Giới thiệu
Chào các bạn tới với series về kubernetes. Đây là bài thứ 15 trong series của mình, ở bài trước chúng ta đã nói về cách security cho cluster nodes và network dùng PodSecurityPolicies – NetworkPolicy, ở bài này chúng ta sẽ nói về cách quản lý và phân chia tài nguyên của cluster để application của chúng ta có thể chạy được tốt nhất.
Trong series này chúng ta cũng đã tạo khá nhiều Pod, và ta tạo những Pod đó ra mà không cần quan tâm gì tới nó sẽ cần bao nhiêu CPU, memory để chạy hoặc bị giới hạn chỉ có thể xài được bao nhiêu CPU, memory cả. Nhưng khi chạy thực tế, việc xác định tài nguyên của từng Pod rất quan trọng, nó sẽ giúp những application của chúng ta có thể đạt được hiệu suất tốt khi chạy trong cluster. Ví dụ: ta có 2 service, một thằng xử lý notify, một thằng xử lý transaction, ta sẽ không muốn service notify chạy chiếm hết tài nguyên của service xử lý transaction được, vì service transaction quan trọng hơn.
Trong bài này ta sẽ xem cách cấu hình và quản lý resouce requests và resouce limits của một Pod một cách hiệu quả nhất.
Requesting resources
Khi viết cấu hình của Pod, ta có thể thêm thuộc tính để chỉ định tổng số lượng CPU và memory của một container mà nó cần để chạy (được gọi là resouce requests), và tổng số lượng CPU và memory mà nó chỉ có thể tiêu thụ được nhiêu đó, không thể tiêu thụ vượt qua tổng số lượng ta đã chỉ định được (được gọi là resouce limits).
Ta sẽ chỉ định thuộc tính cho từng container trong Pod, và resouce requests – resouce limits của một Pod sẽ được cộng hết từ những container của nó lại.
Tạo Pod với resource requests
Giờ ta làm ví dụ để hiểu hơn, tạo một file tên là requests-pod.yaml với config như sau:
apiVersion: v1
kind: Pod
metadata:name: requests-pod
spec:containers:-name: main
image: busybox
command:["dd","if=/dev/zero","of=/dev/null"]resources:requests:cpu: 200m # The container requests 200 millicores (that is, 1/5 of a single CPU core’s time).memory: 10Mi # The container also requests 10 mebibytes of memory.Ở file trên, ta sử dụng thuộc tính resources.requests.cpu để chỉ định số lượng CPU mà container này cần, và resources.requests.memory để chỉ định số lượng memory mà container này cần. Bây giờ ta tạo Pod và kiểm tra thử cpu của nó với top command:
$ kubectl apply -f requests-pod.yaml
pod/requests-pod created
$ kubectl exec -it requests-pod top
Mem: 8006084K used, 143884K free, 214440K shrd, 74888K buff, 930220K cached
CPU: 7.6% usr 12.9% sys 0.0% nic 73.8% idle 1.1% io 0.0% irq 4.4% sirq
Load average: 3.51 2.65 1.14 8/5061 14
PID PPID USER STAT VSZ %VSZ CPU %CPU COMMAND
1 0 root R 1308 0.0 6 12.0 dd if /dev/zero of /dev/null
8 0 root R 1316 0.0 1 0.0 top
Thằng dd command chạy trong container có thể tiêu thụ bao nhiêu tài nguyên nó muốn cũng được vì ta chưa có chỉ định resources limit, ở ví dụ trên ta thấy có 6 cpu, mỗi thằng 12% là 120m, tổng là 720m.
Resource requests có ý nghĩa gì
Nếu bạn nghĩ khi ta chỉ định thuộc tính resources.requests cho container trong Pod thì thằng kubernetes sẽ giữ cho bao nhiêu đó tài nguyên của server cho container chạy thì không phải nhé.
