MySQL là một trong những hệ thống quản lý relational DB phổ biến nhất. Nó chạy bằng Structured Query Language (SQL), và do đó bạn có thể một số mẹo liên quan cho các hệ thống khác như PostgreSQL, MariaDB,..
Tại sao chúng ta nói về vấn đề hiệu năng
Ngày nay, hầu hết các công ty khởi nghiệp đều làm việc với các frameworks có chứa ORM để xây dựng MVP của họ nhanh nhất có thể. Vấn đề với các ORM này xảy ra thường xuyên, bạn từ bỏ một số quyền kiểm soát của mình đối với các truy vấn, để có thời gian xây dựng nhanh hơn (không ai muốn viết truy vấn cho mỗi lần lấy dữ liệu hoặc tạo dữ liệu đơn giản).
Vấn đề là một ngày bạn thức dậy tới một triệu rows trong các bảng, điều này ảnh hưởng trực tiếp đến hiệu suất ứng dụng của bạn. Tại một số điểm, bạn hiểu rằng dịch vụ sẽ không mang lại hiệu suất tốt và bạn phải đi sâu vào và giải quyết các vấn đề về hiệu suất này.
Let’s go practical
Sử dụng đúng Tools
Có một cách để debug các truy vấn của bạn, điểm dừng đầu tiên là chọn đúng công cụ.
slow log and general log
để có một cách đơn giản để xác định các vấn đề liên quan đến DB của bạn, bạn nên sử dụng bảng query logs. Nếu bạn sử dụng RDS hoặc bất kỳ nền tảng nào khác để để quản lý MySQL của mình, bạn chỉ cần thêm nó vào cài đặt, nếu không bạn cần tạo các bảng này — bạn có thể tìm thấy SQL code trong link này.
enable query logging
Sau khi bạn tìm thấy phần bị chậm, đã đến lúc đi sâu vào các truy vấn cụ thể. Bạn có thể bật query log bằng cách sử dụng framwork của bạn — thường là một cái gì đó giống như db.enableQueryLog(), hoặc trực tiếp trong DB của bạn:
SETglobal general_log =1;SETglobal log_output ='table';-- to select themSELECT*FROM
mysql.general_log;-- to turn offSETglobal general_log =0;MySQL workbench
Nó là một MySQL tool để quản trị cơ sở dữ liệu. Bạn có thể tìm thấy nó ở đây. Nếu bạn không tìm thấy công cụ phù hợp để lập kế hoạch và phân tích các truy vấn, mình chắc chắn đề xuất công cụ này vì lý do mình đề cập về điều này vì vì query explain tool của họ, có thể giúp bạn hiểu được hành trình truy vấn và trả lời các câu hỏi như — nó có sử dụng đúng index không? cái nó tạo ra là gì, kết quả joins là gì,…
Và nếu bạn thích làm việc theo một cách khác bạn luôn có thể thêm “Explain” trước truy vấn của bạn để có được server explaination.
Using index
Giải pháp cơ bản và dễ dàng nhất cho hầu hết các query chậm, trước khi chuyển qua các mẹo khác, bạn chắc chắn nên bắt đầu với việc sử dụng mẹo này.
MySQL cung cấp 5 loại indexes:
- Primary – một index duy nhất, không có giá trị nào có thể là null. Nó có thể được thay đổi, thường được sử dụng cho identification column.
- Unique index – tất cả giá trị của column phải là duy nhất.
- Regular index – có thể trên một column hoặc nhiều column, chủ yếu được sử dụng để tìm kiếm nhanh hơn.
- Full-text index – sử dụng để lập chỉ mục text
- Descending index (MySQL 8+) – là 1 Regular index được lưu trữ theo thứ tự ngược lại, hữu ích trong trường hợp bạn cần hiển thị dữ liệu tạo gần đây nhất.
Nếu bạn quan tâm đến index hoạt động như nào, bạn có thể đọc câu trả lời tại đây.
-- regular indexCREATEINDEX index_name
ON table_name (column1, column2,...);-- uniqueCREATEUNIQUEINDEX index_name
ON table_name (column1, column2,...);--descending indexCREATEINDEX index_name
ON table_name (column1 DESC, column2 ASC,...);Làm sao để chọn đúng loại index?
- Kiểm tra query log thường xuyên.
- Xác định các column liên quan – nó có thể là một hoặc nhiều, mà bạn đang sử dụng để truy vấn.
- Chọn đúng index – chú ý sự khác biệt giữa các loại index
Fine-tuning các truy vấn của bạn
select only what you need
ORM và developers thường thực hiện lựu chọn select * , truy vấn này là một mức giá khi bạn cần xử lý một bảng lớn.
