Hướng dẫn này là một ví dụ nhỏ hướng dẫn mọi người về cách xử lý dữ liệu thời gian thực bằng cách sử dụng Kafka Stream với Spring Boot.
Trước đây, chúng ta thường thu thập dữ liệu, lưu trữ trong cơ sở dữ liệu và xử lý dữ liệu hàng đêm. Nó được gọi là xử lý batch processing! Trong kỷ nguyên Microservices này, chúng ta nhận được luồng dữ liệu liên tục, đôi khi việc trì hoãn việc xử lý dữ liệu này có thể gây ảnh hưởng nghiêm trọng đến hoạt động kinh doanh của chúng ta. Ví dụ: Hãy xem xét một ứng dụng như Netflix / YouTube. Dựa trên bộ phim hoặc video chúng ta xem, các ứng dụng này hiển thị các đề xuất về những video hay bộ phim cùng chủ đề chúng ta đang xem ngay lập tức. Nó cung cấp trải nghiệm người dùng tốt hơn nhiều và giúp cho việc kinh doanh từ đó tốt hơn.
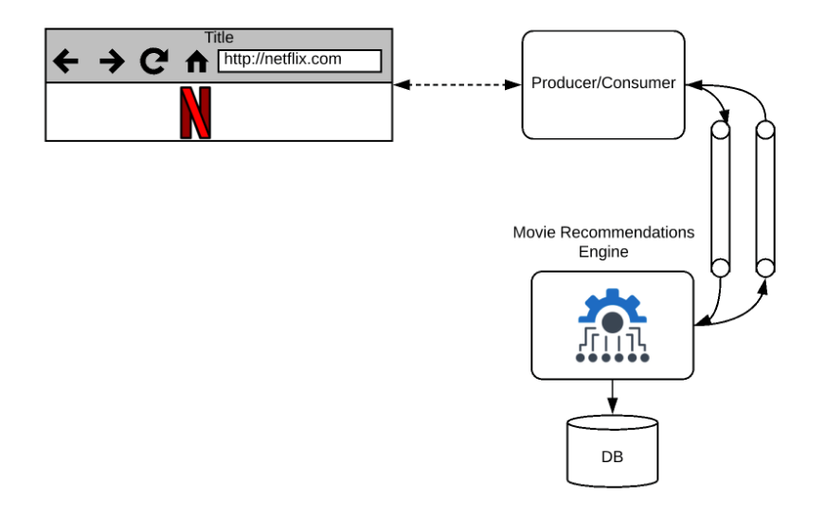
Stream processing là quá trình xử lý dữ liệu liên tục theo thời gian thực. Hãy xem cách chúng ta có thể xử lý luồng thời gian thực đơn giản bằng cách sử dụng Kafka Stream với Spring Boot.
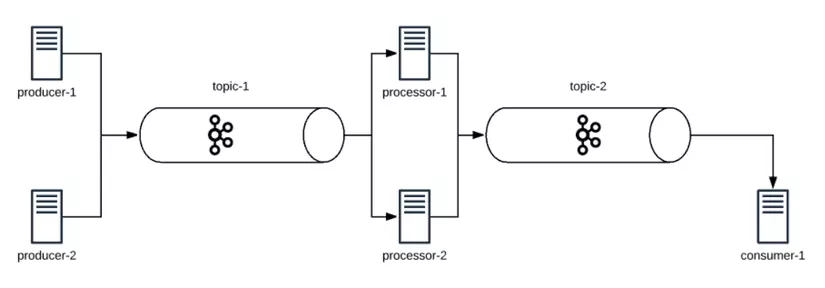
Để demo xử lý luồng dữ liệu theo thời gian thực này, Chúng ta hãy xem xét một ứng dụng đơn giản có chứa 3 microservices.
- Producer: Microservice này tạo ra một số dữ liệu. Trong thế giới thực, Producer có thể là trình duyệt / ứng dụng ngân hàng. Một số hành động của người dùng sẽ gửi lịch sử lướt phim / giao dịch thẻ tín dụng,… đến Consumer cần thu thập dữ liệu. Trong ví dụ này chúng ta sẽ tạo các số tuần tự từ 1 đến N trong mỗi giây và gửi dữ liệu đi.
