1. Mở đầu
Chào các bạn, vậy là mình cũng đã lặn sâu được gần 10 tháng, hôm nay mình đã quay trở lại. Lần này là một nội dung “cũ mà mới”. Cũ vì khi nhắc đến cache, gần như mọi người đã được nghe đến, đã được tiếp cận, đã làm việc hoặc đã được đọc những bài viết vô cùng chất lượng trên Viblo của các tác giả khác. Mới vì ở bài viết này:
- Sẽ không đi sâu vào việc tích hợp Cache trong source code như thế nào mà tập trung vào quá trình phân tích, trải nghiệm của một Newbie (là mình cách đây hơn 1 năm) tập tành sử dụng Cache
- Bài viết sẽ không đi hết mọi thứ về Cache, mà nghiêng về sự trải nghiệm với những gì đã học, đã làm về Cache.
Mình phải nói trước như vậy để tránh các bạn quá kì vọng vào nội dung rồi không tìm thấy gì quá mới mẻ, nhất là các bạn đã có kinh nghiệm. Còn nếu bạn cũng là newbie, muốn đồng hành cùng bài viết này thì cùng xem tiếp nhé
2. Nắm bắt tình hình
Quay trở lại hơn 1 năm về trước, khi 1 trong những dự án nhỏ của mình tham gia gặp vấn đề về “Performance”. API mất quá nhiều thời gian để có thể trả dữ liệu về phía Client. Đồng thời kéo theo CCU của ứng dụng là rất nhỏ. Hãy lấy 1 ví dụ: Thông thường, 1 API xem chi tiết một bài Blog sẽ có endpoint như này /api/v1/posts/:post_id
Và tin được không, khi chỉ cần khoảng 30 user truy cập vào 1 lúc là thứ mà bạn thấy trên màn hình là hiệu ứng “loading”. Đo thời gian trung bình, API trên sẽ cần khoảng 4.25s để trả kết quả về client
Được rồi, dù dự án có nhỏ đi chăng nữa thì không thể chấp nhận một con số như thế. Mình bắt đâu đi suy xét tình hình:
- Kiểm tra cấu hình server: 8GB RAM / 6 core / 100GB SSD. Trông ổn, nhất là với ứng dụng nhỏ
- Kiểm tra môi trường: BE của ứng dụng được viết bằng Typescript chạy trên Node.js runtime. Mà nhắc đến Node là nhắc đến Single Thread. Vì vậy cần tận dụng những thứ như Promise, Cluster để tăng performance…. Mình kiểm tra tất cả những thứ này, tất cả đã được implement đúng cách. Ngang đây sẽ có bạn thắc mắc rằng code Promise như nào là đúng cách và tốt cho hiệu suất? Yên tâm, mình sẽ có 1 bài viết riêng biệt cho vấn đề này, còn bài này tập trung vào Cache nhé
- Kiểm tra database (DB): DB được sử dụng là MongoDB. Thứ mà mình quan tâm đến là query đã được viết tốt chưa? Mình đánh giá qua 1 số tiêu chí như:
- Dữ liệu có thừa không (Chỉ lấy những gì cần thiết)?
- Sử dụng aggregate, lookup, pagination đã đúng chưa? Có thừa query hay không? – Phần này cũng sẽ có bài viết riêng nhé
- DB đã được đánh index chưa?
Xem qua thì có 1 số vấn đề, mình đã điều chỉnh lại. Tuy nhiên tình hình dù có cải thiện, chủ yếu là giảm tải cho DB, giảm response data size, chứ chưa thực sự cải thiện nhiều về CCU. Lúc này, mình lai tiếp tục tìm hiểu xem logic của API. Đầu tiên là xem API cần lấy những thông tin gì.