Lưu ý một điều quan trọng là khi ta chỉ định giá trị này, như ở ví dụ trên, không phải kubernetes sẽ giữ 200m cpu và 10Mi memory của server cho container này sử dụng, mà giá trị này sẽ được sử dụng trong quá trình một Pod được schedule tới worker node. Scheduler sẽ tìm xem thằng worker node nào còn có CPU unallocated lớn hơn 200m và memory unallocated lớn hơn 10Mi để schedule Pod tới worker node đó. Nếu ta không chỉ định resources.requests, thì khi Pod được schedule tới worker node, Scheduler sẽ không xem xét giá trị CPU và memory chưa unallocated của worker node cho Pod. Nghĩa là nếu Pod ta cần 200m CPU để chạy, mà ta không chỉ định rõ, thì một worker node chỉ còn 100m CPU, Pod của ta cũng có thể được schedule tới worker node đó.
Và một điều quan trọng nữa là giá trị CPU và memory unallocated sẽ được Scheduler tính ra bằng cách lấy resources của node trừ đi cho tổng toàn bộ resources.requests của Pod (nếu có, hoặc nếu cpu hiện tại của pod nếu không có chỉ định resources requests, hoặc cpu hiện tại lớn hơn resources requests do ta không sử dụng limit, thì Scheduler sẽ lấy giá trị lớn hơn đó) trên một worker node lại, chứ không phải là giá trị CPU và memory còn free chưa xài của worker node. Kể cả khi giá trị free của worker node có đáp ứng được Pod requests mà giá trị unallocated không đáp ứng được thì Pod cũng sẽ không được schedule tới đó.
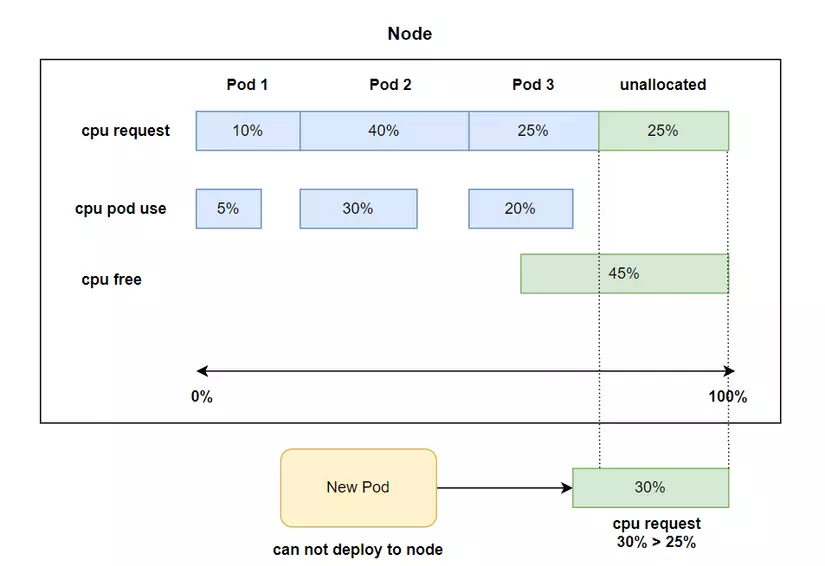
Ở hình minh họa trên, Pod sẽ không được deploy tới worker node do cpu request hiện tại lớn hơn cpu unallocated còn lại của worker node, mặc dù cpu free thực tế còn tới 45%. Scheduler sẽ không xem xét cpu free thực tế mà chỉ xem xét tới cpu unallocated.
Cách Scheduler sử dụng resource requests để chọn node tốt nhất cho Pod
Ở bài bài Kubernetes internals architecture, ta có nói về cách Scheduler sẽ lọc ra những node tốt nhất bằng thuật toán rồi sắp xếp theo thứ tự ưu để chọn ra được node có thứ tự ưu tiên cao nhất. Thì trong đó, resource requests sẽ được sử dụng như một tiêu chí để đánh giá thứ tự ưu tiên cho node, có hai phương thức là: LeastRequestedPriority, MostRequestedPriority.
