Mở đầu
Trong quá trình deploy các dự án lên server, thì việc hệ thống của mình “lên hình” là một chuyện, nhưng việc duy trì độ “ngon lành” của nó lại là 1 chuyện khác.
Nhiều lúc mình mải các việc cá nhân khác hoặc các dự án khác không để ý tới hệ thống, thì đôi lúc nó đã bị “down” bởi một vài lý do mà mình không lường trước được. Vì thế ở bài này mình sẽ hướng dẫn các bạn
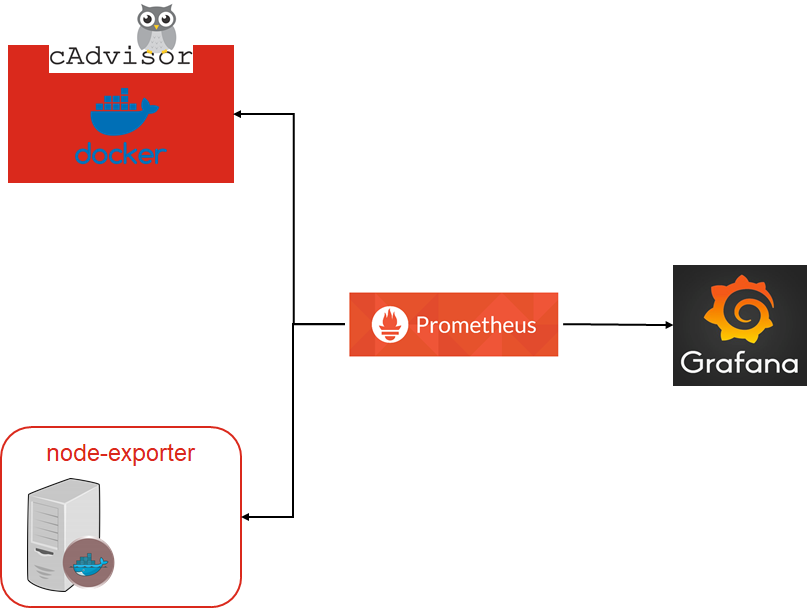
Monitoring hệ thống đơn giản với bộ công cụ Grafana, Prometheus, Cadvisor và Node Exporter được mình dựng tất cả môi trường dưới dạng container. Dưới đây là minh họa sơ đồng tổng quát
Grafana là gì ?
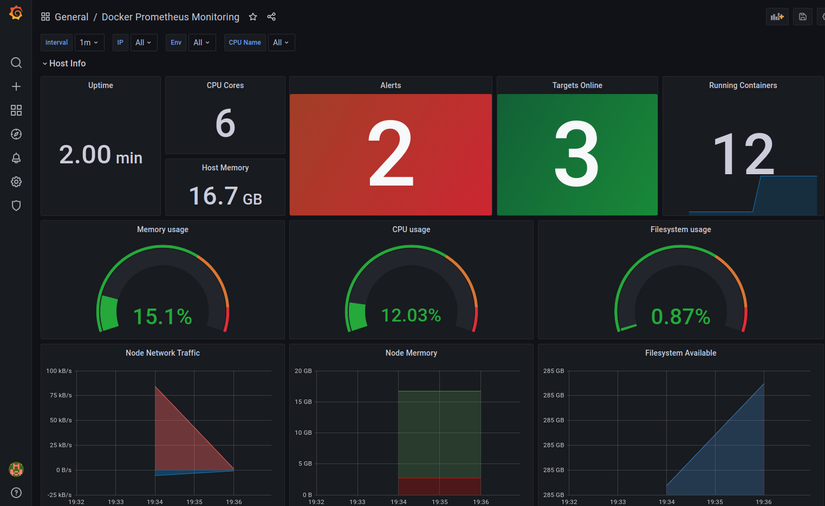
Mình không muốn mất nhiều thời gian mô tả chi tiết nhưng một cách dễ hiểu, Grafana sẽ là thằng thu thập các dữ liệu metric để nó phân tích và tạo ra dashboard mô tả trực quan các metric cần thiết cho việc monitoring ví dụ như cpu, ram, dish, network, iops, session.
