Xin chào các bạn, hôm nay mình sẽ chia sẻ một bài viết về chủ đề làm sạch dữ liệu, như mọi người cũng biết bước làm sạch dữ liệu cực kì quan trọng trước khi đưa vào phân tích dữ liệu hoặc huấn luyện mô hình. Mình tình cờ đọc được bài viết sử dụng thư viện có sẵn để làm sạch dữ liệu và mình thấy nó khá là hay và còn rút ngắn được thời gian làm sạch dữ liệu. Bây giờ chúng ta cùng nhau tìm hiểu nhé.
Pyjanitor
Pyjanitor là một triển khai của gói Janitor R để làm sạch dữ liệu bằng các phương pháp chuỗi trên môi trường Python. Pyjanitor dễ sử dụng với một API trực quan được kết nối trực tiếp với Pandas. Trên thực tế, chúng ta cũng đều biết pandas cung cấp rất nhiều tính năng làm sạch dữ liệu hữu ích như, dropna() để giảm giá trị null và todummies để mã hóa phân lọai. Pyjanitor nâng cao tính năng đó của Pandas như thế nào mình cùng xem nhé..
Import and Install
Để sử dụng được Pyjanitor chúng ta tiến hành cài đặt và gọi đến Pyjanitor:
pip install pyjanitor
import và check version
import janitor
janitor.__version__!
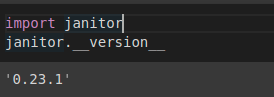
Hình: pyjanitor version
Ở đây mình dùng pyjanitor version 0.23.1. Tiếp theo chúng ta sẽ dùng thử package này xem như thế nào nhé. Đầu tiên mình sẽ tạo data sau đó sẽ thử với pandas và janitor
stocks = {"CompanyName":["Roku","Google",pd.NA],
"DATE":["20202912","20202912",pd.NA],
"STOCK Price":["300","1700",pd.NA],
"DIvidend":[pd.NA,pd.NA,pd.NA]}
Convert data sang dạng dataFrame :
stocks_df = pd.DataFrame.from_dict(stocks)
stocks_df
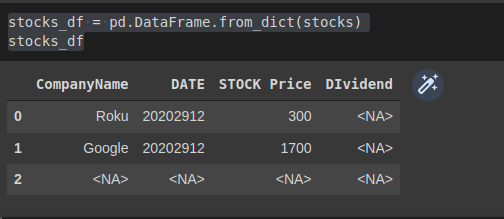
Hình 2: dataframe
làm sạch dữ liệu với Pandas:
# Delete a column from the DataFrame. Say 'DIvidend'
del stocks_df['DIvidend']
# Drop rows that have empty values in columns
stocks_df = stocks_df.dropna(subset=['DATE', 'STOCK Price'])
Hoặc sử dụng với api
stocks_df = (
pd.DataFrame(stocks)
.drop(columns="DIvidend")
.dropna(subset=['DATE', 'STOCK Price'])
)
Kết quả của cả 2 cách trên sẽ được như dưới đây
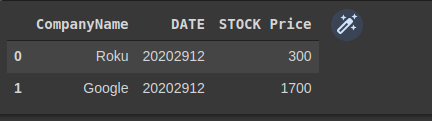
Hình: kết quả với pandas
Bây giờ chúng ta sẽ thực hành với pyjanitor
stocks_df.clean_names().remove_empty()
Kết quả như sau:
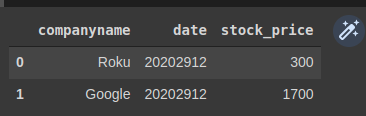
Hình: pyjanitor
Đổi tên columns trong pyjanitor, ở đây mình đổi companyname thành company:
(stocks_df
.clean_names()
.remove_empty()
.rename_column('companyname',"company"))
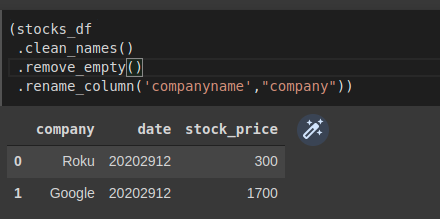
Hình: đổi tên columns
Pyjanitor sử dụng api của pandas nên mình thấy nó khá tương tương nhau, nhưng mình thấy pyjanitor code sẽ gọn hơn và nhanh hơn.
Klib
Với Klib chúng ta có thể làm sạch dữ liệu một cách nhanh chóng và rất dễ áp dụng với giá trị mặc định hợp lý có thể được sử dụng trên hầu hết DataFrame, bên cạnh đó còn có thể lấy được thông tin chi tiết của dữ liệu và trực quan hóa dữ liệu.
