Intro
Hiện nay các dự án phát triển xe tự lái đang được nghiên cứu, phát triển rầm rộ ở mọi quốc gia. Mấy hôm trước thì mình thấy ở Việt Nam có dự án của bên VinAI hay của bên FPT, cũng có video sản phẩm đã làm của họ được public. Về cơ bản yêu cầu chính của hệ thống xe tự lái là:
- Phát hiện các đối tượng giao thông (Detec Object).
- Phân đoạn khu vực có thể lái được (Segmenting the drivable area).
- Phát hiện làn đường (Detecting lanes).
- Phát hiện biển báo giao thông (Detecting traffic).
- ….
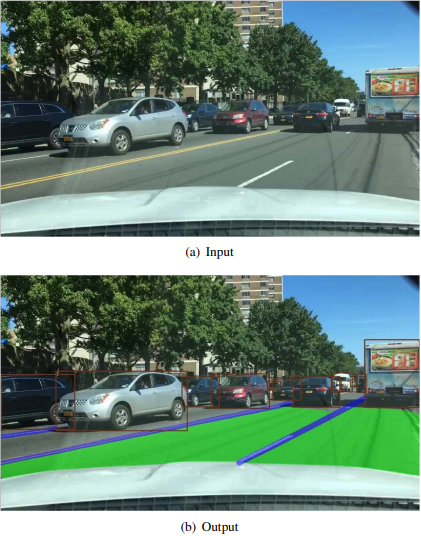
Thực tế hiện tại thì với mỗi task như bên trên đã có rất nhiều SOTA (state-of-the-art) thuật toán mạnh đối với từng nhiệm vụ. Ví dụ như Faster-RCNN, Yolov1,2,3,4,… cho nhiệm vụ object detection. Kiếm trúc UNet, PSPNet cho task semantic segmentation. Mạng SCNN, SAD-ENet cho task detecting lanes. Như vậy đối với từng nhiệm vụ riêng lẻ thì các phương pháp đạt hiệu suất cao, tuy nhiên khi thực hiện lần lượt từng task một thì xuất hiện độ trễ là rất lớn, mà đối với xe tự lái việc ra quyết định, giải quyết các task dường như là ngay lập tức (vd như đang đi trên đường phát hiện ra có người đi qua hay có xe khác thì phải xử lý ngay và luôn chứ không để vài chục giây, phút sau mới xử lý thì toi). Ngoài yếu tố thời gian, thì việc deploy lên các thiết bị nhúng vốn dĩ đã ít tài nguyên tính toán, độ trễ lớn thì phương pháp chạy qua từng model trên hoàn toàn không khả thi.
Như vậy, người ta áp dụng một mạng xử lý được đa tác vụ (Mutiltask-Learning) để xử lý trong trường hợp như này, chỉ cần một model có thể xử lý nhiều tác vụ khác nhau. Trong bài viết này mình xin giới thiệu đến một phương pháp áp dụng trực tiếp vào bài toán xe tự lái, paper có tên là YOLOP – You Only Look Once for Panoptic Driving Perception. Trong bài paper có nhắc đến các kiến trúc như CSP-Darknet, Feature Pyramid Network (FPN) , Spatial Pyramid Pooling (SPP), Path Aggregation Network (PAN), có thể làm mọi thứ hơi khó nắm bắt nên mọi người đọc qua một chút về nó:
- Spatial Pyramid Pooling – paper, blog
- Feature Pyramid Network – paper, blog
- CSP-Darknet – paper, blog
- Path Aggregation Network – paper, blog
Ngoài ra các bài viết liên quan đến Multitask-Learning: - Multitask Learning – PhamDinhKhanh
- Multi Task Learning – Một Số Điều Bạn Nên Biết – DaoQuangHuy
- Multi-task learning in Machine Learning – Towards Data Science
Trước tiên mình sẽ nói qua về bài toán Multi-task learning
Multi-task learning
Multi-task learning là bài toán dự đoán nhiều loại nhãn cùng một lúc mà sử dụng chung một model. Ví dụ vừa muốn đoán xem mèo giống gì, vừa muốn biết xem nó nặng bao nhiêu. Hay như trong bài toán xe tự lái là nhận biết nhiều vật thể khác nhau như các loại phương tiện, người đi bộ, tín hiệu biển báo, đèn giao thông,…trong cùng một model.
Về cơ bản sẽ có hai giai đoạn:
- Giai đoạn 1: Một mạng CNN có nhiệm vụ trích đặc trưng của ảnh. Các đặc trưng này sẽ là những đặc trưng chung cho toàn bộ các task nhận diện đằng sau.
