Introduction
RepVGG là một mô hình đã làm mưa làm gió trong cộng đồng Machine Learning những ngày vừa qua. Những model ConvNet cổ điển như VGG đã đạt được những thành công lớn trong lĩnh vực nhận thức hình ảnh với kiến trúc tương đối đơn giản gồm các lớp Conv, ReLU và pooling. Tuy nhiên, sự chú ý của các nhà nghiên cứu đang chuyển dời sang những model được thiết kế tinh tế và phức tạp hơn, với những ví dụ điển hình như Inception hay ResNet. Những mô hình phức tạp này tuy mang lại độ chính xác cao nhưng đồng thời với đó cũng tồn tại những mặt bất lợi đáng kể. Có thể kể đến như sự phức tạp của thiết kế nhiều nhánh khiến cho việc xây dựng mô hình trở nên khó khăn hơn đồng thời khiến cho việc inference chậm hơn và giảm sự tận dụng bộ nhớ hay một số mô hình làm tăng cost của việc truy cập bộ nhớ và không phù hợp trên một số thiết bị. Vì vậy chúng ta có sự ra đời của RepVGG với một số lợi thế nhất định như sở hữu cấu trúc đơn giản của VGG (không có nhánh và output của lớp trước sẽ trở thành input của lớp sau), chỉ sử dụng lớp Conv3x3 và ReLU activation và cuối cùng là không cần bao gồm những thiết kế phức tạp như tìm kiếm tự động hay sàng lọc thủ công.
Cấu trúc mô hình
Tiếp đến chúng ta sẽ làm quen với cấu trúc mô hình RepVGG. Ảnh dưới đây là một phần của mô hình giúp cho chúng ta dễ hình dung
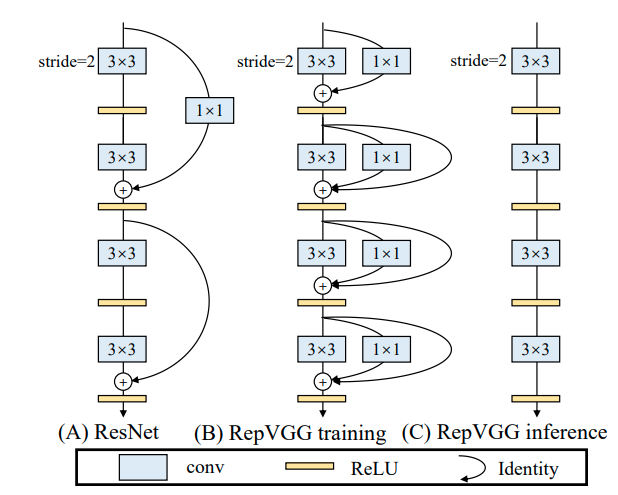
Mô hình RepVGG được chia theo tổng cộng 5 stages, trong mỗi 1 stage sẽ gồm các block tương tự nhau về cấu trúc. Trong block đầu tiên của 1 stage, các lớp Conv sẽ có strides 2 để thực hiện down-sampling .
Chúng ta sẽ đi tìm hiểu chi tiết mô hình mà RepVGG sử dụng trong training trước. Trong training, khi input được truyền vào 1 stage, như đã nói ở trên, input sẽ được đi qua đồng thới 2 lớp Conv3x3 và Conv1x1 với strides 2, sau đó outputs của 2 lớp này sẽ được cộng lại với nhàu và đi qua 1 lớp ReLU activation cuối cùng. Output của block đầu tiên được tiếp tục sử dụng cho block tiếp theo. Từ block thứ 2 trở đi, cấu trúc các block trong stage là giống hệt nhau. Các block đều gồm 3 nhánh: Conv3x3 với stride 1, Conv1x1 với stridde 1 là 1 nhánh Identity sử dụng Batch Normalization. Ouputs của các nhánh cũng sẽ được cộng lại với nhau trước khi đưa qua 1 lớp ReLU activation. Các stage có cấu trúc tương tự nhau và giống như đã được trình bày ở trên, điểm khác biệt duy nhất của các stages đó là số lượng của các blocks trong stage đó.