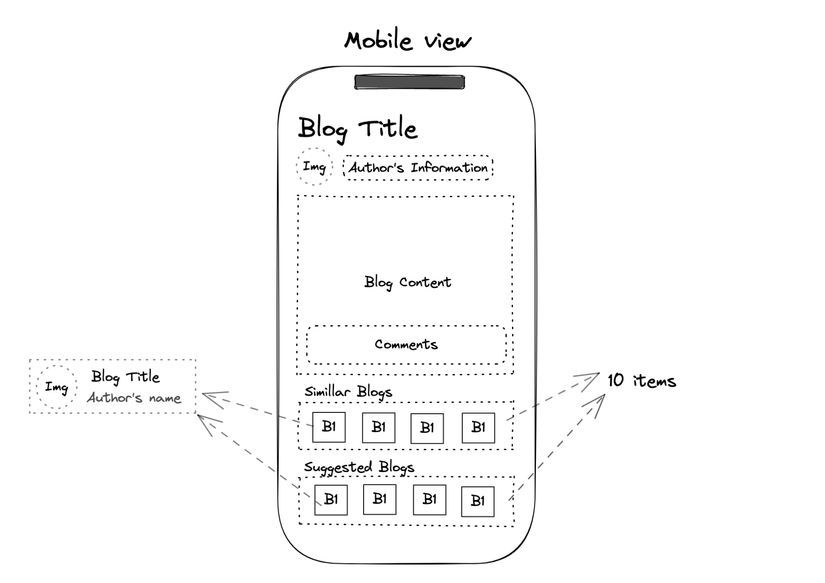
- Dữ liệu về bài viết (Blog): Tất nhiên, nội dung chính mà. Phần này thì chỉ cần query theo
post_idtrong bảng Blogs là xong - Tác giả bài viết (User hay Author): Cần một số thông tin như: Tên, ảnh đại diện, thông tin thống kê (số bài viết, số lượt thích, đánh giá trung bình,…), giới thiệu,… lấy từ bảng Users
- Danh mục (Category): Phần này cần lấy đầy đủ cây danh mục của ứng dụng để người dùng thay đổi.
- Bài viết tương tự, bài viết gợi ý: Danh sách các bài viết tương tự dựa trên 1 số tiêu chí chung, phần này vẫn lấy từ bảng Blogs nhé. Mỗi mục tương tự hay gợi ý lấy về khoảng 10 bài viết, mỗi bài viết chỉ hiển thị tiêu đề và thông tin cơ bản của tác giả tương ứng
- Danh sách bình luận (Comment): Lấy từ bảng Comments
Thông tin cần truy vấn ở đây là khá nhiều. Lúc này, mình bắt đầu nghĩ đến cache
3. Tại sao lại nghĩ đến cache?
Như các bạn thấy những thông tin cần trả về client ở màn hình xem bài viết là như trên. Lúc này, căn cứ vào thiết kế hệ thống, mình chia thành 2 loại dữ liệu chính:
- Static Data: Dữ liệu tĩnh. Là dữ liệu không thay đổi, là cố định trên hệ thống. Chỉ tạo 1 lần và sử dụng mãi mãi thì có Danh mục (Category).
- Dynamic Data: Dữ liệu động. Là dữ liệu có khả năng thay đổi theo thời gian với nhiều mức độ khác nhau. Mình tiếp tục chia thành các mức độ sau:
- Low: Dữ liệu ít bị thay đổi, tần suất thay đổi khoảng 1 ngày trở lên: Mình đưa phần thông tin user vào mức độ này
- Medium: Dữ liệu có sự thay đổi thường xuyên hơn, thường tính bằng giờ: Mình đưa phần thông tin bài viết chính, danh sách bài viết tương tự, bài viết gợi ý vào mức độ này, bởi ngoại trừ bài viết chính cần hiển thị đủ thông tin, dữ liệu còn lại như đã nói chỉ bao gồm tiêu đề và thông tin cơ bản tác giả. Về tác giả thì đã được phân loại vào mức “low” ở trên, còn phần tiêu đề cũng hiếm khi bị thay đổi. Thứ thay đổi nhiều hơn ở đây là điều kiện đánh giá tiêu chí bài viết tương tự, bài viết gợi ý
