1. Giới thiệu vấn đề.
Tổng hợp hình ảnh (Image synthesis) hiện nay đang là một hướng đi phát triển trong lĩnh vực Thị Giác Máy Tính (Computer Visison – CV). Tức là ta có thể tạo ra các hình ảnh giống thật qua các mô hình sinh ảnh với đầu vào là dạng văn bản hoặc hình ảnh,…
Mô hình sinh là một bài toán trong học máy liên quan đến việc tự động phát hiện và học các mẫu phổ biến trong dữ liệu để từ đó, mô hình có thể sáng tạo ra các ví dụ mới phù hợp với dữ liệu gốc. Với mô hình sinh ảnh thì chúng sẽ học các thành phần của ảnh trong tập huấn luyện, từ đó sinh ra các mẫu ảnh mới.
Mô hình sinh ảnh nổi tiếng ta có thể kể đến như mạng GAN (Generative Adversarial Network).
Hình ảnh trên với đầu vào là là hình vẽ tay các vật bằng các loại “cọ đối tượng khác nhau”, đầu ra là một bức ảnh sinh ra dựa trên đó.
Vài năm trở lại đây đã nổi lên Diffusion Models là các mô hình cũng dùng để sinh ra dữ liệu ảnh mới nhưng đạt được hiệu suất training tốt hơn mạng GAN. Diffusion Models (DMs) lấy cảm hứng từ hiện tượng nhiệt động lực học không cân bằng từ Vật lý.
Và trong bài viết hôm nay, chúng ta sẽ đi tìm hiểu về Latent Diffusion Models cùng với một số các kĩ thuật cải tiến đi kèm để tổng hợp ra hình ảnh có chất lượng cao theo nội dung mong muốn ở bài báo khoa học “High-Resolution Image Synthesis with Latent Diffusion Models“.
2. Tại sao lại cần có “Latent” trong Diffusion Models.
Như chúng ta đã biết trong lĩnh vực Thị Giác Máy Tính. Các mô hình học của chúng ta đều có kiến trúc rất lớn và phức tạp, đi kèm theo với đó là hàng triệu tham số mô hình. Tập dữ liệu dùng để huấn luyện mô hình cũng là lớn, với các mô hình CV dữ liệu là các ảnh có kích thước lớn do đó ta có thể thấy các phép toán thực hiện là rất nhiều. Điều đó có nghĩa là khi đào tạo mô hình ta rất tốn thời gian. Với các máy tính không có đủ tài nguyên thì việc đào tạo mô hình dường như là không thể tiến triển như mong đợi.
Nhận thức được điều đó, tác giả trong bài báo đã đưa ra một mô hình Encoding hình ảnh của ta trước khi đưa vào mô hình để giảm chiều dữ liệu xuống thấp hơn nhưng vẫn giữ nguyên đầy đủ ngữ nghĩa tri giác về hình ảnh.
Thông thường việc học của Diffusion Models sẽ trải qua 2 giai đoạn:
- Giai đoạn 1: Nén tri giác (Perceptual compression) dùng để xóa đi các thông tin tần số cao về hình ảnh nhưng vẫn học được một ít về ngữ nghĩa.
- Gian đoạn 2: Mô hình sinh sẽ học các ngữ nghĩa và các thành phần của hình ảnh.
Với giai đoạn 1 trong mô hình tác giả sử dụng một mạng CNN dùng để nén tri giác ngữ nghĩa của ảnh, việc nén này giúp giảm chiều dữ liệu hình ảnh xuống nhưng vẫn giữ nguyên được thông tin ngữ nghĩa tri giác về hình ảnh. Tức là họ sẽ không đưa nguyên hình ảnh RGB dạng Pixel vào trong Diffusion Models (DMs) mà nén thành một không gian ẩn khác gọi là Latent Space và quá trình nén này là mô hình học được thông qua quá trình đào tạo. Quá trình này gọi là Encoder, và ta cũng có một bộ Decoder để ánh xạ các giá trị ở không gian ẩn về không gian pixel ban đầu. Giai đoạn 2 tác giả vẫn sử dụng Diffusion models để học ở thông tin ngữ nghĩa ở không gian ẩn này. Một mô hình Diffusion với bộ Autoencoder như thế có tên là Latent Diffusion Models (LDMs).
