Lời mở đầu
Xin chào tất cả mọi người, thời gian gần đây mình có tìm hiểu về Contrastive Learning và mình có dạo một vòng google thì số lượng bài viết chia sẻ về chủ đề này còn khá hạn chế nên hôm nay mình mạn phép đóng góp một bài viết về chủ đề này, mong nhận được sự ủng hộ và góp ý từ tất cả các bạn. Bài viết với mục đích chia sẻ tới các bạn một cái nhìn tổng quan về bài toán Contrastive Learning cho các bạn muốn tìm hiểu về chủ đề này có thể tiếp cận một cách dễ dàng hơn
Contrastive learning là gì ?
Ý tưởng chính của Contrastive learning là tìm ra các cặp đặc trưng của dữ liệu có tính tương đồng – tương phản nhau trong bộ dataset. Từ đó, với những cặp dữ liệu mang tính tương đồng ta có thể “kéo” chúng lại gần để học được những đặc trưng cấp cao hơn của nhau, và ngược lại với những cặp những liệu tương phản sẽ bị “đẩy” ra xa. Để làm được điều này, ta sẽ cần sử dụng các similarity metric để tính toán khoảng cách giữa các embedding vector biểu diễn các điểm dữ liệu với nhau. Ví dụ, ta đã có 1 điểm dữ liệu gốc gọi là anchor, sau đó có thể dùng thêm các kỹ thuật augmentation khác nhau để có thêm 1 biến thể từ anchor gốc gọi là positive sample, và phần còn lại của batch / dataset sẽ được coi là negative sample. Sau đó model sẽ được train để có thể phân biệt được positive sample với negative sample từ 1 cụm dữ liệu.

Nghe có vẻ hơi trừu tượng nhỉ ? Lấy một ví dụ đơn giản như thế này nhé. Con người chúng ta có thể dễ dàng phân biệt được các vật thể khác nhau từ khi còn bé ( thậm chí là sơ sinh), và những vật thể đấy sau này sẽ được người lớn “gán nhãn”. Vậy tại sao chúng ta lại có thể phân biệt được các vật thể đấy từ lần nhìn đầu tiên ? Bởi vì não bộ của chúng ta có thể nhận biết được những đặc điểm, đặc trưng khác biệt nhất của một vật thể hay còn gọi là đặc trưng bậc cao, và đem so sánh những đặc trưng đấy với “dữ liệu” có sẵn trong não bộ để có thể phân biệt được những vật thể giống – khác loại ( loài ). Chỉ cần nhận ra những điểm tương đồng và khác biệt giữa vật khác nhau, bộ não có thể học được các đặc điểm cấp cao của các đối tượng trong thế giới của chúng ta. Ví dụ, chúng ta có thể nhận ra một cách vô thức rằng hai con mèo ở ảnh trên có đôi tai nhọn, trong khi con chó có đôi tai cụp xuống. Hoặc chúng ta có thể đối chiếu chiếc mũi nhô ra của chó với mặt phẳng của mèo. Về cơ bản thì contrastive learning cũng cho phép model của chúng ta làm điều tương tự, mục tiêu của phương pháp là đối chiếu sự tương phản giữa embedding của các phiên bản biến đổi của cùng một sample để học các đặc trưng bất biến của nó trong khi vẫn phân biệt được embedding của các sample khác.
Tại sao Contrastive learning lại được coi là một phương pháp cực kỳ mạnh mẽ và càng ngày càng phổ biến ?
Các phương pháp supervised learning truyền thống phụ thuộc rất nhiều vào lượng dữ liệu đã được gán nhãn sẵn trong khi lượng data chưa được gán nhãn là vô cùng khổng lồ. Mặc dù số dataset đã có nhãn là rất lớn nhưng với sự gia tăng mạnh mẽ của nhu cầu về lượng dữ liệu cũng như các bài toán mới thì số dataset đấy là hoàn toàn không đủ. Nhất là với những bài toán cần gán nhãn chính xác đến từng pixel như semantic segmentation thì đây là việc vô cùng tốn công sức và thời gian. Và từ đấy các phương pháp học self/semi – supervised learning lên ngôi. Với các kỹ thuật self-supervised learning thì chúng ta có thể train để model học rất tốt từ data chưa được gán nhãn và self – supervised learning được áp dụng khá phổ biến với 2 hướng đi : GANs và Contrastive learning. Trong vài năm qua, các phương pháp self – supervised learning tốt nhất đã dần dần chuyển từ pretext task learning như rotation, colorization và jigsaw puzzling sang contrastive learning và xu hướng này đang ngày càng được củng cố nhờ việc có nhiều hơn những nghiên cứu mang tính đột phá trong computer vision với contrastive learning.