- High: Dữ liệu có sự thay đổi liên tục, thường tính bằng giây hoặc phút. Mình đưa phần comments vào mức độ này
Lưu ý: Mức độ thay đổi dữ liệu được mình tính dựa trên khả năng “xấu nhất”, tức là mức độ thay đổi dữ liệu thường xuyên nhất của đối tượng và mang tính chất tương đối. Việc phân chia như trên sẽ giúp chúng ta đánh giá được dữ liệu, từ đó đưa ra được phương pháp cache “đúng hoặc gần đúng”
Như vậy, ta nhận thấy rằng việc cache dữ liệu cho các thông tin trên là hoàn toàn khả thi để tăng hiệu năng hệ thống, nhất là với phần dữ liệu tĩnh. Lan man thế đã đủ, giờ thì bắt tay vào ứng dụng thôi
4. Ứng dụng
4.1. Cache cho phần danh mục (Category)
Xời, cái này thì dễ quá rồi đúng không. Đây là phần dữ liệu tĩnh, việc duy nhất của chúng ta là lưu dữ liệu lên cache 1 lần duy nhất, sau đó chỉ việc đọc nó mà thôi, mô hình đơn giản thì thế này:
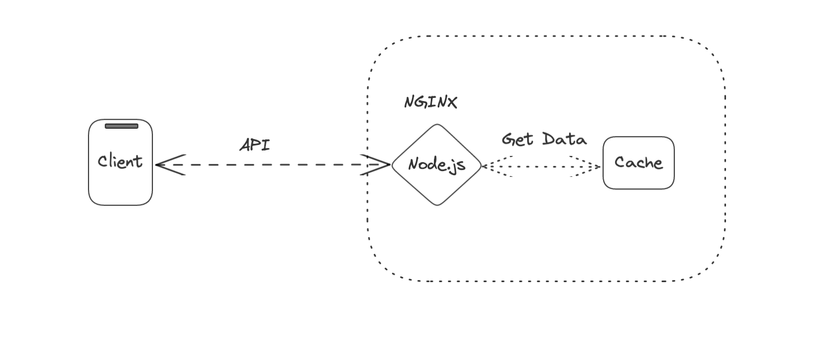
Tuy nhiên, nếu một ngày nào đó, anh cache nổi chứng ra sập, vậy thì ứng dụng chẳng phải sẽ không thể hiển thị được danh mục hay sao? 🤔
Thế thôi thì, ta sẽ xây dựng lại mô hình để dự phòng cho trường hợp này nhé:
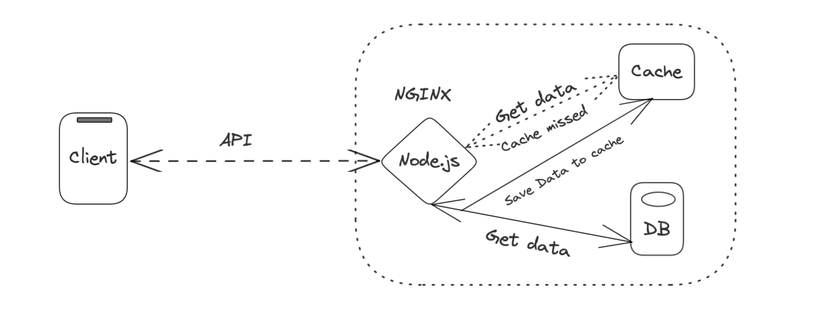
Triển khai ở code thì nó trông như này:
constgetOrSetCategory=async()=>{let categories =awaitgetCategoryFromCache(key)if(!categories){
categories =awaitgetCategoryFromDB()setCategoryCache(categories)}return categories
}4.2. Cache cho phần thông tin tác giả (Users) và danh sách bài viết tương tự, bài viết gợi ý (Blogs)
Về mặt đọc dữ liệu từ API sẽ không có gì khác so với logic ở trên. Điều mà chúng ta quan tâm ở đây là: Khi dữ liệu thay đổi, ta sẽ cập nhật cache như thế nào?
Như đã phân tích ở trên, dữ liệu hiển thị cho những đối tượng này có sự thay đổi ở mức độ “Low or Medium”. Do đó, mình chọn giải pháp là xây dựng 1 background job để chạy mỗi 6h/lần cho User và 1h/lần cho 2 danh sách bài viết gợi ý và bài viết tương tự. Tại sao mình lại chọn con số 6h và 1h, và nó có ý nghĩa gì?
