Giới thiệu MMDetection
MMDetection là một thư viện chuyên phục vụ cho các bài toán liên quan đến Object Detection, được tạo ra bởi OpenMMLab, cha đẻ của rất nhiều thư viện khác như MMCV, MMSegmentation,… Lưu ý, nên xem bài viết này trong lúc mở sẵn github của MMDetection hoặc một IDE có MMDetection để có thể hiểu được tốt nhất
Lưu ý, nên xem bài viết này trong lúc mở sẵn github của MMDetection hoặc một IDE có MMDetection để có thể hiểu được tốt nhất
Ưu điểm
- Tính module hóa cực cao, mọi thứ đều rời rạc với nhau nên việc lắp ghép các thành phần của một mạng Object Detection cực thuận tiện và dễ dàng
- Hỗ trợ cực kì nhiều pre-trained models, kể cả những paper gần đây nhất
- Nhiệt tình trả lời issues trên Github nếu bạn hỏi
- Hiểu được flow của MMDetection, ta có thể dễ dàng hiểu được các thư viện khác như MMSegmentation, MMAction2,… vì chúng chung flow.
Nhược điểm
- Cực kì khó làm quen cho người mới sử dụng
- Vẫn cần phải hiểu các thành phần làm gì thì mới có thể lắp ghép vào được, chứ mọi thứ không phải là tự động
- Chưa hỗ trợ tốt trên windows do phải cài đặt Pycocotools
Cách install các bạn có thể làm theo hướng dẫn ở readthedocs của MMDetection: https://mmdetection.readthedocs.io/en/latest/get_started.html#installation
Khuyến khích sử dụng openmim (có đề cập trong link bên trên) để cài đặt các thư viện của OpenMMLab tránh xảy ra lỗi.
Config
Mọi ma thuật đều xảy ra ở đây, đây là nơi ta tiến hành xây dựng model Object Detection của riêng bản thân, tự thêm vào các augmentations trong lúc load data, điều chỉnh optimizer, bla bla đủ thứ khác. Chính vì vậy, để hiểu được config là vô cùng quan trọng và vô cùng khó.
Ví dụ config:
_base_ = [
'../_base_/datasets/coco_detection.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
model = dict(
type='ATSS',
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
style='pytorch',
init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
start_level=1,
add_extra_convs='on_output',
num_outs=5),
bbox_head=dict(
type='ATSSHead',
num_classes=80,
in_channels=256,
stacked_convs=4,
feat_channels=256,
anchor_generator=dict(
type='AnchorGenerator',
ratios=[1.0],
octave_base_scale=8,
scales_per_octave=1,
strides=[8, 16, 32, 64, 128]),
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[.0, .0, .0, .0],
target_stds=[0.1, 0.1, 0.2, 0.2]),
loss_cls=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=1.0),
loss_bbox=dict(type='GIoULoss', loss_weight=2.0),
loss_centerness=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0)),
# training and testing settings
train_cfg=dict(
assigner=dict(type='ATSSAssigner', topk=9),
allowed_border=-1,
pos_weight=-1,
debug=False),
test_cfg=dict(
nms_pre=1000,
min_bbox_size=0,
score_thr=0.05,
nms=dict(type='nms', iou_threshold=0.6),
max_per_img=100))
# optimizer
optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
Mình có nói ở trên là config là nơi kiểm soát mọi thứ, từ dataset, dataloading, nhưng như các bạn thấy trong file config này hầu hết là chỉnh config cho model, vậy config cho những thứ khác nằm ở đâu.
Chú ý từ khóa _base_ ở đầu config, bao gồm '../_base_/datasets/coco_detection.py', '../_base_/schedules/schedule_1x.py', chúng sẽ được lấy từ mmdetection/configs/_base_. /_base_/datasets/ sẽ là nơi chứa configs cho các datasets, dataloading, tương tự với các _base_ khác có nhiệm vụ y như tên của chúng.
Vậy những tham số truyền vào configs thì ảnh hưởng gì?
model = dict(
type='ATSS'
Ở đây sẽ tạo ra một model, có class là ATSS, thế cái class ATSS là gì? Ở đâu? Được định nghĩa như nào?