Cách thực hiện của Contrastive Representation Learning

Pipeline thực hiện của contrastive learning (nguồn: Advancing Self-Supervised and Semi-Supervised Learning with SimCLR)
Về pipeline thực hiện của contrastive learning thì mình sẽ diễn đạt theo hướng của bài A Simple Framework for Contrastive Learning of Visual Representations, vì hướng này là hướng chính của contrastive learning và khá dễ hiểu đồng thời mình cũng tìm được 1 implementation khá đơn giản của bài báo, các bạn có thể xem ở cuối bài viết 😉. Các bước thực hiện như sau :
- Data Augmentation
- Encoder
- Projection head
- Loss function
1. Data augmentation
Data augmentation là 1 phần khá quan trọng trong các mô hình contrastive learning và gần như là không thể thiếu được. Trong bài SoTA SImCLR của nhóm tác giả đến từ Google Research, người ta đã dành hẳn 1 chương để nói về data augmentation và tầm quan trọng của nó đối với contrastive learning :Composition of data augmentation operations is crucial for learning good representations và Contrastive learning needs stronger data augmentation than supervised learning. Nếu data augmentation không đủ phức tạp thì gradient sẽ không đủ tốt để model có thể học các đặc trưng trong dữ liệu và ngược lại. Các tác giả chủ yếu sử dụng tuần tự 3 loại augment : random crop, random color distortions, và random Gaussian blur. Và nhận ra rằng random crop và color distortion là khá quan trọng để model đạt được kết quả tốt. Nhưng nếu chỉ sử dụng riêng rẽ 1 loại biến đổi thì sẽ không cho ra kết quả vượt trội, chỉ khi kết hợp 2 loại biến đổi với nhau thì kết quả mới đạt tới ” state-of-the-art “.

2. Encoder
Thông thường, encoder là 1 mạng CNN có nhiệm vụ map các đầu vào là ảnh thành các embedding vector làm đầu vào cho contrastive loss. Nếu mạng encoder trích xuất đặc trưng không đủ tốt thì model sẽ rất khó để học đươc cách phân biệt các đặc điểm có trong 1 điểm dữ liệu. Đa số mạng encoder được sử dụng hiện nay là Resnet và biến thể của nó, trong số đó thì có lẽ Resnet-50 là biến thể được các nhà nghiên cứu sử dụng nhiều nhất vì tính cân bằng giữa kích thước và hiệu suất của mô hình.
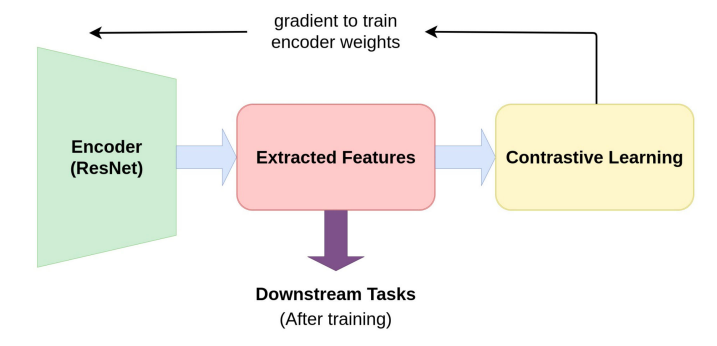
Để model encoder học được các đặc điểm của vật thể với hướng đi của self-supervised thì phải trải qua pretext task ( sẽ được nói ở phần sau ) sau khi được huấn luyện qua với pretext task thì model sẽ có khả năng trích xuất các đặc trưng tốt hơn, đồng thời có thể kiêm thêm downstream task. Một số model thuộc lĩnh vực unsupervised learning thậm chí còn có thể “outperform” các model SoTA của supervised learning, tiêu biểu như MoCo của Facebook hay SimCLR của Google. Điều này có nghĩa là các nhà nghiên cứu đã dần thu hẹp được khoảng cách giữa unsupervised và supervised representation learning trong một số task computer vision.
3. Projection Head
Sau khi data đi qua khối encoder thì sẽ được tính toán với projection head được cấu thành từ các fully-connected layer để cho ra output là 1 embedding vector biểu diễn cho ảnh ở đầu vào. Mạng này có tác dụng khuếch đại các đặc trưng bất biến của dữ liệu từ đó tối đa hóa khả năng phân biệt các phép biến đổi từ cùng 1 bức ảnh của mạng.
