Xã hội phát triển, công nghệ phát triển. Ngày nay các ứng BigData, ecommerce,… đã trở lên phổ biến. Một khối lượng dữ liệu khổng lồ được sử dụng và khai thác. Khi phát triển các ứng dụng phần mềm, về dữ liệu chúng ta có hai thách thức chính, thách thức đầu tiên là làm thế nào để thu thập khối lượng lớn dữ liệu và thách thức thứ hai là làm thế nào để phân tích dữ liệu thu thập được. Để vượt qua những thách thức đó, chúng ta phải cần một hệ thống gửi/nhận – thu thập nhắn tin đủ tốt và đáng tin cậy. Trước đây chúng ta có ActiveMQ, RabbitMQ, nhưng có vẻ như vậy là chưa đủ đáp ứng cho các bài toán lớn. Vì vậy Kafka ra đời, nó được thiết kế cho các hệ thống phân tán cần thông lượng cao. Kafka hoạt động rất hiệu quả và nó như một sự thay thế cho một message-brocker truyền thống. So với các message systems khác, Kafka có thông lượng tốt hơn, khả năng sao chép và phân vùng linh hoạt, chịu lỗi cao, điều này làm cho Kafka phù hợp với các ứng dụng xử lý tin nhắn ở mức quy mô lớn.
Định nghĩa đơn giản về Kafka
Kafka là một hệ thống phân tán message – distributed messaging system (được phát triển và duy trì bởi Apache nên còn được gọi là Apache Kafka). Cũng giống như các message brocker truyền thống ActiveMQ, RabbitMQ,… Kafka được phát triển theo mô hình Pub/Sub.
Dưới đây là một số hình vẽ mình tìm được trên mạng về mô hình tổ chức và cách hoạt động của Kafka giúp mọi người dễ hiểu hơn:

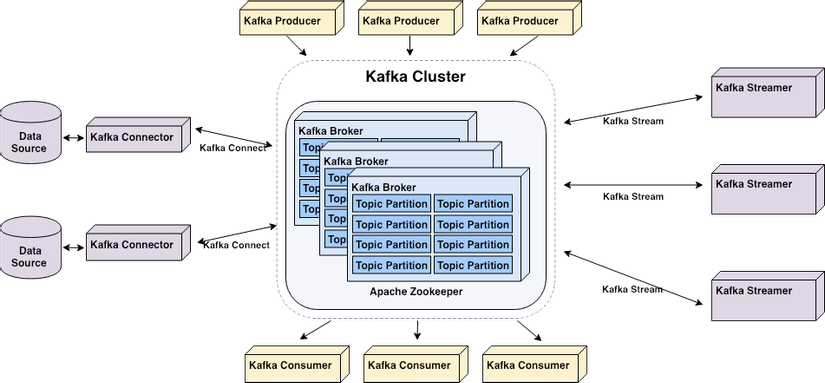
Hình 1
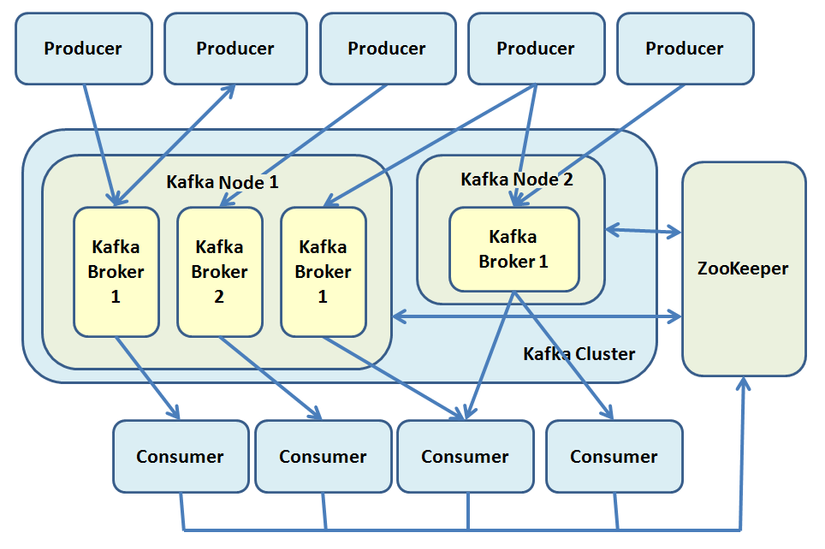
Hình 2
Hình 3
Để dễ hình dung và hiểu về các thành phần trong mô hình trên, chúng ta sẽ đi tìm hiểu các khái niệm.
Một số khái niệm giúp hiểu rõ về Kafka
- Producer: Kafka lưu, phân loại message theo topic. Sau khi tạo ra một message, chúng ta sử dụng producer để publish message vào các topic. Dữ liệu được gửi đển partition của topic lưu trữ trên Broker.