Đó chính là thời gian tối đa mà mình chấp nhận sự sai lệch dữ liệu giữa cache và DB. Việc chọn các con số này phụ thuộc vào mức độ realtime mà các bạn muốn áp dụng cho phần mà các bạn cache. Ở đây, các dữ liệu hiển thị như tên tác giả, các thông số thống kê của tác giả hay tên bài viết là những dữ liệu ít dc thay đổi, do vậy, mình chọn 2 con số trên
Bây giờ, mô hình của nó sẽ như thế này:
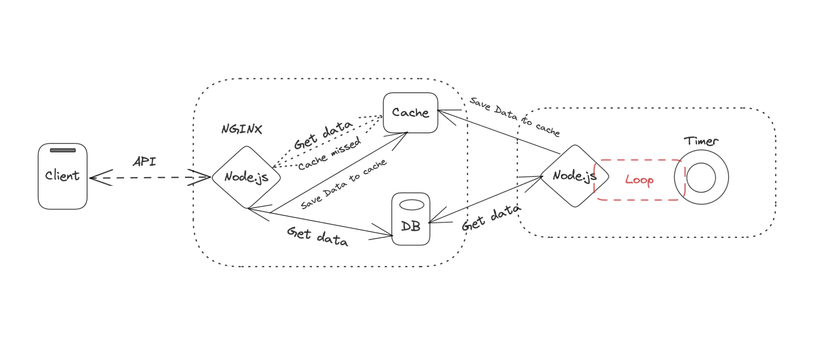
Điểm mới ở đây chính là mình xây dựng thêm 1 con Node hoạt động độc lập. Chức năng của nó là xử lý các background job để phân tích, cập nhật dữ liệu lên cache. Nó sẽ lặp lại theo thời gian định sẵn để thực hiện các tác vụ mà mình cần. Các bạn có thể sử dụng package “node-cron” nhé
4.3. Cache cho phần bình luận (Comments)
Sau một thời gian theo dõi, thống kê, mình nhận thấy rằng đây là phần có dữ liệu thường xuyên thay đổi nhất trên ứng dụng. Các bình luận được tạo mới / chỉnh sửa liên tục. Nguyên do là hệ thống ở thời điểm đó chưa có chức năng Q&A riêng biệt, do đó, mỗi khi người dùng có thắc mắc hay điều cần trao đổi, họ đều sử dụng tính năng bình luận
Một lần nữa, mô hình đọc dữ liệu sẽ không thay đổi. Vậy việc cập nhật cache thì sao? Có thể sử dụng background job như trên không?
Câu trả lời là được. Chỉ cần giảm thời gian giữa các lần chạy xuống còn 10s/lần là cũng ổn đấy. Nhưng, liệu nó có tốt, khi mà các job sẽ chồng chéo lên nhau, và liệu 10s có đủ để job hoàn thành việc đọc, phân tích và cập nhật dữ liệu?
Chính vì vậy, mình chọn triển khai cache cho phần này theo một cách khác:
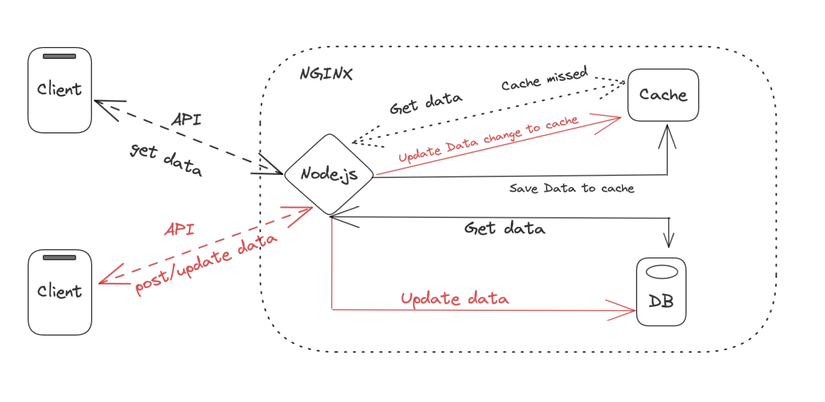
Phần màu đỏ chính là phần mới của mô hình này, mỗi khi có 1 yêu cầu cập nhật dữ liệu, BE sẽ thực hiện việc cập nhật dữ liệu lên DB. Nếu quá trình lưu thành công, dữ liệu sẽ đồng thời được cập nhật ngay lên cache. Code sẽ trông như thế này:
constupdateData=async(newData)=>{const updatedData =awaitsaveDataToDB(id, newData)findAndUpdateCache(key, updatedData)return updatedData
}Cũng khá dễ hiểu đúng không nào? Tuy nhiên, ta cần nghĩ đến 1 bài toán lớn hơn. Trên thực tế, sẽ có nhiều API cùng thực hiện việc tạo mới / cập nhật một đối tượng. Theo mô hình trên thì ta phải gọi hàm updateData ở tất cả các API đó
Lúc này, mình áp dụng 1 số kĩ thuật tối ưu hơn như:
- Redis Pub/Sub