4. Loss function
Một điều cuối cùng không thể thiếu đó chính là hàm loss, hàm loss được sử dụng ở trong bài báo SimCLR được gọi là NT-Xent (normalized temperature-scaled cross entropy loss). Đầu tiên, người ta lấy mẫu ngẫu nhiên một minibatch gồm NN điểm dữ liệu và áp dụng 2 phép data augmentation khác nhau tạo thành 2N2N điểm :
x~i=t(x),x~j=t′(x),t,t′∼Ttilde{mathbf{x}}_i = t(mathbf{x}),quadtilde{mathbf{x}}_j = t'(mathbf{x}),quad t, t’ sim mathcal{T}
Giả sử có 1 cặp dữ liệu positive, 2(N−1)2(N-1) điểm còn lại được coi là các điểm negative. Xác định vector biểu diễn được tạo bởi encoder f(.)f(.) :
hi=f(x~i),hj=f(x~j)mathbf{h}_i = f(tilde{mathbf{x}}_i),quad mathbf{h}_j = f(tilde{mathbf{x}}_j)
Hàm loss sẽ được tính toán dựa trên vector biểu diễn được tạo bởi projection head g(.)g(.). Gọi sim(u,v)=uTv/∥u∥∥v∥operatorname { sim } ( u , v ) = u ^ { T } v / | u | | v | là hàm cosine similarity của 2 vector đã được chuẩn hóa ℓ2ell _ { 2 } norm u,vu,v, khi đó hàm loss cho 1 cặp dữ liệu positive (i,j)(i, j) được định nghĩa như sau :
zi=g(hi),zj=g(hj)LSimCLR(i,j)=−logexp(sim(zi,zj)/τ)∑k=12N1[k≠i]exp(sim(zi,zk)/τ)begin{aligned}
mathbf{z}_i &= g(mathbf{h}_i),quad
mathbf{z}_j = g(mathbf{h}_j) \
mathcal{L}_text{SimCLR}^{(i,j)} &= – logfrac{exp(text{sim}(mathbf{z}_i, mathbf{z}_j) / tau)}{sum_{k=1}^{2N} mathbb{1}_{[k neq i]} exp(text{sim}(mathbf{z}_i, mathbf{z}_k) / tau)}
end{aligned}
Trong đó 1[k≠i]={1k≠i0coˋn lạimathbb{1}_{[k neq i]}=
begin{cases}
1 &kneq i \
0 &text{còn lại}
end{cases}
5. Pretext task
Pretext task chính là self-supervised task với nhiệm vụ huấn luyện để model học được các đặc trưng với dữ liệu chưa được đánh nhãn, với các phương pháp thông thường thì các điểm dữ liệu sẽ được gán nhãn giả bằng cách: biến đổi ảnh gốc dựa trên các phép data augmentation (augmented data) làm input cho model và output sẽ là ảnh gốc đấy. Tức là chúng ta sẽ để model học được cách khôi phục ảnh gốc dựa trên các bức ảnh đã bị biến đổi. Mục tiêu của pretext task thông thường khác pretext task của contrastive learning – contrastive prediction task ở chỗ pretext task sẽ cố gắng khôi phục lại ảnh cũ từ ảnh đã biến đổi, còn contrastive prediction task sẽ cố gắng học những đặc trưng bất biến của ảnh gốc từ ảnh đã biến đổi trong khi vẫn phân biệt được với các ảnh negative khác trong batch. Model đã được huấn luyện qua pretext task có thể được sử dụng ở các nhiệm vụ khác như fine-tune với các bộ dataset đã gán nhán để thực hiện các downstream task. Có 4 loại pretext task thường được dùng đó là : color transformation, geometric transformation, context-based tasks, và cross-modal-based tasks.
6. Downstream task
Downstream task nói nôm na chính là việc chúng ta tận dụng các kiến thức model đã được học qua pretext task để sử dụng chúng vào một mục đích cụ thể nào đó. Model đã được pretrain ở pretext task chứa những trọng số giàu thông tin và hoàn toàn có thể được sử dụng với những bài toán thích hợp khác thông qua kỹ thuật fine-tune model hay tổng thể được gọi là transfer learning. Kết quả của transfer learning với những task có level cao hơn kia sẽ miêu tả khả năng tổng quát hóa của các đặc trưng đã được học. Một số downstream task thường được biết đến là clasification, detection, segmentation, future prediction. Việc sử dụng một hay nhiều trong các task đã được liệt kê cũng có thể coi là đang kiểm thử và đánh giá hiệu quả của model.