Hãy xem các truy vấn sau:
-- select *SELECT*FROM corpus_project.sentence_words limit1000000;
execution time-0.609 sec
-- select specific columnsSELECT id, word_id FROM corpus_project.sentence_words limit1000000;
execution time-0.313 sec
Ngay cả khi bạn truy vấn các rows của mình theo từng khối, cuối cùng sự khác biệt vẫn gần với kết quả này. Vì vậy, nó rất đơn giản, chỉ truy vấn các column cần thiết chứ không phải toàn bộ bảng.
join using indexes
Table joining là một hành động tốn thời gian và cần phải được quản lý cẩn thận. Nếu bạn sử dụng các truy vấn join columns với các kiểu dữ liệu khác nhau, bạn sẽ gửi đến SQL engine để quét toàn bộ bảng, tùy chọn chậm nhất có thể. Do đó, cần xác minh rằng các truy vấn joins sử dụng index, nếu không hãy thử tìm cách thay đổi truy vấn hoặc thêm đúng index.
Lưu ý: Trong hầu hết các trường hợp, full index scan nhanh hơn nhiều (chúng tôi đã cải thiện từ 28 giây xuống 1,9 giây trên một số truy vấn), nhưng có những trường hợp full index scab sẽ chậm hơn vì đôi khi đọc tuần tự (như được sử dụng trong full table scan) có thể hiệu quả hơn so với việc đọc index (nhanh) và sau đó chạy rất nhiều truy vấn ngẫu nhiên để tìm nạp các giá trị theo giá trị.
Choosing the right columns
Đôi khi, một hành động đơn giản như chọn đúng column hoặc xây dựng bảng phụ phù hợp có thể tạo ra sự khác biệt lớn về hiệu suất. Xem lại tất cả các column bạn sử dụng trong toàn bộ truy vấn và cố gắng tập trung và hạn chế nhất có thể.
Hãy xem ví dụ:
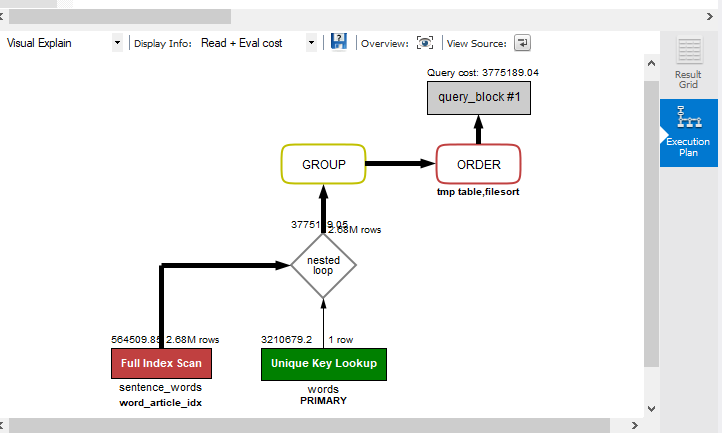
Truy vấn trên bảng có 2.68 triệu rows
SELECT sentence_words.word_id,count(sentence_words.id)as frequency, words.title as word_title
FROM sentence_words join words on sentence_words.word_id=words.id
groupby word_id orderby frequency descThoạt nhìn, có vẻ như truy vấn này phải rất nhanh vì tất cả các cột mà nó sử dụng đều được đánh index – id (unique), word_id (index). Truy vấn chạy mất 27.865 giây. Mặc dù đã sử dụng tất cả các mẹo khác, vậy bước tiếp theo là gì?
Bằng cách sử dụng giải query explain nên đã phát hiện ra rằng mặc dù đang sử dụng các index, truy vấn vẫn thực hiện full table scan, sau đó thực hiện một thay đổi nhỏ để chuyển từ truy vấn 27 giây sang truy vấn 2.531 giây – bằng cách sử dụng cùng một index đang truy vấn cho – word_id trong count. Bằng cách đó, truy vấn đã thay đổi từ full table scan sang full index scan.
Using Cache
Cache là một giải pháp tốt cho các vấn đề hiệu suất. nó có thể được giải quyết ở program level, sử dụng các Memcached services như Redis hoặc ở cấp độ SQL.
Ở cấp độ SQL, bạn nên biết rằng họ đã quyết định loại bỏ nó và nếu bạn sử dụng phiên bản 8+ thì nó đã bị xóa.
Nếu bạn chọn sử dụng cache ở program level, thử thách chính là tìm đúng cách để quản lý tính nhất quán giữa cache và cơ sở dữ liệu. Bộ nhớ đệm có thể được sử dụng làm phần mềm trung gian giữa mã của bạn và DB hoặc cho các trường hợp cụ thể. Bạn cũng có thể sử dụng nó để lưu trữ dữ liệu sau một số thao tác và không phải là truy vấn thô. Trong giai đoạn lập kế hoạch, hãy đảm bảo bạn xem xét đồng thời, cập nhật và tạo tỷ lệ và mức độ chính xác bạn cần từ dữ liệu của mình.
nguồn: https://medium.com/nexc-co/practical-tips-to-improve-mysql-query-performance-2038d036f31b
Nguồn: viblo.asia