Mục tiêu: Cải thiện tìm kiếm trong database (DB) hay nói cách khác là làm sao để tìm kiếm trong database cho nó thông minh hơn.
Ghi chú: Mình sử dụng postgresql 12 cho bài viết này. Với các loại Structured Query Language(SQL) DB khác mình nghĩ sẽ tương tự. Các bạn có thể chạy example trên loại DB khác để test.
Giới thiệu
Đa số nói đến tìm kiếm trong DB thì mọi nguời sẽ sử dụng từ khoá LIKE để so sánh giữa hai chuỗi (string), nhưng nếu để ý kĩ hơn thì có nhiều vấn đề mà cách thông thương này không giải quyết được. Mình sẽ đưa ra từng vấn đề và cách mình đang xử lý chúng. Tất nhiên sẽ có nhiều cách khác nhau, các bạn comment giúp mình nhé ~.
Mình sẽ đưa ra ví dụ dựa trên dữ liệu sản phẩm của một trang website bán hàng. Bảng dữ liệu gồm có 2 cột ID và Tittle . Mình cũng sẽ thêm 1 ít dữ liệu để cho trực quan hơn.
CREATETABLE product (
id serialNOTNULL,
title TEXTNOTNULL,CONSTRAINT product_pkey PRIMARYKEY(id));INSERTINTO product (title)VALUES('Main B360 Msi B360-F Pro LGA1151'),('Main B360 Msi B360 A Pro LGA1151'),('Mainboard B360M Pro VH LGA1151 2*DDR4'),('Mainboard B360M MORTAR TITANIUM LGA1151 4*DDR4'),('Main Msi B360M Mortar LGA1151 4*DDR4'),('Main B360-F Pro LGA1151 2*DDR4'),('Mainboard Msi B360 A Pro LGA1151 4*DDR4'),('Mainboard Msi B360M Mortar LGA1151 4*DDR4'),('Mainboard B360M Bazooka LGA1151 4*DDR4'),('Mainboard Msi B360M PRO-VD LGA1151 4*DDR4');Nội dung
Tìm kiếm bằng So sánh 2 chuỗi
Cách đơn giản nhất để tìm kiếm là SELECT column_name FROM table WHERE column_name LIKE 'key_word'. Bạn cũng có thể cải thiện thêm phạm vi tìm kiếm bằng cách thêm các kí tự đặc biệt như:
Main%: để tìm tất cả các ký nào bắt đầu bằng chữ Main. Hoặc%board%bất kì giá trị nào có chữ board. Ví dụ:SELECT * FROM product WHERE title LIKE '%board%';
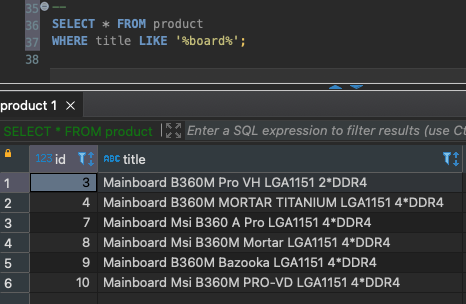
_xy: để tìm giá trị bắt đầu với ít nhất 1 ký tự bất kì. Ví dụ:axy,$xy,xy. Các giá trị không hợp lệ như:xy,a xy,bxyz. Nếu là__xythì sẽ đúng với các giá trị với 2 kí từ đầu bất kì.ILIKE: giống nhưLIKEnhưng sẽ bỏ qua kiểm tra giá trị hoa hay thường.
Về cơ bản thì bạn cũng có thể bao phủ các trường hợp mà cần tìm kiếm rồi. Nhưng với người dùng không rõ mình cần tìm kiếm cái gì thì với các trường hợp sau bạn sẽ xử lý như thế nào:
- Tìm kiếm: main msi thay vì phải ghi đầy đủ ra mainboard msi. Mình xử lý trường hợp này như sau:
SELECT * FROM product WHERE title ILIKE '%main%msi%';Bằng cách tìm kiếm trên sẽ ra đầy đủ các sản phẩm mình cần tìm kiếm.
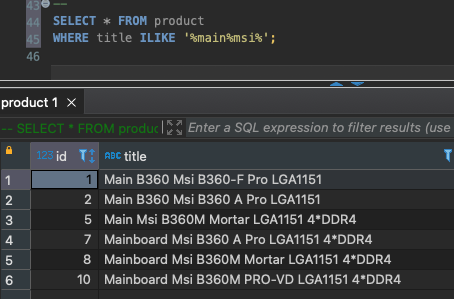
Có vẻ cũng khá thông mình đó! 👏
- Thế còn từ khóa khoá như: msi main. Như này thì vị trí các từ khoá đã bị thay đổi rồi nên DB sẽ không trả về kết quả nào. Các bạn có thể suy nghĩ hoán vị các từ khoá, nhưng nếu như có hơn 10 từ khác nhau với DB hơn 10 triệu dòng thì quả thật không gian tìm kiếm quá lớn. Hoặc các bạn có thể tách từng từ ra tìm kiếm. Như vậy DB vẫn phải tìm kiếm toàn bộ các dòng điều này dẫn tới tốc độ tìm kiếm chậm và server cũng phải xử lý nhiều.