Để đánh giá các đặc trưng đã được học của hướng self-supervised cho các downstream task, người ta thường sử dụng các phương pháp như kernel visualization, feature map visualization, và nearest-neighbor-based. Những phương pháp này cũng hỗ trợ việc phân tích hiệu quả của pretext task trong training model
7. Các dạng kiến trúc khác
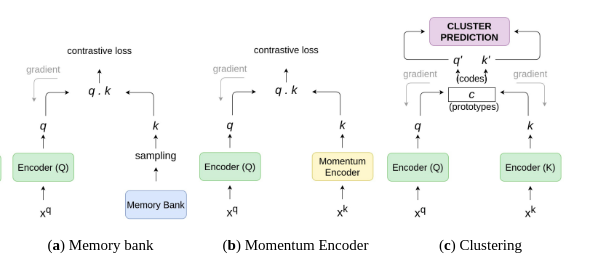
Coi 1 ảnh anchor đã được encode là query qq và 1 tập các sample đã được encode là {k0,k1,k2,…{k_0, k_1, k_2,…}}, tập này ta coi là key của 1 bộ dictionary. Giả sử trong dictionary có khóa k+k_+ trùng với query qq. Vậy thì hàm contrastive loss sẽ là hàm tính toán ra giá trị thấp nếu qq giống với positive key k+k_+ và khác với tất cả key còn lại (coi những key này là negative với qq). Như vậy là người ta đã mô hình hóa contrastive learning thành bài toán đi tìm key trong 1 bộ dictionary gồm rất nhiều key khác nhau được lưu trữ dưới dạng hàng đợi và kích thước của dictionary phải lớn hơn mini-batch size rất nhiều.
7.1 Memory bank
Với SimCLR, người ta đã chứng minh được training với batch size càng lớn thì kết quả đạt được càng tốt và các nhà nghiên cứu của google đã cho ra kết quả SoTA với batch size 4096 trong 100 epoch. Cơ sở cho kết luận này nằm ở số lượng negative sample có trong 1 batch và hiển nhiên là batch size càng lớn thì số negative sample càng nhiều. Nhưng điều này lại có 1 vài bất lợi đó là quá trình training khá tốn tài nguyên và batch size lớn cũng có thể ảnh hưởng đến hàm tối ưu hóa, từ đó người ta đưa ra 1 giải pháp khắc phục đó là duy trì một bộ dictionary gọi là Memory Bank.
Mục tiêu chính của memory bank là tích lũy số lượng lớn các đặc trưng biểu diễn của negative sample trong suốt quá trình training thông qua việc sử dụng một bộ dictionary để lưu trữ và đồng thời update liên tục các embedding vector mới nhất. Tuy nhiên, việc duy trì memory bank cũng gặp 1 số bất lợi, một trong số đó chính là khối lượng tính toán khá lớn khi phải update các vector biểu diễn trong memory bank liên tục bởi vì các vector biểu diễn này lỗi thời khá nhanh.
7.2 Momentum encoder
Sử dụng hàng đợi không chỉ khiến dictionary lớn mà còn khiến key encoder khó cập nhật thông qua back-propagation (gradient sẽ phải được lan truyền đến tất cả các sample trong hàng đợi). Để giải quyết vấn đề đã nêu, người ta đề xuất copy luôn gradient từ query encoder fqf_q cho key encoder fkf_k, nhưng hướng đi này lại cho kết quả khá tệ, nguyên nhân có thể là do việc thay đổi gradient quá nhanh đã làm giảm tính nhất quán của key encoder. Vì thế người ta đã đề xuất phương pháp momentum update để giải quyết vấn đề này:
Coi các tham số của fkf_k là θktheta_k và của fqf_q là θqtheta_q. θktheta_k sẽ được update với công thức sau:
θk←mθk+(1−m)θq.theta_{k}leftarrow mtheta_{k}+(1-m)theta_{q}.
Với m∈[0,1)m in [ 0,1 ) là hệ số momentum, và chỉ có θqtheta_q là được cập nhật thông qua back-propagation. Momentum update sẽ giúp θktheta_k được cập nhật trơn tru hơn θqtheta_q. Lợi thế của việc sử dụng phương pháp này là không cần phải traing 2 model riêng biệt, đồng thời cũng không cần giữ lại memory bank tránh khối lượng tính toán lớn và tốn nhiều tài nguyên.