- LeastRequestedPriorit: sẽ chọn node có tổng resource request là ít nhất, nghĩa là resource unallocated là nhiều nhất.
- MostRequestedPriority: sẽ chọn node có tổng resource request là cao nhất, nghĩa là resource unallocated là ít nhất.
Scheduler sẽ được config để chọn một trong hai phương thức trên, mặc định phương thức được sử dụng là LeastRequestedPriorit. Ta có thể config Scheduler để xài phương thức MostRequestedPriority thay thế, xài MostRequestedPriority khi ta muốn resoucre của chúng ta được sử dụng đều nhất có thể, rất quan trọng trên môi trường cloud provider, ta sẽ muốn sử dụng ít VM nhất có thể để giảm chi phí.
Scheduler in action
Giờ ta sẽ tạo thêm pod để xem Scheduler có thực hiện đúng như cách ta nói ở trên không. Đầu tiên ta sẽ xem capacity của node.
$ kubectl describe node
...
Capacity:
cpu: 8
ephemeral-storage: 263174212Ki
hugepages-2Mi: 0
memory: 8149968Ki
pods: 110
Allocatable:
cpu: 8
ephemeral-storage: 242541353378
hugepages-2Mi: 0
memory: 8047568Ki
pods: 110
...
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests
-------- --------
cpu 3475m (43%)
memory 6978796928 (84%)
...
Có 2 thuộc tính quan trọng ta cần chú ý là Capacity và Allocatable, với Capacity là tổng tài nguyên của worker node, và Allocatable là tài nguyên mà Pod có thể xài. Ta sẽ thấy nó không bằng nhau vì sẽ có một ít tài nguyên để system sử dụng. Ta không nên xài hết. Ta có cpu allocatable là 8 core = 8000m, và cpu allocated là 3475m. Ta sẽ tạo một Pod mà request 3000m xem cpu allocated của ta có tăng lên không.
$ kubectl run requests-pod-2 --image=busybox --restart Never --requests='cpu=3000m,memory=20Mi' -- dd if=/dev/zero of=/dev/null
pod/requests-pod-2 created
Nếu bạn chạy kubelet version lớn hơn 1.21 thì sẽ có thông báo như sau:
Flag --requests has been deprecated, has no effect and will be removed in the future.
Nếu gặp lỗi này thì thì bạn tạo file config chứ đừng dùng cli nhé. Giờ ta describe node lại:
$ kubectl describe node
...
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests
-------- --------
cpu 6475m (80%)
memory 6999768448 (84%)
...
Ta sẽ thấy lúc này cpu allocated của ta đã lên 6475m, nếu ta tạo thêm một Pod mà có request là 3000m nữa thì Pod của ta sẽ không thể deploy lên node được.
$ kubectl run requests-pod-3 --image=busybox --restart Never --requests='cpu=3000m,memory=20Mi' -- dd if=/dev/zero of=/dev/null
pod/requests-pod-3 created
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
requests-pod-2 1/1 Running 0 6m10s
requests-pod-3 0/1 Pending 0 44s
Pod requests-pod-3 của ta sẽ ở trạng thái pending vì nó không được deploy tới pod, khi ta describe pod, ta sẽ thấy lý do là không có worker node nào có đủ cpu cho Pod:
$ kubectl describe pod requests-pod-3
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 55s (x3 over 2m2s) default-scheduler 0/1 nodes are available: 1 Insufficient cpu.