Điều chú ý là chúng ta chỉ cần training mạng Autoencoder này 1 lần và có thể sử dụng lại cho nhiều các nhiệm vụ khác nhau của việc huấn luyện LDMs.
3. Thế thì họ sẽ tổng hợp hình ảnh có độ phân giải cao như thế nào?
Bài báo có tên là tổng hợp ảnh độ phân giải cao với Latent Diffusion Model. Ở trên mình đã đưa ra cái nhìn cơ bản về Latent Space. Nó có tác dụng giảm chiều dữ liệu ảnh xuống chiều thấp hơn thì cũng có bộ Decode tương ứng để đưa ảnh về kích thước ban đầu. Nhưng như thế vẫn chưa rõ ràng, thế tóm lại nó sẽ tăng độ phân giải hình ảnh lên như thế nào? Ta sẽ cùng đi tìm hiểu chi tiết về phương pháp.
3.1 Perceptual Image Compression.
Tạm dịch tiêu đề trên là nén tri giác hình ảnh. Trong mô hình họ đưa ra biến hình ảnh thành không gian ẩn (Latent Space).
Ta có 1 ảnh RGB x∈RH×W×3x in mathbb{R}^ {H times W times 3} thông qua bộ encoder E(x)E(x) ta được không gian ẩn đại diện z=E(x)z = E(x), tương ứng với nó ta có bộ decoder D(z)D(z) từ không gian ẩn, ta sẽ được x^=D(z)=D(E(x))hat x=D(z) = D(E(x)). Và z∈Rh×w×czin mathbb{R}^{h times w times c}. Và ta cần quan tâm đến một hệ số tỉ lệ giữa kích thước không gian ảnh pixel với kích thước không gian f=H/h=W/wf = H/h = W/w, với f=2mf=2^m với m∈Nmin mathbb{N}
Vậy việc học bộ Encoder và Decoder này như thế nào, dưới đây mình sẽ trình bày về ý tưởng:
Trong khi training mô hình với Encoder và Decoder chúng ta cần học được sự sai khác giữa giá trị ảnh thật và ảnh được tái tạo lại D(E(x))D(E(x)) là ít nhất. Để tránh các giá trị của Latent spaces zz có các giá trị tùy tiện, ta sẽ thêm chính quy hóa vào việc học zz để các giá trị gần không và có phương sai nhỏ. Và họ đưa ra 2 phương pháp để thêm chính quy hóa đó:
- Tối ưu nhỏ nhất giá trị Kullback-Leibler giữa qE(z∣x)=N(z,Eμ,Eσ2)q_E(z|x)=N(z, E_mu, E_{sigma^2}) với phân phối chuẩn N(z,0,1)N(z,0,1)
- Chính quy hóa không gian ẩn với một lớp vector lượng tử hóa bởi việc học một codebook ∣Z∣|Z|.
Để có được các bức ảnh tái tạo có độ trung thực cao ta sẽ sử dụng chính quy hóa rất nhỏ cho cả 2 cách.
Đối với cách đầu tiên ta chọn các giá trị nhỏ của KL ở vào khoảng hệ số 10−610^{-6}, còn cách thứ hai, ta sẽ chọn codebook có số chiều cao.
