1. Giới thiệu về bài toán Image Generation
Bài toán Image Generation là một trong những bài toán cũng đang được quan tâm rất nhiều trong thời gian gần đây. Có thể hiểu một cách đơn giản đó là, nhiệm vụ của Image Generation là tạo ra các hình ảnh mới từ một bộ dữ liệu cho trước.
Bài toán này hiên nay cũng đang được làm 2 loại:
- Unconditional generation: Tạo hình ảnh với không có điều kiện từ tập dữ liệu cho trước, kí hiệu
p(y). - Conditional image generation: Tạo hình ảnh với có điều kiện từ tập dữ liệu cho trước, dựa trên nhãn (label), kí hiệu
p(y/x). Điển hình của dạng này, là các subtasks đã khá quen thuộc như Image-to-Image Translation, Image Inpainting, Face Generation, …
Ngoài ra, mỗi một bài toán nêu trên lại có những model phát triển phục vụ riêng. Có thể kể đến, ProDA và pix2pix là 2 model đang làm mưa làm gió trên bảng xếp hạng Image-to-Image Translation, hay SN-PatchGAN và CoModGAN cũng đang on top bài toán Image Inpainting, ….
bài toán Image Inpainting, ….
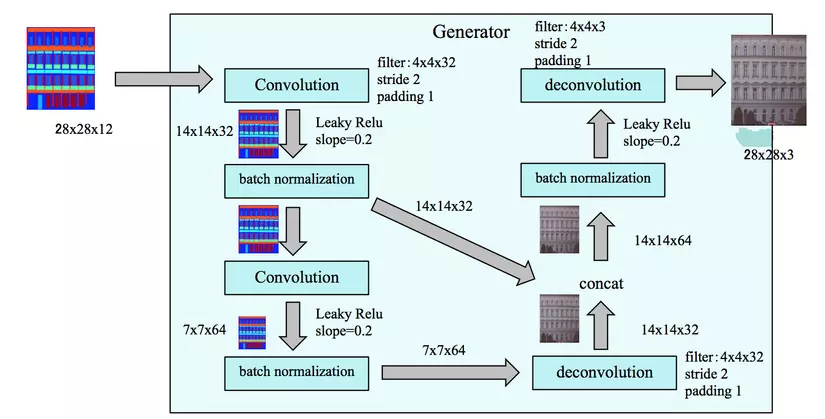
Hình 1: Kiến trúc Pix2Pix GAN trong bài toán image-to-image translation.
Vậy để so sánh các model khác nhau trên cùng bộ dữ liệu, đơn giản hơn là đánh giá chất lượng của model, người ta thường có các cách nào để đánh giá, lựa chọn được một model ưng ý?
2. Vấn đề trong Evaluating Image Generation
Để giải quyết câu hỏi bên trên, chúng ta sẽ phải biết một điều rằng: các bài toán mình kể ở trên không giống với các bài toán Segmentation, Object Detection như chúng ta thường gặp. Dễ hiểu hơn, mình xin lấy mô hình mạng GAN làm ví dụ, GAN là một mô hình được tạo thành từ 2 mạng con Generator và Discriminator, việc train GAN là việc chúng ta phải train đồng thời cùng lúc 2 mạng này, không có hàm mục tiêu cụ thể hay thước đo cụ thể để đánh giá mô hình Generator.
Từ đó, có thể thấy: Đây là một vấn đề đối với việc nghiên cứu và sử dụng GAN, xa hơn là với bài toán Image Generation. Đã có rất các phương pháp khác nhau được đề xuất, song nhìn chung, đánh giá ảnh sinh ra cần dựa trên 2 yếu tố sau:
- Chất lượng ảnh: Ảnh sinh ra phải có chất lượng cao, giống với dataset.
- Độ đa dạng: Generator cần sinh ra được nhiều ảnh khác nhau thuộc nhiều lớp khác nhau. Nếu Generator mãi chỉ sinh ra được một vài ảnh hay thuộc cùng 1 class thì cũng không thực sự ý nghĩa lắm.