Việc xây dựng Dashboard nó là một phần quan trọng trong việc monotor của hệ thống. Grafana support rất nhiều giải pháp monitor khác nhau. Nó sẽ nhận dữ liệu các queries từ Prometheus, Prometheus sẽ thu thập dữ liệu metric từ các datasource khác nhau ở Node-Exporter và Cadvisor ( tại sao lại có 2 thằng này thì tới phần giới thiệu các bạn sẽ rõ nhé  ).
).
Prometheus là gì ??
Prometheus hiện đang là một opensource được viết bằng golang, tốc độ của nó rất tốt, nó được coi là 1 datacenter tiếp nhận và xử lý các dữ liệu metric từ các datasource mình đã mô tả ở trên, ngoài ra thì còn vài tính năng rất hay ho của nó đặc biệt là Alert với plugin Alert manager
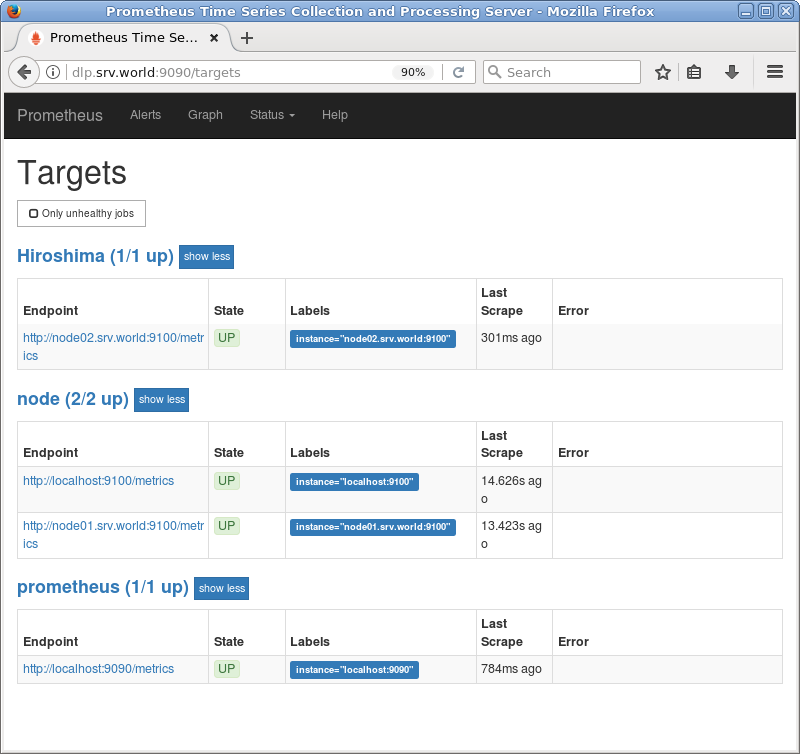
Thực ra thằng prometheus này nó cũng có UI khi chúng ta cài đặt, mặc định nó sẽ ở port 9090 như các bạn thấy ở trên, nhưng thường UI của nó không được chi tiết cho lắm nên mình mới suggest sử dụng Grafana để mình có thể thỏa sức “sáng tạo” với cái dashboard monitoring của mình
cAdvisor là gì?
cAdvisor là 1 dự án Open source của Google (nghe Google là biết hàng xịn rồi, không cần nói nhiều 😄), mục đích để phân tích mức độ sử dụng, hiệu năng, và rất nhiều thông số khác từ các ứng dụng Container, cung cấp cho người dùng cái nhìn tổng quan về toàn bộ các container đang chạy. Ok vậy thằng này sẽ là 1 datasource lấy metrics từ container tiếp đến sẽ là Node Exporter
Node Exporter là gì ???