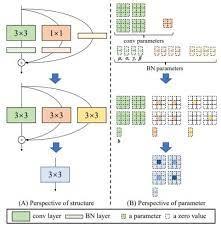
Trong inference, cấu trúc của RepVGG có sự thay đổi nhẹ. Thay vì sử dụng các nhánh Conv rồi cộng output lại với nhau như trong training thì trong inference, input khi đi qua mô hình sẽ chỉ còn đi qua các lớp Conv3x3 và ReLU activation liên tiếp (hình (C) ở ảnh trên). Tuy nhiên đây là điểm phức tạp khi xây dựng mô hình này, vì các Conv3x3 không chỉ đơn giản là một Conv3x3 với weight được lấy ngẫu nhiên. Weight của các Conv3x3 trong inference sẽ được triển khai bằng cách cộng các weight của các nhánh Conv3x3, Conv1x1 và Identity (nếu có) trong training. Phương pháp này được gọi là reparameterization.
Implementation với TF2
Chúng ta đã làm quen với cấu trúc mô hình RepVGG, vậy bây giờ hãy bắt tay vào xây dựng mô hình nào. Paper gốc đã có link tới github chứa code cho mô hình pretrained của RepVGG sử dụng PyTorch, tuy nhiên hiểu rằng rất nhiều các bạn muốn sử dụng Tensorflow vì sự tiện lợi của framework này cũng như thói quen của mỗi người, vậy mình sẽ giúp các bạn triển khai mô hình này trên Tensorflow v2.
Bước đầu tiên đương nhiên là chuẩn bị những thư viện cần thiết.
import tensorflow as tf
import numpy as np
from tensorflow.keras.layers.experimental import preprocessing
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras import Model, Sequential
from tensorflow.keras.layers import Input, Layer, AveragePooling2D, Conv2D, BatchNormalization, Dropout, Dense, Flatten, ReLU, ZeroPadding2D
from tensorflow.keras.optimizers import SGD
Vì các block của RepVGG sẽ được lặp đi lặp lại theo một cấu trúc tương đối giống nhau, chúng ta sẽ để nó thành 1 class.
classRepVGGBlock(Layer):def__init__(self, in_channels, out_channels, kernel_size, stride):super(RepVGGBlock, self).__init__()
padding =1
padding_11 = padding - kernel_size//2
self.in_channels = in_channels
value = np.zeros((3,3,int(self.in_channels),int(self.in_channels)), dtype=np.float32)for i inrange(int(self.in_channels)):
value[1,1, i %int(self.in_channels), i]=1
self.id_tensor = tf.convert_to_tensor(value, dtype=np.float32)# Triển khai lớp Conv3x3 sau reparameterization
self.reparam = Sequential([ZeroPadding2D(padding=padding, name='pad'),
Conv2D(out_channels, kernel_size, strides=stride, padding='valid',
dilation_rate=1, name='conv')])# Triển khai lớp Conv3x3 trong training
self.conv_bn3x3 = Sequential([ZeroPadding2D(padding=padding, name='pad'),
Conv2D(out_channels, kernel_size, strides=stride, padding='valid',
dilation_rate=1, use_bias=False, name='conv'),
BatchNormalization(name='bn')])# Triển khai nhánh Conv1x1 trong training
self.conv_bn1x1 = Sequential([ZeroPadding2D(padding=padding_11, name='pad'),
Conv2D(out_channels, kernel_size=1, strides=stride, padding='valid',
dilation_rate=1, use_bias=False, name='conv'),
BatchNormalization(name='bn')])
self.activation = ReLU()# Triển khai nhánh Identity trong training
self.identity = BatchNormalization(name='identity')if(stride==1and
in_channels == out_channels)elseNoneỞ đây, chúng ta đang subclass 1 layer, nghĩa là chúng ta đang viết 1 block của RepVGG dưới dạng 1 layer cho 1 model. Layer này sẽ lấy các thông số là số lượng channels của input, số lượng channels của output, kích cỡ của lớp Conv và strides. Lưu ý rằng khi khai báo nhánh Identity, chúng ta kèm theo điều kiện để nhánh chỉ được triển khai khi stride là 1 vì block đầu tiên của stage khi strides là 2 không có nhánh này. Trong các nhánh Conv, chúng ta sẽ sử dụng Sequential của Keras để gộp chung các layer ZeroPadding2D và Conv2D. Chúng ta thêm ZeroPadding2D vào trước lớp Conv2D để ảnh không bị mất đi thông tin trong quá trình trích xuất. Ở lớp Conv trong training, chúng ta còn thêm 1 lớp BatchNormalization ở sau cùng. Sau khi đã khai báo các biến trong class như trên, chúng ta cần viết function call để có thể gọi được layer
defcall(self, inputs, training=True):# Initialize the branches for training