Class ATSS sẽ được định nghĩa trong mmdetection/mmdet/models/detectors/atss.py:
@DETECTORS.register_module()
class ATSS(SingleStageDetector):
"""Implementation of `ATSS <https://arxiv.org/abs/1912.02424>`_."""
def __init__(self,
backbone,
neck,
bbox_head,
train_cfg=None,
test_cfg=None,
pretrained=None,
init_cfg=None):
super(ATSS, self).__init__(backbone, neck, bbox_head, train_cfg,
test_cfg, pretrained, init_cfg)
Có thể thấy trên config đã truyền đủ các tham số cho việc init class ATSS, với:
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
style='pytorch',
init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50'))
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
start_level=1,
add_extra_convs='on_output',
num_outs=5)
và tương tự với bbox_head.
Ủa nhưng mình truyền vào config là dictionary mà? Đúng vậy, chỉ cần truyền vào một dictionary với các tham số phù hợp là ta đã tạo ra được model. Đó là vì các class này được build dựa trên thư viện phụ MMCV cũng của OpenMMLab thông qua cơ chế Registry giống của Detectron. Class ATSS được ghi vào trong Registry thông qua@DETECTORS.register_module()
Mình xin phép không đi sâu vào phần này vì chúng ta không cần hiểu về MMCV vẫn có thể dùng tốt được MMDetection.
Về ý nghĩa của từng dòng trong config, các bạn có thể tìm hiểu thêm qua ví dụ về config đầy đủ của Mask R-CNN được viết sẵn của MMDetection ở đây: https://mmdetection.readthedocs.io/en/latest/tutorials/config.html#an-example-of-mask-r-cnn
Tóm tắt lại config:
_base_: nếu bạn muốn dùng lại config có sẵn- Xây dựng config của một thứ bạn muốn thông qua
dict(**kwargs)
Tiếp theo, mình sẽ hướng dẫn các bạn tạo một custom config hoặc là ghi đè một config
Dataset
Điều quan trọng nhất khi đem một model đi train chính là ta cần phải biết cách tổ chức data, cách load data vào train đã. MMDetection đã có những dataset nổi tiếng được định nghĩa trước ở trong mmdetection/mmdet/datasets/. Việc này là để các bạn có thể thay đổi tham số truyền vào config của dataset nếu dataset của bạn được tổ chức giống với các datasets được định nghĩa sẵn trong mmdetection/mmdet/datasets/. Mình sẽ lấy ví dụ với COCO Dataset và config của COCO Dataset để các bạn hiểu cách ghép tham số của config.
Xét config base của COCO:
# dataset settings
dataset_type = 'CocoDataset'
data_root = 'data/coco/'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
train=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_train2017.json',
img_prefix=data_root + 'train2017/',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_val2017.json',
img_prefix=data_root + 'val2017/',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_val2017.json',
img_prefix=data_root + 'val2017/',
pipeline=test_pipeline))
evaluation = dict(interval=1, metric='bbox')
Có khá là nhiều thứ trong này, nhưng mình sẽ lần lượt dẫn các bạn qua những thứ mà ta cần hiểu và quan tâm.
Bắt dầu với dataset_type. Đây sẽ là thứ định nghĩa chúng ta dùng dataset gì ở trong Registry của MMCV. Ta thấy dataset_type = 'CocoDataset. Ta cần tìm tới mmdetection/mmdet/datasets/coco.py có chứa class CocoDataset
@DATASETS.register_module()
class CocoDataset(CustomDataset):
...
Nhờ có dòng ma thuật @DATASETS.register_module() mà class CocoDataset được nằm trong Registry của MMCV.
Ủa nhưng lần này làm gì có __init__? Để ý thấy class CocoDataset được kế thừa từ CustomDataset, mở nơi chứa CustomDataset, ta sẽ thấy hàm __init__.