- Giai đoạn 2: Thực hiện nhiều nhiệm vụ phân loại khác nhau (xe, tín hiệu đèn, làn,…). Từ các đặc trưng chung được trích suất từ giai đoạn 1 sẽ được sử dụng làm đầu vào cho bài toán phân loại nhị phân (Binary Classification) khác nhau. Output của chúng ta sẽ bao gồm nhiều units (Multi-head) mà mỗi unit sẽ tính toán khả năng xảy ra của một nhiệm vụ phân loại nhị phân hay cho một dạng nhãn. Các units này sẽ chia sẻ chung các lớp ở phía trước, mục đích là để các bài toán nhiệm vụ khác nhau sẽ có sự trao đổi thông tin lẫn nhau.

Giả sử ta biết con chó pitbull với thân hình vạm vỡ sẽ có cân nặng nhiều hơn so với một con chó Pug, như vậy chỉ cần biết chó là giống gì thì cũng sẽ giúp cho việc dự đoán cân nặng. Hay như người phụ nữ thường có xu hướng thích những màu sắc, họa tiết hơn đàn ông, thì từ giới tính ta cũng dự đoán được đồ dùng của giới tính đó (chỉ là ví dụ thôi nhé). Trong một số bài toán, người ta chỉ ra rằng dự đoán nhiều loại nhãn với chỉ một model sẽ cho kết quả cao hơn so với xây dựng từng model riêng biệt cho từng loại nhãn.
Một khía cạnh quan trọng nữa là việc encoding label. Bình thường ta đã quen đến one-hot encoding thì trong multitask này cũng gần giống như thế. Ví dụ như ta làm đồng thời hai nhiệm vụ là phân loại sản phẩm thời trang gồm {dress, jean, shirt} và màu sắc sản phẩm {black, pink, blue}. Từ số lượng nhãn như vậy ta sẽ tổng hợp thành một list gồm 6 nhãn [dress, jean, shirt, black, pink, blue] và một sản phẩm có nhãn là dress-pink thì sẽ được encode thành dạng [1, 0, 0, 0, 1, 0] ứng với vị trí giá trị 1 tương ứng với nhãn của dữ liệu.
YoloP
Method
YoloP cơ bản sẽ được chia ra làm 2 phần là Encoder (nơi chứa các features của input) và Decoder (bao gồm 3 subsequent decoders tương ứng với từng task).
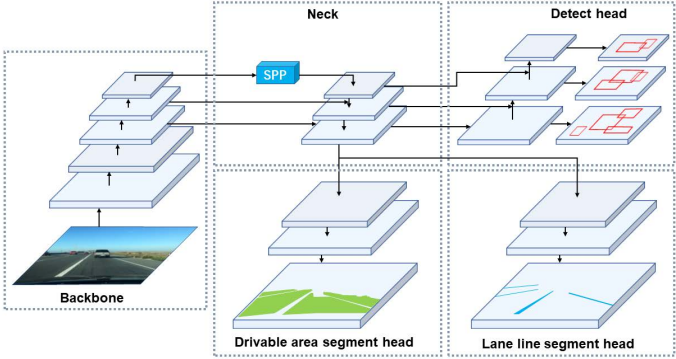
Encoder
Phần này như trên hình vẽ trên bao gồm Backbone network và Neck network.
Backbone Network
Về bản chất ở phần này sẽ là extract features từ ảnh đầu vào, và các mạng thực hiện nhiệm vụ classification được sử dụng trong phần này. Trong paper nhóm tác giả sử dụng mạng lightweight CSP-Darknet làm backbone (ưu điểm mạng này là giảm số lượng tham số và phép tính toán hơn so với các mạng khác như vậy sẽ làm giảm thời gian tính toán đi nhiều).
Neck network
Tiếp đến là Neck network có nhiệm vụ chính là feature engineering (hiểu đơn giản là quá trình chuyển đổi tập dữ liệu thô ban đầu thành tập các thuộc tính (features) có thể giúp biểu diễn tập dữ liệu ban đầu tốt hơn), sẽ bao gồm 2 module là of Spatial Pyramid Pooling (SPP) module và Feature Pyramid Network (FPN) module. SPP là một pooling layer có nhiệm vụ loại bỏ fixed-size input của mạng, hay CNN không yêu cầu kích thước ảnh đầu vào phải có kích thước cố định.
Như bình thường mạng CNN sẽ bao gồm phần trích đặc trưng sau đó đến lớp fully connected để classification. Phép tính convolution sẽ trượt qua toàn bộ ảnh đầu vào, với input size khác nhau thì size đầu ra cũng khác nhau. Tuy nhiên trong CNN đến lớp Fully-Connected input size phải là cố định. Việc phải resize lại ảnh đầu vào sẽ gặp phải trường hợp bị giảm độ phân giải, hay ảnh bị “vỡ, méo” vì thế để khắc phục điều này thì SPP ra đời. Module tiếp theo là Feature Pyramid Network(FPN) là bộ extract feature áp dụng nguyên lý kim tự tháp feature bên trong, mô hình kết hợp bottom-up kết hợp với top-down để tìm đối tượng, đảm bảo cân bằng giữa độ chính xác và tốc độ xử lý. Về chi tiết của 2 module SPP, FPN thì các bạn có thể đọc thêm các bài viết khác nếu đưa cụ thể vào thì khá dài và loãng nội dung chính, mình xin tạm dừng nó ở đây.
