Yêu cầu nhỏ
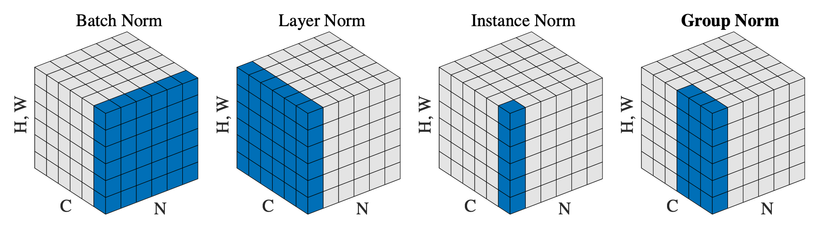
Hiểu về các lớp Norm khác nhau hoạt động như nào: BatchNorm (BN), GroupNorm (GN), LayerNorm (LN) và biết cách sử dụng Pytorch
Mở đầu
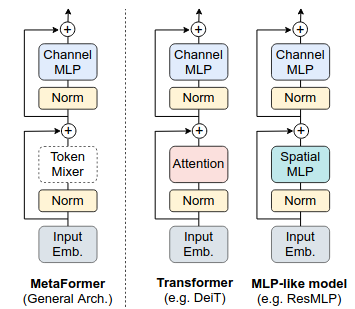
Từ khi Transformer được áp dụng cho bài toán phân loại ảnh qua ViT, đã có rất nhiều models mới tập trung vào cải thiện phép Self-Attention. Một khối encoder của Transformer có kiến trúc chung như ở hình 1, bao gồm 2 thành phần. Phần đầu là nơi chứa Attention module dùng để “mix” thông tin của tokens với nhau, do đó ta đặt nó là “Token Mixer”. Phần còn lại là các module nhỏ kiểu như Channel MLP và Skip-connection. Với sự thành công của Transformer, người ta cho rằng đó là do sự vượt bậc của phép Self-Attention. Do đó, có rất nhiều models mới tập trung vào cải thiện phép Self-Attention. Tuy nhiên, một số nghiên cứu lại chỉ đơn thuần sử dụng phép Spatial MLP làm Token Mixer và đạt được hiệu năng tương đương với phép Self-Attention. Hay thậm chí, có một nghiên cứu khác sử dụng Fourier Transform thay thế cho phép Attention và đạt được hiệu năng tới 97% một model ViT thuần.
Tác giả của paper MetaFormer nhận ra một điểm chung giữa các models được phát triển bây giờ, đó là các khối của chúng đều có kiến trúc 2 phần tương tự nhau. Phần đầu chứa phép Token Mixer, phần sau là Channel MLP và các skip-connection. Và tác giả cho rằng, thay vì tập trung quá nhiều vài cải tiến Token Mixer, kiến trúc tổng thể của một khối, cũng góp phần vô cùng lớn trong việc tạo ra một model có hiệu năng mạnh mẽ. Tác giả đóng gói kiến trúc tổng thể của một khối này lại, và đặt tên cho nó là MetaFormer (Hình 1). Tác giả đã tạo ra một hướng nghiên cứu mới, thay vì tập trung vào cải thiện Token Mixer, thì ta sẽ cải thiện kiến trúc tổng thể của nó, tức cải thiện MetaFormer.
Chứng minh
Ừ thì tác giả đề ra rằng kiến trúc tổng thể cũng vô cùng quan trọng, nếu không có gì để backup cho lời nói đó thì cũng chỉ là kết luận xàm xí thôi. Đầu tiên, tác giả sẽ chứng minh cho câu nói đó.