@DATASETS.register_module()
class CustomDataset(Dataset):
CLASSES = None
PALETTE = None
def __init__(self,
ann_file,
pipeline,
classes=None,
data_root=None,
img_prefix='',
seg_prefix=None,
proposal_file=None,
test_mode=False,
filter_empty_gt=True,
file_client_args=dict(backend='disk')):
Chúng ta cần phải truyền vào 2 tham số ann_file và pipeline. Nhớ lại cách tạo một class mình đã nói ở trên, tạo một Python dictionary với tham số tương ứng.
dataset_type = 'CocoDataset'
data_root = 'data/coco/'
data = dict(
...,
train=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_train2017.json',
img_prefix=data_root + 'train2017/',
pipeline=train_pipeline) #tạm thời cứ tạm bỏ qua thứ này đã, chút mình sẽ giải thích pipeline sau,
...
Với config ở trên, ta đã tạo một train dataset thuộc class CocoDataset với cách tổ chức folder dataset như sau:
|_data
|_coco
|_train2017
|_image(1).jpg
|_image(2).jpg
|_annotations
|_instances_train2017.json
Các bạn nên đọc comment trong source code để có thể hiểu ann_file, img_prefix,… là gì.
Tuy nhiên, mình muốn train model với một dataset có cách annotation như COCO, nhưng cách tổ chức folder, các class trong dataset cũng khác. Ví dụ, mình muốn train một dataset hoa quả gồm các class thuộc hoa quả, và có cách tổ chức folder như sau:
|_dataset
|_fruitCOCO
|_train
|_fruit(1).jpg
|_fruit(2).jpg
.
.
|_annotations.coco.json
Trong config của model bạn muốn train, thường sẽ có sẵn
_base_ = ['../_base_/datasets/coco_detection.py']
Giữ nguyên base config cho dataset từ coco_detection.py, ta sẽ chỉ thay đổi những thứ cần thay đổi trong file config của model ta muốn.
_base_ = ['../_base_/datasets/coco_detection.py'] # base config
# dataset settings
data_root = '../Dataset/FruitCOCO/' # thay đổi data_root
dataset_type = 'CocoDataset' # giữ nguyên dataset_type
classes = ["Apple", "Avocado", ...] # khai báo các class trong dataset
# chỉ cần ghi những thứ cần thay đổi so với base config
data = dict(
train=dict(
ann_file=data_root + 'train/_annotations.coco.json', # vị trí file annotation thay đổi
img_prefix=data_root + 'train/', # thay đổi folder chứa ảnh train
classes=classes # thêm kwargs classes
)
)
Để có thể hiểu rõ là những gì bạn cần thay đổi, và có thể truyền vào kwargs gì, nên đọc comment và source code của CustomDataset, thứ mà CocoDataset kế thừa.
Còn Dataset không theo tiêu chuẩn thì sao? Đây là một câu hỏi chắc là đặc biệt dành cho các dataset theo kiểu của YOLO, vì ngoài YOLO ra thì mình nghĩ chắc là k có ai có thể chế ra cái kiểu tổ chức dataset buồn cười như vậy được nữa. Lúc này, ta sẽ cần phải viết một class Dataset của bản thân, kế thừa lại CustomDataset, và viết lại hàm load_annotations.
@DATASETS.register_module()
class MyDataset(CustomDataset):
CLASSES = (...)
def load_annotations(self, ann_file):
"""Load annotation from annotation file."""
data_infos = [] # ta cần tạo ra một list chứa toàn bộ data_info của từng ảnh
... (Code xử lý logic)
data_infos.append(
dict(
filename=filename,
width=width,
height=height,
ann=dict(
bboxes=np.array(bboxes).astype(np.float32),
labels=np.array(labels).astype(np.int64))
))
return data_infos
data_infos phải là một list các dictionary, và dictionary này phải đủ các keys cần thiết để việc load data có thể được thực hiện. Các keys cần thiết này sẽ do các bạn, người viết class Dataset, tự định nghĩa, tuy nhiên nó nên có đủ các keys như mình đã viết ở phần code bên trên.
Tóm tắt lại về datasets và cách config dataset trong MMDetection:
- Nếu dataset của chúng ta có cách annotation giống như các datasets đã được viết sẵn trong MMDetection, chỉ cần thay đổi các tham số phù hợp như đường dẫn tới file/folder annotation, các class trong dataset của chúng ta, áp vào trong config là xong.
- Nếu dataset của chúng ta không hề có annotation giống như các datasets được viết sẵn trong MMDetection, tự tạo một class
Datasetcủa riêng bản thân, kế thừaCustomDataset, thêm nó vào registry thông qua@DATASETS.register_module(), viết lại hàmload_annotationstheo logic của bản thân.