Node Exporter cũng là một datasource nhưng nó sẽ thiên về việc lấy các dữ liệu phần cứng từ hệ thống của chúng ta hơn, như các thông số về CPU, RAMnhư các thông số về CPU, RAM.
Thằng này cũng được viết bằng Go ( lúc này Go đảm nhiệm tốc độ tốt phết =)) )
Các bạn có thể tìm thấy repo của nó ở đây https://github.com/prometheus/node_exporter
Setup Docker-compose
Ở đây mình có setup trước một file docker-compose.yml như sau. À quên để tiện theo dõi thì mình show cấu trúc folder trước, các bạn lưu ý là với cấu trúc này thì thì các bạn có thể tạo 1 repo riêng của hệ thống mình monitor hoặc để thẳng vào source của hệ thống đó cũng được nhé, ý mình là phần này nó sẽ độc lập với project của bạn
├── alertmanager
│ └── config.yml
├── docker-compose.yml
├── grafana
│ └── provisioning
│ ├── dashboards
│ │ ├── dashboard.yml
│ │ ├── Docker.json
│ │ └── Host.json
│ └── datasources
│ └── datasource.yml
└── prometheus
├── alert.rules
└── prometheus.yml
Ok phần nội dung docker-compose.yml sẽ như sau
version:"3.4"services:cadvisor:image: gcr.io/google-containers/cadvisor:latest
container_name: cadvisor
# ports:# - 8080:8080volumes:- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
prometheus:image: prom/prometheus:latest
container_name: prometheus
# ports:# - 9090:9090command:-'--config.file=/etc/prometheus/prometheus.yml'-'--storage.tsdb.path=/prometheus'volumes:- ./prometheus:/etc/prometheus
- prometheus-db:/prometheus
- ./prometheus/alert.rules:/alertmanager/alert.rules
depends_on:- cadvisor
- node-exporter
- alertmanager
node-exporter:image: prom/node-exporter
container_name: node-exporter
volumes:- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:-'--path.procfs=/host/proc'-'--path.sysfs=/host/sys'---collector.filesystem.ignored-mount-points
-"^/(sys|proc|dev|host|etc|rootfs/var/lib/docker/containers|rootfs/var/lib/docker/overlay2|rootfs/run/docker/netns|rootfs/var/lib/docker/aufs)($$|/)"# ports:# - 9100:9100restart: always
alertmanager:image: prom/alertmanager:v0.22.2
container_name: alertmanager
volumes:- ./alertmanager:/etc/alertmanager
command:-'--config.file=/etc/alertmanager/config.yml'-'--storage.path=/alertmanager'# ports:# - 9093:9093restart: unless-stopped
grafana:image: grafana/grafana
ports:- 4000:3000volumes:- grafana-db:/var/lib/grafana
- ./grafana/provisioning/:/etc/grafana/provisioning/
restart: always
user:"472"depends_on:- prometheus
volumes:grafana-db:prometheus-db:portainer-db:Ở trên mình có tất cả là 5 containers, với mỗi đoạn cấu hình thì các bạn có thể lên thẳng docs của từng cái là nó sẽ hướng dẫn các bạn setup docker-compose, ở bài này mình sẽ chỉ lưu ý vài chỗ mình customize
- Thứ nhất, các bạn thấy các phần port mình comment lại, có nghĩa đây là các công cụ có UI và khi các bạn mở port của công cụ đó ra thì chúng ta có thể truy cập vào UI của nó thông qua port, ở trên mình có nói sẽ sử dụng Grafana làm UI tổng quan nên mình sẽ không cần phải export cái port của các công cụ kia ra làm gì
