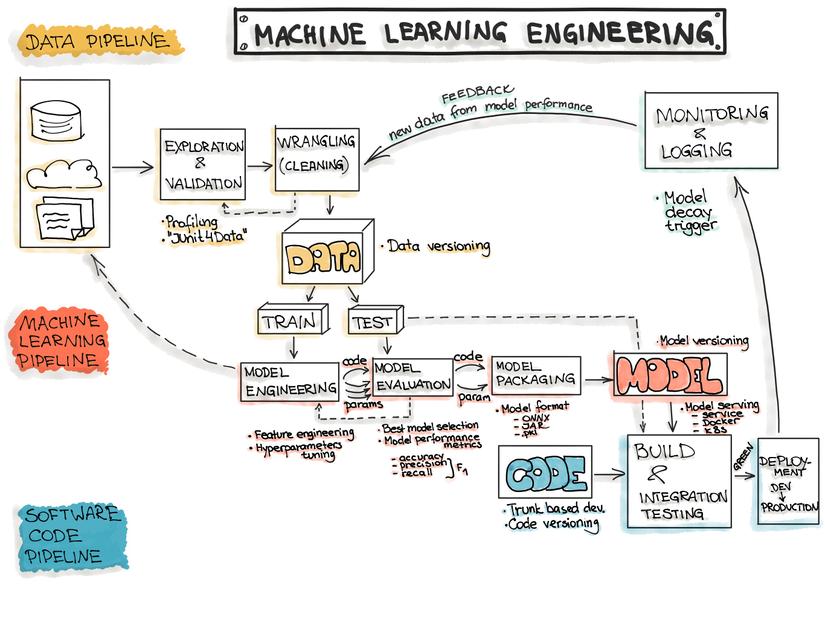
Mở đầu
Hẳn là chúng ta đã quen với việc train, evaluate model machine learning rồi. Vậy train xong rồi thì làm gì? Khi đưa mô hình ML từ research lên môi trường production (ví dụ như app điện thoại hoặc phần mềm máy tính) thì phải làm thế nào? Trên thực tế, model serving thường có nghĩa là model sẽ được deploy như một service và các service khác có thể giao tiếp với nó, yêu cầu đưa ra dự đoán và sử dụng kết quả đó.
Trong bài này mình sẽ tìm hiểu về việc làm thế nào để “serve” một machine learning model – biến mô hình đã được train thành một service để người khác cũng có thể sử dụng.
Có nhiều công cụ giúp việc serve model trở nên dễ dàng như Torch Serve, Tensorflow Serving, Cortex, tuy nhiên trong bài này mình sẽ giới thiệu một công cụ tiện lợi và hỗ trợ nhiều ML framework, đó là BentoML
BentoML là một framework mã nguồn mở dùng cho serving, quản lý và deploy mô hình học máy, nhằm mục đích thu hẹp khoảng cách giữa Data Science và DevOps. Các nhà khoa học dữ liệu có thể dễ dàng đóng gói model của họ với BentoML và reproduce model để serve trong quá trình production. BentoML giúp quản lý các mô hình đóng gói ở định dạng BentoML và cho phép DevOps triển khai chúng dưới dạng các online API serving endpoints hoặc offline batch inference jobs, trên bất kỳ nền tảng đám mây nào.
-
Hỗ trợ nhiều framework ML, bao gồm Tensorflow, PyTorch, Keras, XGBoost, vv.
-
Deploy trên nền tảng đám mây với Docker, Kubernetes, AWS, Azure, vv.
-
High-Performance online API serving and offline batch serving
-
Web dashboards và APIs để đăng ký mô hình và quản lý deployment
Dưới đây mình sẽ trình bày các bước sử dụng BentoML để serve một model spacy qua một REST API server, và containerize model server với Docker để phục vụ production deployment. Bạn cũng có thể làm tương tự với các framework khác.