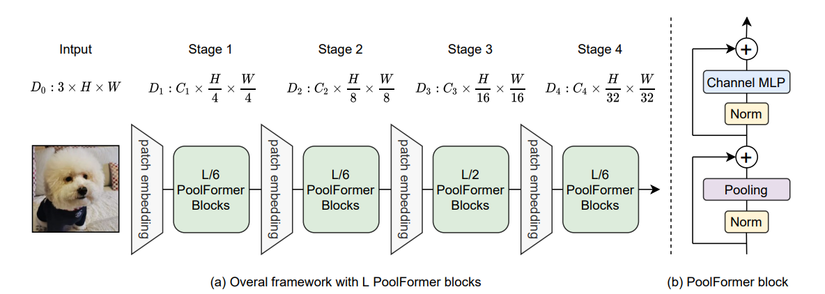
Một khối MetaFormer được chia ra làm 2 phần (Hình 1), phần đầu có Token Mixer và phần sau cho Channel MLP:
X′=X+TokenMixer(Norm1(X))X’ = X + TokenMixer(Norm_1(X))
X′′=X′+ChannelMLP(Norm2(X′))X” = X’ + ChannelMLP(Norm_2(X’))
Token Mixer
Để chứng minh rằng MetaFormer là thứ cực kì quan trọng, thì tất nhiên ta phải sử dụng một Token Mixer cực yếu để xem rằng hiệu năng của toàn bộ model với Token Mixer cực yếu này có còn tốt?
Vì vậy, Token Mixer được chọn sẽ là phép Pooling. cụ thể là Average Pooling. Cụ thể, phép Pooling sẽ được định nghĩa như sau:

Modified Layer Norm
Thông thường trong kiến trúc họ Transformer, Norm được chọn để sử dụng là LayerNorm (LN). Tuy nhiên, tác giả nhận ra Norm này có vẻ không phù hợp cho lắm.
Trước tiên, ta phải hiểu về cách hoạt động của một số lớp Norm thường sử dụng và Norm của Pytorch API đã. Khi sử dụng kiến trúc họ Transformer, Feature maps sẽ có dạng (B,tokens,C)(B, tokens, C) với tokenstokens là H×WH times W. Khi thực hiện LN, ta sẽ norm ở trên chiều CC, và weight của LN sẽ có chiều CC luôn. Tuy nhiên, việc không sử dụng phép Self-Attention, tức feature maps sẽ có dạng (B,C,H,W)(B, C, H, W). Và nếu lúc này thực hiện LN thông qua nn.LayerNorm của Pytorch thì ta sẽ thực hiện norm ở trên chiều [C,H,W][C, H, W] thay vì chỉ CC, và weight của LN cũng sẽ có chiều là [C,H,W][C, H, W]. Nếu ta muốn áp dụng được LN chuẩn mực, tức là chỉ Norm trên chiều CC kể cả là feature maps có dạng (B,C,H,W)(B, C, H, W), thì vẫn hoàn toàn có thể, chỉ là giờ chúng ta sẽ phải tự viết code chứ không còn áp dụng được nn.LayerNorm của Pytorch nữa mà thôi.
Tóm cái váy lại thì:
- LayerNorm chỉ trên chiều channel như Transformer: Phải tự viết code lại, chỉ thực hiện norm trên chiều channel và weight cũng có chiều channel
nn.LayerNorm: thực hiện norm trên chiều [C,H,W][C, H, W] và weight có chiều [C,H,W][C, H, W]
Oke thế giờ thì 2 Norm kể trên LayerNorm và nn.LayerNorm có gì chưa tốt nếu sử dụng với feature maps có dạng (B,C,H,W)(B, C, H, W). Nếu ta sử dụng nn.LayerNorm, ta sẽ phải khai báo một lớp LN như sau:
self.layer_norm = nn.LayerNorm([C, H, W])Điều này yêu cầu nn.LayerNorm của ta phải có HH và WWcố định thì mới có thể khai báo và forward được. Điều này khiến cho mạng chỉ nhận đầu vào là một kích cỡ ảnh cố định →rightarrow không khả thi cho các downstream task.
Còn sử dụng LayerNorm thì hiệu năng yếu.
Vì vậy, tác giả đã tạo ra Modified Layer Norm (MLN). MLN sẽ thực hiện Norm trên chiều [C,H,W][C, H, W], tuy nhiên, weight của MLN sẽ có chiều CC. Nó là sự kết hợp giữa nn.LayerNorm và LayerNorm. Khi khai báo, ta sẽ chỉ phải khai báo như sau:
self.modified_layer_norm = ModifiedLayerNorm(C)Tức là giờ ta không còn phải cố định chiều HH và WW nữa.