7.3 Clustering Feature Representations
Hai kiến trúc kể trên đều tập trung vào hướng so sánh các sample sử dụng similarity metric và cố gắng kéo các sample giống nhau lại gần, đẩy các sample khác nhau ra xa. Nhưng kiến trúc ở phần này lại đi ngược với 2 hướng kể trên, người ta đi theo hướng end-to-end với 2 encoders chia sẻ trọng số với nhau, nhưng thay vì đi theo hướng contrastive thì họ sử dụng thuật toán phân cụm để nhóm các đặc trưng giống nhau lại. Mục đích của việc này không chỉ là để kéo 1 cặp sample lại với nhau mà còn đảm bảo được việc tất cả các sample tương tự với nhau được phân vào 1 cụm với nhau. Ví dụ trong không gian embedding của 1 tập đa dạng các loại ảnh, các đặc trưng của mèo sẽ đuợc kéo lại gần với của chó (cùng là con vật) và đẩy ra xa với của nhà. Một trong những nghiên cứu được đề xuất gần đây ứng dụng phương pháp phân cụm nói trên chính là SwAV:
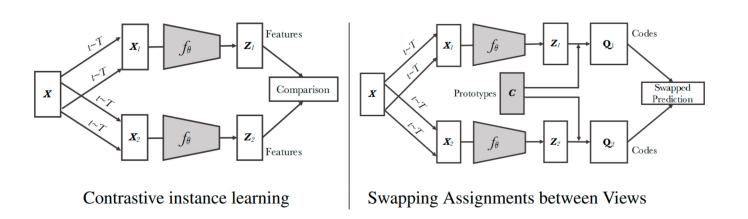
Với contrastive learning thông thường, mỗi sample sẽ được coi là 1 class riêng trong dataset, điều này trở nên mâu thuẫn khi có một ảnh thuộc về negative sample nhưng lại cùng lớp với ảnh gốc, trường hợp này được coi là false negative. Ví dụ như chúng ta có ảnh 1 con mèo làm gốc và các ảnh khác trong batch sẽ được gọi là negative, vấn đề sẽ xảy ra khi trong số đấy có ảnh của 1 hay vài con mèo nữa. Trong trường hợp này, model bắt buộc phải học rằng 2 bức ảnh của 2 con mèo là khác nhau trong khi chúng lại thuộc về cùng 1 class và có thể gây ra “degradation” – suy thoái đối với chất lượng vector biểu diễn. Vấn đề này được giải quyết ngầm bằng cách tiếp cận dựa trên phân cụm.
Supervised Contrastive Learning
Trong paper “ Supervised Contrastive Learning” được trình bày tại NeurIPS 2020, các nhà nghiên cứu đã đề xuất một hàm loss gọi là SupCon – Supervised Contrastive Loss, nhằm thu hẹp khoảng cách vô hình giữa self-supervised learning và fully-supervised learning và cho phép contrastive learning có thể được ứng dụng với các bài toán supervised learning. Vẫn giữ nguyên ý tưởng của contrastive learning, hàm SupCon sẽ cố gắng tận dụng dữ liệu được gán nhãn để kéo các embedding vector đã được chuẩn hóa của cùng 1 class lại gần nhau và ngược lại đối với những embedding vector khác class. Việc có thêm dữ liệu được gán nhãn sẽ làm đơn giản hóa quá trình chọn positive sample và tránh được các trường hợp false negative
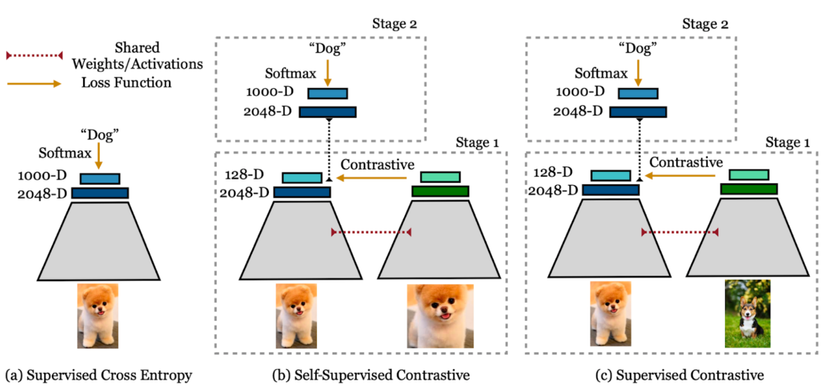
Cross-entropy, self-supervised contrastive loss và supervised contrastive loss. Trái: Cross-entropy loss sử udngj nhãn là hàm softmax loss để huấn luyện 1 bộ classifier. Giữa: Self-supervised contrastive loss sử dụng hàm contrastive loss và data augmentation để học các đặc trưng biểu diễn. Phải: Hàm supervised contrastive loss cũng học các đặc trưng biểu diễn thông qua contrastive loss nhưng có sử dụng thêm thông tin từ nhãn của dữ liệu để lấy mẫu positive (các bức ảnh cùng lớp với anchor) ngoài dữ liệu augmentation của 1 bức ảnh.