Ơ, vậy thì làm sao để biết được ảnh có chất lượng tốt, hay ảnh có đa dạng không nhỉ?

Hình 2: Từ trái qua phải: Input ảnh đầu vào, Ảnh thực tế, Ảnh sinh ra.
Cách đơn giản nhất đó, đó là trực tiếp dùng mắt thường để đánh giá. Cái này nhỏ nhưng rất có võ nhé , đặc biệt trong lúc train model thường sẽ predict results để xem luôn. Ngoài ra, còn đặc biệt hữu hiệu với người mới tiếp xúc như mình.
Ưu điểm của phương pháp này đó là verify rất nhanh, nhưng nhược điểm của nó là không khách quan (mỗi người có một định nghĩa ảnh tốt ảnh đẹp khác nhau), không áp dụng được trên một tập dữ liệu lớn. Như vậy, chúng ta cần tìm cách khác để đánh giá được ảnh sinh ra, thoả mãn 2 yếu tố trên và đồng thời áp dụng được cho tập dữ liệu lớn.
3. Danh sách các chỉ số áp dụng cho việc đánh giá Model
Để cho mọi người có cái hình dung nhanh, dưới đây là các chỉ số đã được đề xuất để đánh giá Image Generation
- Average Log-likelihood
- Coverage Metric
- Inception Score (IS)
- Modified Inception Score (m-IS)
- Mode Score
- AM Score
- Frechet Inception Distance (FID)
- Maximum Mean Discrepancy (MMD)
- Classifier Two-sample Tests (C2ST)
- Number of Statistically-Different Bins (NDB)
- Image Retrieval Performance
- Generative Adversarial Metric (GAM)
- Normalized Relative Discriminative Score (NRDS)
- Adversarial Accuracy and Adversarial Divergence
- Geometry Score
- Reconstruction Error
- Image Quality Measures (SSIM, PSNR and Sharpness Difference)
- Low-level Image Statistics
- …
Cũng còn khá nhiều các chỉ số được dùng để đánh giá, nhưng mình xin liệt kê 1 số ít ở đây, mọi người có hứng thú với cái nào thì có thể tìm hiểu qua link này nhé: [(https://arxiv.org/abs/2103.09396)]
4. Giới thiệu các chỉ số được sử dụng nhiều nhất trong các paper
Vì chỉ gói gọn trong 1 bài viết, nên mình sẽ giới thiệu một vài chỉ số đã được chấp nhận rộng rãi cũng như được các paper sử dụng nhiều nhất. Ở đây mình xin đưa ra 4 chỉ số: IS, FID, SSIM, PSNR
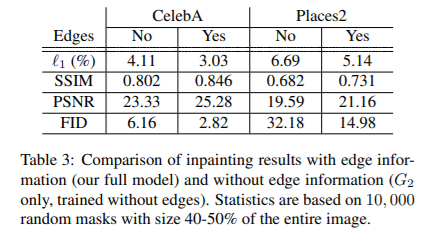
Hình 3 được trích từ bài báo “EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning”
4.1. Inception Score (IS)
Inception đúng với tên gọi của nó. Nó chính là mạng CNN về nhì trong cuộc thi ImageNetChallange 2015. IS được tính bằng cách sử dụng pre-trained model Inception trên dữ liệu ImageNet. Input của mạng Inception là 1 ảnh và output với hàm softmax sẽ cho ra được xác suất ảnh đấy thuộc từng lớp tương ứng.