BentoML yêu cầu python phiên bản 3.6 trở lên, chúng ta có thể cài đặt package bằng pip:
!pip install -q bentoml spacy>=2.3.0
Dưới đây là một cấu trúc thư mục cơ bản của một BentoML project:

Download pretrained model của spacy để serving với BentoML
!python3 -m spacy download en_core_web_sm
Load và train model với một vài sample:
import en_core_web_sm
nlp = en_core_web_sm.load()
# Getting the pipeline component
ner=nlp.get_pipe("ner")
# training data
TRAIN_DATA = [
("Walmart is a leading e-commerce company", {"entities": [(0, 7, "ORG")]}),
("I reached Chennai yesterday.", {"entities": [(19, 28, "GPE")]}),
("I recently ordered a book from Amazon", {"entities": [(24,32, "ORG")]}),
("I was driving a BMW", {"entities": [(16,19, "PRODUCT")]}),
("I ordered this from ShopClues", {"entities": [(20,29, "ORG")]}),
("Fridge can be ordered in Amazon ", {"entities": [(0,6, "PRODUCT")]}),
("I bought a new Washer", {"entities": [(16,22, "PRODUCT")]}),
("I bought a old table", {"entities": [(16,21, "PRODUCT")]}),
("I bought a fancy dress", {"entities": [(18,23, "PRODUCT")]}),
("I rented a camera", {"entities": [(12,18, "PRODUCT")]}),
("I rented a tent for our trip", {"entities": [(12,16, "PRODUCT")]}),
("I rented a screwdriver from our neighbour", {"entities": [(12,22, "PRODUCT")]}),
("I repaired my computer", {"entities": [(15,23, "PRODUCT")]}),
("I got my clock fixed", {"entities": [(16,21, "PRODUCT")]}),
("I got my truck fixed", {"entities": [(16,21, "PRODUCT")]}),
("Flipkart started it's journey from zero", {"entities": [(0,8, "ORG")]}),
("I recently ordered from Max", {"entities": [(24,27, "ORG")]}),
("Flipkart is recognized as leader in market",{"entities": [(0,8, "ORG")]}),
("I recently ordered from Swiggy", {"entities": [(24,29, "ORG")]})
]
for _, annotations in TRAIN_DATA:
for ent in annotations.get("entities"):
ner.add_label(ent[2])
# Disable pipeline components you dont need to change
pipe_exceptions = ["ner", "trf_wordpiecer", "trf_tok2vec"]
unaffected_pipes = [pipe for pipe in nlp.pipe_names if pipe not in pipe_exceptions]
# Import requirements
import random
from spacy.util import minibatch, compounding
from pathlib import Path
# TRAINING THE MODEL
with nlp.disable_pipes(*unaffected_pipes):
# Training for 30 iterations
for iteration in range(300):
# shuufling examples before every iteration
random.shuffle(TRAIN_DATA)
losses = {}
# batch up the examples using spaCy's minibatch
batches = minibatch(TRAIN_DATA, size=compounding(4.0, 32.0, 1.001))
for batch in batches:
texts, annotations = zip(*batch)
nlp.update(
texts, # batch of texts
annotations, # batch of annotations
drop=0.5, # dropout - make it harder to memorise data
losses=losses,
)
print("Losses", losses)
1. Tạo một Prediction Service
Việc serving mô hình với BentoML được thực hiện sau khi một mô hình đã được train xong. Bước đầu tiên là tạo một class cho prediction servce, class này định nghĩa các mô hình được sử dụng và các API dùng cho inference. Dưới đây là một prediction service được tạo để serve mô hình spacy NER được đào tạo ở trên, được viết trong file bento_service.py:
%%writefile bento_service.py
from bentoml import BentoService, api, env, artifacts
from bentoml.frameworks.spacy import SpacyModelArtifact
from bentoml.adapters import JsonInput
@env(auto_pip_dependencies=True)
@artifacts([SpacyModelArtifact('nlp')])
class SpacyNERService(BentoService):
@api(input=JsonInput(), batch=True)
def predict(self, parsed_json_list):
result = []
for index, parsed_json in enumerate(parsed_json_list):
doc = self.artifacts.nlp(parsed_json['text'])
result.append([{'entity': ent.text, 'label': ent.label_} for ent in doc.ents])
return result
Đoạn code trên định nghĩa một prediction service mà đóng gói mô hình spacy và cung cấp một inference API nhận một đối tượng JsonInput làm đầu vào của nó. BentoML cũng hỗ trợ các kiểu dữ liệu đầu vào API khác bao gồm DataframeInput, ImageInput, FileInput, vv.
