Xin chào anh em đã quay trở lại với series về Apache Kafka này của mình, Ở bài viết trước sau khi đi tìm câu trả lời cho câu hỏi Kafka nó làm được những gì thì hôm nay mình tiếp tục với bài đầu tiên trong chuỗi bài giải thích các khái niệm và thuật ngữ trong Kafka
Và những lời quảng cáo giới thiệu về Khả năng của Kafka có đúng sự thật hay không??????
Let go.
Chắc anh em còn nhớ ở cuối bài trước mình đã tổng hợp lại tổ hợp các chức năng chính của Kafka tới thời điểm hiện tại : 10/2022, nếu ae nào chưa biết thì có thể đọc lại bài trước của mình tại đây
Đầu tiên là : “Publish (ghi) và Subscribe (Đọc/nhận) event”.
Ghi, Đọc, Nhận thì chắc anh em đều hiểu rồi vậy còn cái “event” nghe có vẻ khá trìu tượng. Tạm dịch sang tiếng việt thì là sự kiện hay nói cách khác nó có thể là một hành động vô tình hoặc có chủ ý của con người hoặc động vật…. xảy ra trong cuộc sống trên trái đất này. Với con người (Động vật) thì có thể nhìn thấy nghe thấy ghi nhận và nhớ những thứ đã xảy ra. Vậy thì
Như anh em cũng đã biết Kafka là một hệ thống phần mềm được các kỹ sư lập trình tạo nên và được cài cắm trên máy chứ không phải là con người do các chị/em/cô/dì… đẻ ra (đương nhiên phải có cái gì đó tác động lên chứ tôi cũng không tin lắm các câu chuyện như uống nước trong sọ dừa hay ra đồng đặt chân vào mấy cái lỗ nó giống cái bàn chân có chửa rồi đẻ được 😆😆😆 ) hoặc bất cứ một loài động vật nào trên trái đất 😀 .
Vậy làm sao để Kafka có thể nhận, ghi và lưu trữ cho đúng quy trình ?
Cách giải thích của mình sẽ như sau:
- Khái niệm đầu tiên.
Event trong Kafka còn được gọi với một cái tên khác làmessage.
Với tên gọi làmessagethì anh em đã dễ hiểu hơn và dịch hẳn ra thì nó là tin nhắn, nói đến tin nhắn thì thành phần cấu tạo nên nó đương nhiên phải là chữ rồi là chữ thì máy tính đã có thể ghi nhận và lưu trữ một cách dễ dàng được rồi nhỉ 👏 . Giá trị của nhữngmessagecó thể là: tên, ngày tháng năm, hành động…. ( tất cả nó được mô tả dưới dạng chữ).
Tiếp theo
Publish (Ghi) : nói đến ghi thì từ xưa tới nay ghi thì chúng ta thường lấy bút ghi chữ lên giấy.
Thế còn Kafka nó publish (dịch ra tiếng việt mình chưa nghĩ ra từ nào cho nó sát nghĩa nên mình dùng tạm tiếng anh, anh em thông cảm nhé 😘) bằng cái gì và nó publish vào đâu????
(không biết có anh em nào trong đầu lại nghĩ đọc bài của thằng này hỏi nhiều vcl không 😂😂)
Mình giải thích nó cho anh em như sau:
Kafka nó publish dựa vào Producers
- Khái Niệm thứ 2.
Producers không ngoài gì khác đó chính là các application, service … được anh em code lập trình nên có sử dụng các thư viện hoặc bản thân ngôn ngữ lập trình nên các service đó đã hỗ trợ kết nối với Kafka để publish các message lên Kafka theo Topic .
Cùng nhìn lại kiến trúc của Kafka .
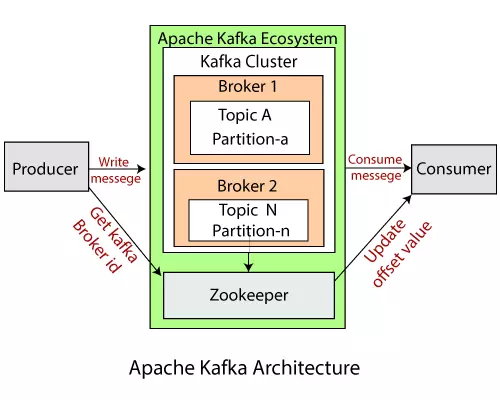
Sau khi các ứng dụng, service đã publish thành công lên Kafka rồi, thì các Kafka Broker trong cụm Kafka Cluster sẽ tiếp nhận theo Topic .