train_branch = self.conv_bn3x3(inputs)
sub_branch = self.conv_bn1x1(inputs)if self.identity isNone:
id_branch =0else:
id_branch = self.identity(inputs)# Initialize the single branch for inference
self.reparam(inputs)
kernel, bias = self.convert_kernel_bias()
self.reparam.layers[1].weights[0].assign(kernel)
self.reparam.layers[1].weights[1].assign(bias)
inference_branch = self.reparam(inputs)if training:return self.activation(train_branch+sub_branch+id_branch)else:return self.activation(inference_branch)Hàm call sẽ lấy 2 arguments là inputs (input được truyền vào cho block) và training (1 biến Boolean để tái cấu trúc lại block khi chuyển từ training sang inference). Khi training, có thể thấy inputs sẽ được truyền đồng thời qua 3 nhánh Conv3x3, Conv1x1 và Identity (nếu có) và sau đó trả về giá trị khi đã qua ReLU activation. Còn khi inference, chúng ta sẽ chỉ sử dụng đến layer self.reparam, weight và bias của layer này được xây dựng nên từ 3 nhánh của training thông qua hàm self.convert_kernel_bias(). Hàm được định nghĩa như sau:
defconvert_kernel_bias(self):
kernel3x3, bias3x3 = self.get_kernel_bias(self.conv_bn3x3)
kernel1x1, bias1x1 = self.get_kernel_bias(self.conv_bn1x1)
kernelid, biasid = self.get_kernel_bias(self.identity)return(kernel3x3+self.pad_1x1_to_3x3(kernel1x1)+kernelid,
bias3x3+bias1x1+biasid)defpad_1x1_to_3x3(self, kernel1x1):if kernel1x1 isNone:return0else:return tf.pad(
kernel1x1, tf.constant([[1,1],[1,1],[0,0],[0,0]]))defget_kernel_bias(self, branch):if branch isNone:return0,0ifisinstance(branch, tf.keras.Sequential):
kernel = branch.get_layer("conv").weights[0]
running_mean = branch.get_layer("bn").moving_mean
running_var = branch.get_layer("bn").moving_variance
gamma = branch.get_layer("bn").gamma
beta = branch.get_layer("bn").beta
eps = branch.get_layer("bn").epsilon
else:assertisinstance(branch, tf.keras.layers.BatchNormalization)
kernel = self.id_tensor
running_mean = branch.moving_mean
running_var = branch.moving_variance
gamma = branch.gamma
beta = branch.beta
eps = branch.epsilon
std = tf.sqrt(running_var + eps)
t = gamma / std
target_kernel = kernel*t
target_bias = beta-running_mean*gamma/std
return target_kernel, target_bias
Hàm convert_kernel_bias sẽ lấy các weights và bias của các nhánh trong training thông qua hàm get_kernel_bias và trả lại giá trị của weight và bias cho layer reparam bằng cách thêm padding cho weight của Conv1x1 và cộng weight với weight, bias với bias.
Sau khi RepVGGBlock được xây dựng xong có thể được sử dụng để xây dựng mô hình RepVGG như dưới đây. Trước hết chúng ta tạo mô hình bằng việc subclass Model:
classRepVGG(Model):def__init__(self, num_blocks, width_multipliers, dropout=0.5):super(RepVGG, self).__init__()
self.in_planes =min(64,64*width_multipliers[0])assertlen(width_multipliers)==4
self.stage0 = RepVGGBlock(in_channels=3, out_channels=self.in_planes, kernel_size=3, stride=2)
self.stage1 = self.make_stage(int(64*width_multipliers[0]), num_blocks[0], stride=2)
self.stage2 = self.make_stage(int(96*width_multipliers[1]), num_blocks[1], stride=2)
self.stage3 = self.make_stage(int(128*width_multipliers[2]), num_blocks[2], stride=2)
self.stage4 = self.make_stage(int(256*width_multipliers[3]), num_blocks[3], stride=2)
self.gap = tf.keras.layers.AveragePooling2D(pool_size=(3,3))
self.flatten = Flatten()
self.dropout = Dropout(dropout)
self.dense = Dense(6, activation="softmax")Mô hình này sẽ nhận 3 arguments: số lượng các blocks trong các stages, hệ số αalpha và βbeta để điều chỉnh đầu ra của output trong các stages, cuối cùng là hệ số dropout. Như đã nói ở trên, mô hình của chúng ta sẽ có tất cả 5 stages, với trường hợp này, mô hình được xây dựng cho mục đích phân loại ảnh, vậy nên sau các stage, chúng ta sẽ có thêm 1 lớp Global Average Pooling (GAP), 1 lớp Flatten và Dense để đưa về véc tơ phân loại với 6 là số lượng class chúng ta cần phân biệt và cuối cùng là layer Dropout để tránh overfit. Trong paper có đưa ra stage đầu tiên sẽ chỉ có 1 block, vì vậy chúng ta khai báo stage sử dụng trực tiếp RepVGGBlock với số lượng channels đầu vào là 3 (ảnh RGB) và số lượng channels đầu ra phụ thuộc vào hệ số αalpha (số lượng channels đầu ra = min(64,64α)min(64, 64alpha)). Các stages khác sẽ được khai báo thông qua hàm make_stage định nghĩa như sau:
defmake_stage(self, out_channels, num_blocks, stride):
strides =[stride]+[1]*(num_blocks-1)
blocks =[]for stride in strides:
blocks.append(RepVGGBlock(in_channels=self.in_planes, out_channels=out_channels,
kernel_size=3, stride=stride))
self.in_planes = out_channels
return Sequential(blocks)Hàm này sẽ lấy số lượng channels đầu ra, số lượng block trong 1 stage và stride làm các arguments. Đầu tiên 1 list strides sẽ được tạo vì các block có stride khác nhau trong 1 stage, block đầu tiên sẽ nhận được stride được truyền vào hàm và các block còn lại sẽ tự động được gán stride 1. Sử dụng vòng lặp và tạo các block liền nhau với số lượng channels của output từ block trước sẽ trở thành số lượng channels input của block sau và trả lại dãy các block.
Sau khi đã khai báo đủ các layers cũng như các biến sử dụng, chúng ta sẽ viết hàm call để gọi model:
defcall(self, inputs, training=True):
output = self.stage0(inputs, training)
output = self.stage1(output, training)
output = self.stage2(output, training)
output = self.stage3(output, training)
output = self.stage4(output, training)
output = self.gap(output)
output = self.flatten(output)
output = self.dropout(output)
output = self.dense(output)return output
Giống như ở trên, hàm call sẽ nhận 2 arguments: inputs là input được truyền vào model (ảnh RGB dưới dạng ma trận) và biến boolean training để thay đổi cấu trúc mô hình từ train sang inference. Hàm call sẽ truyền lần lượt ảnh qua các stages, qua GAP, Flatten, Dropout và cuối cùng là Dense để trả lại véc tơ phân loại.
Train
Việc tiếp theo chính là tiến hành train mô hình. Trước hết chúng ta cần chuẩn bị data. Trong bài này mình sử dụng là data trên Kaggle với mục đích phân loại ảnh theo 6 classes lần lượt là buildings – 0, forest – 1, glacier – 2, mountain – 3, sea – 4, street – 5. Các bạn có thể xem thêm hoặc tải data tại đây.
Sử dụng công cụ có sẵn của Keras, chúng ta sẽ load data:
gen = ImageDataGenerator(rescale=1./255, width_shift_range=[-75,75], height_shift_range=0.25, horizontal_flip=True,
vertical_flip=True, rotation_range=90, brightness_range=[0.2,1.0])
train = gen.flow_from_directory("###Link to train data###", target_size=(150,150),
batch_size=128, shuffle=True)
test = gen.flow_from_directory("###Link to test data###", target_size=(150,150),
batch_size=128, shuffle=True)Sử dụng ImageDataGenerator ảnh sẽ được tải lên và rescale lại để các gí trị nằm giữa 0 và 1, đồng thời áp dụng một số phương pháp như flip, rotation, shift và brightness để augment ảnh tạo thêm dữ liệu giúp quá trình huấn luyện được chính xác hơn. Để giữ nguyên được chất lượng ảnh, chúng ta sẽ giữ nguyên kích thước khi tải lên, đồng thời dữ liệu sẽ được tải lên theo các batch size là 128 để đẩy nhanh quá trình huấn luyện.
from tensorflow.keras.metrics import CategoricalAccuracy
lnr =0.1
num_blocks =[2,4,14,1]# [2, 4, 14, 1] for RepVGG-A or [4, 6, 16, 1] for RepVGG-B
width_multipliers =[0.75,0.75,0.75,2]
epochs =70
sgd = SGD(learning_rate=lnr, momentum=0.2)
model = RepVGG(num_blocks, width_multipliers, dropout=0.3)
inp = Input(shape=(150,150,3))
model(inp)
acc = CategoricalAccuracy(name='acc')
model.compile(optimizer=sgd, loss='categorical_crossentropy', metrics=[acc], run_eagerly=True)
model.summary()Bước tiếp theo sẽ là xây dựng model trên máy, bắt đầu bằng việc khai báo những thông số cần thiết. Đầu tiên chính là số lượng các blocks với biến num_blocks, [2, 4, 14, 1] là số lượng blocks mặc định cho mô hình RepVGGA theo như paper gốc. Các thông số αalpha và βbeta lần lượt là 0.75 và 2.