Mình xin phép được trình bày cách thứ 2 như sau:
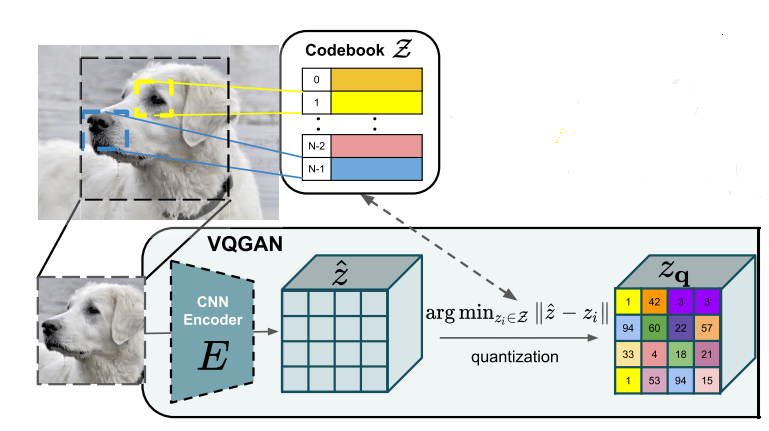
Nhìn vào ảnh ta có thể thấy ban đầu model của chúng ta dùng một CNN Encoder để học không gian ẩn z^hat z và một mạng VQGAN dùng để học Codebook ZZ với Z={zk}k=1K∈RnzZ ={z_k}^K_{k=1} in mathbb{R}^{n_z}. Chúng ta tạo ra được zqz_q bằng cách sử dụng z^=E(x)∈RH×W×nzhat z = E(x) in mathbb{R}^{H times W times n_z} và một phép lượng tử hóa vector q(.)q(.) với mỗi z^ij∈Rnzhat z_{ij}in mathbb{R}^{n_z} như sau:
zq=q(z^):=(argminzk∈Z∣∣z^ij−zk∣∣)∈Rh×w×nzz_q = q(hat z) := (argmin_{z_k in Z} || hat z_{ij} – z_k|| ) in mathbb{R}^{h times w times n_z}
Việc áp dụng thêm chính quy hóa sử dụng codebook ZZ mang lại cho không gian ẩn các ngữ nghĩa tri giác tương tương. Và sẽ sử dụng zqz_q này để đi vào trong Diffusion Models. Vậy Diffusion Models là gì, ta sẽ cùng tìm hiểu ở phần tiếp theo.
3.2 Diffusion Models.
Diffusion Models (DMs) là một mô hình xác suất được thiết kế để học các phân phối xác suất trong quá trình thêm nhiễu và khử nhiễu cho ảnh trong quá trình huấn luyện. Hiểu một cách đơn giản thì mô hình của chúng ta được huấn luyện từ một bức ảnh ban đầu, thêm nhiễu (noise) dần qua từng bước và đầu ra cuối cùng là một ảnh toàn nhiễu. Sau đó quá trình khử nhiễu, từ một ảnh đầy nhiễu, sẽ khử nhiều dần qua từng bước và được một ảnh không nhiễu ban đầu. Thế thì DMs sẽ học cái gì, nó sẽ học để dự đoán ra noise ở mỗi bước và ta sẽ lấy cái ảnh có noise ở bước đó để trừ đi noise được ảnh ít noise hơn.
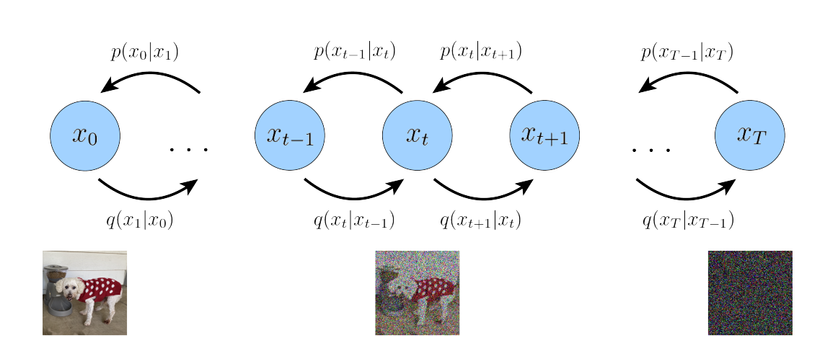
Mính sẽ giải thích một chút toán của mô hình.
Ta có x0x_0 là giá trị ảnh đầu vào, xtx_t là ảnh thêm noise ở từng bước và xTx_T là bức ảnh toàn noise ở cuối cùng.