- Processor: Microservice này sử dụng dữ liệu, thực hiện một số xử lý trên dữ liệu và gửi tiếp dữ liệu đến một topic khác. Trong thế giới thực, đây có thể là dịch vụ đề xuất phim cho Netflix. Trong ví dụ này, chúng ta sẽ bỏ qua tất cả các số lẻ và tìm bình phương của các số chẵn.
- Consumer: Microservice này sử dụng dữ liệu đã xử lý từ Processor. Trong thế giới thực, đây có thể là trình duyệt của chúng ta để nhận các đề xuất mới nhất dựa trên quá trình duyệt phim. Trong ví dụ này, chúng ta sẽ sử dụng dữ liệu và in nó trên console.
Producer, Processor và Consumer là 3 ứng dụng khác nhau được kết nối qua 2 chủ đề (topic) Kafka khác nhau như hình bên dưới:
Set up Kafka
Theo hướng dẫn ở bài viết Install Kafka cluter on local. Chúng ta tạo ra 2 topic:
- numbers (Topic 1 / Source topic)
- squaredNumbers (Topic 2 / Sink topic)
Java Functional Interface
Spring Cloud Functions đơn giản hóa việc phát triển ứng dụng này bằng cách sử dụng các Functional Interface bên dưới.
| Application Type | Java Functional Interface |
|---|---|
| Kafka Producer | Supplier |
| Kafka Processor | Function |
| Kafka Consumer | Consumer |
Kafka Stream Proceder
Việc sử dụng Kafka Stream với Spring Boot dễ dàng hơn việc manual cấu hình. Spring Boot thực hiện hầu hết tất cả các công việc cấu hình một cách tự động. Chúng ta tạo một Bean đơn giản để tạo ra một số tuần tự mỗi giây.
- Nếu loại Bean này là Supplier, Spring Boot sẽ coi nó như một Producer.
- Chúng ta sử dụng Flux vì nó sẽ là một luồng dữ liệu liên tục (data stream)
@Configuration
public class KafkaProducer {
/*
* produce a number from 1, every second
* Supplier<T> makes this as kafka producer of T
* */
@Bean
public Supplier<Flux<Long>> numberProducer(){
return () -> Flux.range(1, 1000)
.map(i -> (long) i)
.delayElements(Duration.ofSeconds(1));
};
}
Bây giờ câu hỏi quan trọng là dữ liệu sẽ được ghi vào đâu? Ở phần đầu chúng ta đã tạo một topic cho điều này – numbers. Chúng ta cấu hình điều đó thông qua application.yaml như hình dưới đây.
- spring.cloud.stream.functions.definition: nơi chúng ta cung cấp danh sách các tên Bean (được phân tách bởi dấy
 .
. - spring.cloud.stream.bindings.numberProductioner-out-0.destination: cấu hình nơi dữ liệu đến! out chỉ ra rằng nơi mà Spring Boot ghi dữ liệu vào chủ đề Kafka. Ngược lại, để đọc dữ liệu, chỉ cần sử dụng in.
- spring.cloud.stream.bindings.numberProductioner-out-0.producer.use-native-encoding : Serialization/deserialization.
- spring.cloud.stream.kafka.bindings.numberProductioner-out- 0.producer.configuration.value: Serialization/deserialization.
- Sau đó, chúng ta cấu hình địa chỉ kafka brocker (hay kafka server).
spring.cloud.stream:
function:
definition: numberProducer
bindings:
numberProducer-out-0:
destination: numbers
producer:
use-native-encoding: true
kafka:
bindings:
numberProducer-out-0:
producer:
configuration:
value:
serializer: org.apache.kafka.common.serialization.LongSerializer
binder:
brokers:
- localhost:9091
- localhost:9092
Kafka Stream Processor
Processor vừa là Producer vừa là Consumer. Nó sử dụng dữ liệu từ 1 topic và tạo ra dữ liệu mới và gửi cho topic khác. Trong trường hợp của chúng ta:
- Chúng ta sẽ nhận dữ liệu từ topic numbers
- Loại bỏ các số lẻ
- Bình phương các số chẵn
- Cuối cùng là gửi chúng đến một topic khác.