- Bạn còn muốn tìm kiếm trên các cột dữ liệu khác như mã code sản phẩm, nội dung sản phẩm hay các tags mà sản phẩm có, thì bạn cũng phải viết các câu SQL tìm kiếm trên tất cả các thuộc tính này. Nó chậm, phức tạp và dài dòng code 🙃. Mình là mình lười á 🫢.
Chính vì vậy nhiều DB đã hỗ trợ full-text search, nó nhanh và linh hoạt hơn so với cách tìm kiếm thông thường.
Full-text search
Đầu tiên, full-text search là gì? Link cho bạn đọc
Theo mình hiểu một cách đơn giản, full-text search là một kỹ thuật tìm kiếm các từ khoá nằm trong dữ liệu văn bản của database. Dữ liệu văn bản có thể là một thuộc tính (1 cột) hoặc kết hợp nhiều thuộc tính với nhau như tên sản phẩm+mã code+nội dung sản phẩm. Kết quả trả về sẽ chứa một vài từ khoá hoặc tất cả từ khoá cần tìm kiếm tuỳ thuộc vào cách ta tìm kiếm.
Chúng ta bắt đầu nhé:
1. tsvector
tsvector là một kiểu dữ liệu trong DB dùng để lưu các từ khoá (ts nghĩa text search), giống như các kiểu dữ liệu như text, integer, hay char.
to_tsvector là hàm dùng để chuyển đổi văn bản sang các token. Ví dụ như: SELECT to_tsvector('The quick brown fox jumped over the lazy dog.'); Kết quả trả về: 'brown':3 'dog':9 'fox':4 'jump':5 'lazi':8 'quick':2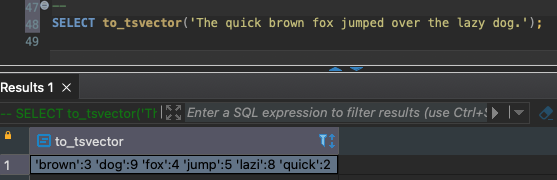
Các từ như jumped hoặc jumping sẽ được tự động chuyển về dạng nguyên mẫu jump . Nhưng nó chỉ hoạt động trong một số ngôn ngữ như Tiếng Anh, chứ Tiếng Việt mình chưa thấy có.
2. tsquery
to_tsquery là hàm dùng để chuyển các từ khoá thành các token và kiểm tra xem có đúng (matching) với ts_vector được tạo từ to_tsvector hay không.
Để làm được điều này thì sử dụng toán tử @@ cho nhiệm vụ kiểm tra (matching). Ví dụ:
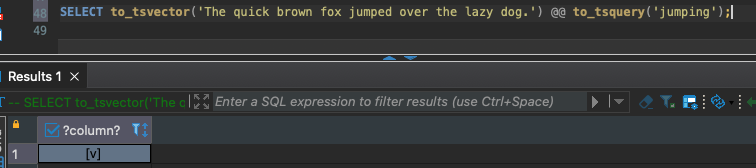
Với từ khoá jumping thì giá trị trả về True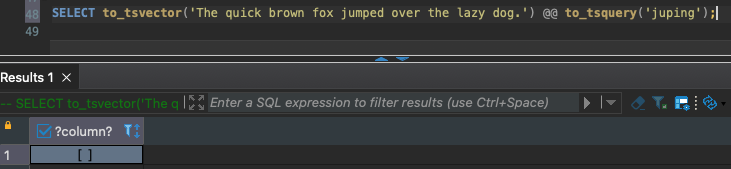
Nhưng với từ khoá juping thì trả về False. Ví nó không có trong các token được tạo ra từ to_tsvector.