Với quá trình khuếch tán thuận, mô hình sẽ tính noise và thêm vào các ảnh theo phân phối xác suất q(x1:T∣x0)q(x_{1:T}|x_0) được gọi với thuật ngữ là diffusion process, và xác suất này được đưa về dạng chuỗi Markov như sau:
q(x1:T∣x0):=∏t=1Tq(xt∣xt−1)q(x_{1:T}|x_0) := prod_{t=1}^T q(x_t|x_{t-1})
và từng cái phân phối xác suất này sẽ tuân theo một phân phối chuẩn, q(xt∣xt−1):=N(xt,1−βtxt−1,βtI)q(x_t|x_{t-1}):=N(x_t, sqrt{1-beta_t}x_{t-1}, beta_tI), với βbeta là một phương sai có thể được học hoặc cố định như các hyperparameter. Điều đáng chú ý là ta có thể lấy mẫu xtx_t tại bước thời gian tt theo x0x_0 như sau:
q(xt∣x0)=N(xt,αˉtx0,(1−αˉ)I)αt:=1−βtαˉt:=∏s=1tαsq(x_t|x_0)=N(x_t,sqrt{=alpha_t}x_0, (1-=alpha)I) \
alpha_t := 1- beta_t \ =alpha_t := prod_{s=1}^t alpha_s
Đó là quá trình thuận tạo ra noise cho ảnh ở các bước thời gian tt.
Đối với quá trình ngược, mô hình sẽ dựa vào phân phối xác suất pθ(x0):=∫pθ(x0:T)dx1:Tp_theta(x_0):= int p_theta(x_{0:T})dx_{1:T} và x0∼q(x0)x_0 sim q(x_0). Một phân phối xác suất chung pθ(x0:T)p_theta(x_{0:T}) được gọi là reverse process, và nó cũng được viết dưới dạng chuỗi Markov như sau và bắt đầu học quá trình ngược từ p(xT)=N(xT;0,I)p(x_T) = N(x_T;0,I):
pθ(x0:T):=p(xT)∏t=1Tpθ(xt−1∣xt),pθ(xt−1∣xt):=N(xt−1,μθ(xt,t),Σθ(xt,t))p_theta(x_{0:T}) := p(x_T)prod_{t=1}^Tp_theta(x_{t-1}|x_t),
\
p_theta (x_{t-1}|x_t) := N(x_{t-1}, mu_theta(x_t,t), Sigma _theta(x_t,t))
Việc huấn luyện mô hình dựa trên việc tối ưu giới hạn của negative log likelihood:
E[−logpθ(x0)]≤Eq[−logpθ(x0:T)q(x1:T∣x0)]=E[−logp(xT)−∑t≥1logpθ(xt−1∣xt)q(xt∣xt−1)]:=Lmathbb{E} [-log p_theta(x_0) ] leq mathbb{E}_q [-log frac{p_theta(x_{0:T)}}{q(x_{1:T}|x_0)}] = mathbb{E}[-log p(x_T) – sum_{t geq1}log frac{p_theta(x_{t-1}|x_t)}{q(x_t|x_{t-1})}] :=L
Việc tối ưu hóa hiệu quả có thể thực hiện được Stochastic Gradient Descent. Những cải tiến hơn nữa đến từ việc giảm phương sai bằng cách viết lại L như sau:
Eq[DKL(q(xT∣x0)∣∣p(xT)⏟LT+∑t>1DKL(q(xt−1∣xt,x0)∣∣pθ(xt−1∣xt)⏟Lt−1−logpθ(x0∣x1)⏟L0]mathbb{E}_q left[ underbrace{D_{KL}(q(x_T|x_0)||p(x_T)}_{L_T} + sum_{t>1} underbrace{D_{KL}(q(x_{t-1}|x_t,x_0)||p_theta (x_{t-1}|x_t)}_{L_{t-1}} -underbrace{log p_theta(x_0|x_1)}_{L_0}right ]
Ở đây ta thấy có kí hiệu DKLD_{KL} chính là Kullback-Leibler Divergence là phép đo sự khác biệt giữa 2 phân phối trên. Trong công thức trên ta thấy họ dùng DKLD_{KL} để so sánh trực tiếp pθ(xt−1∣xt)p_theta(x_{t-1}|x_t) với các hàm phân phối ở chiều thuận, và trong quá trình huấn luyện ta luôn cố gắng học để sự khác biệt giữa các phân phối này là nhỏ nhất, tức là nó có thể học được đúng với các noise mà nó đã tạo ra trong quá trình thuận.