Limiting resources
Ta đã hiểu cách sử dụng resources request, bây giờ ta sẽ xem cách dùng resources limit, để tránh một Pod sẽ chiếm tài nguyên của các Pod khác. Tạo một file tên là limited-pod.yaml với config như sau:
apiVersion: v1
kind: Pod
metadata:name: limits-pod
spec:containers:-name: main
image: busybox
command:["dd","if=/dev/zero","of=/dev/null"]resources:limits:cpu: 1000m # The container limits 1 cpu core.memory: 20Mi # The container limits 20 mebibytes of memory.Ở file config trên ta dùng thuộc tính resources.limits để chỉ định limits resources của một container, nếu ta không chỉ định thuộc tính request, thì mặc định nó sẽ được chỉ định bằng với giá trị của limits. Tạo file và kiểm tra thử:
$ kubectl apply -f limited-pod.yaml
pod/limits-pod created
$ kubectl exec -it limits-pod top
Mem: 7462364K used, 687604K free, 174260K shrd, 151972K buff, 1245064K cached
CPU: 6.7% usr 10.8% sys 0.0% nic 78.0% idle 0.4% io 0.0% irq 3.9% sirq
Load average: 2.10 1.31 1.30 4/4106 13
PID PPID USER STAT VSZ %VSZ CPU %CPU COMMAND
1 0 root R 1308 0.0 1 12.1 dd if /dev/zero of /dev/null
7 0 root R 1316 0.0 4 0.0 top
Ta sẽ thấy là ở trên khi ta chưa chỉ định limit, cpu core ta có thể xài là 6, sau khi ta chỉ định, cpu core ta có thể xài bây giờ chỉ có 1.
Khi một container vượt quá limit
Vậy chuyện gì xảy ra khi một container của chúng ta sử dụng tài nguyên vượt qua tài nguyên limit ta đã chỉ định. Thì sẽ có hai trường hợp:
- Đối với cpu, khi container của chúng ta cần quá số lượng cpu chúng ta đã chỉ định ở limit, thì nó không thể không thể xài quá cpu này được, nó chỉ được xài tới cpu mà ta đã chỉ định.
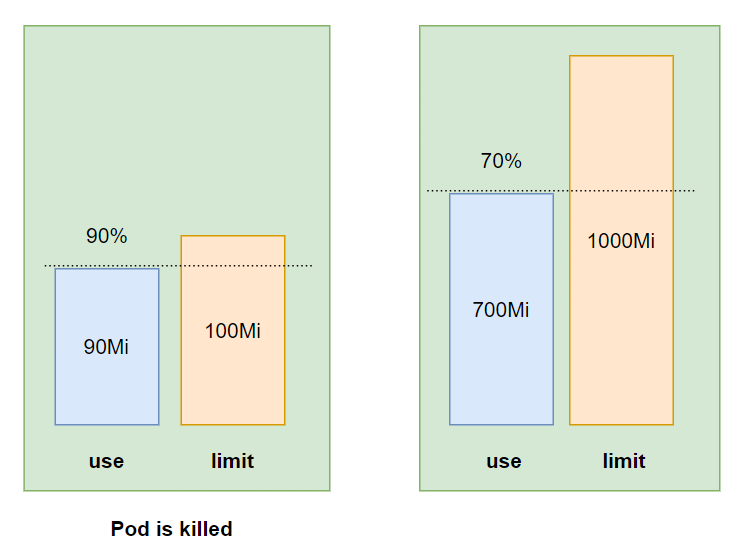
- Đối memory thì sẽ khác, khi container của chúng ta xài quá limit được cho phép, container này sẽ bị kill đi, nếu ta có chỉ định restartPolicy đã nói ở bài 12 là Always hoặc OnFailure, thì container của ta sẽ tự động restart lại.
QoS classes
Khác với cpu limit, tổng số memory limit của ta khi config có thể vượt quá 100% memory của worker node. Vậy thì chuyện gì sẽ xảy ra nếu có một Pod chạy quá memory của worker node, thằng Pod đó sẽ bị kill đi hay là một thằng khác sẽ bị kill đi?
Ví dụ ta có hai Pod, một thằng A với limit 550Mi memory, một thằng B với limit 600Mi memory, worker node của ta memory chỉ có 1G RAM. Bây giờ thằng A đang chạy chiếm là 500Mi, thằng B đang chạy chiếm 400Mi, sau đó thằng B chạy chiếm memory lên tới 550Mi, hai thằng cộng lại là 1050Mi, vượt quá memory của worker node, trong khi không thằng nào chạy vượt quá limit của nó hết, vậy thằng nào sẽ bị kill đi?