- Mongo Change Stream (yêu cầu có Mongo Replica Set)
- Node EventEmitter
Các kĩ thuật này sẽ giúp tự động hoá phần nào việc theo dõi sự thay đổi dữ liệu trên hệ thống và lưu vào cache. Mình sẽ không đi sâu vào việc sử dụng các kĩ thuật này, vì đã có nhiều tác giả viết về những thứ này rồi
5. Kết quả
Vậy là đã cache được hầu hết các dữ liệu trên API xem bài viết rồi, thành quả sau khi cache thì mình đo được:
- Giảm thời gian phản hồi trung mình của API xuống <= 30ms
- Tỉ lệ hit cache đạt <= 85%, giảm gánh nặng cho DB (Sẽ nhiều bạn thấy tỉ lệ cache này chưa cao, thì hãy đọc thêm bài API NodeJS của tôi đã handle peak traffic như thế nào? của tác giả Minhmonmen nhé, sẽ biết cách để tăng tỉ lệ nha, rất hay đấy)
- Tăng CCU lên ~ 8000 CCU (800 req/s)
Thành quả này là nhỏ thôi, nhưng nó cũng là động lực cho 1 newbie về caching cách đây 1 năm
6. Kết luận
Như các bạn thấy ngay từ phần “Nắm bắt tình hình” ở trên, mình đã kiểm tra qua khá nhiều thứ trước khi nghĩ đến cache, chứ không lạm dụng nó ngay. Cache chỉ nên được sử dụng khi nó thật sự cần thiết và phải sau khi kiểm tra code, DB query. Bởi nếu bản chất những thứ trên chưa tốt, mà lạm dụng cache khi chưa cần thiết, sẽ làm tăng tài nguyên hệ thống, khi đạt 1 giới hạn, sẽ làm tăng chi phí dự án, mà điều này gần như khách hàng của chúng ta không mong muốn, họ chỉ mong sao cho “với chi phí nhỏ nhất có thể làm ra được 1 ứng dụng tốt nhất tương xứng”
Cách phân chi dữ liệu thành 2 dạng static data và dynamic data ở trên sẽ giúp chúng ta dễ dàng nhận biết cần cache những gì hơn. Hiển nhiên, dữ liệu tĩnh được cache là điều nên làm. Còn với dữ liệu động, nó nên tuỳ thuộc vào mức độ thay đổi dữ liệu để xác định có nên cache hay không? Nếu mức độ dữ liệu thay đổi thường xuyên, thì cần phải lựa chọn phương án cập nhật sao cho độ sai lệch dữ liệu là nhỏ nhất
Một lưu ý “nhỏ mà có võ” nữa là: Các bạn chỉ nên lưu lên cache dữ liệu vừa đủ, không thừa cũng không thiếu. Nếu dữ liệu quá nhiều ngoài việc tăng tốn kém tài nguyên, nó sẽ còn làm chậm quá trình đọc dũ liệu từ cache nữa đó nhé
Sẽ vẫn còn nhiều điều thú vị về cache, về trải nghiệm của mình nữa, nhưng hôm nay tạm nghỉ ở đây thôi. Nếu bài viết nãy hữu ích, đừng quên Upvote, đóng góp ý kiến và chờ bài viết sau nhé. Cám ơn các bạn thật nhiều và hẹn gặp lại 👋
Nguồn: viblo.asia