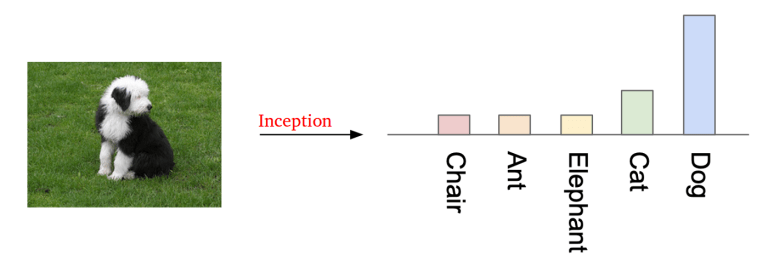
Hình 4: Mạng inception dự đoán ảnh con chó, thuộc 1 trong các class dataset.
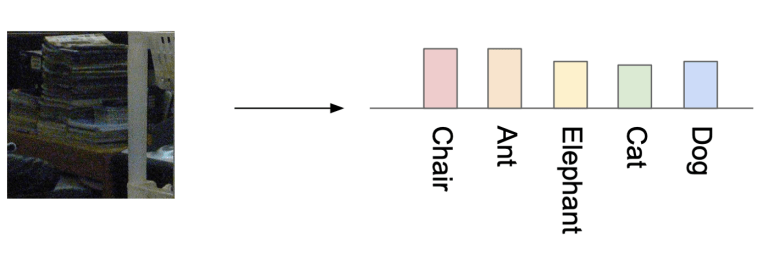
Hình 5: Mạng inception dự đoán ảnh đống sách, không thuộc 1 trong các class dataset.
Nhận xét: run through qua inception, ảnh rõ ràng thuộc một lớp nào đó sẽ cho ra xác suất tại lớp đó là rất cao, còn ảnh không thuộc lớp nào sẽ cho ra xác suất giữa các lớp là same nhau (uniform).
Từ trên, ngta đã nghĩ ra cách dựa vào Inception, kiểm tra được 2 yếu tố ở trên:
- Kiểm tra được chất lượng ảnh: Cho ảnh sinh ra qua mạng Inception nếu ảnh rõ, tốt thì mạng sẽ phân loại tốt (xác suất 1 lớp cao hơn hẳn).
- Kiểm tra được độ đa dạng của ảnh sinh ra: Cộng theo từng lớp các giá trị xác suất của tất cả các ảnh sinh ra trong generator. Nếu Generator có thể sinh ra đa dạng dữ liệu thì tổng xác suất sẽ dạng uniform, ngược lại nếu dữ liệu chỉ sinh ra dữ liệu ở 1 hay 2 lớp thì tổng xác suất sẽ chỉ cao hơn ở 1 hay 2 lớp.
Đấy là ý tưởng, vậy người ta đã triển khai với toán như nào :
- Sử dụng Kullback–Leibler divergence (KLD) để đánh giá (Hiểu đơn giản thì Kullback–Leibler (KL) nhận input là 2 distribution và output ra độ tương đồng giữa hai distribution. Nếu 2 distribution giống nhau thì KL = 0, hai distribution càng khác nhau thì KL càng lớn.)
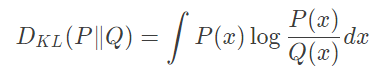
-
Ta gọi: Label Distribution
p(y/x): xác suất của ảnh x thuộc class y, marginal distributionp(y):
tổng xác suất của class y. -
Để ảnh sinh ra tốt (chất lượng tốt và đa dạng) thì ta muốn label distribution cao ở một lớp, thấp ở các lớp khác và marginal distribution sẽ dạng uniform , ta thấy giá trị KLD cao.
-
Từ đây, có được nhận xét: Giá trị KLD cao khi ảnh chất lượng cao và ảnh đa dạng.
-
Như vậy, tính giá trị KLD cho mỗi ảnh sinh ra rồi lấy trung bình lại làm giá trị IS cho model.
![]()
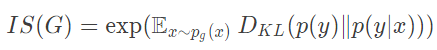
Hạn chế của IS:
- Nếu Generator chỉ sinh được một ảnh mỗi lớp thì chỉ số KL vẫn có thể cao => Chỉ đa dạng lớp nhưng không đa dạng ảnh trong mỗi lớp.