Chúng ta cùng nhau tìm hiểu Topic xử lý và lưu trữ như thế nào?
- Khái niệm thứ 3
Topic theo khái niệm sách vở thì nó được định nghĩa là “luồng dữ liệu của Kafka”.
Dễ hiểu hơn thì ae liên tưởng Topic cũng giống như là Table trong các cơ sở dữ liệu quan hệ như: MySQL, Oracle, Mssql …. nó cũng có tên và lưu trữ có thứ tự và nó cũng được lưu trên ổ cứng của máy ( Đây cũng là lý do để Kafka được quảng cáo là có độ tin cậy cao)
Một cách giải thích khác cho trân thực hơn thì :
Topic nó là folder có thể nằm ở đâu đó trong hệ thống lưu trữ của máy tính và các Event (message) được lưu trữ trên chính cái folder đó.
Khi một event được publish tới Topic việc Broker sẽ làm là appen message vào partition và lưu trữ nó xuống ổ cứng và thằng Kafka nó nó sẽ đảm bảo cho anh em rằng tất cả các Consumer consume vào topic-partition sẽ luôn luôn đọc được chính xác cái message đã ghi theo thứ tự và không giống như các hệ thống message khác message sẽ bị xóa đi sau khi consumption. Thay vào đó thì message đó vẫn được lưu trữ trên Topic theo thời gian mà chúng ta cấu hình.
Bonus thêm cho ae là những message nào có chung 1 key (chỗ này chắc mình sẽ làm một bài giải thích kỹ hơn về chỗ này) sẽ được lưu chung vào một partition.
-
Khái niệm tiếp theo Offset
Offset chính cái nó để chỉ thứ của message trong 1 partition mà mình đã nhắc đến ở trên -
Khái niệm cuối trong bài viết này là Consumer và ConsumerGroup
Đã có đầu publish message (ông gửi thư) đã có Kafka nhận vận chuyển lưu trữ message (ông giao thư ) thì đương nhiên sẽ phải có người nhận chứ đúng ko anh em?
