I. Lời mở đầu
Tiếp nối chủ đề về kiến trúc Tacotron mà mình đã đề cập với các bạn trong bài viết Tìm hiểu kiến trúc Text2Speech nổi danh một thời -Tacotron (Phần 1), hôm nay chúng ta tìm hiểu một phiên bản lột xác Tacotron2 được đề cập trong bài báo NATURAL TTS SYNTHESIS BY CONDITIONING WAVENET ON MEL SPECTROGRAM
PREDICTIONS
Tacotron là kiến trúc dạng sequence-to-sequence dự đoán cường độ các chuỗi spectrogram từ chuối kí tự đầu vào thay thế cho việc sinh trực tiếp các đặc trưng ngôn ngữ và âm thanh
Vậy so sánh giữa hai kiến trúc Tacotron và Tacotron2, điểm khác biệt giữa chúng là gì ?
- Intermediate Feature Representation hay còn gọi là dạng biểu diễn trung gian trước khi chuyển đổi thành giọng nói.
- Thay thế module CBHG bằng các lớp Convolution
- Vocoder dùng WaveNet thay thế thuật toán Griffin Algorithm.
Bây giờ chúng ta sẽ đi vào tìm hiểu chi tiết tại sao như vậy ?
II. Kiến trúc mô hình.
Trong phần này chúng ta sẽ đi qua 2 đề mục nhỏ:
- Dạng biếu diễn đặc trưng trung gian.
- Spetrogram Prediction Network
Phần thuật toánh sinh âm thanh WaveNet ta sẽ tách riêng thành một bài viết riêng để phân tích chi tiết hơn.
2.1. Dạng biếu diễn đặc trưng trung gian.
Nếu như trong bài báo về kiến trúc Tacotron, tác giả sử dụng Linear Spectrogram làm biểu diễn trung gian trước khi đi vào Vocoder để sinh ra âm thanh. Tuy nhiên, việc cảm nhận âm thanh của tai người là phi tuyến tính nên việc sử dụng Mel spectrogram đem lại kết quả tốt hơn nhiều so với Linear Spectrogram. Nếu các bạn chưa biết hai khái niệm này, các bạn có thể xem lại tại bài Một số kiến thức cơ bản về Text2Speech
Mel Spectrogram có thể thu được bằng cách áp dụng các biến đổi phi tuyến lên trục tần số của đồ thị thuật toán Short-time Fourier Transform. Mục đích có thể giúp nhấn mạnh các âm thanh ở tần số thấp và giảm nhấn mạnh các âm thanh ở tần số cao phù hợp với khả năng nghe của con người.
Bài báo cũng đề cập linear spectrogram bị mất mát những thông tin về pha tuy nhiên thuât toán sinh tương ứng là Griffin-Lim lại có thể dự đoán thông tin mất mát đó. Mel spectrogram thậm chí mất mát nhiều thông tin hơn. Tuy nhiên khi so sánh với đầu vào dùng cho đặc trưng âm thanh và ngôn ngữ của kiến trúc WaveNet gốc thì mel spectrogram tương đối đơn giản hơn, là dạng biểu diễn tín hiệu audio âm thanh ở level thấp hơn. Còn lý do tại sao tác giả dùng WaveNet vì theo thí nghiệm thời điểm bấy giờ, WaveNet đem lại kết quả vượt trội hơn.
2.2. Spectrogram Prediction Network.
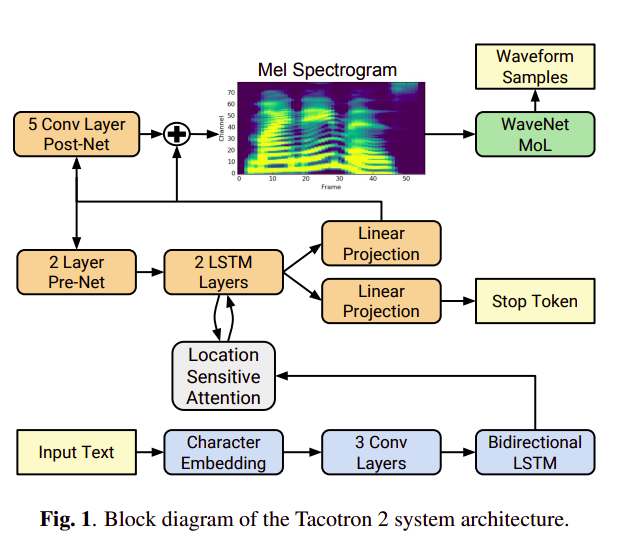
Như hình một miêu tả, kiến trúc Tacotron2 bao gồm một phần encoder và một phần decoder với attention giống như kiểu kiến trúc được dùng cho Tacotron trước đây. Kiến trúc Tacotron nhận đầu vào hai giá trị <text, audio>. Thông này sau đó được xử lý như sau:
- Từ audio đầu vào chúng ta qua biến đổi Short Time Fourier Transform (STFT) ra mel spectrogram với thông số như sau: 50 ms frame size, 12.5 ms frame hop. Sau đó chuyển đổi cường độ STFT sang mel scale bằng mel filterbank 80 channel trải dài 125Hz đến 7.6Khz.