Thì kubernetes có cung cấp cho ta cách để đánh độ ưu tiên của Pod, Pod nào có độ ưu tiên thấp hơn sẽ bị kill đi trước. Quality of Service (QoS) là cách để kubernetes phân độ ưu tiên của Pod, có 3 QoS là:
- BestEffort (độ ưu tiên thấp nhất)
- Burstable
- Guaranteed (độ ưu tiên cao nhất)
QoS sẽ được gán cho container, sau đó kết hợp toàn bộ QoS của container ta sẽ có được QoS của Pod.
Xác định QoS của container
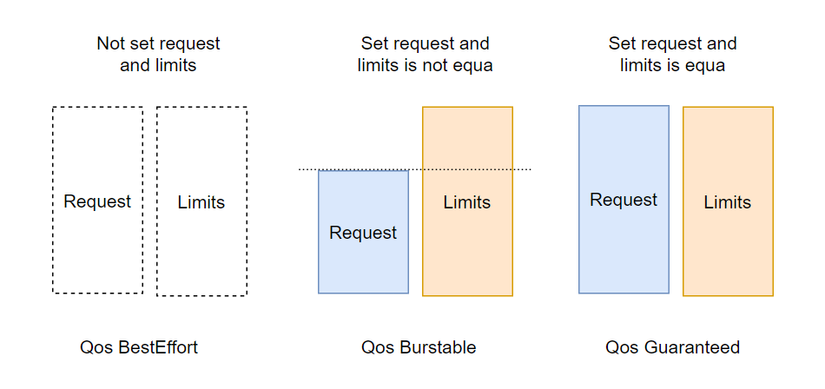
BestEffort là container với độ ưu tiên thấp nhất, QoS class này sẽ được gán cho container mà không có chỉ định thuộc tính resources requests và limits. Nếu memory của worker node vượt quá 100%, Pod với class BestEffort sẽ bị kill đầu tiên.
Burstable là container có độ ưu tiên trung bình, QoS class này sẽ được gán cho container mà chỉ định mỗi resources requests, hoặc chỉ định mà giá trị của hai thuộc tính resources requests và limits không bằng nhau, Pod với class Burstable sẽ bị kill khi không còn Pod nào với class BestEffort tồn tại.
Guaranteed là container có độ ưu tiên cao nhất, bị kill cuối cùng, QoS class này sẽ được gán cho Pod mà:
- Chỉ định cả hai thuộc resources requests và limits trong container. Hoặc chỉ định mỗi resources limits, resources requests sẽ mặc định lấy giá trị của resources limits.
- Hai thuộc tính này giá trị phải bằng nhau.
Xác định QoS của Pod
Nếu tất cả các container đều cùng QoS class, thì QoS đó sẽ là QoS của Pod, nếu không, thì QoS sẽ được gộp lại theo bảng sau:
| Container 1 QoS class | Container 2 QoS class | Pod’s QoS class |
|---|---|---|
| BestEffort | BestEffort | BestEffort |
| BestEffort | Burstable | Burstable |
| BestEffort | Guaranteed | Burstable |
| Burstable | Burstable | Burstable |
| Burstable | Guaranteed | Burstable |
| Guaranteed | Guaranteed | Guaranteed |
Hiểu cách Pod bị kill khi memory vượt quá giới hạn của worker node
Như ta đã nói ở trên, khi memory của worker node vượt quá 100%, Pod với Qos là BestEffort sẽ bị kill trước, tiếp đó là Pod với Qos là Burstable, và cuối cùng là thằng Guaranteed.
Cách Pod cùng QoS sẽ bị kill
Mỗi thằng process của chúng ta sẽ có một OutOfMemory (OOM) score. Khi Pod với cùng QoS class thì thằng nào có process với OOM cao hơn sẽ bị kill đi trước. OOM score sẽ được tính bằng số memory request và số memory process đang sử dụng hiện tại, thằng nào đang xài % memory với request cao hơn sẽ bị kill đi trước.