- Nếu Generator nhớ và sinh ra các ảnh trong dataset thì chỉ số KL cũng cao => Không tốt.
4.2. Frechet Inception Distance (FID)
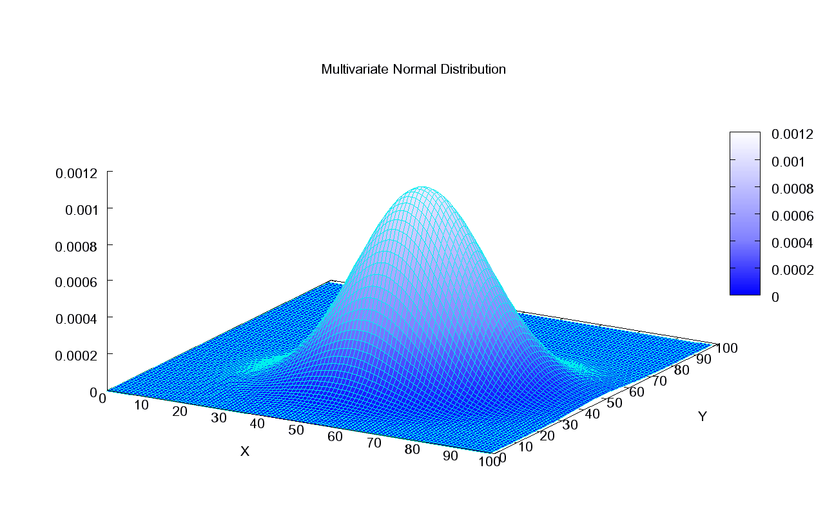
Đầu tiên, ta sẽ cùng nhau ôn lại một chút về Multivariate normal distribution:
-
MND đôi khi được gọi là phân phối Gauss nhiều chiều, là tổng quát hóa của phân phối chuẩn một chiều (còn gọi là phân phối Gauss) cho không gian nhiều chiều hơn.
![]() Hình 6: Từ các điểm dữ liệu (3d) thì ta sẽ tìm được 2d multivariate gaussian distribution như này.
Hình 6: Từ các điểm dữ liệu (3d) thì ta sẽ tìm được 2d multivariate gaussian distribution như này. -
Với n điểm dữ liệu m chiều ta sẽ tìm được một (m-1) dimension multivariate gaussian distribution fit nhất.
FID
Cách tính FID phụ thuộc vào Inception network( giữ đến lớp AvgPool, bỏ phần sau). Như vậy, output của mỗi ảnh sẽ là 1 vector 2048 * 1. Giả sử, tập datasets của chúng ta có n ảnh.
Các bước tiến hành:
- Cho n ảnh trong tập datasets chạy qua Inception network được n vector 2048 * 1. => tìm được 1 multivariate gaussian distribution ứng với n vector này.
- Cho n ảnh sinh ra cũng chạy qua Inception network được n vector 2048 * 1. => tương tự cũng tìm được 1 multivariate gaussian distribution
- Để các ảnh sinh ra giống các ảnh trong dataset thì ta mong muốn 2 multivariate gaussian distribution giống nhau, hay mean và variance gần nhau.
Ta định nghĩa công thức FID:
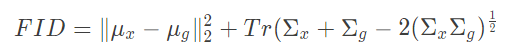
Nhận xét:
- FID không âm và FID càng thấp thì 2 distribution càng gần nhau => ảnh sinh ra càng giống ảnh gốc trong dataset.
- Không giống như Inception Score (IS) , chỉ đánh giá sự phân bố của các hình ảnh được sinh ra, FID so sánh sự phân bố của các hình ảnh được sinh ra với sự phân bố của các hình ảnh thực tế được sử dụng .