Decoder
Đối với nhiệm vụ phát hiện đối tượng, YoLoP áp dụng kỹ thuật anchor-based multi-scale detection tương tự như của YOLOv4. Có hai lý do đằng sau sự lựa chọn này, thứ nhất là single-stage detection networks nhanh hơn two-stage detection networks. Thứ hai, cơ chế dự đoán dựa trên grid-based phù hợp hơn với nhiệm vụ semantic segmentation tasks. Ban đầu sẽ sử dụng một cấu trúc gọi là Path Aggregation Network (PAN). Sau khi sử dụng FPN từ phần Encoder sẽ có được semantic features tại top-down sẽ qua PAN để lấy các features tại bottom-up , và combine hai phần đó lại với nhau tạo ra một multi-scale fusion feature maps cho việc detec. Và rồi mỗi một grid trong multi-scale fusion feature maps đó sẽ được assign 3 anchor với tỷ lệ khung hình khác nhau.
Tiếp đến task segment vùng lái, làn đường thì sử dụng chung một cấu trúc mạng. Lấy đầu vào sẽ là lớp cuối cùng của FPN trong Encoder với size là (W/8, H/8, 256) sẽ upsampling và restore để size đầu ra sẽ là (W, H, 2).
Loss Function
Hàm Loss trong bài toán multitask-learning sẽ là tổng loss của từng task :
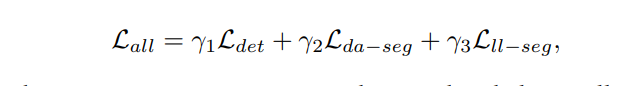
Trong đó:
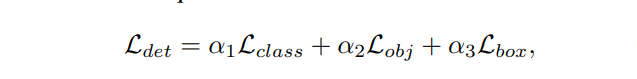
- Lclass và Lobj là focal loss. Lclass là loss classification và Lobj cho confidence dự đoán. Lbox bản chất là LIoU độ overlap của box.
- L(da-seg): Cross Entropy Loss của task drivable area segmentation (vùng lái)
- L(ll-seg) : Cross Entropy Loss của task lane line segmentation (làn đường)
- Giá trị α1, α2, α3, γ1, γ2, γ3 là tham số
Ngoài lề hàm loss
-
Đối với bài toán phân loại nhị phân hàm loss function có dạng:
-
Trong trường hợp bài toán phân loại có C nhãn. C nhiều hơn 2 nhãn. Đồng thời chúng ta sử dụng hàm sorfmax để tính phân phối xác suất output thì hàm loss function là một hàm cross entropy như sau:
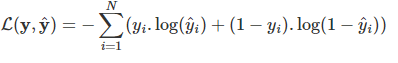
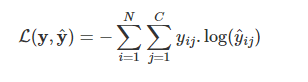
- Trong thuật toán multitask learning, đối với mỗi một tác vụ phân loại sẽ có giá trị hàm loss function là:
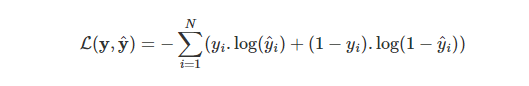
Như vậy khi có C tác vụ phân loại khác nhau, hàm loss function gộp của chúng sẽ là:
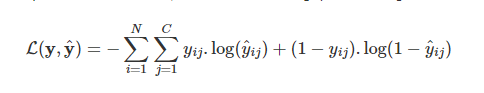
Trong đó i là chỉ số của mẫu, j là chỉ số của từng tác vụ.
Như vậy về bản chất hàm loss function của multitask learning là tổng các loss function (dạng binary cross entropy) của từng bài toán phân loại nhị phân ứng của mỗi một tác vụ.
Result
Link repo github. Kết quả trong paper mình đưa ra đây. So sánh giữa single-task với multitask, ban đầu sẽ train với ứng với mỗi nhiệm vụ là một model riêng biệt như drivable area segmentation (Da-Seg), lane line segmentation (Ll-Seg), Object Detect (Det). Kết quả cho thấy hiệu xuất gần bằng từng model riêng lẻ và thời gian cũng giảm đi đáng kể nếu chạy qua từng model.

Và dưới đây là video output:
Như vậy bài viết đến đây là hết, cảm ơn mọi người đã đọc. Trong nội dung bài viết sẽ không tránh có thiếu sót, mong mọi người thông cảm và mong nhận góp ý từ mọi người. Thanks !!!!
Reference
Nguồn: viblo.asia