Chúng ta tạo Processor bằng cách sử dụng Functional Interface tương ứng trong Java là Function<T, R>.
- Chúng ta sử dụng dữ liệu đầu vào là KStream<String, Long> .
- Chúng ta thực hiện một số xử lý.
- Sau đó, chúng ta trả về kiểu dữ liệu KStream<String, Long>.
Lưu ý rằng kiểu trả về có thể là bất cứ kiểu dữ liệu gì. Không nhất thiết phải giống với loại dữ liệu đầu vào.
@Configuration
public class KafkaProcessor {
/*
* process the numbers received via kafka topic
* Function<T, R> makes this as kafka stream processor
* T is input type
* R is output type
*
* */
@Bean
public Function<KStream<String, Long>, KStream<String, Long>> evenNumberSquareProcessor(){
return kStream -> kStream
.filter((k, v) -> v % 2 == 0)
.peek((k, v) -> System.out.println("Squaring Even : " + v))
.mapValues(v -> v * v);
};
}
Trong file application.yaml chúng ta sử dụng từ khóa in để thu tập dữ liệu đầu vào, và sử dụng từ khóa out để ghi dữ liệu đầu ta.
spring.cloud.stream:
function:
definition: evenNumberSquareProcessor
bindings:
evenNumberSquareProcessor-in-0:
destination: numbers
evenNumberSquareProcessor-out-0:
destination: squaredNumbers
kafka:
binder:
brokers:
- localhost:9091
- localhost:9092
Kafka Stream Consumer
Trong ví dụ này, những bước chúng ta cần làm để thu thập (consume) dữ liệu là:
- Tạo một Bean loại Consumer để sử dụng dữ liệu từ một topic.
- KStream<String, Long>: Key có kiểu dữ liệu String, và Value có kiểu giá trị là Long. Là kiểu dữ liệu được gửi đến topic (dữ liệu đầu vào).
@Configuration
public class KafkaConsumer {
/*
* consume the numbers received via kafka topic
* Consumer<T> makes this as kafka consumer of T
* */
@Bean
public Consumer<KStream<String, Long>> squaredNumberConsumer(){
return stream -> stream.foreach((key, value) -> System.out.println("Square Number Consumed : " + value));
};
}
Trong file application.yaml.
- Chúng ta cập nhật tên Bean của spring cloud function bean name
- Chúng ta giả định rằng chủ đề squaredNumbers đã được tạo và chúng ta sử dụng dữ liệu từ topic.
- Để sử dụng dữ liệu chúng ta sử dụng từ khóa in.
spring.cloud.stream:
function:
definition: squaredNumberConsumer
bindings:
squaredNumberConsumer-in-0:
destination: squaredNumbers
kafka:
binder:
brokers:
- localhost:9091
- localhost:9092
Kafka Stream Processing
Kết quả:
Processer
Squaring Even : 2
Squaring Even : 4
Squaring Even : 6
Squaring Even : 8
Squaring Even : 10
Squaring Even : 12
Squaring Even : 14
Consumer
Square Number Consumed : 4
Square Number Consumed : 16
Square Number Consumed : 36
Square Number Consumed : 64
Square Number Consumed : 100
Square Number Consumed : 144
Square Number Consumed : 196
Tổng kết
Trên đây, chúng ta vừa khám phá ví dụ khả năng xử lý dữ liệu thời gian thực bằng cách sử dụng Kafka Stream với Spring Boot. Hy vọng mọi người sẽ hiểu được ý tưởng tổng thể của bài viết để có thể áp dụng nó vào dự án của mọi người một cách thoải mái nhất.
Nguồn:https://thenewstack.wordpress.com/2021/11/24/kafka-kafka-stream-with-spring-boot/
Follow me: thenewstack.wordpress.com
Nguồn: viblo.asia