- Thứ hai, ở Grafana mình có sử dụng 1 folder gọi là Provisioning , thì tại sao lại có folder này ? Folder này mình sẽ lưu trữ các thành phần gọi là Dashboard và Data Source mình đã fix sẵn ở đây. Bởi vì khi chúng ta setup grafana chúng ta sẽ cần lên UI của nó để thêm mới Dashboard ( các bạn có thể lên grafana template dashboard, và lựa chọn các dashboard mình muốn rồi lấy ID của nó để import thẳng vào ) và tiến hành add Datasource là Prometheus để xem Grafana với Prometheus đã thông chưa đó là câu chuyện setup tay, còn việc mình map thẳng folder Provisioning vào đó là bởi vì mình đã export hết các config của 2 thằng trên ra thành files, và việc của mình chỉ là docker-compose up -d là nó đã tiến hành setup hết tất cả tự động ( lưu ý với cách này thì mình không chỉnh sửa được dashboard trực tiếp trên UI Grafana nhé, các bạn sẽ cần phải export lại )
- Thứ ba, là Prometheus bản chất của nó đã có chức năng Alert rồi nhưng mình có sử dụng thêm 1 plugin đi kèm cũng của Prometheus luôn gọi là Alert Manager thằng này sẽ giúp các bạn có các tính năng thông báo phong phú hơn cũng như việc quản lý các alert dễ dàng hơn. Với nội dung ở trên thì khi các bạn up services lên thì nó đã chạy một cách ngon lành rồi, và giờ mình sẽ show config của Prometheus và Alert để xem chúng ta kết nối các services này như thế nào nhé
Prometheus config
global:scrape_interval: 1s
evaluation_interval: 15s
external_labels:monitor:'Project-technical-report'alerting:alertmanagers:-static_configs:-targets:- alertmanager:9093# Load and evaluate rules in this file every 'evaluation_interval' seconds.rule_files:-"/alertmanager/alert.rules"scrape_configs:-job_name: prometheus
scrape_interval: 5s
scrape_timeout: 2s
honor_labels:truestatic_configs:-targets:['prometheus:9090']-job_name: node-exporter
scrape_interval: 5s
scrape_timeout: 2s
honor_labels:truestatic_configs:-targets:['node-exporter:9100']-job_name: cadvisor
scrape_interval: 5s
scrape_timeout: 2s
honor_labels:truestatic_configs:-targets:['cadvisor:8080']Ở trên mình có khai báo các phần quan trọng như sau
- Alert: mình sử dụng alertmananagers và connect tới targets là alertmanager:9093 ( lưu ý là mình đang chạy các service trong 1 network của docker nên mình có thể dụng name service để dns tới container của alertmanager và tại cổng 9093 ) và các Rule alert thì ở file config /alertmanager/alert.rules
- Các Datasource sẽ được Prometheus hứng: Đầu tiên là chính nó targets prometheus:9090, Node-exporter ở target node-exporter:9100 và cadvisor ở targets cadvisor:8080
Ok phần cấu hình prometheus khá đơn giản phải không, các thuộc tính khác như Scrape interval hay timeout chỉ là các mốc thời gian nó sẽ thực hiện hứng trong vòng bao nhiêu giây một lần. Tiếp đến là các Rules ở Alert nhé
Alert Rules
groups:-name: targets
rules:-alert: monitor_service_down
expr: up == 0
for: 30s
labels:severity: critical
annotations:summary:"Monitor service non-operational"description:"Service {{ $labels.instance }} is down."-name: host
rules:-alert: HighMemoryLoad
expr: (sum(node_memory_MemTotal_bytes) - sum(node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes) ) / sum(node_memory_MemTotal_bytes) * 100 > 85
for: 2m