q(xt−1∣xt,x0)=N(xt−1;μ˜t(xt,x0),β˜tI),μ˜t(xt,x0):=αˉt−1βt1−αˉtx0+αt(1−αˉt−1)1−αˉtxt,β˜t:=1−αˉt−11−αˉtβtq(x_{t-1}|x_t,x_0) = N(x_{t-1}; ~mu_t(x_t,x_0), ~beta_tI),\
~mu_t(x_t,x_0) := frac{sqrt{=alpha_{t-1}}beta_t}{1- =alpha_t}x_0 + frac{sqrt{alpha_t}(1-=alpha_{t-1})}{1-=alpha_t}x_t,\
~beta_t := frac{1-=alpha_{t-1}}{1-=alpha_t}beta_t
Và ta có thể viết Lt−1L_{t-1} đưới dạng sau:
Lt−1=Eq[12σt2∣∣μ˜t(xt,x0)−μ0(xt,t)∣∣2]+CL_{t-1} = mathbb{E} _q left[ frac{1}{2 sigma_t^2} || ~mu_t(x_t,x_0) – mu_0(x_t,t)||^2 right] +C
Mục tiêu học của mô hình là học hàm μθmu_theta để dự đoán μ˜~mu. Ta sẽ mở rộng hơn phương trình trên bằng cách tham số hóa xt(x0,ϵ)=αˉtx0+1−αˉtϵx_t(x_0,epsilon) = sqrt{=alpha_t}x_0 + sqrt{1-=alpha_t }epsilon với ϵ∼N(0,I)epsilon sim N(0,I). Ta thay xtx_t vào phương trình và biến đổi thành như sau:
Lt−1−C=Ex0,ϵ[12σt2∣∣1αt(xt(x0,ϵ)−βt1−αˉtϵ)−μθ(xt(x0,ϵ),t)∣∣2]L_{t-1} -C = mathbb{E}_{x_0,epsilon} left[ frac{1}{2sigma_t^2}||frac{1}{sqrt{alpha_t}}left( x_t(x_0,epsilon ) – frac{beta_t}{sqrt{1-=alpha_t}}epsilon right) – mu_theta(x_t(x_0,epsilon),t)||^2 right]
Từ đó suy ra được rằng:
μθ(xt,t)=μ˜t(xt,1αˉt(xt−1−αˉtϵ(xt)))=1αt(xt−βt1−αˉtϵθ(xt,t))mu_theta (x_t,t) = ~mu_t(x_t, frac{1}{sqrt{=alpha_t}}(x_t – sqrt{1-=alpha_t}epsilon(x_t)))= frac{1}{sqrt{alpha_t}}(x_t -frac{beta_t }{sqrt{1-=alpha_t}} epsilon_theta(x_t,t))
Với ϵθ(.)epsilon_theta(.) là một hàm xấp xỉ dự đoán ϵepsilon từ xtx_t. Ta sẽ sinh ra xt−1∼pθ(xt−1∣xt)x_{t-1} sim p_theta(x_{t-1}|x_t) và tính được xt−1=1αt(xt−βt1−αˉtϵθ(xt,t))+σtzx_{t-1} = frac{1}{sqrt{alpha_t}}(x_t – frac{beta_t}{sqrt{1-=alpha_t}} epsilon_theta(x_t,t)) + sigma_tz với z∼N(0,I)z sim N(0,I).
Ta có hàm loss như sau:
Ex0,ϵ[βt22σt2αt(1−αˉt)∣∣ϵ−ϵθ(αˉtx0+1−αˉtϵ,t)∣∣2]mathbb{E}_{x_0,epsilon} left[ frac{beta_t^2}{2sigma_t^2alpha_t(1-=alpha_t)} ||epsilon – epsilon_theta(sqrt{=alpha_t}x_0 + sqrt{1-=alpha_t}epsilon, t)||^2right]
Trong công thức, ϵepsilon là noise sinh ra trong quá tình thuận ở bước thứ t, ϵθepsilon_theta là giá trị noise dự đoán tương ứng.