Làm tương tự như vậy với validation dataset của các bạn, là ta đã config xong dataset rồi.
Training
Nếu chúng ta chỉ muốn sử dụng một model có sẵn trên tập dataset của chúng ta, thì chỉ cần chỉnh sửa dataset, và thêm một phần này trong config nữa là có thể tiến hành training được.
model = dict(
bbox_head=dict(
num_classes=x # ở đây, ta sẽ sửa 'x' là số class có trong dataset của các bạn
)
)
Ví dụ, ta muốn train model ATSS, với dataset fruit có annotation dạng COCO mà mình đã đề cập ở trên, ta sẽ tạo một file config mới ở trong mmdetection/configs/atss và đặt tên cho nó là cái gì cũng được, ở đây mình sẽ ví dụ là atss_test.py
Vì chúng ta chỉ thay đổi dataset mà không hề thay đổi models (trừ cái số class đầu ra trong head), ta sẽ kế thừa lại config đã được viết sẵn của ATSS như sau:
_base_ = ['./atss_r50_fpn_1x_coco.py'] # kế thừa lại toàn bộ configs được viết sẵn
# model settings
model = dict(
bbox_head=dict(
num_classes=x # ở đây, ta sẽ sửa 'x' là số class có trong dataset của các bạn
)
)
# dataset settings
data_root = '../Dataset/FruitCOCO/'
dataset_type = 'CocoDataset'
classes = [...]
data = dict(
samples_per_gpu=2, # batch size
train=dict(
ann_file=data_root + 'train/_annotations.coco.json', # vị trí file annotation thay đổi
img_prefix=data_root + 'train/', # thay đổi folder chứa ảnh train
classes=classes # thêm kwargs classes
),
val=dict(
ann_file=data_root + 'valid/_annotations.coco.json',
img_prefix=data_root + 'valid/',
classes=classes
)
)
Để thực hiện training, ta sẽ chỉ cần gõ dòng này vào command line:
python3 tools/train.py "configs/atss/atss_test.py"
với "configs/atss/atss_test.py" là đường dẫn tới file config của các bạn. Còn muốn hiểu rõ những tham số gì cần phải truyền vào tools/train.py, hãy vào mmdetection/tools/train.py để tìm hiểu.
Models
Đọc qua phần trên thì đa số mọi người sẽ thấy là nó không hề nhanh hơn những framework khác, thậm chí lại còn phải đọc về config để có thể biết cách training được. Nhưng phần này sẽ bộc lộ rõ sức mạnh tại sao mình lại thích MMDetection tới thế.
Ưu điểm lớn nhất trong phần này chính là số lượng pretrained models mà MMDetection đã cung cấp cho chúng ta. Hầu hết những gì chúng ta cần, đều đã được MMDetection làm sẵn, thậm chí cả những paper gần đây nhất như DDOD: Disentangle Your Dense Object Detector, ConvNeXt: A ConvNet for the 2020s,… Những phần dưới đây sẽ phụ thuộc về hiểu biết của các bạn khá là nhiều, nên các bạn hãy chuẩn bị chắc cho mình kiến thức khi muốn custom model trong MMDetection.
Backbone
Bình thường với các framework khác, hoặc chúng ta tự code, khi muốn thay đổi backbone thì ta sẽ phải tìm implementation của backbone đó, thêm các chỉnh sửa cần thiết trong source code cho phù hợp với mục đích của chúng ta, thay đổi code load model.
Trong MMDetection, khi ta muốn lắp một backbone mới, tất cả những gì ta cần làm là thay đổi configs.
