Trái ngược với việc Machine Learning đã và đang có vô vàn ứng dụng trong thực tế trong hơn vài thập kỷ qua, công cụ hỗ trợ các nhà nghiên cứu và kỹ sư trong lĩnh vực này vẫn đang phát triển. Vậy nên khi các mô hình trở nên phức tạp và các nguồn dữ liệu trở nên đa dạng, cơ sở hạ tầng, đặc biệt là các cơ sở hạ tầng cấp thấp như Kubernetes, mạng, trình điều khiển GPU, quản lý tài nguyên, v.v sẽ trở thành thứ cản trở quá trình phát triển. Từ nhu cầu đó, một số công cụ đã được xây dựng dựa trên các thành phần của MLOps stack và một trong số đó là Flyte – một nền tảng hỗ trợ việc xây dựng workflow.
Giới thiệu chung
Flyte là một nền tảng xử lý phân tán và lập trình có cấu trúc, mã nguồn mở, hỗ trợ xây dựng các quy trình làm việc (workflow) đồng thời, có thể mở rộng và có thể bảo trì cao để sử dụng cho học máy và xử lý dữ liệu. Nó cho phép người dùng tập trung vào business logic trong khi có thể không cần quan tâm đến cơ sở hạ tầng bên dưới.

Được Lyft phát triển, trên kinh nghiệm sử dụng Airflow, nhìn chung cả Airflow và Flyte có các đặc điểm như sau:
- Hỗ trợ Python để viết quy trình công việc
- Chạy quy trình công việc theo lịch trình hoặc trường hợp đặc biệt
- Cung cấp tích hợp với các compute engines
- Hoạt động tốt khi sử dụng theo batch và không thích hợp cho xử lý luồng
Tuy vậy, do vẫn có một số tồn đọng khi sử dụng Airflow được liệt kê tại bài viết Orchestrating Data Pipelines at Lyft: Comparing Flyte and Airflow, Lyft đã xây dựng Flyte nhằm bổ sung các chức năng bao gồm: kiểm soát tài nguyên thông qua việc cô lập môi trường thực thi dưới dạng container với lượng tài nguyên cần cấp phát được xác định trước, quản lý phiên bản thông qua việc đóng gói và hỗ trợ bộ nhớ đệm được định nghĩa trong từng tác vụ. Trước khi đi vào tìm hiểu cách thức hoạt động thông qua một số ví dụ nhỏ, ta sẽ tìm hiểu một vài khái nhiệm chính của Flyte như sau:
- Task : một đơn vị thực thi có môi trường biệt lập với các thư viện và gói. Các tác vụ có thể là mã Python, các công việc Spark được phân phối, các lệnh gọi đến một công cụ tính toán như Trino hoặc Hive hoặc bất kỳ Docker container nào.
- Workflow: một tập hợp các nhiệm vụ và sự phụ thuộc giữa chúng.
- Project: một tập hợp các quy trình làm việc.
- Domain : sự phân tách một cách logic của các quy trình công việc trong dự án:
development,staging,production. - Launch Plan: Một khởi tạo cho một quy trình công việc có thể được liên kết với một cron và có thể sử dụng đầu vào được định cấu hình trước.
Là một graduated project của LF AI & Data, Flyte hỗ trợ một cách native các công cụ/công nghệ nhằm hoạt động trên các nền tảng đám mây. Tuy vậy, để hỗ trợ việc kiểm tra mã nguồn trước khi thực sự triển khai lên môi trường production, Flyte cũng đồng thời hỗ trợ việc chạy trực tiếp mã nguồn trên môi trường cục bộ.
Chuẩn bị môi trường
Trước khi bắt đầu, để đảm bảo việc chạy Flyte diễn ra thuận lợi, ta cần đảm bảo một số điều kiện như sau:
- Docker đã được cài đặt và daemon của nó đang được chạy
- Python với phiên bản 3 đã được cài đặt
Sau khi đã kiểm tra được các điều kiện trên, ta cài đặt SDK của Flyte với câu lệnh sau:
pip install flytekit
Để khởi chạy tương tác với 1 cụm Flyte, ta cần cài đặt flytectl thông qua câu lệnh như sau:
curl -sL https://ctl.flyte.org/install |sudobash -s -- -b /usr/local/bin
exportPATH=$(pwd)/bin:$PATHViệc khởi tạo và sử dụng các cụm Flyte có thể thực hiện bằng nhiều cách và một trong số đó là:
-
Triển khai một cụm đầy đủ lên k8s theo tài liệu cung cấp tại trang Deployment của
Flyte: Cách này hơi phức tạp không phù hợp với phạm vi của một bài giới thiệu. -
flytectl demo start: Khởi tạo một cụmdemotrong một docker container. Cách này sẽ chỉ tạo cụm tối thiểu nhất có thể do đó sẽ thường thiếu một số thành phần bổ trợ được liệt kê trong trang Integrations
củaFlyte -
flytectl sandbox start: Khởi tạo một cụmsandboxtrong một docker container. Cách này sẽ tạo một cụm đầy đủ thành phần nhưng chạy với tài nguyên bị giới hạn.
Dựa trên những đặc điểm trên, bài viết chọn cách thứ 3 để tạo cụm sandbox nhằm cung cấp cho các bạn cái nhìn đầu đủ về cách thức hoạt động của Flyte mà vẫn tiết kiệm được thời gian thực hiện.