Cấu hình request và limit mặc định cho namespace
Ta đã biết được cách sử dụng requests và limits, bằng cách chỉ định thuộc tính cho từng container nhất định. Nếu ta không chỉ định thì Pod sẽ xài bao nhiêu nó muốn, nên tốt là ta nên có cách cấu hình requests và limits bằng một giá trị mặc định cho một container khi ta không chỉ định requests và limits của nó.
LimitRange resource
Thay vì phải cấu hình cho từng container riêng biệt, ta có thể tạo một resource tên là LimitRange, để chỉ định requests và limits mặc định trong một namespace giùm chúng ta.
LimitRange sẽ có hai công dụng, chỉ định minimum và maximum của requests và limits, và giá trị mặc định khi ta không chỉ định thuộc tính trong container.
Khi ta tạo LimitRange thì nó sẽ được config bên trong Admission control plugin mà ta đã nói ở bài 11.
Tạo LimitRange
Giờ ta sẽ tạo một LimitRange resouce, tạo một file tên là limits.yaml với config như sau:
apiVersion: v1
kind: LimitRange
metadata:name: example
spec:limits:-type: Pod
min:cpu: 50m
memory: 5Mi
max:cpu:1memory: 1Gi
-type: Container
defaultRequest:cpu: 100m
memory: 10Mi
default:cpu: 200m
memory: 100Mi
min:cpu: 50m
memory: 5Mi
max:cpu:1memory: 1Gi
maxLimitRequestRatio:cpu:4memory:10-type: PersistentVolumeClaim
min:storage: 1Gi
max:storage: 10Gi
Ở file config trên, ta chỉ định limit cho 3 thành phần là Pod, Container, PersistentVolumeClaim. Ta chỉ định minimun cpu của Pod là 50m và memory là 5Mi, maximun là 1 cpu và 1Gi memory. Đối với container, ta chỉ định giá trị mặc định của của request bằng thuộc tính defaultRequest và mặc định của limit bằng thuộc tính default, và thuộc tính max và min tương tự như của Pod. Ta cũng có thể chỉ định giá trị cho storage với type là PersistentVolumeClaim.
Ta tạo và kiểm tra thử LimitRange có làm việc đúng như ta muốn hay không.
$ kubectl apply -f limits.yaml
limitrange/example created
$ kubectl run requests-pod-big-cpu --image=busybox --requests='cpu=3'
The Pod "requests-pod-big-cpu" is invalid: spec.containers[0].resources.requests: Invalid value: "3": must be less than or equal to cpu limit
Nếu nó in ra lỗi này thì LimitRange của ta đã làm việc chính xác, ta chỉ cho phép maximun cpu request là 1 core, ở trên ta request 3 core nên không thể tạo được Pod.
Ta kiểm tra và thấy LimitRange đã thực hiện đúng việc validate min và max của một Pod có thể được tạo. Giờ ta kiểm tra nó có chỉ định giá trị requests và limits mặc định cho ta không.
$ kubectl run pod-no-setting-resoucre --image=busybox --restart Never -- dd if=/dev/zero of=/dev/null
pod/pod-no-setting-resoucre created
$ kubectl describe pod pod-no-setting-resoucre
Name: pod-no-setting-resoucre
Namespace: default
...
Containers:
pod-no-setting-resoucre:
Container ID: docker://9add62820682c8ef4cae6e647b3180b396118cfdfdaac857f3fd396b686e10b2
Image: busybox
...
Limits:
cpu: 200m
memory: 100Mi
Requests:
cpu: 100m
memory: 10Mi
...
Kiểm tra terrminal và ta sẽ thấy container của chúng ta đã được chỉ định giá trị requests và limits mặc định. LimitRange đã hoạt động giống như ta muốn.