Công thức toán mình đưa ra hơi nhiều và rắc rối, phần chứng minh chi tiết các bạn có thể xem tại paper gốc mình để bên dưới link tham khảo.

Tóm tắt lại thuật toán: Trong quá trình huấn luyện, từ quá trình thuận ta thêm các noise vào ảnh gốc qua từng bước thời gian, đến khi được ảnh toàn noise. Quá trình ngược bắt đầu từ ảnh toàn noise, ta làm bớt noise đi sau mỗi bước thời gian tt bằng cách dự đoán noise và lấy ảnh xtx_t trừ đi noise ta sẽ được ảnh xt−1x_{t-1} ít noise hơn. Quá trình học là học các dự đoán noise với noise ban đầu ta thêm vào. Quá trình sinh ảnh từ một ảnh noise ta khử dần noise sinh ra ảnh không còn noise dựa vào quá trình trình ngược.
3.3 Latent Diffusion Models với cơ chế điều kiện.
Với 2 phần vừa nêu ở trên là nén tri giác ảnh và Diffusion Models, ta kết hợp chúng lại và có hàm loss đơn giản như sau:
LLDM:=EE(x),ϵ∼N(0,1),t[∣∣ϵ−ϵθ(zt,t)∣∣22]L_{LDM} := mathbb{E}_{E(x),epsilon sim N(0,1),t} left[||epsilon – epsilon_theta(z_t,t)||_2^2right]
Việc học hàm ϵθepsilon_theta bằng cách cho ảnh có noise đi qua mạng U-net, đầu ra là noise của bức ảnh đó. Bên dưới là kiến trúc của U-net.
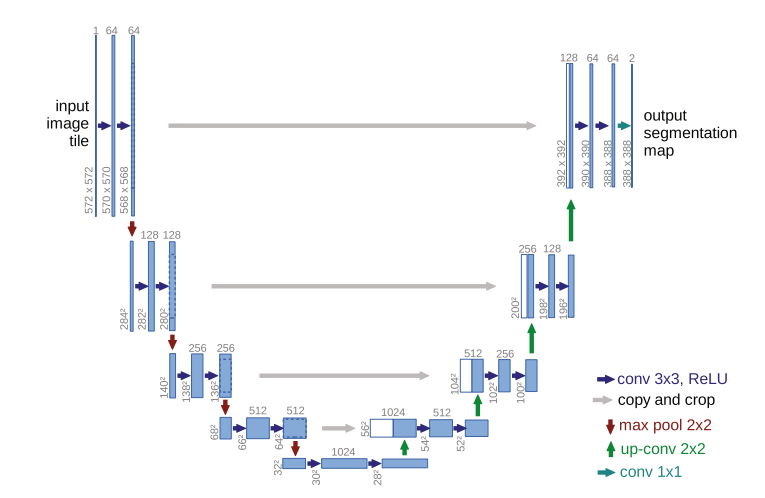
Dùng mạng Latent Diffusion models có thể sinh ra ảnh mới nhưng làm thế nào để sinh ra ảnh theo ý muốn của mình và là ảnh có độ phân giải cao. Thì tác giả đã đưa ra một cơ chế điều kiện giúp kiểm soát quá trình sinh ảnh như sau.
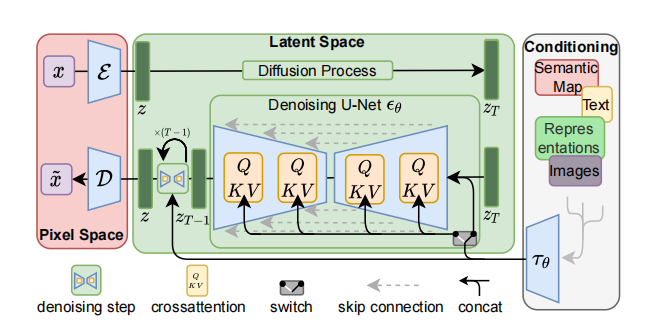
Ở trên hình ta có thể thấy điều kiện mà chúng ta thêm vào đó là text, ảnh, hoặc semantic map,… thông qua một cơ chế encoder đặc biệt τθtau_theta với input là yy; τθ(y)∈RM×dτtau_theta(y) in mathbb{R}^{M times d_tau}. Output của τθtau_theta sẽ được ánh xạ tới các lớp trung gian của UNet thông qua cơ chế cross-attention.