Xây dựng workflow
Tiếp đó, để hình dung được Flyte quản lý các task và workflow , ta sẽ xây dựng workflow demo nhằm huấn luyện mô hình XGBoost với bộ dữ liệu Pima Indian Diabetes. Quá trình này bao gồm các bước như sau:
- Tải dữ liệu và chia nó thành các bộ training và validate
- Huấn luyện mô hình với dữ liệu training
- Chạy mô hình trên tập validate
- Kiểm tra độ chính xác cho kết quả ở bước trước
Với mỗi bước ở trên, ta có một task tương ứng và được cài đặt thành một Python function. Vậy để Flyte biết điều đó, ta sẽ cần thêm một decorator chẳng hạn như @task(....). Trong trường hợp đơn giản nhất, Flyte hỗ trợ việc ta định nghĩa và chạy workflow trên một file Python duy nhất nhưng cách này sẽ thiếu mất một số chức năng chẳng hạn như quản lý requirements cũng như đánh phiên bản. Bởi vậy nên thay vào đó ta sẽ tạo một thư mục mới với câu lệnh pyflyte init flyte-demo và kết quả thu được là như mục như sau:
.
├── docker_build_and_tag.sh
├── Dockerfile
├── flyte
│ ├── __init__.py
│ └── workflows
│ ├── example.py
│ └── __init__.py
├── flyte.config
├── LICENSE
├── README.md
└── requirements.txt
Trong các file được tạo, ta cần chú ý đến các file sau:
example.py: Định nghĩaworkflowvàtasktương ứngDockerfile: định nghĩa việc build docker image được sử dụng choworkflowdocker_build_and_tag.sh: bash script dùng để build image và đánh phiên bảnflyte.config: chứa các thông tin cấu hình dành cho việc chạy trên cụmflyterequirements.txt: chứa các thư viện cần được cài đặt. Để có thể sử dụng các thư viện được đề cập ở phần dưới đây, filerequirements.txtnên có nội dung như sau:
dataclasses_json==0.5.7
flytekit==1.1.0
joblib==1.1.0
pandas==1.4.3
scikit_learn==1.1.1
xgboost==1.6.1
Tiếp đó, có nhiều cách để khởi tạo cụm Flyte tuy nhiên đơn giản nhất ta sẽ dùng câu lệnh flytectl sandbox start --source *đường dẫn đến project vừa tạo. Lúc này Flyte sẽ dựng giúp ta một cụm k3s nằm trong một docker container và cài đặt các thành phần chính Flyte trong đó. Sau khi đợi tầm khoảng 20p, thành quả thu được của ta sẽ như sau:
(flytekit) ➜ flyte-demo main ✓ kubectl get pods -n flyte
NAME READY STATUS RESTARTS AGE
flyte-deps-kubernetes-dashboard-85bf8ffd7d-997gt 1/1 Running 1 4h19m
postgres-6cff57c4d6-bpgnk 1/1 Running 1 4h19m
flyte-deps-contour-contour-8cd76cd5c-7sbxf 1/1 Running 1 4h19m
minio-58965fd6d-lc5ft 1/1 Running 0 4h19m
flyte-deps-contour-envoy-49znq 2/2 Running 1 4h19m
syncresources-dd8c9c78f-hnkgj 1/1 Running 0 4h11m
flyteconsole-7fd66978c4-24ddv 1/1 Running 0 4h11m
flyte-pod-webhook-cdc9b99cb-7m42j 1/1 Running 0 4h11m
flytepropeller-5dcf8d858f-khg2q 1/1 Running 0 4h11m
datacatalog-668d6cdc99-ff826 1/1 Running 0 4h11m
flyteadmin-7b966b76bb-jzlw9 1/1 Running 0 4h11m
OK vậy là giờ ta chỉ cần quan tâm đến việc cài đặt workflow và task tương ứng trong example.py và việc đầu tiên cần làm là import một số thành phần cần thiết bao gồm: Resources, task, workflow từ Flyte để xây dựng workflow cũng như XGBClassifier từ xgboostđể xây dựng mô hình và một số hàm từ sklearn nhằm phục vụ quá trình huấn luyện:
import os
import typing
from collections import OrderedDict
from dataclasses import dataclass
from typing import Tuple
import joblib
import pandas as pd
from dataclasses_json import dataclass_json
import flytekit
from flytekit import Resources, task, workflow
from flytekit.types.fileimport JoblibSerializedFile
from flytekit.types.schema import FlyteSchema
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from xgboost import XGBClassifier
Tiếp đó, ta định nghĩa các biến cố định nhằm phục vụ quá trình huấn luyện như sau:
DATASET_COLUMNS = OrderedDict({"#preg":int,"pgc_2h":int,"diastolic_bp":int,"tricep_skin_fold_mm":int,"serum_insulin_2h":int,"bmi":float,"diabetes_pedigree":float,"age":int,"class":int,})FEATURE_COLUMNS = OrderedDict({k: v for k, v in DATASET_COLUMNS.items()if k !="class"})
CLASSES_COLUMNS = OrderedDict({"class":int})Quá trình huấn huyện mô hình XGBoost sẽ cần đến việc tối ưu các siêu tham số nên để hạn chế số biến truyền vào một task ta định nghĩa class XGBoostModelHyperparams như sau:
@dataclass_json@dataclassclassXGBoostModelHyperparams(object):
max_depth:int=3
learning_rate:float=0.1
n_estimators:int=100
objective:str="binary:logistic"
booster:str="gbtree"
n_jobs:int=1Việc cần sử dụng decorator @dataclass_json@dataclass nhằm mục đích serialize object cũng như tự động sinh một số phương thức đặt biệt xem tại đây
Cuối cùng, ta định nghĩa các task và workflow được tạo từ chúng như sau:
Đầu tiên là task chia bộ train và test:
@task(cache_version="1.0", cache=True, limits=Resources(mem="200Mi"))defsplit_traintest_dataset(
dataset: FlyteFile[typing.TypeVar("csv")], seed:int, test_split_ratio:float)-> Tuple[FlyteSchema[FEATURE_COLUMNS], FlyteSchema[FEATURE_COLUMNS], FlyteSchema[CLASSES_COLUMNS], FlyteSchema[CLASSES_COLUMNS],]:
column_names =[k for k in DATASET_COLUMNS.keys()]
df = pd.read_csv(dataset, names=column_names)
x = df[column_names[:8]]