Giới hạn tổng số lượng tài nguyên của một namespace
Ta đã thấy được sự tiện lợi khi ta sử dụng thằng LimitRange. Nhưng các bạn có thể để ý là thằng LimitRange chỉ giới hạn tài nguyên của một đối tượng trong namespace, chứ không thể giới hạn tổng tài nguyên có thể sử dụng của một namespace được. Khi làm dự án với nhiều team khác nhau, ta sẽ muốn từng team chỉ có thể sử dụng được số lượng tài nguyên mà ta chỉ định cho họ, team này không nên xài chiếm tài nguyên của team khác. Để làm được việc đó, kubernetes có cung cấp cho chúng ta một resource tên là ResourceQuota.
ResourceQuota
Đây là resource sẽ giúp ta giới hạn tài nguyên của một namespace, khi ta tạo một ResourceQuota resource, nó sẽ được config ở Admission Control plugin giống như LimitRange, khi một Pod được tạo, nó phải qua plugin này để kiểm tra Pod đó có sử dụng quá giới hạn tài nguyên mà ta đã chỉ định trong ResourceQuota hay không, nếu có, API server sẽ trả về lỗi.
ResourceQuota không chỉ giới hạn tài nguyên sử dụng của Pod và storage của PersistentVolumeClaims, mà còn có thể giới hạn số lượng Pod, PersistentVolumeClaims có thể được tạo trong một namespace.
ResourceQuota giới hạn cpu và memory
Giờ ta sẽ xem qua ví dụ để dễ hiểu hơn, tạo một file tên là quota-cpu-memory.yaml với config như sau:
apiVersion: v1
kind: ResourceQuota
metadata:name: cpu-and-mem
namespace: default
spec:hard:requests.cpu: 400m
requests.memory: 200Mi
limits.cpu: 600m
limits.memory: 500Mi
Ở file config trên, ta giới sẽ chỉ định tổng tài nguyên request của namespace default là 400m cpu và 200Mi memory, khi ta tạo Pod ta không thể chỉ định request lớn hơn số này được, và tổng tài nguyên nó bị giới hạn sử dụng là 600m cpu và 500Mi memory. Khi ta tạo ResourceQuota này, thì toàn bộ các Pod trong namespace chỉ có thể xài tối đa tài nguyên là 600m cpu và 500Mi memory. Ví dụ ta có cần tạo Pod với request là 200m cpu, thì ta chỉ có thể tạo tối đa 3 Pod ở trong namespace default.
Sau khi ta tạo resource, ta có thể xem bao nhiêu resource đã được sử bên trong quota rồi bằng câu lệnh describe:
$ kubectl apply -f quota-cpu-memory.yaml
resourcequota/cpu-and-mem created
$ kubectl describe quota cpu-and-mem
Name: cpu-and-mem
Namespace: default
Resource Used Hard
-------- ---- ----
limits.cpu 0 600m
limits.memory 0 500Mi
requests.cpu 0 400m
requests.memory 0 200Mi
Nếu ta xóa hết các Pod đã tạo ở trên đi, thì ta sẽ thấy cả 4 thông số đều là 0, giờ ta sẽ tạo một Pod và kiểm tra thử xem số này có tăng lên không:
$ kubectl run quota-pod --image=busybox --restart Never --limits='cpu=300m,memory=200Mi' -- dd if=/dev/zero of=/dev/null
pod/quota-pod created
$ kubectl describe quota cpu-and-mem
Name: cpu-and-mem
Namespace: default
Resource Used Hard
-------- ---- ----
limits.cpu 300m 600m
limits.memory 200Mi 500Mi
requests.cpu 300m 400m
requests.memory 200Mi 200Mi
Ta thấy giá trị ở đây đã tăng lên đúng như ta muốn, giờ ta sẽ tạo một Pod mà request 400m cpu, lúc này nó sẽ báo lỗi:
$ kubectl run quota-pod-1 --image=busybox --restart Never --limits='cpu=400m,memory=200Mi' -- dd if=/dev/zero of=/dev/null
Error from server (Forbidden): pods "quota-pod-1" is forbidden: exceeded quota: cpu-and-mem, requested: limits.cpu=400m,requests.cpu=400m,requests.memory=200Mi, used: limits.cpu=300m,requests.cpu=300m,requests.memory=200Mi, limited: limits.cpu=600m,requests.cpu=400m,requests.memory=200Mi
Bạn sẽ thấy lỗi là pods “quota-pod-1” is forbidden: exceeded quota: cpu-and-mem, nghĩa là Pod quota-pod-1 vượt quá giới hạn của ResourceQuota ta cho phép hiện tại, nên Pod không được tạo ra.