Đầu tiên mình sẽ sử dụng với data stocks_df như ở trên để làm sạch dữ liệu nhé:
# install klib
!pip install -U klib
# import klib
import klib
# clean stocks_data
klib.data_cleaning(stocks_df)
Code clean đơn giản đúng không ạ. chúng ta cùng xem kết quả nhé:
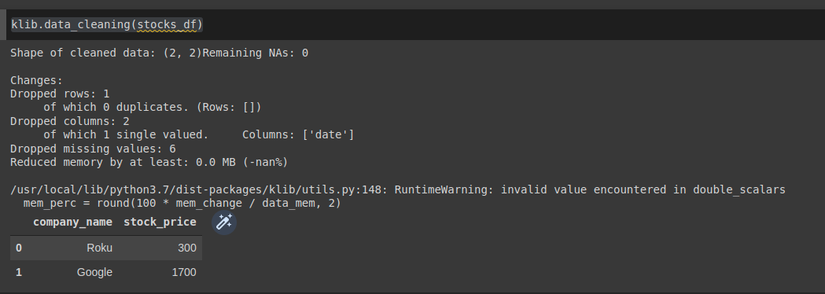
Hình: clean dữ liệu với Klib
Ở hình trên chúng ta còn thấy thông xin số columns bị drop , số lượng missing values bị drop nữa.
Tiếp theo chúng ta sử dụng thêm một số tính năng của gói Klib này nha, mình sẽ sử dụng data này nhé
Đầu tiên sẽ đọc dữ liệu ở trên đã nhé:
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/akanz1/klib/main/examples/NFL_DATASET.csv

Hình: NFL dataset
Plot missing value:
klib.missingval_plot(df)

Hình: plot missing value
Dựa vào hình này chúng ta có thể thấy được data này rất nhiều dữ liệu missing, vì vậy chúng ta cần clean dữ liệu luôn.
df_cleaned = klib.data_cleaning(df)
Kết quả:
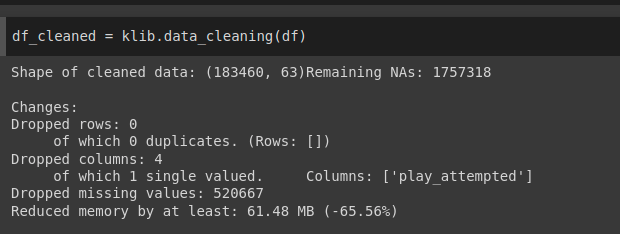
Hình: clean dữ liệu
Chúng ta cũng có thể vẽ biểu đồ Correlation:
klib.corr_plot(df_cleaned, annot=False, figsize=(15,12))
klib.corr_plot(df_cleaned, split='pos', annot=False, figsize=(15,12))
klib.corr_plot(df_cleaned, split='neg', annot=False, figsize=(15,12))
Với Klib chúng ta có thể làm rất nhiều việc vừa dễ dàng vừa nhanh chóng.
DataPrep
DataPrep dùng để: làm sạch dữ liệu, phân tích dữ liệu và thu thập dữ liệu. Tuy nhiên trong bài này chúng ta chỉ đề cập đến vấn đề làm sạch dữ liệu thôi.
# install
pip install dataprep
Ở đây mình cũng sử dụng dữ liệu titanic nha mn
from dataprep.datasets import load_dataset
from dataprep.eda import create_report
df = load_dataset("titanic")
df.head()
Với dataprep chúng ta có thể xuất ra 1 report hoàn chỉnh như sau:
create_report(df).show_browser()
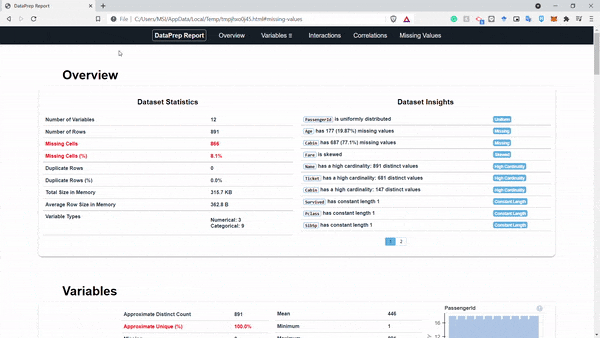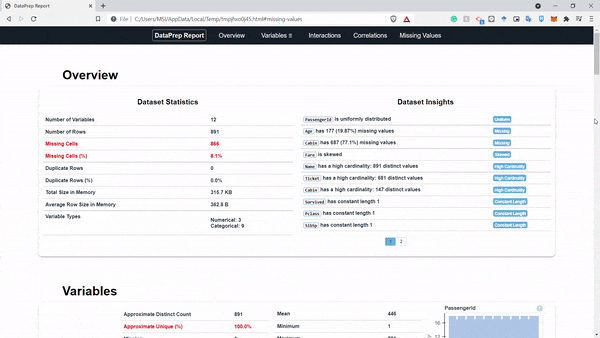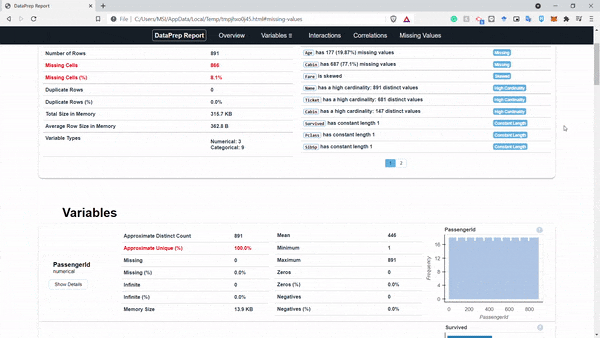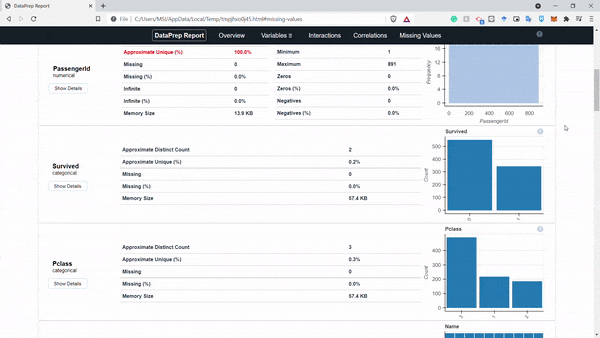
Hình: report