y = df[[column_names[-1]]]return train_test_split(x, y, test_size=test_split_ratio, random_state=seed)Tiếp đó là task huấn luyện mô hình:
@task(cache_version="1.0", cache=True, limits=Resources(mem="200Mi"))deffit(x: FlyteSchema[FEATURE_COLUMNS], y: FlyteSchema[CLASSES_COLUMNS], hyperparams: XGBoostModelHyperparams)-> JoblibSerializedFile:
x_df = x.open().all()
y_df = y.open().all()
m = XGBClassifier(n_jobs=hyperparams.n_jobs, max_depth=hyperparams.max_depth, n_estimators=hyperparams.n_estimators, booster=hyperparams.booster, objective=hyperparams.objective, learning_rate=hyperparams.learning_rate,)
m.fit(x_df, y_df)
working_dir = flytekit.current_context().working_directory
fname = os.path.join(working_dir,f"model.joblib.dat")
joblib.dump(m, fname)return JoblibSerializedFile(path=fname)Phần thứ 3 là task chạy mô hình với bộ dữ liệu test:
@task(cache_version="1.0", cache=True, limits=Resources(mem="200Mi"))defpredict(x: FlyteSchema[FEATURE_COLUMNS], model_ser: JoblibSerializedFile)-> FlyteSchema[CLASSES_COLUMNS]:
model = joblib.load(model_ser)
x_df = x.open().all()
y_pred = model.predict(x_df)
col =[k for k in CLASSES_COLUMNS.keys()]
y_pred_df = pd.DataFrame(y_pred, columns=col, dtype="int64")
y_pred_df.round(0)return y_pred_df
Phần cuối cùng là task tính điểm dựa trên kết quả đã đoán nhận:
@task(cache_version="1.0", cache=True, limits=Resources(mem="200Mi"))defscore(
predictions: FlyteSchema[CLASSES_COLUMNS], y: FlyteSchema[CLASSES_COLUMNS])->float:
pred_df = predictions.open().all()
y_df = y.open().all()# evaluate predictions
acc = accuracy_score(y_df, pred_df)print("Accuracy: %.2f%%"%(acc *100.0))returnfloat(acc)Cuối cùng ta định nghĩa workflow được xây dựng từ 4 task trên như sau:
@workflowdefdiabetes_xgboost_model(
dataset:str="https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv",
test_split_ratio:float=0.33,
seed:int=7,)-> Tuple[JoblibSerializedFile,float]:
x_train, x_test, y_train, y_test = split_traintest_dataset(dataset=dataset, seed=seed, test_split_ratio=test_split_ratio )
model = fit(x=x_train, y=y_train,hyperparams=XGBoostModelHyperparams(max_depth=4),)
predictions = predict(x=x_test, model_ser=model)return model, score(predictions=predictions, y=y_test)Đầu tiên chạy thử workflow trực tiếp, ta thu được kết qủa như sau:
if __name__ =="__main__":print(f"Running {__file__} main...")print(diabetes_xgboost_model())(flytekit) ➜ flyte-demo main ✓ pyflyte run flyte/workflows/example.py diabetes_xgboost_model
Accuracy: 75.98%
WorkflowOutput(model=/tmp/flyte-e9qnszkd/raw/bcf777bca7c3e92387229f7b230cac2b/model.joblib.dat, accuracy=0.7598425196850394)Ok vậy là ngon rồi. Tuy vậy trước khi đẩy workflow lên cụm sandbox trên, ta cùng tìm hiểu một số thành phần bổ trợ của Flyte được sử dụng trong ví dụ trên như sau:
FlyteFile: đại diện cho một file được sử dụng trongtaskFlyteSchema: đại diện cho 1 dataframe. DoFlytehỗ trợ đa ngôn ngữ nên việc định nghĩa rõ ràng từ cột dữ liệu thông qua việc sử dụng các biếnCLASSES_COLUMNSvàFEATURE_COLUMNSlà cần thiết để đảm bảo workflow sẽ hoạt động mà không có lỗi xảy ra.flytekit.current_context().working_directory: lấy thông tin thư mục từ context củataskhiện tạiJoblibSerializedFile: Đại diện cho một file được sinh ra bằng thư việnjoblib- Decorator
workflowđược sử dụng để định nghĩa mộtworkflow - Decorator
taskđược sử dụng để định nghĩa cáctaskvà nó cho nhận các tham số như sau:cache_version: Định nghĩa phiên bản của cachecache: Cho phép sử dụng bộ nhớ đệmlimits: Giới hạn tài nguyên được sử dụng (ví dụ nhưResources(mem="200Mi")có nghĩa là chỉ được sử dụng tối đa lượng RAM là 200Mi)- Ngoài ra còn rất nhiều tham số mà
taskcó thể nhận nhưcontainer_image,environment,execution_mode, … Chi tiết về chúng mọi người có thể xem tại flytekit.task
- Câu lệnh chạy trực tiếp
workflowlàpyflyte run flyte/workflows/example.py diabetes_xgboost_modeltrong đó:pyflyte: cli đi kèm khi ta cài đặtflytekitflyte/workflows/example.py: đường dẫn đến file định nghĩaworkflowdiabetes_xgboost_model: tên củaworkflowcần chạy
Đăng ký workflow lên cụm sandbox
Sau khi đảm bảo source code chạy thành công và không có lỗi phát sinh, ta tiến hành việc đẩy workflow lên cụm sandbox bằng các bước sau:
- Đầu tiên Flyte sử dụng các Docker container để đóng gói
workflowvàtask, đồng thời gửi chúng đến cụmFlyte. Tuy vậy, vì cụmsandboxđược chạy cục bộ trong Docker container nên ta không cần phải đẩy Docker iamge lên đâu cả mà chỉ cần build trực tiếp docker image trong container của cụmsandbox. Điều này có thể được thực hiện bằng cách sử dụng lệnh sau:
sandbox exec -- docker build . --tag "diabetes_xgboost_model:v1"- Tiếp theo, đóng gói quy trình làm việc bằng cách sử dụng
pyflyte cliđi kèm vớiFlytekitbằng câu lệnh sau:
pyflyte --pkgs flyte.workflows package --image "diabetes_xgboost_model:v1"Tiếp đó là tải gói này lên cụm thông qua hành động được Flyte gọi là đăng ký (registration) và tag được sử dụng cũng không cần thiết phải đúng với tag của docker image. Tuy vậy ta cũng nên để các tag đồng nhất để dễ quản lý.