Cụ thể:
Attention(Q,K,V)=softmax(QKTd).V),Q=WQ(i).φi(zt),K=WK(i).τθ(y),V=WV(i).τθ(y).Attention(Q,K,V) = softmax left(frac{QK^T}{sqrt{d}}).V right),\
Q= W_Q^{(i)}.varphi_i(z_t), K = W_K^{(i)}.tau_theta(y), V =W_V^{(i)}.tau_theta(y).
Với φi(zt)∈RN×dϵivarphi_i(z_t) in mathbb{R}^{N times d_epsilon^i} là một đại diện trung gian của UNet khi thực hiện Denoising, tức là đây là giá trị output trước khi đi qua Max pool hay Up-conv trong Unet. WV(i)∈Rd×dϵi,WQ(i)∈Rd×dτ,WK(i)∈Rd×dτW_V^{(i)} in mathbb{R}^{d times d_epsilon^i}, W_Q^{(i)} in mathbb{R}^{d times d_tau}, W_K^{(i)} in mathbb{R}^{d times d_tau} là ma trận học được trong quá trình huấn luyện.
Lúc này hàm loss của chúng ta sẽ có dạng như sau:
LLDM:=EE(x),y,ϵ∼N(0,1),t[∣∣ϵ−ϵθ(zt,t,τθ(y))∣∣22]L_{LDM} := mathbb{E}_{E(x), y, epsilon sim N(0,1), t} left[||epsilon – epsilon_theta(z_t, t,tau_theta(y))||^2_2 right]
Việc tối ưu bây giờ sẽ cho cả τθtau_theta và ϵθepsilon_theta.
Đó là cơ chế điều khiển để kiếm soát nội dung của ảnh được sinh ra nhưng ta vẫn chưa thấy làm thế nào để ảnh có độ phân giải cao. Các bạn còn nhớ tỉ lệ ff khi mình đề cập đến trong phần nén ảnh sang không gian ẩn chứ, ta sẽ dựa vào nó để tăng độ phân giải. Dựa vào tỉ lệ ff bộ Decoder sẽ đưa zz về tỉ lệ theo ff, tức là tùy thuộc vào ff lớn hay nhỏ mà độ phân giải tăng lên nhiều hay ít.
Quá trình sinh ảnh từ quá trình ngược với đầu vào xTx_T toàn noise độ phân giải h×wh times w kết hợp với cơ chế điều kiện τθtau_theta, sau khi khử hết noise, ta được zz và cho đi qua decoder ảnh đầu ra sẽ có độ phân giải H×WH times W với H/h=W/w=fH/h=W/w=f.
4. Kết quả thực nghiệm.

Bên trên là kết quả tổng hợp ảnh của text-to-image model, với LDM−8(KL)LDM-8(KL) là Latent Diffusion Models với f=8f=8 và sử dụng KL-regularized cho quá trình nén ảnh, huấn luyện trên bộ dữ liệu LAION.
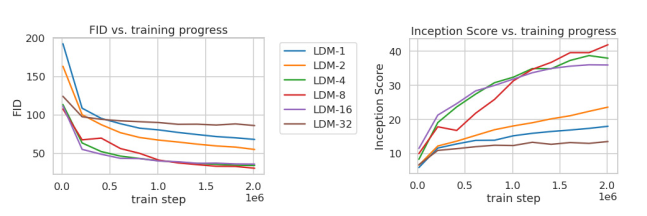
Biểu đồ trên phân tích kết quả với các giá trị ff khác nhau với khoảng 2 triệu bước trên bộ dữ liệu ImageNet. Ta có thể thấy f=1f=1 tương đương với không gian Pixel tốn nhiều thời gian huấn luyện hơn với các giá trị ff khác. f=32f=32 làm hạn chế chất lượng tổng hợp ảnh. Các model với f∈{4,8,16}f in {4,8,16} có kết quả tốt hơn các model khác.