- Consumer: Kafka sử dụng consumer để subscribe vào topic, các consumer được định danh bằng các group name. Nhiều consumer có thể cùng đọc một topic.
- Consumer Group: 1 Consumer có thể không xử lý được tất cả các tin nhắn từ một Topic. Ví dụ: Một Producer xuất bản 1000 tin nhắn trong 1 giây và nó tiếp tục xuất bản tin nhắn. Giả sử Consumer phải đọc và xử lý thông tin. Nó chỉ có thể đọc 100 tin nhắn mỗi giây. Với tốc độ này, Consumer sẽ không bao giờ bắt kịp để đọc tất cả các tin nhắn trong Topic. Kafka cho phép chúng ta thiết lập nhiều Consumer hoạt động cùng nhau và tạo thành một nhóm Consumer để xử lý tin nhắn. Nó được gọi là Consumer Group.
‘+ Nếu số consumer > số partition, khi đó một số consumer sẽ ở chế độ rảnh rỗi bởi vì chúng không có partition nào để xử lý.
‘+ Nếu số partition > số consumer, khi đó consumer sẽ nhận các message từ nhiều partition.
‘+ Nếu số consumer = số partition, mỗi consumer sẽ đọc message theo thứ tự từ 1 partition.
Chúng ta cũng có thể có nhiều Consumer Group cùng lắng nghe trên một Topic. Giả sử có Topic cho đơn đặt hàng của khách hàng. Bất cứ khi nào khách hàng đặt hàng, Producer sẽ gửi thông điệp vào Topic này. Một Consumer Group chịu trách nhiệm vận chuyển sản phẩm sẽ sử dụng các thông điệp này, trong khi có thể có một Consumer Group khác sẽ sử dụng các thông điệp này cho mục đích phân tích mặt hàng nào được quan tâm nhiều. Hai consumer group này cùng nhận message từ Topic và xử lý độc lập nhau.
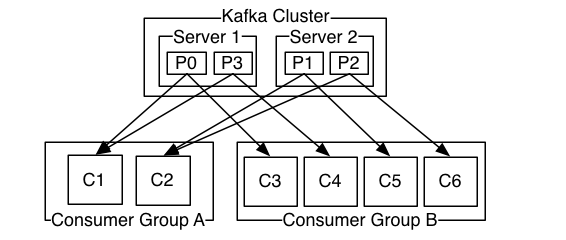
Trong bức ảnh ở trên, Server 1 giữ partition 0 và 3 và server 2 giữ các partition 1 và 2. Chúng ta có 2 consumer groups là A và B. Group A có 2 consumer và group B có 4 consumer. Consumer group A có 2 consumer, vậy nên mỗi consumer sẽ đọc message từ 2 partition.Trong consumer group B, số lượng consumer bằng số partition nên mỗi consumer sẽ đọc message từ 1 partition.
- Message: Đơn vị dữ liệu trong Kafka được gọi là message (một message chỉ đơn giản là một mảng byte) .Nếu tiếp cận Kafka từ góc nhìn cơ sở dữ liệu, chúng ta có thể nghĩ về message tương ứng như một row hoặc một record trong một table.
- Topic: Nếu message tương ứng như một row (record) thì topic tương ứng như một table để gom nhóm những message cùng loại. Dữ liệu truyền trong Kafka sẽ đến các Topic chỉ định.
- Partition: Là nơi lưu trữ dữ liệu bên trong topic. Một topic có thể có một hay nhiều partition. Trên mỗi partition thì dữ liệu lưu trữ cố định và được gán cho một ID gọi là offset. Trong một Kafka cluster (gồm nhiều brocker) thì một partition có thể replicate (sao chép) ra nhiều bản copy để tăng tính HA (High Availability). Trong đó có một bản được bầu là leader chịu trách nhiệm đọc ghi dữ liệu và các bản còn lại gọi là follower chỉ thực hiện đồng bộ vời partition leader. Khi bản leader bị lỗi thì sẽ có một bản follower lên làm leader thay thế. Nếu muốn dùng nhiều consumer đọc song song dữ liệu của một topic thì topic đó cần phải phân chia dữ liệu ra thành nhiều partition đặt ở các brocker khác nhau.