Consumer : nó là 1 phần của Consumer Group thì anh em hiểu cũng chính là application/service các anh em code ra có khả năng kết nối tới Kafka cluster và có triển khai method lắng nghe Topic của Kafka thì nó là 1 Consumer
ConsumerGroup là tất cả các Consumer cùng listener 1 group id thì nó .
Khi mà các consumer consume vào 1 topic thì có thể có các TH xảy ra như sau:
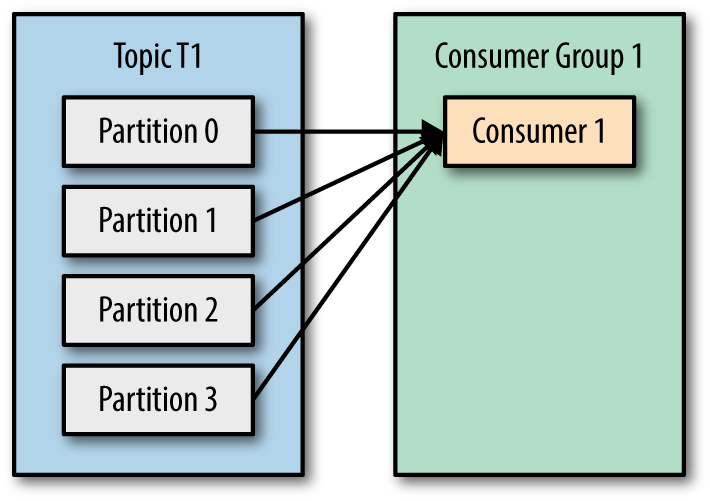
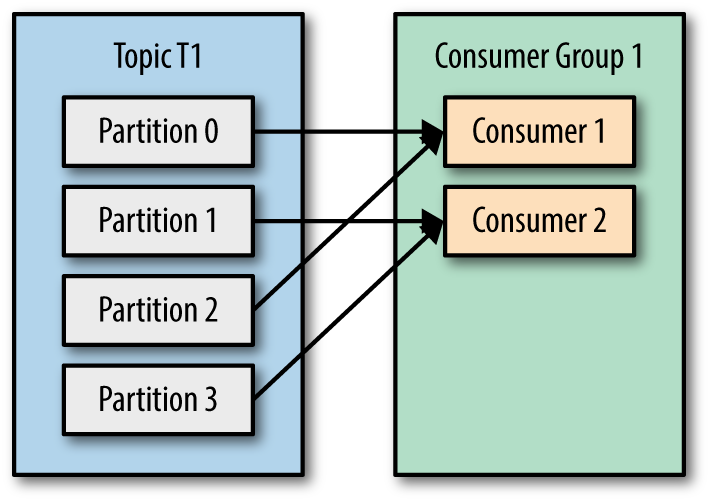
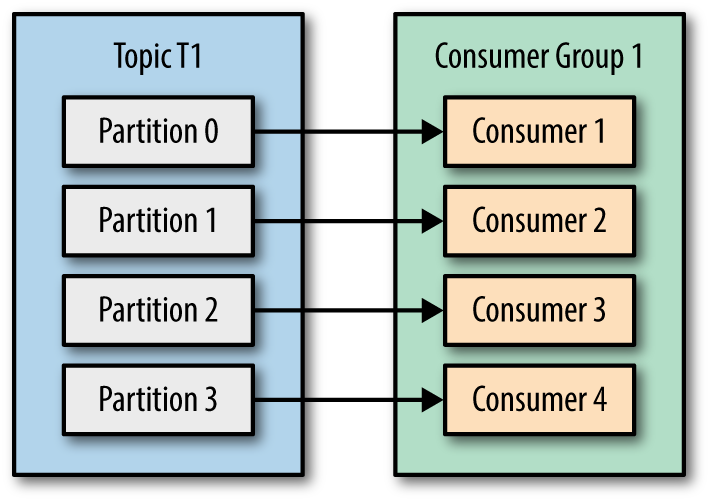
Đó giờ có ai hỏi anh em Kafka nó publish, nhận với ghi message thế nào thì ae cứ mạnh dạn trả lời application/service sẽ làm Producer bắn message vào Kafka tới Topic-partition những message này có thể có cùng 1 key hoặc mỗi message có 1 key riêng biệt và Kafka Broker sẽ làm nhiệm vụ appen message và partition và lưu xuống ổ cứng theo thứ tự.
Để giải thích cho cái lời quảng cáo độ tin cậy cao thì anh em cùng nhìn vào bức hình sau:
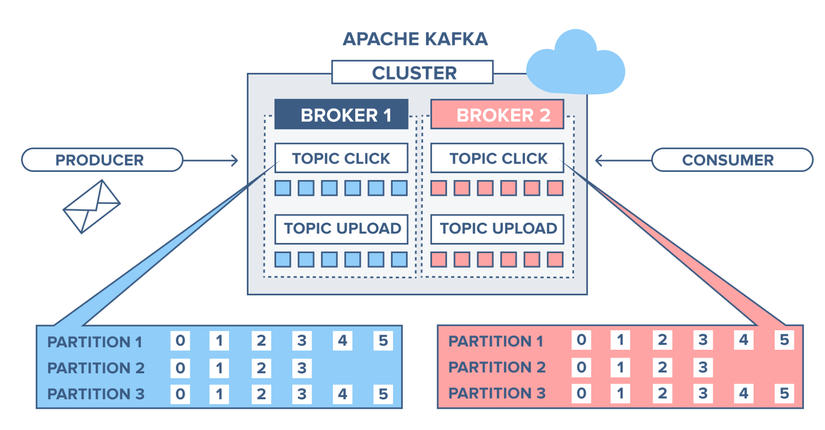
Ở hình bên trên là một cụm Kafka cluster gồm 2 Broker có 2 Topic, Topic Click có 3 partition và nằm được replica (mở rộng) trên cả 2 Broker và mỗi message sẽ được appen vào đủ 6 partition và lưu xuống ổ cứng theo thứ tự.
—————– > độ tin cậy cao dựa trên việc Kafka replica Topic trên nhiều Partition.
Chỗ này mình cũng giải thích luôn về cái lời quảng cáo thứ 4 của kafka High performance (thông lượng cao)
Với số lượng partition có thể có trên 1 Broker và khả năng xử lý của mỗi partition là 10MB/s benchmark tại đây với mỗi 1 partition có sẽ được Kafka phân phối tới 1 consumer thì lưu lượng message đúng là khổng lồ đúng không anh em. (Mình sẽ có 1 bài phân tích kỹ về vấn đề này)
Anh em cùng chào đón phần tiếp theo nhé còn rất nhiều điều hay ho về Kafka mà không thể bỏ lỡ.
Many thanks!
Nguồn: viblo.asia