Dưới đây là bảng kết quả so sánh MLN với LN và BN:

Kiến trúc của mạng
Bảng kết quả
Phần đáng mong đợi nhất đây. Đây là điều khiến cho câu nói của tác giả không trở thành câu chém gió vô căn cứ.
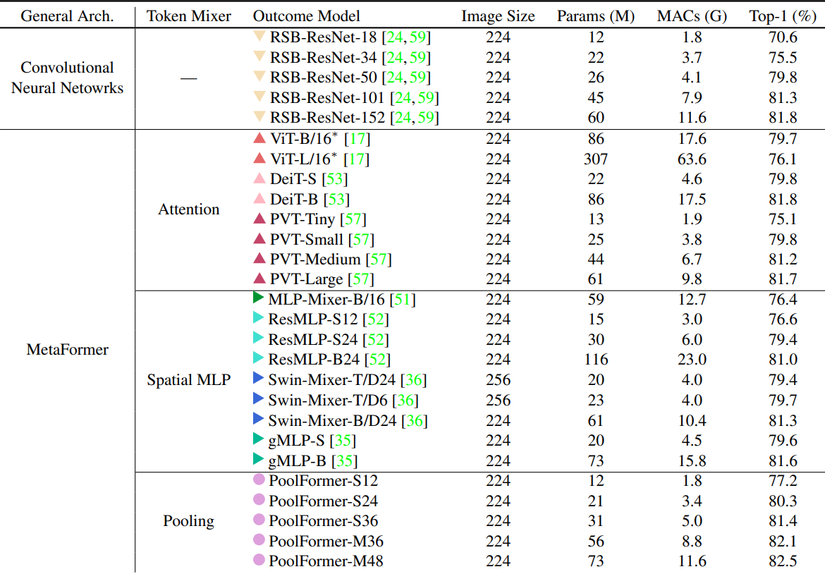
 Mình có một câu hỏi thú vị muốn đặt ra cho các bạn đọc bài này. Phía trên CNN cùi bắp thì không nói, nhưng cùng là MetaFormer, tại sao PoolFormer lại mạnh hơn PVT, ViT hay Swin với việc chỉ sử dụng phép Pooling làm Token Mixer?
Mình có một câu hỏi thú vị muốn đặt ra cho các bạn đọc bài này. Phía trên CNN cùi bắp thì không nói, nhưng cùng là MetaFormer, tại sao PoolFormer lại mạnh hơn PVT, ViT hay Swin với việc chỉ sử dụng phép Pooling làm Token Mixer?
Cải thiện MetaFormer
Như đã nói ở trên, thay vì tập trung sáng tạo ra một Token Mixer mới, thì ta sẽ sử dụng những Token Mixer đơn giản, và cải thiện những thứ còn lại của một MetaFormer Block.
StarReLU
Trong paper Transformer, ReLU được chọn làm activation function:
ReLU(x)=max(x,0)ReLU(x) = max(x, 0)
Activation function này có độ nặng tính toán là 1 FLOP. Sau đó, GELU được sử dụng làm activation function chính cho các model họ Transformer:
GELU(x)=xΦ(x)≈0.5×x(1+tanh(2/π(x+0.044715×x3)))GELU(x) = x Phi(x) approx 0.5 times x(1+tanh(sqrt{2/pi}(x+0.044715 times x^{3})))
Phép tính GELU(x)GELU(x) tốn mất 14 FLOPs, lớn hơn gấp 14 lần ReLU. Có một paper đã tìm ra phép thay thế gần đúng của GELU, gọi là SquaredReLU như sau:
SquaredReLU=xReLU(x)=(ReLU(x))2SquaredReLU = xReLU(x) = (ReLU(x))^2
SquaredReLU chỉ tốn có 2 FLOPs, tuy nhiên, hiệu năng của SquaredReLU vẫn không thể sánh ngang với GELU trên bài toán phân loại ảnh. Nhóm tác giả của MetaFormer cho rằng, việc hiệu năng tụt giảm có thể là do distribution shift (sự dịch chuyển phân phối) trên output của phép tính. Giả dụ xx tuân theo phân phối chuẩn với mean 0 và variance 1, ~N(0,1)N(0, 1), ta có:
E((ReLU(x)2)=0.5,Var((ReLU(x)2)=1.25E((ReLU(x)^2) = 0.5, qquad Var((ReLU(x)^2) = 1.25