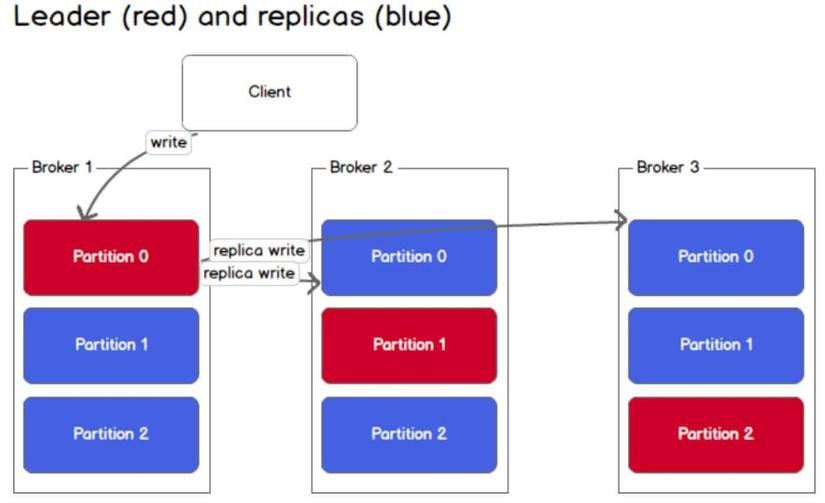
Để so sánh nó với ví dụ Database, chúng ta hãy xem xét một bảng có 3 triệu bản ghi. Nếu có 3 brocker trong cụm kafka, 3 triệu hồ sơ đó có thể được chia cho 3 brocker theo alpha-b của tên người dùng. Từ A-I sẽ lưu ở brocker 1, từ J-R sẽ lưu ở brocker 2 và từ S-Z sẽ lưu ở brocker 3. Vì vậy, mỗi brocker/partition không nhất thiết phải có cùng số lượng message mà có thể khác nhau.
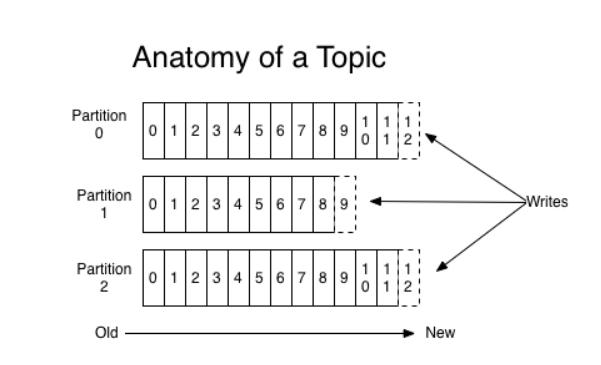
- Kafka Broker: chính là các Kafka server có thể cài trên 1 hoặc nhiều Kafka Node (server vật lý). Các broker hoạt động song song với nhau để quản lý dữ liệu vào ra. Các broker hoạt động ngang hàng với nhau và được quản lý bởi Zookeeper.
- Kafka cluster: là một tập hợp nhiều server vật lý – Kafka Node (hay chính là nhiều broker).
- Zookeeper: được dùng để quản lý và bố trí các broker. Toàn bộ thông tin về topic và partitions của 1 cluster đều được lưu trên Zookeeper. Khi có sự kiện thêm hoặc mất broker, hoặc thay thể partition leader thì thông tin trên Zookeeper sẽ giúp toàn bộ các broker còn lại biết được hiện trạng của cụm để có những điều chỉnh phù hợp về leader.
Conumser Groups và Quá trình tái cân bằng phân vùng (Partition Rebalance)
Trong một consumer group các consumer sẽ chia sẻ quyền sở hữu các partition trong một topic mà chúng subcribe tới. Khi chúng ta thêm một consumer mới tới một group, nó bắt đầu xử lý các message từ các partitions trước đó mà đang được xử lý bởi consumer khác. Điều tương tự cũng xảy ra khi một consumer bị shutdown hay crash. Nó rời khỏi group, và các partitions nó đang xử lý sẽ được xử lý bởi một trong những consumer còn lại trong consumer group. Quá trình sắp xếp lại các partition (Reasssignment) tới các consumers cũng xảy ra khi các topics mà consumer group đang tiêu thụ được chỉnh sửa (nếu người quản trị thêm các partition mới vào topic).
Quá trình di chuyển liên kết các partitions từ consumer này tới consumer khác được gọi là quá trình tái cân bằng phân vùng (rebalance). Rebalance rất quan trọng vì chúng cung cấp cho consumer group khả năng sẵn sàng và tính mở rộng cao (cho phép chúng ta thêm và xóa consumer dễ dàng và an toàn).
Một điều cần chú ý đó là trong quá trình sử dụng bình thường, quá trình rebalance không nên xảy ra. Trong quá trình rebalance, consumer không thể tiêu thụ các message được, do đó, việc rebalance về cơ bản sẽ làm cho toàn bộ consumer trong consumer group không thể tiêu thụ message được. Ngoài ra, khi các partitions được di chuyển từ consumer này tới consumer khác, consumer sẽ mất đi trạng thái hiện tại của nó. Nếu như nó đã cache dữ liệu sẵn rồi, nó sẽ cần phải làm mới lại cache – dẫn đến làm chậm ứng dụng cho đến khi consumer thiết lập lại trạng thái của nó.