Lấy ví dụ tiếp với ATSS. Backbone hiện tại của ATSS được config như sau:
model = dict(
type='ATSS',
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
style='pytorch',
init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
Đó là ResNet-50, với đầu ra ở block thứ [0, 1, 2, 3]. Đây là lúc bạn cần phải hiểu ResNet-50 là gì, đầu ra ở các block là như nào. Các bạn không muốn dùng ResNet-50 làm backbone nữa, bạn muốn dùng một ResNet vip pro hơn như ResNet-101 hoặc ResNet-152, cực kì đơn giản, chỉ cần thay đổi kwarg depth trong file config một cách hợp lý là bạn đã có một ResNet mới. Về các kwargs, các bạn hãy xem ở mmdetection/mmdet/models/backbone/resnet.py
Nhưng bạn không thích ResNet, bạn thích EfficientNet cơ. Lúc này, config của ta sẽ cần phải thay đổi như sau:
_base_ = [
'./atss_r50_fpn_1x_coco.py'
]
model = dict(
backbone=dict(
_delete_=True, # xóa toàn bộ config liên quan đến backbone ở trong _base_
type='EfficientNet' # thay thế kiến trúc thành EfficientNet
),
bbox_head=dict(
num_classes=64
)
)
Hold Up, vẫn chưa xong. Nếu bạn hí hửng cầm config này đi train, thì sẽ có lỗi như này xảy ra.
File ".mmdetectionmmdetmodelsnecksfpn.py", line 154, in forward
assert len(inputs) == len(self.in_channels)
AssertionError
Đây là lỗi đến từ Neck của model.
Model là một thể thống nhất bao gồm: Backbone – Neck – Head. Bạn không thể chỉ đơn giản thay đổi backbone mà không thay đổi Neck được. Nhìn lại config lấy từ _base_ của ATSS:
model = dict(
type='ATSS',
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
style='pytorch',
init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
start_level=1,
add_extra_convs='on_output',
num_outs=5),
Neck của ATSS là FPN (Feature Pyramid Network), nhận đầu vào là một list 4 tensor có số channel trong mỗi tensor là [256, 512, 1024, 2048] được thể hiện ở kwarg in_channels trong neck, chịu ảnh hưởng từ kwarg out_indices trong backbone và start_level trong FPN. Giải thích nhanh ở đây thì backbone ResNet-50 sẽ output ra một list 4 tensor với số channels tương ứng với số channels trong in_channels của FPN, nhưng khi xây dựng FPN thì lại bắt đầu từ start_level là 1, nên là chỉ 3 tensors cuối trong số list 4 tensor output từ ResNet thực sự được forward qua FPN, các bạn có thể xem kiến trúc nối Backbone – Neck của ATSS ở dưới để hiểu rõ hơn.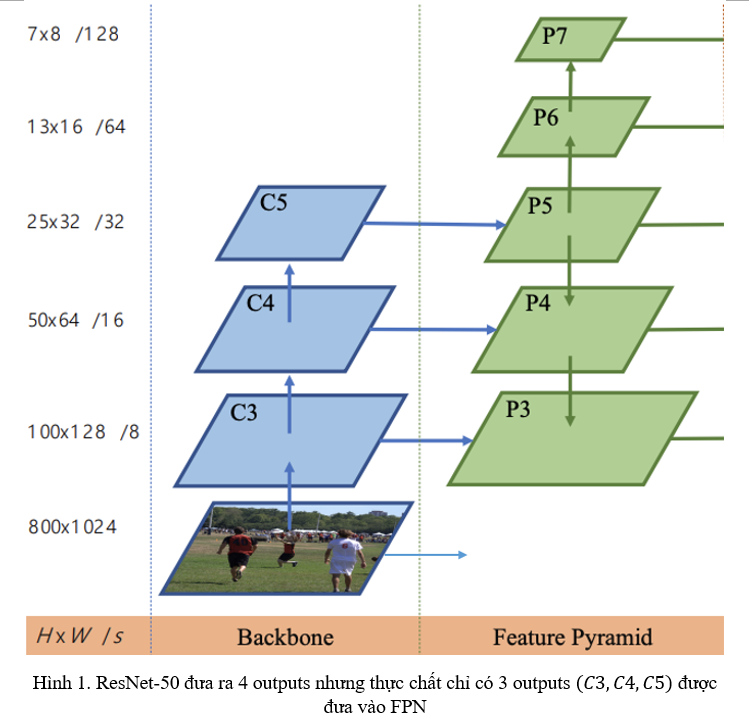
Hình trên cũng đã giải thích thêm một tham số khác trong config neck FPN là num_outs gồm 5 outputs từ P3−P7P3-P7.