flytectl register files --project flyteexamples --domain development --archive flyte-package.tgz --version v1
Trong trường hợp may mắn, câu lệnh trên sẽ không có lỗi gì và bạn sẽ thu được kết quả như sau:
-------------------------------------------------------------------------------- --------- ------------------------------
| NAME (6)| STATUS | ADDITIONAL INFO |
-------------------------------------------------------------------------------- --------- ------------------------------
| /tmp/register4021493296/0_flyte.workflows.example.split_traintest_dataset_1.pb | Success | Successfully registered file|
-------------------------------------------------------------------------------- --------- ------------------------------
| /tmp/register4021493296/1_flyte.workflows.example.fit_1.pb | Success | Successfully registered file|
-------------------------------------------------------------------------------- --------- ------------------------------
| /tmp/register4021493296/2_flyte.workflows.example.predict_1.pb | Success | Successfully registered file|
-------------------------------------------------------------------------------- --------- ------------------------------
| /tmp/register4021493296/3_flyte.workflows.example.score_1.pb | Success | Successfully registered file|
-------------------------------------------------------------------------------- --------- ------------------------------
| /tmp/register4021493296/4_flyte.workflows.example.diabetes_xgboost_model_2.pb | Success | Successfully registered file|
-------------------------------------------------------------------------------- --------- ------------------------------
| /tmp/register4021493296/5_flyte.workflows.example.diabetes_xgboost_model_3.pb | Success | Successfully registered file|
-------------------------------------------------------------------------------- --------- ------------------------------
Tuy vậy nếu đen hơn, câu lệnh này sẽ trả về lỗi với log là:
INFO[0000][0] Couldn't find a config file[]. Relying on env vars and pflags.
panic: runtime error: invalid memory address or nil pointer dereference
[signal SIGSEGV: segmentation violation code=0x1 addr=0x0 pc=0x1306ddb]
goroutine 1[running]:
github.com/flyteorg/flytectl/cmd/core.CommandContext.AdminClient(...)
/home/runner/work/flytectl/flytectl/cmd/core/cmd_ctx.go:48
github.com/flyteorg/flytectl/cmd/register.register({0x2376a80, 0xc000052130}, {0x2369320?, 0xc0008cf8f0?}, {0x0, {0x0, 0x0}, {0x0, 0x0}, {0x0, ...}, ...}, ...)
/home/runner/work/flytectl/flytectl/cmd/register/register_util.go:188 +0x37b
github.com/flyteorg/flytectl/cmd/register.registerFile({0x2376a80, 0xc000052130}, {0xc000410960, _}, {_, _, _}, {0x0, {0x0, 0x0}, ...}, ...)
/home/runner/work/flytectl/flytectl/cmd/register/register_util.go:606 +0x95b
github.com/flyteorg/flytectl/cmd/register.Register({0x2376a80, 0xc000052130}, {0xc000421480?, 0x0?, 0x0?}, 0x3370d60, {0x0, {0x0, 0x0}, {0x0, ...}, ...})
/home/runner/work/flytectl/flytectl/cmd/register/files.go:160 +0x6ca
github.com/flyteorg/flytectl/cmd/register.registerFromFilesFunc({0x2376a80, 0xc000052130}, {0xc000421480, 0x1, 0x8}, {0x0, {0x0, 0x0}, {0x0, 0x0}, ...})
/home/runner/work/flytectl/flytectl/cmd/register/files.go:118 +0xcd
github.com/flyteorg/flytectl/cmd/core.generateCommandFunc.func1(0xc00031b400?, {0xc000421480, 0x1, 0x8})
/home/runner/work/flytectl/flytectl/cmd/core/cmd.go:65 +0x625
github.com/spf13/cobra.(*Command).execute(0xc00031b400, {0xc000421400, 0x8, 0x8})
/home/runner/go/pkg/mod/github.com/spf13/[email protected]/command.go:852 +0x67c
github.com/spf13/cobra.(*Command).ExecuteC(0xc000699680)
/home/runner/go/pkg/mod/github.com/spf13/[email protected]/command.go:960 +0x39c
github.com/spf13/cobra.(*Command).Execute(...)
/home/runner/go/pkg/mod/github.com/spf13/[email protected]/command.go:897
github.com/flyteorg/flytectl/cmd.ExecuteCmd()
/home/runner/work/flytectl/flytectl/cmd/root.go:137 +0x1e
main.main()
/home/runner/work/flytectl/flytectl/main.go:12 +0x1d
Điều này là có thể do config của flyte trỏ sai port hoặc đơn giản là nó không tồn tại. Để sửa lỗi này thì ta chỉ cần kiểm tra file config có nội dung giống ntn là được:
admin:# For GRPC endpoints you might want to use dns:///flyte.myexample.comendpoint: dns:///localhost:30080authType: Pkce
insecure:truelogger:show-source:truelevel:0Lúc này, workflow đã có sẵn trên cụm và có thể xem thông tin cũng như chạy thử tại http://localhost:30080/console/projects/flytesnacks/domains/development/workflows/flyte.workflows.example.diabetes_xgboost_model?duration=all.