ResourceQuota giới hạn persistent storage
Để giới hạn persistent storage của một namespace, ta tạo file với config như sau:
apiVersion: v1
kind: ResourceQuota
metadata:name: storage
spec:hard:requests.storage: 500Gi
ssd.storageclass.storage.k8s.io/requests.storage: 200Gi
standard.storageclass.storage.k8s.io/requests.storage: 300Gi
Ở file config trên, ta giới hạn của request cho toàn bộ PersistentVolumeClaims trong namespace default là 500Gi, ta cũng có thể chỉ định rõ giới hạn request cho từng StorageClass cụ thể, bằng cách prefix tên StorageClass như sau <storageclass-name>.storageclass.storage.k8s.io/requests.storage.
ResourceQuota giới hạn số lượng resource có thể tạo
Bên cạnh giới hạn tài nguyên và storage, ta cũng có thể dùng ResourceQuota để chỉ định số lượng resource object ta có thể tạo trong một namespace, ví dụ như sau:
apiVersion: v1
kind: ResourceQuota
metadata:name: objects
spec:hard:pods:10replicationcontrollers:5secrets:10configmaps:10persistentvolumeclaims:4services:5services.loadbalancers:1services.nodeports:2Ở file config trên, ta giới hạn số lượng pod có thể tạo trong default namespace là 10, replicationcontrollers là 5, secrets là 10, v…v… Những resource mà ResourceQuota có thể chỉ định là:
- Pods
- ReplicationControllers
- Secrets
- ConfigMaps
- PersistentVolumeClaims
- Services: có thể chỉ định rõ số lượng LoadBalancer Services và NodePort Services
Quota scope cho Pod
Đối với Pod, ta có thể chỉ định Quota có được áp dụng với tới nó hay không dựa vào 4 thuộc tính sau đây:
- BestEffort: chỉ ảnh hưởng tới Pod với Qos class là BestEffort
- NotBestEffort: chỉ ảnh hưởng tới Pod với Qos class là Burstable và Guaranteed
- Terminating: chỉ ảnh hưởng tới Pod có thuộc tính activeDeadlineSeconds
- NotTerminating: chỉ ảnh hưởng tới Pod không có thuộc tính activeDeadlineSeconds
Ví dụ như sau:
apiVersion: v1
kind: ResourceQuota
metadata:name: besteffort-notterminating-pods
spec:scopes:- BestEffort
- NotTerminating
hard:pods:4Ở file config trên, ta chỉ có thể tạo 4 pod với Qos class là BestEffort và không có chỉ định thuộc tính active deadline.
Kết luận
Vậy là ta đã tìm hiểu xong về cách cấu hình requests và limits cho Pod. Khi chạy một ứng dụng thực tế trên kubernetes cluster, ta cần phải quan tâm chỉ số này cho kĩ, để giúp ứng dụng ta chạy tốt nhất có thể. Ta cũng đã biết cách xài LimitRange để cấu hình requests và limits mặc định cho Pod, sử dụng LimitRange sẽ tiện hơn khi ta muốn toàn bộ container trong Pod của ta phải có requests và limits. Dùng ResourceQuota để giới hạn tài nguyên cho một namespace, chia tài nguyên cho từng team một cách hợp lý. Nếu có thắc mắc hoặc cần giải thích rõ thêm chỗ nào thì các bạn có thể hỏi dưới phần comment. Ở bài tiếp theo ta sẽ nói về một vấn đề khá thú vị là auto scaling pod và cluster node.
Nguồn: viblo.asia