Okay hơi dài dòng rồi, quay trở lại với backbone là EfficientNet, ta sẽ cần phải thay đổi config như sau:
model = dict(
backbone=dict(
_delete_=True,
type='EfficientNet',
out_indices=(4, 5, 6) # lấy 3 đầu ra từ backbone cho giống với hình trên, các bạn có thể
bao nhiêu cũng được, miễn là các bạn hiểu model hoạt động như nào
),
neck=dict(
in_channels=[112, 320, 1280], # vì 3 đầu ra có lượng channels tương ứng như này
start_level=0 # bắt đầu từ level 0 thay vì 1 vì chúng ta không lấy thừa 1 đầu ra như ở ResNet50
),
bbox_head=dict(
num_classes=64
)
)
Không cần phải thay đổi code model, hoặc code load model, tất cả chỉ cần thay đổi vài dòng config là ta có thể tạo ra một model mới cực kì nhanh.
Nhưng MMDetection không hỗ trợ nhiều backbone? Đừng lo, vì MMDetection phụ thuộc Registry vào MMCV. Chúng ta có thể mượn backbone từ Resgistry của MMCV, bao gồm cả MMClassification. Cách config backbone từ MMClassification hoặc timm mời các bạn xem ở đây: https://mmdetection.readthedocs.io/en/latest/tutorials/how_to.html#use-backbone-network-through-mmclassification
Head
Tiếp túc lại lôi ATSS ra làm ví dụ. Chẳng hạn bạn không muốn sử dụng kiến trúc Head ATSS gồm 3 nhánh là Classification, Regression và Centerness nữa, mà bạn muốn dùng Head từ YOLOX với kiến trúc 1 nhánh. Tiếp tục chỉnh sửa config model như sau:
model = dict(
backbone=dict(
_delete_=True,
type='EfficientNet',
out_indices=(4, 5, 6)
),
neck=dict(
in_channels=[112, 320, 1280],
start_level=0
),
bbox_head=dict(
_delete_=True,
type='YOLOXHead',
in_channels=256,
feat_channels=128,
num_classes=64
),
Các kwargs tạo nên YOLOXHead mời các bạn xem ở mmdetection/mmdet/models/dense_heads/yolox_head.py. Cầm config trên đi train, bạn sẽ tiếp tục gặp lỗi. Trong Object Detection, Head là bộ phận có nhiều ảnh hưởng nhất trong tất cả bộ phận, nó đảm nhiệm việc tính loss, label assignment. Vì vậy, nếu ta đổi Head, ta sẽ phải đổi cả Loss và Label Assignment nữa. May mắn thay là với YOLOXHead, default loss được tự config lại ở trong mmdetection/mmdet/models/dense_heads/yolox_head.py, nên ta chỉ phải sửa label assignment.
Config đầy đủ sẽ như sau:
model = dict(
backbone=dict(
_delete_=True,
type='EfficientNet',
out_indices=(4, 5, 6)
),
neck=dict(
in_channels=[112, 320, 1280],
start_level=0
),
bbox_head=dict(
_delete_=True,
type='YOLOXHead',
in_channels=256,
feat_channels=128,
num_classes=64
),
train_cfg=dict(
assigner=dict(
_delete_=True,
type='SimOTAAssigner',
center_radius=2.5
)
),
)
Vậy là bạn vừa tạo ra một model có backbone là EfficientNet, với 5 level FPN như ATSS nhưng head lại là của YOLOX và Label Assignment cũng của YOLOX, tất cả chỉ thông qua việc chỉnh sửa config
Neck, Losses
Cách config cho Neck và Losses của Model cũng tương tự như Backbone với Head mình đã nói ở trên. Hãy hiểu rằng các bạn đang làm gì, thay đổi của các bạn có những ảnh hưởng gì và viết nó vào config thôi.
Kết
Bên trên là giới thiệu sơ qua về MMDetecton, cũng như là cách làm việc với file config để tạo ra một model của riêng bản thân. Hy vọng các bạn đọc sẽ thấy đây là một thư viện thú vị để áp dụng cho những thử nghiệm của riêng bản thân mình, tăng tốc các thử nghiệm Object Detection, hoặc thậm chí là sử dụng những thư viện khác cũng được phát triển bởi OpenMMLab
Nguồn: viblo.asia