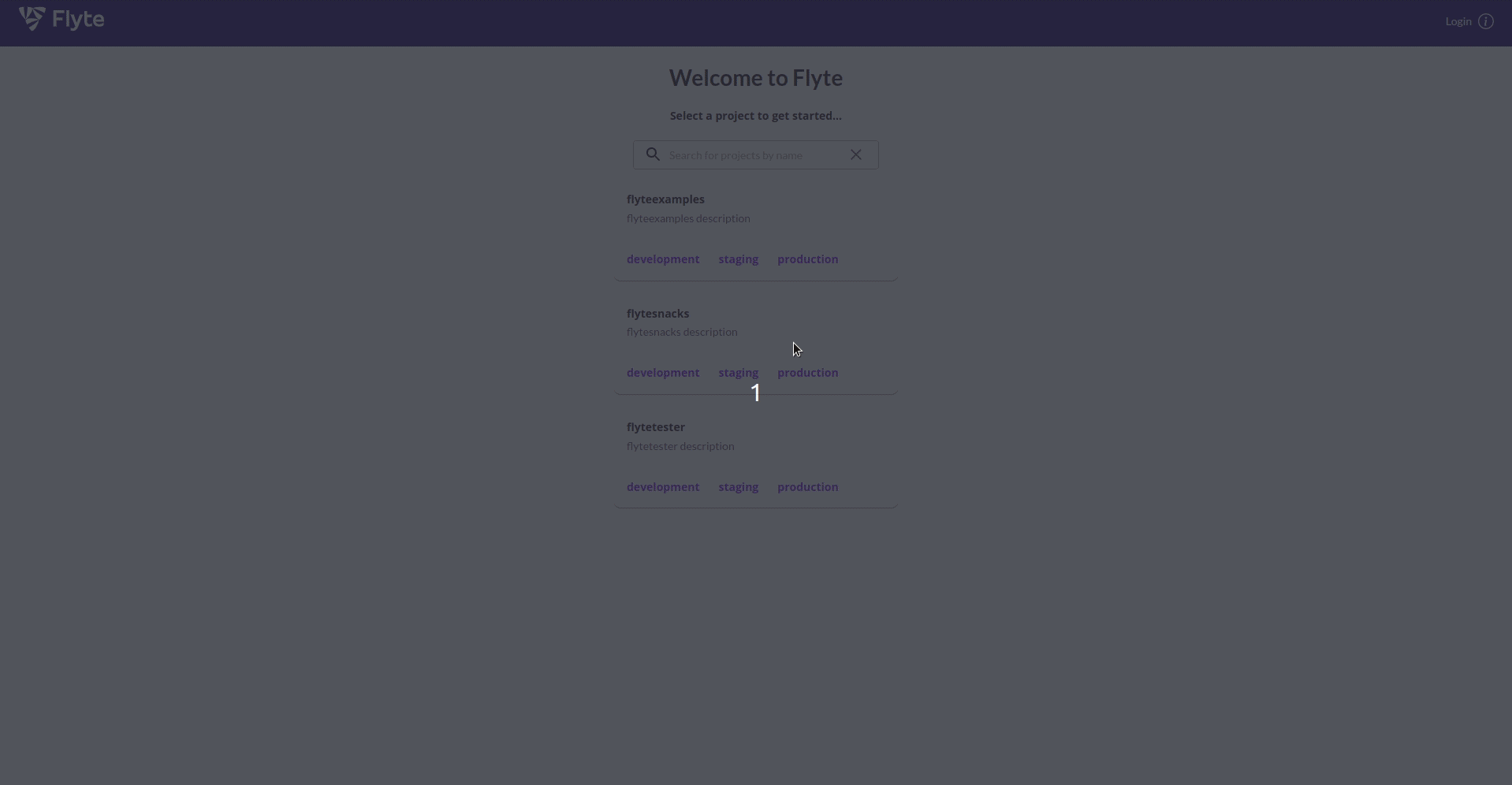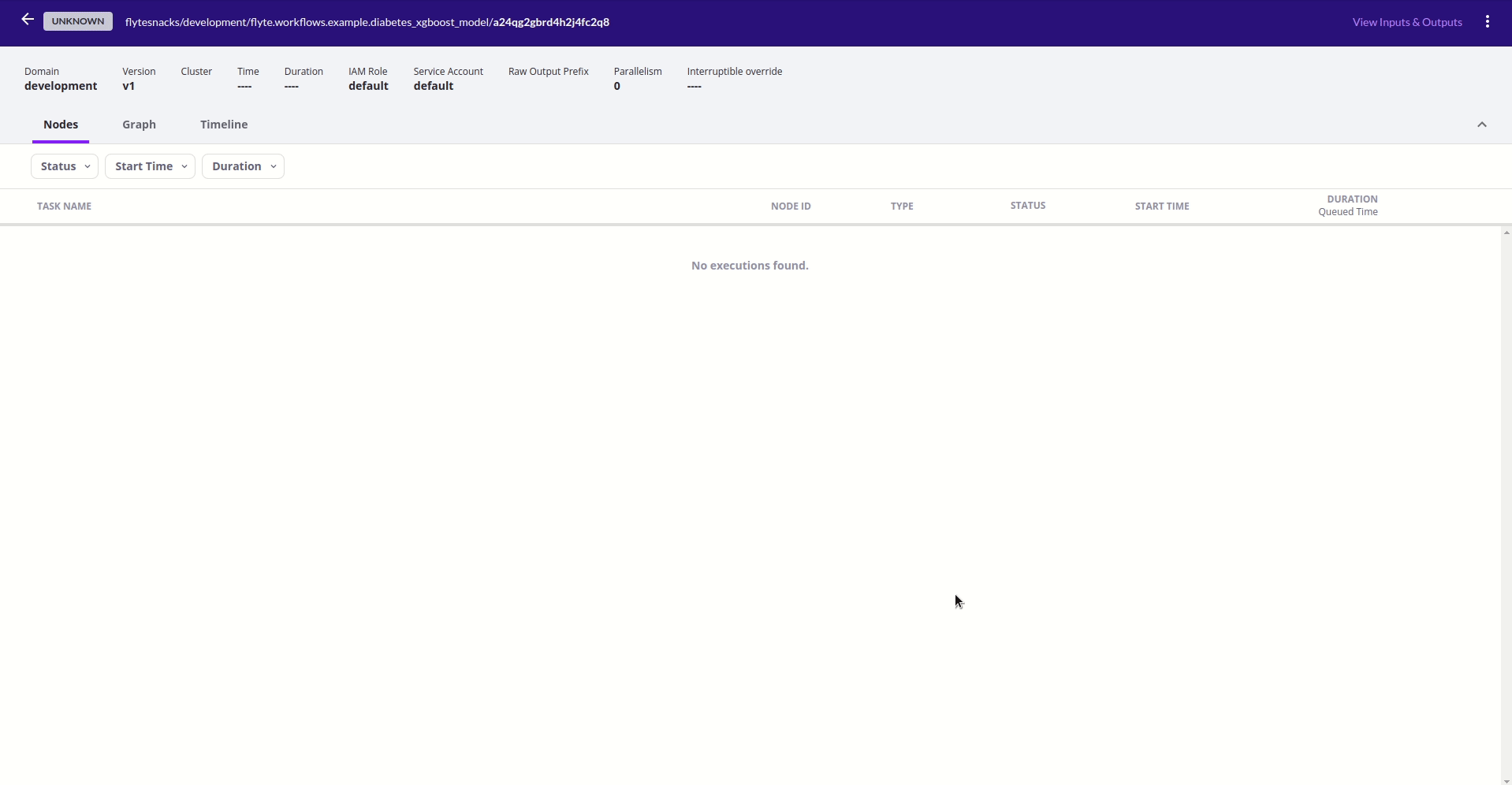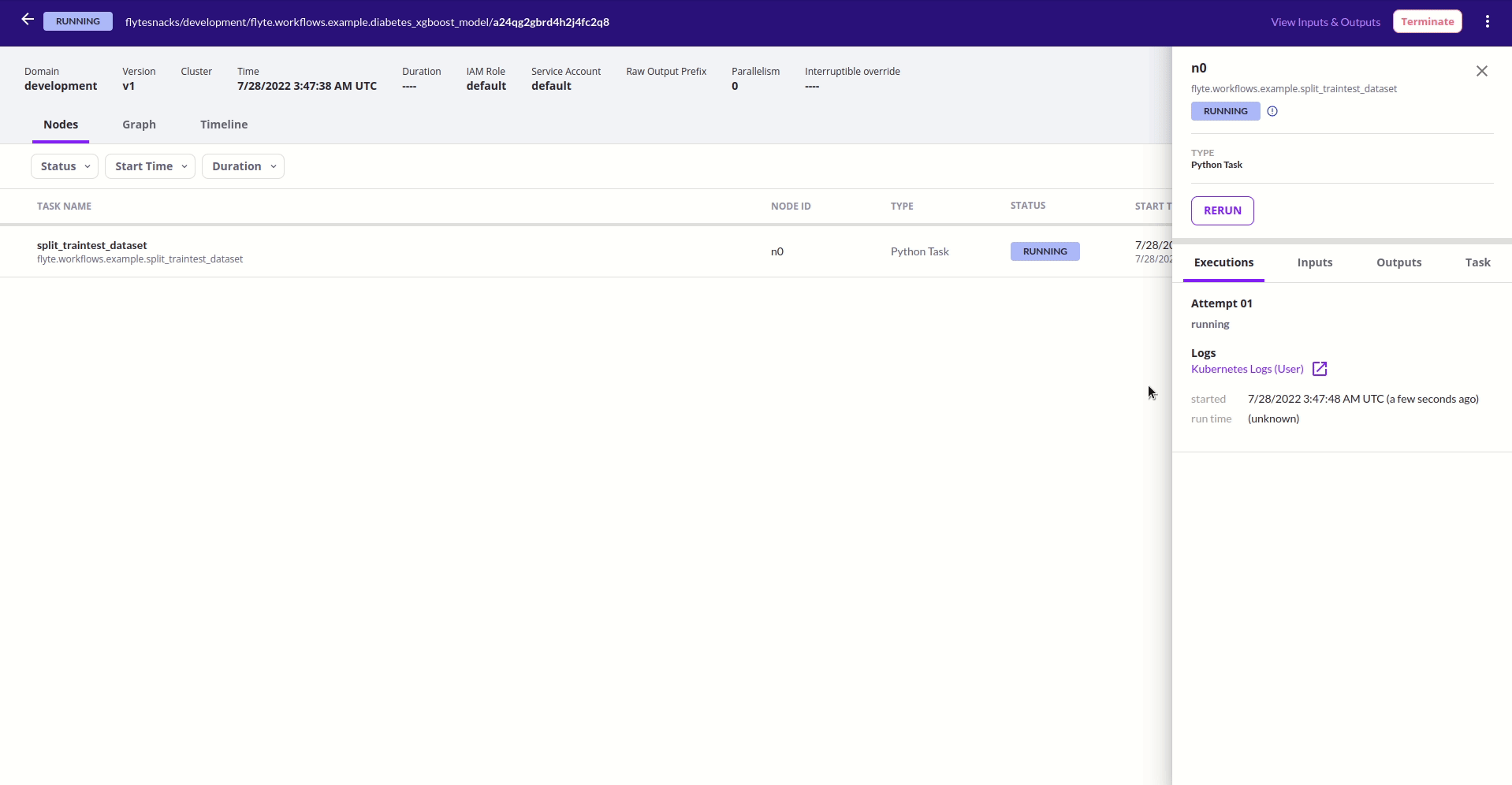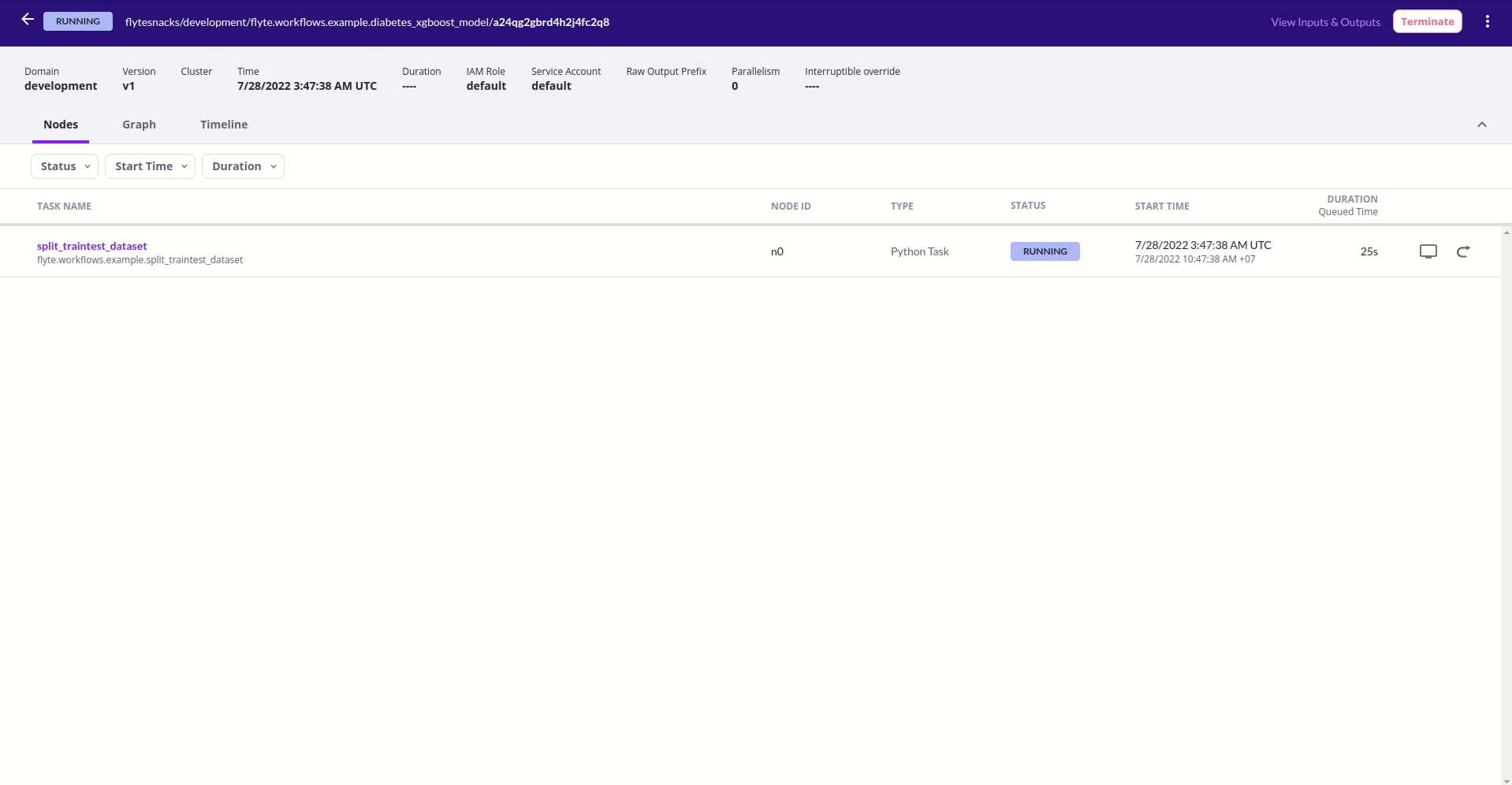
Giao diện quản lý của Flyte
Sau khi đã đăng ký và chạy thành công một workflow, ta có thể thấy rằng Flyte cung cấp khá tường minh các thông tin các thông tin liên quan đến các workflow cũng như các task tương ứng bao gồm lịch sử chạy cùng thời gian và trạng thái tương ứng cũng như input/output và thời gian hoàn thành.