Một consumer được coi là còn sống (alive) nếu nó gửi heartbeat đều đặn tới Kafka Broker (điều phối viên) và đang xử lý messae từ các partitions. Nếu như consumer ngừng gửi heartbeats trong một khoảng thời gian được quy định, khi đó phiên làm việc của nó sẽ hết hạn và sẽ bị coi như đã chết, quá trình rebalance sẽ được kích hoạt. Nếu một consumer gặp sự cố và ngừng xử lý các message, sẽ mất vài giây để Brocker quyết định rằng nó đã chết hay chưa và kích hoạt quá trình rebalance. Trong những giây này, không có message nào được xử lý từ các partitions thuộc sở hữu bởi consumer đã chết.
Cấu trúc dữ liệu trong Kafka
Dữ liệu kafka được lưu trong cấu trúc dữ liệu Log. Log là một cấu trúc dữ liệu có thứ tự nhất quán mà chỉ hỗ trợ dạng nối thêm (append). Chúng ta không thể chỉnh sửa hay xóa các bản ghi từ nó. Nó được đọc từ trái sang phải và được đảm bảo thứ tự các item.
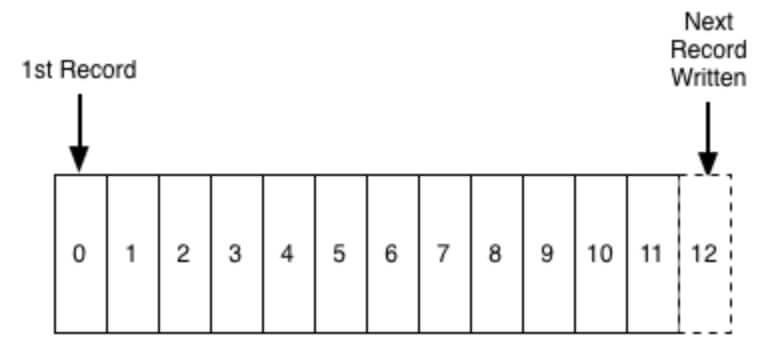
Producer sẽ ghi message vào Log và Consumer sẽ đọc message từ Log tại thời điểm họ lựa chọn.
Mỗi message trong log được định danh bởi một chỉ số gọi là offset, offset giống như chỉ số tuần tự trong một array.
Vì offset chỉ có thể được duy trì trên từng kafka node/broker cụ thể và không thể được duy trì đối với toàn bộ cluster, do đó Kafka chỉ đảm bảo sắp xếp thứ tự dữ liệu cho mỗi partition.
Áp dụng vào bài toán nào?
- Xử lý dữ liệu realtime: Mỗi khi dữ liệu được thêm mới vào topic sẽ ngay lập tức được ghi vào hệ thống và truyền đến cho bên nhận dữ liệu
- Sử dụng như một hệ thống message queue (giải pháp thay thế cho ActiveMq và RabbitMQ).
- Event-sourcing
- Log Aggregation: tổng hợp log,…
Ví dụ thực tế:
Tracing các hoạt động tương tác của người dùng trên website, tạo ra các thông tin liên quan đến người dùng như số lượt xem, sở thích người xem, … các thông tin này sẽ được dùng để tạo báo cáo, cho Machine Learning học, tạo ra các hành động suggestion cho người dùng.
Ứng dụng gửi nhận tin nhắn mà không cần phía nhận khi nào xử lý.
….
Những lợi ích cân nhắc về việc sử dụng Kafka
- Khả năng mở rộng: mô hình phân vùng lưu trữ tin nhắn của Kafka cho phép dữ liệu có thể phân phối trên nhiều máy chủ và qua đó có thể mở rộng máy chủ khi muốn scale.
- Nhanh: Với cách xử lý tách các luồng dữ liệu, vì thế độ trễ rất thấp làm cho tốc độ trở nên nhanh hơn.
- Khả năng chịu lỗi và độ bền: Dữ liệu có thể được sao chép và phân phối trên nhiều server khác nhau. Vì thế, khi có một sự cố xảy ra, dữ liệu sẽ có thể khôi phục (tính chịu lỗi và bền vững hơn).
Tổng kết
Trên đây là một số thông tin tổng quan nhất để mọi người hiểu về Kafka. Hy vọng mọi người sẽ hiểu được ý tưởng tổng thể để có thể áp dụng nó vào dự án của mọi người một cách thoải mái nhất.
Mọi người có thể tìm hiểu các bài viết liên quan tại đây:
Nguồn:https://thenewstack.wordpress.com/2021/11/24/kafka-kafka-introduction-in-depth/
Follow me: thenewstack.wordpress.com
Nguồn: viblo.asia