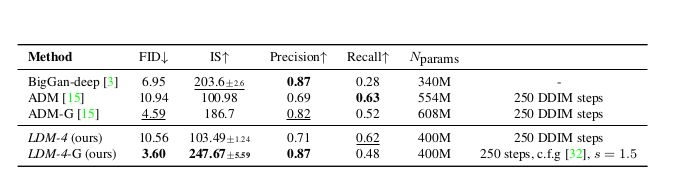
Sự so sánh các model với điều kiện phân lớp trên bộ dữ liệu ImageNet. LDM-4 đạt được hiệu quả cao hơn.
5. Tổng hợp hình ảnh độ phân giải cao với các điều kiện như thế nào?
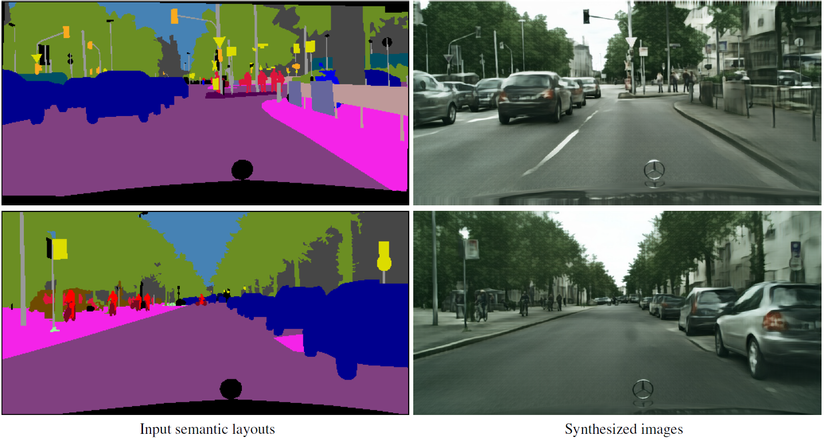
5.1 Tạo ra ảnh độ phân giải cao từ semantic maps.
Họ đào tạo mô hình sử dụng ảnh về phong cảnh cùng với bản đồ ngữ nghĩa của chúng làm cơ chế điều kiện và tỉ lệ f=4f=4. Với đầu vào có độ phân giải 2562256^2 có thể sinh ra được ảnh với độ phân giải lớn tới Megapixel.

5.2 Ảnh siêu phân giải từ ảnh có phân giải thấp.
LDMs được đào tạo sinh ra ảnh có độ phân giải cao bởi điều kiện dựa vào ảnh có độ phân giải thấp hơn. Họ sử dụng f=4f=4 trong autoencoder model được pretrained OpenImage và sử dụng ảnh phân giải thấp encoder τθtau_theta.

6. Kết luận
Với mô hình trên ta thấy tác giả đã thêm vào 2 phần chính là phần Autoencoder để đưa không gian ảnh thành không gian Latent với số chiều giảm hơn và ngược lại, cơ chế điều kiện giúp sinh ảnh với nội dung theo ý muốn. Mô hình của tác giả đã đưa ra một cách đơn giản và hiệu quả để cải thiện đáng kể cả hiệu quả đào tạo và sinh ảnh với Denoising Diffusion Models, mà không làm giảm chất lượng của chúng.
Tham khảo
- High-Resolution Image Synthesis with Latent Diffusion Models (https://arxiv.org/abs/2112.10752).
- Understanding Diffusion Models: A Unified Perspective (https://arxiv.org/abs/2208.11970).
- Denoising Diffusion Probabilistic Models (https://arxiv.org/abs/2006.11239).
- Taming Transformers for High-Resolution Image Synthesis (https://arxiv.org/abs/2012.09841).
Nguồn: viblo.asia