Nói nhiều dài, áp dụng vô dữ liệu mình có nào:
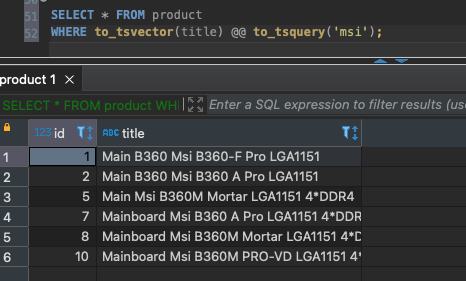
SELECT * FROM product
WHERE to_tsvector(title) @@ to_tsquery('msi');
3. Các phép toán tử
Nhưng với 2 từ khóa trở lên sẽ lỗi, nên từ 2 từ khoá trở lên mới thể hiện được thế mạnh của full-text search! 🤔
- AND – &: cần xuất hiện cùng lúc tất cả từ khoá trong các token từ to_tsvector và không quan tâm thứ tự. VD:
SELECT * FROM product
WHERE to_tsvector(title) @@ to_tsquery('msi & main');
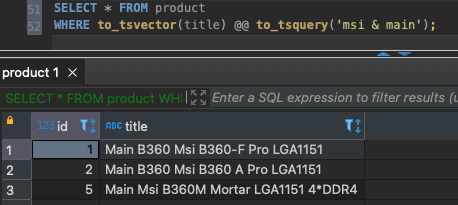
Đảo ngược vị trí main và msi lại, tìm kiếm thông thường không tìm kiếm được nhé!
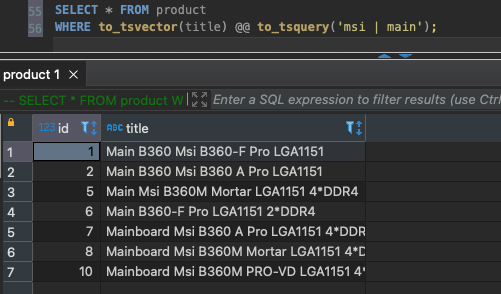
- OR – |: xuất hiện ít nhất một từ khoá trong văn bản. VD:
SELECT * FROM product
WHERE to_tsvector(title) @@ to_tsquery('msi | main');
- NEGATION – !: kiểm tra văn bản không có từ khoá cần tìm.
- Có thể kết hợp tất cả các toán tử trong 1 câu lệnh SQL. VD:
to_tsquery('fox & (dog | clown) & !queen');
4.Tìm kiếm theo cụm từ
Để tìm kiếm theo chính xác theo cụm từ ví dụ như: “Chó Mèo” thì chắc bạn không muốn kết quả có “con Chó cắn con Mèo” (sorry vì ví dụ hơi nhạt nhẽo 🤢 ).
Nếu sử dụng toán tử thông thường AND & thì vị trí của các từ khoá sẽ không được phân biệt, vậy nên có ta có toán từ Proximity–<-> (Xấp xỉ)
- <->: từ thứ 2 phải xuất hiện ngay sau từ thứ nhất. VD: vẫn là từ khóa chó mèo, thì “Nhà nuôi chó mèo” là hợp lý. Nhưng “con Chó cắn con Mèo” là không đúng. Vì vị trí từ mèo cách từ chó là 3.
- <3>: từ thứ 2 phải xuất hiện đứng thứ 3 so với từ thứ nhất. Vì vậy “con Chó cắn con Mèo” sẽ đúng trong trường hợp này.
Lưu ý::
- Tìm kiếm theo cụm từ sẽ không có đối xứng.
- Trong Postgresql,
to_tsquery('chó <3> mèo')là tương đương vớitsquery_phrase('chó', 'mèo', 3).
Một vài tính năng khác mình chưa đề cập tới như: tìm kiếm theo từ điển (1 từ có nhiều nghĩa nên bạn có thể search theo các từ đồng nghĩa), cấu hình lại tsvector (cho phép các từ tìm kiếm sai chính tả hay các từ teen code),
Kết luận
Trên là mình đã trình cách sử dụng full-text search như thế nào trong DB cùng các ví dụ. Về cơ bản các bạn có thể áp dụng vào dự án của các bạn.
Có một vài vấn đề mà mình chưa viết hết trong bài này nếu các bạn cần thì hãy nói cho mình biết để viết chi tiết thêm. Các vấn đề có thể xảy ra là:
- Chưa có Tiếng Việt. Mình xử lý bằng cách chuyển hết về các ký tự ASCII. Vd như: ‘â’ -> ‘a’.
- Tối ưu kết quả tính toán to_tsvector bằng cách lưu vào thành một thuộc tính mới của bảng. Tiết kiệm thời gian tính toán và cải thiện thời gian tìm kiếm.
- Nếu lưu thêm 1 thuộc tính tsvector thì cần phải cập nhập lại giá trị khi Tên sản phẩm, mã code, nội dung thay đổi chẳng hạn. Viết các function và trigger trong DB.
- Đánh trọng số và ưu tiên (setweight() và ts_rank()) các thuộc tính, từ khoá mà muốn được ưu tiên. Ví dụ sẽ ưu tiên từ khoá có trong Tên sản phẩm hơn rồi mới tới từ khoá có trong Nội dung.
Và cảm ơn các bạn đã đọc tới đây ~ .~ Happy time with me 🤪🤪
Tham khảo
Mastering PostgreSQL Tools: Full-Text Search and Phrase Search
Mình cũng tham khảo từ các nguồn google và một vài bài viết trên VIBLO.
Nguồn: viblo.asia