4.3. Structural Similarity Index Measurement (SSIM)
Chỉ số SSIM được sử dụng để đo mức độ giống nhau giữa hình ảnh đầu vào và ảnh sinh ra. Công thức SSIM dựa trên ba thông số để so sánh: độ chói (luminance), tương phản (contrast) và cấu trúc (structure).
Một ảnh sinh ra là tốt nếu:
- Những điểm ảnh có mức độ sáng tối khác nhau, và càng có nhiều mức độ sáng tối càng có nhiều chi tiết ảnh => Ảnh chất lượng tốt
- Một bức ảnh không phải độ tương phản càng cao thì càng tốt mà nên có sự hài hòa cân đối giữa sáng và tối. => Độ da dạng
Từ đó, người ta đề xuất công thức sau:
![]()
Nhận xét: SSIM có giá trị trong khoảng từ -1 đến 1, đạt giá trị bằng 1 trong trường hợp hai bộ dữ liệu giống hệt nhau. Chỉ số này có giá trị càng lớn thì tương ứng với model càng tốt.
4.4. PSNR
PSNR được định nghĩa thông qua sai số toàn phương trung bình (MSE – Mean squared error). MSE là một khái niệm trong thống kê học, nghĩa là sai số toàn phương trung bình của một phép ước lượng là trung bình của bình phương các sai số, nghĩa là sự khác biệt giữa các ước lượng và những gì đánh giá. Ở đây MSE được xác định cho ảnh hai chiều có kích thước mxn trong đó I và K là ảnh gốc và ảnh sau khi tổng hợp.
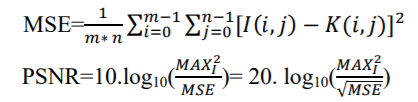
Ở đây MAXi là giá trị tối đa của pixel trên ảnh. Khi các pixels được biểu diễn bởi 8 bits, thì giá trị của nó là 255. Trường hợp tổng quát khi tín hiệu được biểu diễn bởi B bit trên một đơn vị mẫu MAXi là 2^B-1.
Thông thường nếu PSNR>=40 dB thì hệ thống mắt thường gần như không phân biệt được ảnh gốc và ảnh sinh ra. PSNR càng cao thì chất lượng ảnh sinh càng tốt, khi 2 ảnh giống hệt nhau thì MSE=0 và PSNR đi đến vô hạn, đơn vị của PSNR là Decibel.
5. Kết Luận
Như vậy, mình đã đi qua toàn bộ bài, từ giới thiệu bài toán Image Generation là gì? Cho đến vấn đề evaluate của bài toán. Cùng với đó, mình đã liệt kê các chỉ số được sự dụng để evaluate bài toán, giới thiệu sơ qua 1 chút về IS, FID, SSIM, PSNR.
Ở đây mình sẽ tổng hợp lại về 3 chỉ số thường gặp nhất trong bài toán Image Generation.
Mình xin tóm tắt lại như sau:
| Inception Score (IS) | Frechet Inception Distance (FID) | SSIM | PSNR | |
|---|---|---|---|---|
| Cách đánh giá | IS càng cao càng tốt | FID không âm và FID càng thấp càng tốt | Trong khoản (-1,1), càng gần 1 càng tốt | Càng cao càng tốt, PSNR>=40 dB sẽ giống thật nhất. |
6. Tổng kết
Okiiii vậy cũng done!!!
Vì lượng kiến thức còn có hạn hẹp cũng như văn phong của mình còn kém, nên mong mọi người thông cảm ạ. Vì cũng đang sẵn tiện làm đồ án nên mình đã viết bài này luôn, chia sẻ đến mọi người cùng tìm hiểu.
Mong nhận được phản hồi cũng như góp ý cho mình, để mình cải thiện cho lần sauuuu! Thank mọi người
7. Tài liệu tham khảo
https://file.scirp.org/pdf/JCC_2019030117485323.pdf
https://machinelearningmastery.com/how-to-evaluate-generative-adversarial-networks/
Nguồn: viblo.asia