với E(⋅)E(cdot) và Var(⋅)Var(cdot) lần lượt là expectation và variance. Do đó, nhóm tác giả tạo ra StarReLU để có thể giải quyết distribution shift như sau:
StarReLU(x)=(ReLU(x))2−E((ReLU(x))2)Var((ReLU(x))2)=(ReLU(x))2−0.51.25≈0.8944⋅(ReLU(x))2−0.4472StarReLU(x) = frac{(ReLU(x))^2 – E((ReLU(x))^2)}{sqrt{Var((ReLU(x))^2)}} = frac{(ReLU(x))^2 – 0.5}{sqrt{1.25}} approx 0.8944 cdot (ReLU(x))^2 − 0.4472
Tuy nhiên, đấy là giả định khi sử dụng input là normal distribution. Để StarReLU phù hợp với nhiều distribution hơn thì, thay vì sử dụng 2 hệ số cố định 0.89440.8944 và −0.4472-0.4472, ta sẽ để cho nó tự học. StarReLU bản mở rộng như sau:
StarReLU(x)=s⋅(ReLU(x))2+bStarReLU(x) = s cdot (ReLU(x))^2 + b
với s∈Rs in R và b∈Rb in R là learnable params (như BN). StarReLU lúc này chỉ tốn có 4 FLOPs
Các thay đổi khác
Output của một phần trong một khối MetaFormer được tính như sau:
Y=X+F(Norm(X))Y = X + F(Norm(X))
với XX là input, YY là output, NormNorm là lớp Norm và FF là Token Mixer hoặc channel MLP
Scaling branch output. Giống như implicit knowledge dạng nhân, ta có 3 cách thêm scaling branch như sau:
- Residual scale: thêm hệ số scale vào phần Residual:
Y=λr⊙X+F(Norm(X))Y = lambda_r odot X + F(Norm(X))
- Layer Scale: thêm hệ số scale vào phần tính toán
Y=X+λl⊙F(Norm(X))Y = X + lambda_l odot F(Norm(X))
- Branch Scale: Kết hợp cả Layer Scale và Residual Scale
Y=λr⊙X+λl⊙F(Norm(X))Y = lambda_r odot X + lambda_l odot F(Norm(X))
Hiệu năng của Residual Scale, theo những thử nghiệm của tác giả cho bài toán phân loại ảnh, đang là tốt nhất. Tuy nhiên, mọi người có thể thử các cách scale khác cho phù hợp với bài toán
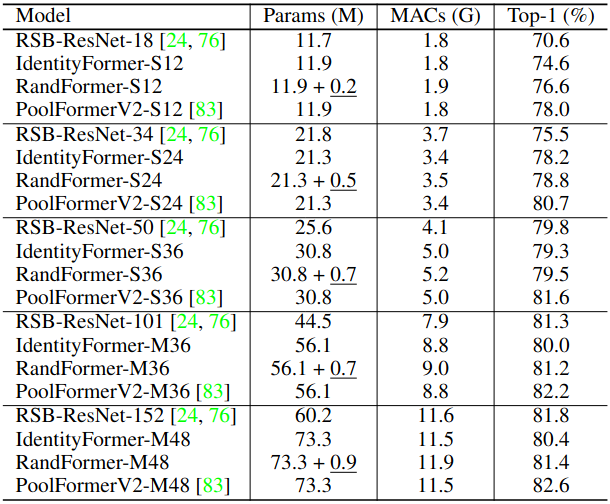
IdentityFormer và RandFormer
Để chứng minh hiệu năng của việc cải thiện MetaFormer thay vì Token Mixer, tác giả của MetaFormer đã tạo ra IdentityFormer và RandFormer