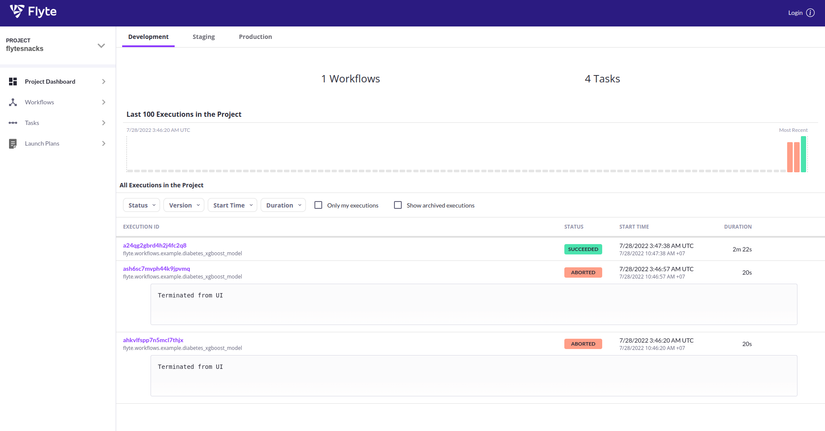
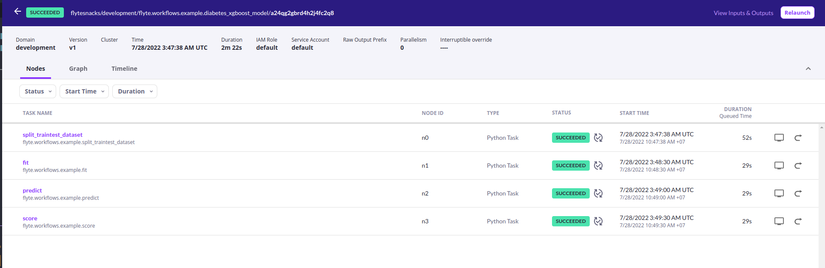
Đối với từng worflow, Flyte hiển thị cho người dùng thông tin dưới 3 dạng chính. Đầu tiên là đơn giản liệt kê các task được định nghĩa trong workflow đó cùng với thời điểm chạy và trạng thái tương ứng cũng như input/output và thời gian hoàn thành.
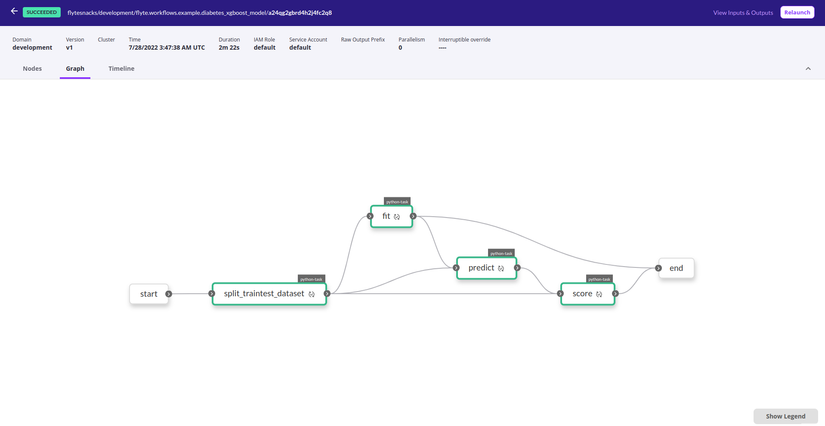
Tiếp theo, Flyte hiển thị mối liên hệ của các task dưới dạng đồ thị, để người dùng hình dung được mỗi quan hệ phụ thuộc giữa các task.
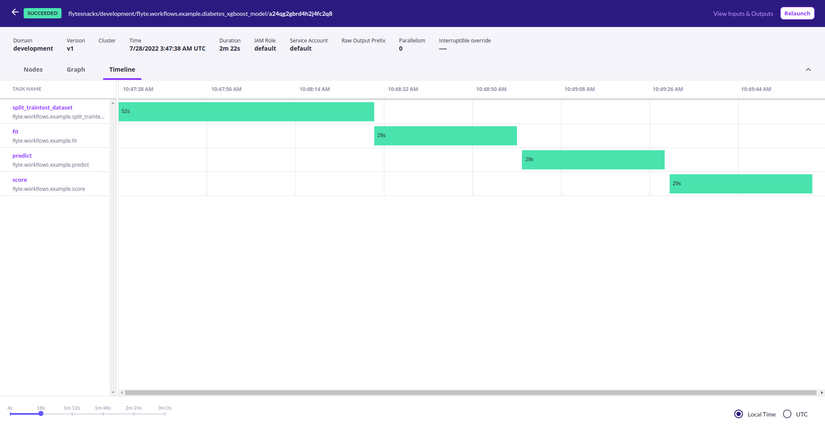
Cuối cùng là dạng timeline để người dùng có thể hình dung được quá trình thực thi của các task nhằm xác định rằng chúng có được thực thi song song hay không hay cần phải thực thi một cách tuần tự.
Kết luận
Bài viết này giới thiệu về Flyte – một nền tảng hỗ trợ việc xây dựng workflow cũng như cung cấp một ví dụ nhỏ nhằm mình họa về cách thức hoạt động của framework này. Mặc dù có một số ưu điểm đã được liệt kê ở trên, Flyte không phải là công cụ ưu việt để có thể thay thế Airflow hay bất kỳ công cụ xây dựng workflow nào khác do vậy, ta cũng cần đánh giá tính phù hợp của từng công cụ trước khi áp dụng vào bài toán của mình. Bài viết của mình đến đây là kết thúc, cảm ơn mọi người đã dành (rất nhiều) thời gian đọc.
Tài liệu tham khảo
- https://github.com/meirwah/awesome-workflow-engines
- https://neptune.ai/blog/best-workflow-and-pipeline-orchestration-tools
- https://docs.flyte.org/en/latest/getting_started/index.html
- https://docs.flyte.org/projects/cookbook/en/latest/auto/larger_apps/larger_apps_deploy.html
- https://blog.flyte.org/orchestrating-data-pipelines-at-lyft-comparing-flyte-and-airflow#heading-airflow-concepts
- https://blog.flyte.org/flyte-joins-lf-ai-and-data
Nguồn: viblo.asia