trong các paper đó. Cảm ơn các bạn đã dành thời gian đọc và hi vọng rằng bài viết này sẽ cung cấp cho các bạn các thông tin hữu ích cho mọi người.
Một số từ viết tắt các thứ :v
- Chủng tộc/dân tộc tự báo cáo (self-reported race/ethnicity): thường được sử dụng trong các nghiên cứu dịch tễ học để đánh giá nguồn gốc xuất thân của một cá nhân. Thông thường, những người tham gia ở Hoa Kỳ được yêu cầu chỉ định một chủng tộc / nhóm dân tộc duy nhất dựa trên sáu loại: Da trắng, Da đen, Da đen gốc Tây Ban Nha, Da trắng Tây Ban Nha, Châu Á hoặc khác
- FDA (U.S. Food and Drug Administration): Cục quản lý Thực phẩm và Dược phẩm Hoa Kỳ
- CXR: X quang ngực
Nguồn: viblo.asia