IdentityFormer. Loại bỏ hoàn toàn Token Mixer ra khỏi model, hay nói cách khác là sử dụng Identity Mapping làm Token Mixer, ta có:
IdentityMapping(X)=XIdentityMapping(X) = X
hay:
X′=X+Norm(X)X’ = X + Norm(X)
RandFormer. Sử dụng một ma trận ngẫu nhiên (Random Matrix) làm Token Mixer, và Random Matrix này sẽ không được cập nhật trong quá trình backprop. Tức là ma trận được khởi tạo ngẫu nhiên ra sao thì giữ nguyên như thế đến cuối
RandomMixing(X)=XWRRandomMixing(X) = XW_R
X∈RN×CX in R^{N times C} có NN là số token (H×WH times W), CC là số channels; WR∈RN×NW_R in R^{N times N}
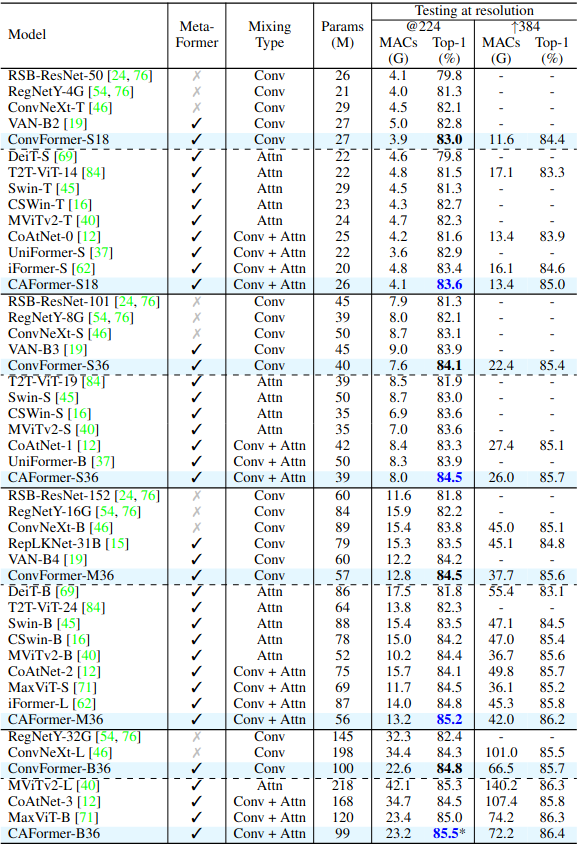
ConvFormer và CAFormer
Với việc đã chứng minh được cải tiến MetaFormer thay vì Token Mixer có thể đem lại hiệu năng không tưởng, ta sẽ sử dụng Token Mixer đơn giản và có sẵn để tạo ra một model mạnh thay vì phải đau đầu suy nghĩ ra một Token Mixer mới và phức tạpConvFormer. Sử dụng Depthwise Separable Convolution trong MobileNetV2 làm TokenMixer:
Conv(X)=Convpw2(Convdw(σ(Convpw1(X))))Conv(X) = Conv_{pw_{2}}(Conv_{dw}(sigma(Conv_{pw_{1}}(X))))
với ConvpwConv_{pw} là 1×11 times 1 DWConv (hay còn gọi là Point wise Conv), ConvdwConv_{dw} là k×kk times k DWConv, trong paper k=7k=7, và σsigma là một hàm phi tuyến tính.
CAFormer. Sử dụng nửa đầu giống như ConvFormer, còn nửa sau của model sử dụng Self-Attention.
Các bạn có thể thử suy nghĩ tại sao nửa sau của CAFormer lại sử dụng Self-Attention mà không sử dụng từ đầu nhé
TL;DR
[W]hat
- Một hướng đi mới trong việc nghiên cứu model cho bài toán phân loại ảnh, có thể mở rộng thành các backbone chung chung
[W]hy
- Mình cũng không có đánh giá gì về phần này vì nó không phải cải tiến những cái gì chưa tốt từ những model cũ mà mở ra một hướng nghiên cứu mới khá là thú vị
Ho[W]
- Tập trung vào cải tiến khối tổng thể (MetaFormer) thay vì chỉ tập trung vào cải tiến một module (Token Mixer)
Reference
PoolFormer: https://arxiv.org/abs/2111.11418
MetaFormer: https://arxiv.org/abs/2210.13452
Nguồn: viblo.asia