labels:severity: warning
annotations:summary:"Server memory is almost full"description:"Docker host memory usage is {{ humanize $value}}%. Reported by instance {{ $labels.instance }} of job {{ $labels.job }}."-name: containers
rules:-alert: PHP_FPM_Down
expr: absent(container_memory_usage_bytes{name="project-report-php-fpm"})
for: 30s
labels:severity: critical
annotations:summary:"PHP-FPM Container is Down"description:"PHP-FPM container is down for more than 30 seconds."-alert: MySQL_Down
expr: absent(container_memory_usage_bytes{name="project-report-mysql"})
for: 30s
labels:severity: critical
annotations:summary:"MySQL Container is Down"description:"MySQL container is down for more than 30 seconds."Ở trong rules mình demo chia làm 3 phần Targets, Host, Containers các bạn cũng thể định nghĩa thêm nhiều rules nhưng việc hướng dẫn cụ thể khá phức tạp vì nó liên quan tới Prometheus Queries, tuy nhiên với các bạn không biết thì chúng ta có thể tham khảo các alert rules example ở repo này https://github.com/samber/awesome-prometheus-alerts
Mình sẽ giải thích khái niệm các phần trên
- Targets: Thì các bạn có thể hình dung bộ công cụ Grafana Prometheus này nó không đơn thuần chỉ monitoring 1 server, mà nó có thể monitoring cả 1 Cluster nhiều servers bên trong, thì phần Targets này là example của 1 server con đó
- Host: Là phần monitoring các thông số của server
- Contaniers: Là phần monitoring các thông số, status của containers, các cái function như là container_memory_usage_bytes là của cAdvisor đó
Ok việc setup rules coi như xong bây giờ setup tiếp phần thông báo nhé, ở config alertmanager/config.yml
route:receiver:'chatwork'group_by:['alertname']group_wait: 15s
group_interval: 5m
repeat_interval: 3h
receivers:-name:'chatwork'webhook_configs:-url: https://cw-forwarder.sun-asterisk.vn/api/v1/webhooks/498f6b7b661c2651c
send_resolved:falsemax_alerts:3Ở đây mình sử dụng phương thức thông báo là qua webhook ( mình dùng luôn service Chatwork Forwarder cho tiện )
Để mình giải thích thêm về các mốc thời gian thông báo ở trên nhé
- group_by: Dòng này có ý nghĩa prometheus sẽ gom những thông báo có cùng
alertnamevào 1 thông báo, và chỉ gửi duy
nhất 1 thông báo mà thôi. Tất nhiên là trong 1 thông báo này sẽ có chứa những thông báo riêng lẻ. - group_wait: Sau khi một cảnh báo được taọ ra. Phải đợi khoảng thời gian này thì cảnh báo mới được gửi đi.
- group_interval: Sau khi cảnh báo đầu tiên gửi đi, phải đợi 1 khoảng thời gian được cấu hình ở đây thì các cảnh báo sau mới được gửi đi.
- repeat_interval: Sau khi cảnh báo được gửi đi thành công. Sau khoảng thời gian này, nếu vấn đề vẫn còn tồn tại,
prometheus sẽ tiếp tục gửi đi cảnh báo sau khoảng thời gian này.
Kết luận
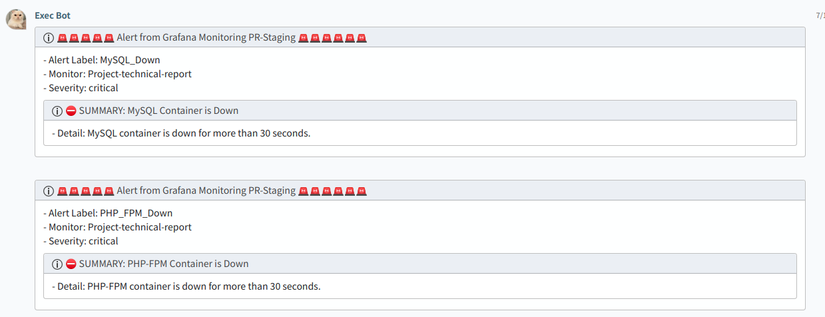
Các bạn có thể thấy việc setup nó khá phức tạp, nhưng thành quả mình thấy khá xứng đáng. Ở phần này mình sẽ đi tổng thể một lượt, ngoài ra sẽ còn các cách tiếp cận khác nếu có thời gian mình sẽ đi chi tiết vào các bài sau. Dưới đây là các tài liệu các bạn có thể tham khảo
https://grafana.com/grafana/dashboards
Nguồn: viblo.asia