Model:"rep_vgg"_________________________________________________________________Layer(type)OutputShapeParam#=================================================================rep_vgg_block(RepVGGBlock)multiple3168_________________________________________________________________sequential_9(Sequential)(None,38,38,48)88608_________________________________________________________________sequential_22(Sequential)(None,19,19,72)364608_________________________________________________________________sequential_65(Sequential)(None,10,10,96)2424768_________________________________________________________________sequential_69(Sequential)(None,5,5,512)938496_________________________________________________________________average_pooling2d(AveragePomultiple0_________________________________________________________________flatten(Flatten)multiple0_________________________________________________________________dropout(Dropout)multiple0_________________________________________________________________dense(Dense)multiple3078=================================================================Totalparams:3,822,726Trainableparams:3,810,550Non-trainableparams:12,176_________________________________________________________________Ở đây mình thay đổi một chút số lượng param so với paper gốc (giảm βbeta xuống 2 và giảm số lượng channels đầu ra của các stages) để mô hình được nhẹ hơn như kết quả tổng hợp ở trên.
from tensorflow.keras import callbacks
earlystopping = callbacks.EarlyStopping(monitor="val_loss", mode="min",
patience=5, restore_best_weights = True)
history = model.fit(train, epochs=epochs, validation_data=test, shuffle=True, verbose=1,
callbacks=[earlystopping], workers=6, use_multiprocessing=True)Chúng ta sẽ tiến hành train model trên data vừa chuẩn bị với sự giúp đỡ của biến earlystopping giúp quá trình huấn luyện dừng lại sớm trước khi bị overfit. Tuy nhiên với mục đích của bài viết, mình chỉ huấn luyện với 8 epochs vì vậy chúng ta chưa thể thấy được nhưng các bạn có thể tự trải nghiệm bằng cách tăng số epochs lên rất cao.
Kết quả
Và dưới đây là kết quả sau khi huấn luyện. Mình đã tạo ra 2 plots của loss và accuracy để tiện hơn cho việc theo dõi
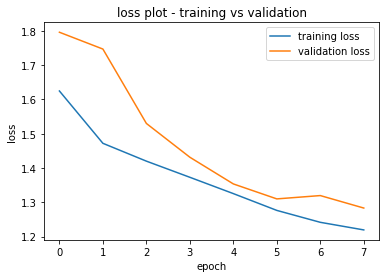
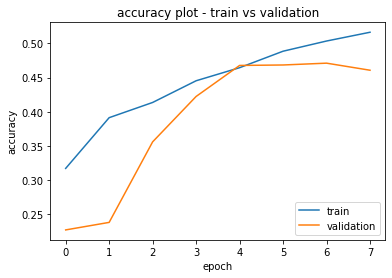
Tuy độ chính xác chưa được cao nhưng hãy cùng thử predict nhé
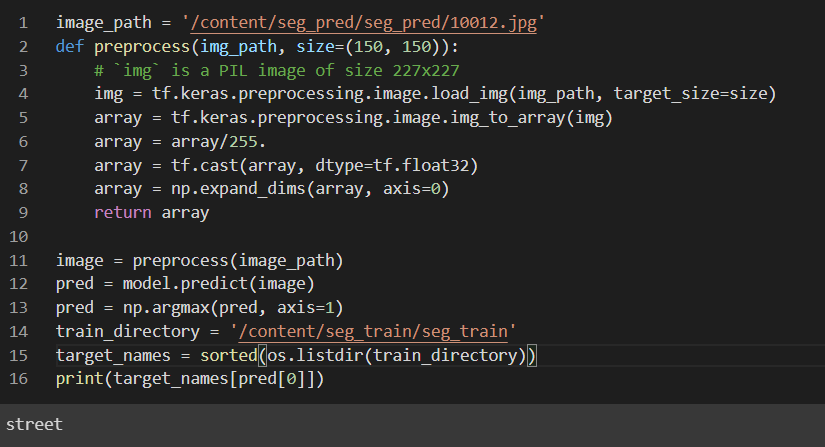
Cảm ơn đã đọc đến đây, nhớ upvote nếu các bạn thấy hữu dụng nhé  )))))))))
)))))))))
Nguồn: viblo.asia