- Chuỗi text đầu vào được biến đổi thành character embedding 512 chiều.

Sau đó character embedding này được cho một chuỗi gồm 3 lớp convolution trong đó mỗi convolution chứa 512 filters với kích thước 5 x 1 (kéo dài 5 character) theo sau đó là batch normalization và relu activation. Các lớp convolution này đóng vai trò mô hình hóa tương quan về ngữ cảnh trong chuỗi kí tự đầu vào. Đầu ra của lớp convolution cuối cùn được cho vào làm BI LSTM gồm 512 units tức mỗi chiều có 256 unit để trích xuất đặc trưng.
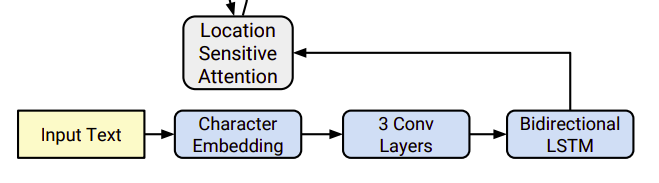
Đầu ra của encoder được cho vào phần mạng attention để tổng hợp đặc trưng dưới dạng vector có kích thước cố định. Ở đây tác giả sử dụng location-sensitive location chuyên sử dụng cho các bài xử lý tiếng nói được đề cập trong bài báo Attention-Based Models for Speech Recognition
. Attention này có điểm đặc biệt là nó sử dụng attention weight ở các decoder time steps trước làm thông tin bổ sung để tính toán trọng số. Điều này tạo ra tính nhất quán về đặc điểm luôn tịnh tiến lên phía trước giữa mô hình và input đầu vào. Xác suất chú ý được tính thông qua chiếu inputs và đặc trưng vị trí lên một ma trận đặc trưng có kích thước 128 chiều.

Decoder ở đây là một autogressive recurrent neural network. Mục đích của mạng này dùng để dự đoán mel spectrogram từ đặc trưng được ma hóa ở encoder. Kết quả dự đoán của timestep trước ở decoder cho qua 1 lớp biến đổi tuyến tính được cho vào một pre-net bao gồm 2 lớp fully connected, mỗi lớp có kích thước 256 theo sau là lớp Relu. Lớp prenet này đóng vai trò kết xuất đặc trưng hỗ trợ cho việc học trọng số chú ý tốt hơn. Sau đó, kết quả của lớp pre-net được nối với attention context vector ở phần trước cho vào 2 lớp LSTM một chiều với 512 unit mỗi lớp. Tiếp theo, chúng ta tiêp tục nối output của LSTM và attention context vector làm một cho qua biến đổi tuyến tính để dự đoán spectrogram.
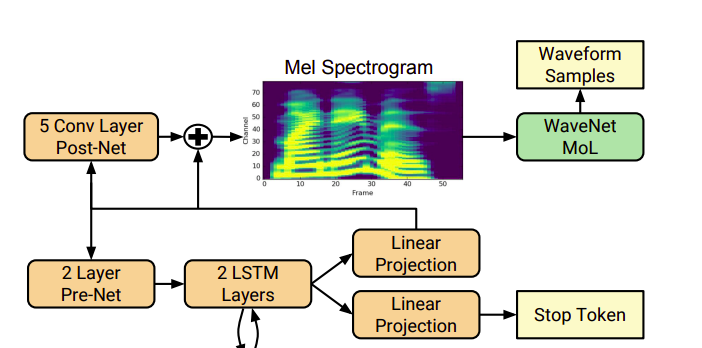
Các spectrogram này sẽ đi qua 5 lớp convolution được gọi là post-net tạo ra thông tin bổ sung vào với spectrogram đã được dự đoán để cải thiện khả năng tái cấu trúc thành âm thanh. Lớp post-net này gồm có 512 filters có kích thước 5×1, theo sau đó là batch normalization và tanh activation.
Để ý một chút, ngoài lớp linear projection để dự đoán spetrogram đã được đề cập bên trên, song song đó ta cũng có một lớp dùng để dự đoán stop token dùng để tự động kết thúc trước khi đến kích thước cố định.
III. Lời kết
Trong cả hai bài về kiến trúc Tacotron và Tacotron 2, mình đều chưa đề cập đến một phần không thể thiếu trong các kiến trúc Text2Speech đó là Vocoder. Phần này chúng ta sẽ cùng nhau tìm hiểu ở các bài tới đây. Cảm ơn các bạn đã theo dõi bài viết của mình. Dịch bệnh đang ở thời điểm căng thẳng. Mình cũng đang là một F0 chính hiệu =)))) và cảm nhận những ảnh hưởng của nó gây ra. Mong mọi người giữ sức khỏe thật tốt để bảo vệ chính bản thân và cùng mình tiếp tục đồng hành trong những bài viết tới nhé.
Tham khảo
Nguồn: viblo.asia