Như ở hình trên chúng ta có thể thấy một báo cáo hoàn chỉnh và chúng ta có thể tương tác trực tiếp trên báo cáo này luôn. Phân tích dữ liệu game là dễ =))) mình đùa thôi nhưng package này đúng là support tận răng luôn á. Tiếp theo chúng ta sẽ thử xem tính răng clean_headers của package dataprep này nhé:
from dataprep.clean import clean_headers
clean_headers(df, case = 'const').head()
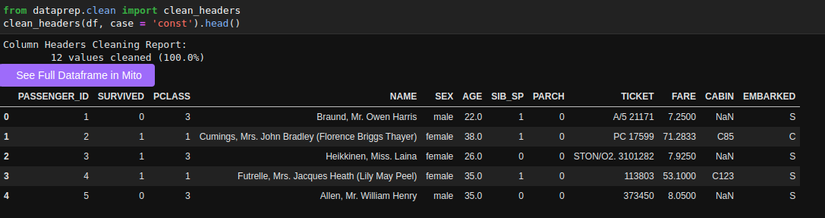
Hình: clean_headers
Và khi chúng ta muốn chuyển tên cột thành chữ thường thay vì chữ in hoa.
clean_headers(df, case = 'camel').head()
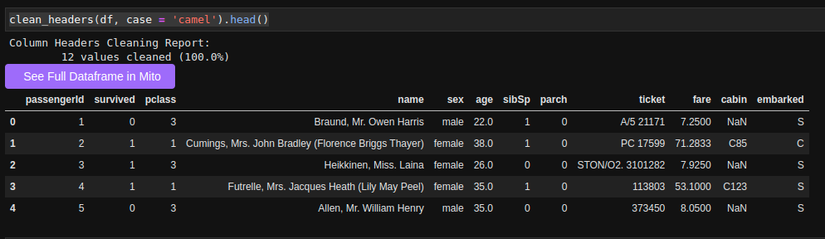
Hình: clean_headers với tên columns là chữ thường
Khi muốn có một DataFrame sạch hoàn chỉnh, chúng ta có thể sử dụng API clean_df từ DataPrep. API này sẽ có hai đầu ra – kiểu dữ liệu và DataFrame đã được làm sạch.
from dataprep.clean import clean_df
inferred_dtypes, cleaned_df = clean_df(df)
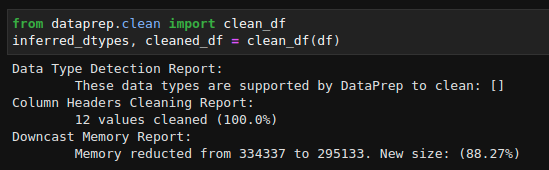
Hình: làm sạch toàn bộ dữ liệu
Bên cạnh việc phân tích dữ liệu gói dataprep còn cung cấp thêm tính năng thu thập dữ liệu nữa các bạn cùng tìm hiểu ở đây nhé.
scrubadub
Scrubadub là một gói Python mã nguồn mở để xóa thông tin nhận dạng cá nhân khỏi dữ liệu văn bản. Scrubadub hoạt động bằng cách xóa dữ liệu cá nhân được phát hiện và thay thế nó bằng một số nhận dạng văn bản như {{EMAIL}} hoặc {{NAME}}.
Đầu tiên chúng ta cùng cài đặt scrubadub
!pip install scrubadub
import scrubadub
text = "My cat can be contacted on [email protected], or 1800 555-5555"
scrubadub.clean(text)
Kết quả:

Hình: kết qủa
Kết Luận
Ở bài viết này mình đã sử dụng một số package để làm sạch dữ liệu giúp cho công việc làm sạch dữ liệu thuận tiện, nhanh chóng và đơn giản hơn. Cảm ơn mọi người đã đọc bài viết của mình, mong nhận được sự góp ý của mọi người.
Reference
https://github.com/pyjanitor-devs/pyjanitor
https://cmdlinetips.com/2021/01/introduction-to-data-cleaning-with-pyjanitor/
https://towardsdatascience.com/clean-connect-and-visualize-interactively-with-dataprep-9c4bcd071ea9
Nguồn: viblo.asia