Supervised contrastive loss
Giả sử có 1 tập nn cặp dữ liệu (ảnh, nhãn) training {xi,yi}i=1n{mathbf{x}_i, y_i}_{i=1}^n, từ đó ta có thêm nn cặp dữ liệu thông qua 2 phép augmentation với mỗi mẫu đã cho {x~i,y~i}i=12n{tilde{mathbf{x}}_i, tilde{y}_i}_{i=1}^{2n}. Hàm supervised contrastive loss Lsupconmathcal{L}_text{supcon} sẽ tận dụng nhiều positive và negative sample:
Lsupcon=−∑i=12n12∣Ni∣−1∑j∈N(yi),j≠ilogexp(zi⋅zj/τ)∑k∈I,k≠iexp(zi⋅zk/τ)mathcal{L}_text{supcon} = – sum_{i=1}^{2n} frac{1}{2 vert N_i vert – 1} sum_{j in N(y_i), j neq i} log frac{exp(mathbf{z}_i cdot mathbf{z}_j / tau)}{sum_{k in I, k neq i}exp({mathbf{z}_i cdot mathbf{z}_k / tau})}
Trong đó zk=P(E(xk~))mathbf{z}_k=P(E(tilde{mathbf{x}_k})), E(.)E(.) là 1 mạng encoder, P(.)P(.) là projection head. Ni={j∈I:y~j=y~i}N_i= {j in I: tilde{y}_j = tilde{y}_i } chứa 1 tập các chỉ số của các mẫu với nhãn yiy_i, càng có nhiều positive sample trong tập NiN_i thì kết quả càng được cải thiện
Supervised contrastive learning framework
Về cơ bản thì phương pháp này có cấu trúc tương tự với phương pháp được sử dụng trong self-supervised contrastive learning nhưng có thêm điều chỉnh cho tác vụ supervised classification. Với một batch dữ liệu, chúng ta sẽ tiến hành áp dụng data augmentation 2 lần để có 2 bản copy của mỗi sample trong batch. Cả 2 bản sẽ được forward qua encoder để lấy embedding vector và sau đó được chuẩn hóa L2L2 rồi đưa qua projection head. Supervised contrastive loss sẽ được tính toán với vector đã được chuẩn hóa ở đầu ra của projection head. Các positive sample sẽ là phiên bản augmentation của anchor cùng với sample cùng class với anchor trong cả 2 batch và negative sample chính là phần còn lại.
Lời kết
Mặc dù thoạt nhìn, contrastive learning có vẻ dễ dàng nhưng việc khiến chúng học cách biểu diễn đầu vào có ý nghĩa là điều khá khó khăn. Hướng đi này cũng còn rất nhiều tiềm năng để khai thác, hi vọng chúng ta sẽ thấy nhiều bài nghiên cứu mang kết quả đột phá hơn nữa trong tương lai. Bài viết đến đây cũng đã dài, trong quá trình đọc có thấy sai sót mong mọi người tích cực góp ý để mình cải thiện hơn ở các bài viết sau. Nếu thấy bài hữu ích có thể tặng mình một Upvote cho mình có thêm động lực để chuẩn bị cho một số bài viết khác sắp tới.
Cảm ơn mọi người đã ủng hộ !
Code
Phần code chính thống của bài báo SimCLR các bạn có thể tham khảo ở đây nhé : Official work
Còn đây là một phiên bản implementation đơn giản hơn của nó: simple implementation
Reference
- A Simple Framework for Contrastive Learning of Visual Representations
- Supervised Contrastive Learning
- Contrastive Representation Learning
- Extending Contrastive Learning to the Supervised Setting
- Unsupervised Learning of Visual Features
by Contrasting Cluster Assignments - Momentum Contrast for Unsupervised Visual Representation Learning
- A Survey on Contrastive Self-supervised Learning
- Understanding Contrastive Learning
Nguồn: viblo.asia