Trong BentoML, tất cả các inference API chấp nhận một list các input và trả về một list kết quả. Trong trường hợp DataframeInput, mỗi hàng của dataframe sẽ được map với một prediction request nhận được từ máy client.
Thiết kế này cho phép BentoML nhóm các API request thành các batch nhỏ khi serving online. So với máy chủ mô hình dựa trên flask hoặc FastAPI, điều này có thể tăng thông lượng tổng thể của máy chủ API lên 10-100 lần tùy thuộc vào khối lượng công việc.
Đoạn code sau sẽ đóng gói mô hình được train với prediction service class được định nghĩa ở trên, sau đó lưu một instance vào đĩa ở định dạng BentoML format để phân phối và triển khai:
from bento_service import SpacyNERService
# Create a SpacyNER service instance
svc = SpacyNERService()
# Pack the newly trained model artifact
svc.pack('nlp', nlp)
saved_path = svc.save()
2. REST API Model Serving
Để khởi động máy chủ mô hình API REST với spacy NER được lưu ở trên, chúng ta sử dụng lệnh bentoml serve. Nếu sử dụng Google Colab, bạn có thể khởi động dev server với tùy chọn –run-with-ngrok, để có quyền access API endpoint với ngrok:
!bentoml serve SpacyNERService:latest --run-with-ngrok
Nếu bạn chạy trên máy local thì model spacy lúc này đã được served tại localhost:5000. Sử dụng curl command để gửi prediction request:
curl -i
--request POST
--header "Content-Type: application/json"
--data "{"text":"I am driving BMW"}"
localhost:5000/predict
Hoặc dùng request library của python:
import requests
response = requests.post("http://127.0.0.1:5000/predict", json={"text":"I am driving BMW"})
print(response.text)
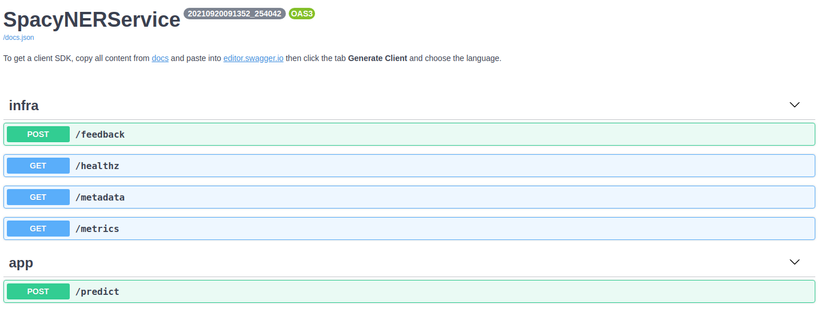
The BentoML API server also provides a simple web UI dashboard. Go to http://localhost:5000 in the browser and use the Web UI to send prediction request:
Máy chủ API BentoML cũng cung cấp một cái dashboard đơn giản qua giao diện web. Truy cập http: // localhost: 5000 trong trình duyệt và sử dụng giao diện này để gửi prediction request:
3. Container hóa model server với Docker
Một cách phổ biến để phân phối model API server trong production là thông qua Docker container. Và BentoML hỗ trợ chúng ta làm điều đó một cách rất dễ dàng.
Nếu bạn đã có Docker trong máy local, chỉ cần chạy lệnh sau để tạo ra một Docker container serving prediction service được nói ở trên:
!bentoml containerize SpacyNERService:latest
!docker run -p 5000:5000 spacynerservice
Kết luận
Như vậy trong bài này mình đã trình bày cách sử dụng BentoML để đưa một mô hình học máy, cụ thể là spacy từ research lên production. Vì kiến thức còn có hạn nên đây mới chỉ là một bài hướng dẫn khá sơ khai. Cảm ơn các bạn đã đọc!
Reference
Nguồn: viblo.asia