Trước tiên mình xin cảm ơn tất cả mọi người đã, đang và sẽ đọc bài viết này của mình. Đây là bài viết đầu tay của mình với mục địch chia sẻ, trao đổi kiến thức nên sẽ không thể tránh khỏi những sai sót, rất mong nhận được ý kiến của các bạn để các bài viết sau này của mình được tốt hơn.
Trong bài viết này mình sẽ giới thiệu về kiến trúc FastSpeech dựa trên bài báo FastSpeech: Fast, Robust and Controllable
Text to Speech, do đó yêu cầu một số kiến thức cơ bản, các bạn có thể tham khảo tại bài viết Một số kiến thức cơ bản về Text2Speech.
I. Tổng quan
Text2Speech hay Text to Speech (TTS) là một công nghệ giúp chuyển chữ viết thành giọng nói, đã được nghiên cứu từ vài chục năm trước và đặc biệt phát triển mạnh trong những năm gần đây nhờ sự phát triển của trí tuệ nhân tạo để đáp ứng yêu cầu về chất lượng giọng nói. Đã có rất nhiều mô hình học sâu (Deep Learning – DL) về lĩnh vực này, như Tacotron, Tacotron2 (trên viblo cũng đã có series về chủ đề này, các bạn có thể tham khảo tại đây), Deep Voice 3. Những mô hình này có điểm chung là sẽ tạo ra các mel-spectrogram từ chữ viết sau đó tổng hợp thành giọng nói bằng cách sử dụng các công cụ gọi là vocoder như Griffin-Lim, WaveNet, WaveGlow. Tuy nhiên theo tác giả, các mô hình trên có một số nhược điểm:
- Tốc độ suy luận (inference) chậm: Do các mô hình trên đều dựa trên RNN, hàng trăm hoặc hàng nghìn mel-spectrogram với cái sau được dự đoán dựa vào cái trước sẽ làm giảm tốc độ suy luận.
- Giọng nói tổng hợp được thường gặp vấn đề với những từ bị bỏ qua hoặc lặp lại.
- Thiếu khả năng kiểm soát tốc độ và giọng nói.
Do đó tác giả đề xuất mô hình FastSpeech nhận vào các âm vị (phoneme), sử dụng mạng chuyển tiếp dựa trên “self-attention” và convolution 1D để dự đoán chuỗi mel-spectrogram (chuỗi những cửa sổ phổ). Mô hình này đã giải quyết các vấn đề:
- Tăng tốc quá trình tổng hợp bằng cách tạo ra mel-spectrogram một cách song song.
- Bộ dự đoán thời lượng âm vị (Phoneme duration predictor) giúp hạn chế được các vấn đề mất từ và lặp từ.
- Bộ điều chỉnh độ dài (length regulator) xác định độ dài của các mel-spectrograms từ đó dễ dàng điều chỉnh tốc độ giọng nói bằng cách kéo dài hoặc rút ngắn thời lượng của âm vị cũng như điều chỉnh âm điệu bằng cách thêm vào các khoảng ngắt giữa các âm vị liền kề.
Bây giờ chúng ta cùng đi tìm hiểu xem mô hình hoạt động như thế nào.
II. Kiến trúc mô hình
Thay vì dựa trên cấu trúc encoder-attention-decoder, fastspeech dựa trên cấu trúc chuyển tiếp (feed-forward), cấu trúc tổng thể của mô hình được biểu diễn như hình dưới đây:
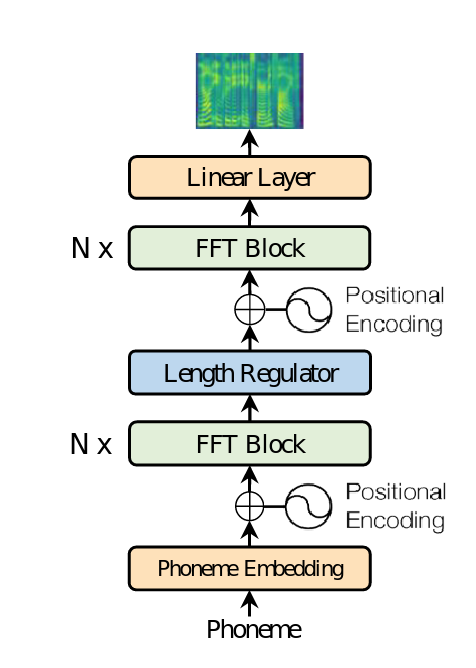
Ngoài các thành phần cở bản của một mô hình xử lý ngôn ngữ là Embedding và Positional Encoding, thứ làm cho fastspeech khác với các mô hình khác đó chính là FFT block được chia thành 2 phần, N khối ở về phía âm vị và N khối ở phía phổ tín hiệu được kết nối với nhau bởi Length Regulator (N có thể được coi là một hyperparameter của mô hình). Vậy những thành phần này là gì, mình sẽ trình bày bên dưới, hãy cùng theo dõi nhé!
1. Feed-Forward Transformer
Thành phần xương sống của fastspeech là những khối thành phần dựa trên self-attention của mô hình Transformer và mạng tích chập 1 chiều 1D convolution (thay vì 2 lớp Dense như các mô hình transformer khác) được tác giả gọi là “Feed-Forward Transformer” (FFT) (Lưu ý: phép biến đổi fourier nhanh trong xử lý tín hiệu cũng thường được ký hiệu là FFT nhưng trong bài viết này không sử dụng đến nên từ giờ đến hết bài viết này, “FFT” sẽ chỉ sử dụng để nói về “Feed-Forward Transformer” ). Nói vậy có thể hơi khó hình dung, hãy nhìn vào hình biểu diễn cấu trúc của khối FFT sẽ dễ hơn:
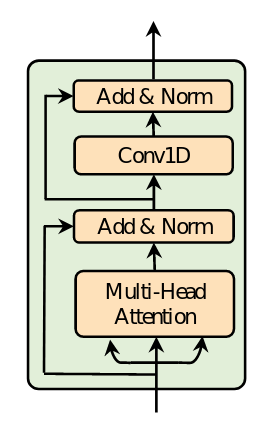
Từ hình vẽ chúng ta có thể dễ dàng nắm được cấu trúc của một FFT Block, bao gồm một self-attention cụ thể là multi-head attention (mình sẽ không đi vào chi tiết cơ chế của attention, đã có nhiều bài viết về vấn đề này, các bạn có thể tham khảo trên blog về AI của KhanhBlog hoặc trên Viblo). Như đã đề cập ở trên, khác với các cấu trúc Transformer khác, 2 lớp Conv 1D với hàm kích hoạt là ReLU được sử dụng thay cho 2 lớp Dense. Lý giải cho sự khác biệt này, tác giả cho rằng những trạng thái ẩn liền kề nhau thì liên quan chặt chẽ hơn trong âm vị và trong chuỗi mel-spectrogram. Điều này đã được tác giả thể hiện bằng thực nghiệm. Sau mỗi khối multi-head attention và Conv1D là một kết nối tắt (residual connection), layer normalization và dropout.
2.Length Regulator
Một âm có thể ngắn hoặc dài, do đó có thể biểu diễn bằng số lượng các cửa sổ mel-spectrogram khác nhau. Vì vậy nếu chỉ sử dụng các khối FFT sẽ làm sai lệch giữa âm và chuỗi các phổ của chúng. Length Regulator (LR) sinh ra để giải quyết vấn đề đó, ngoài ra LR còn giúp điều khiển tốc độ và ngữ điệu của giọng nói. Nghe thật thú vị phải không? Cấu trúc của nó như sau:
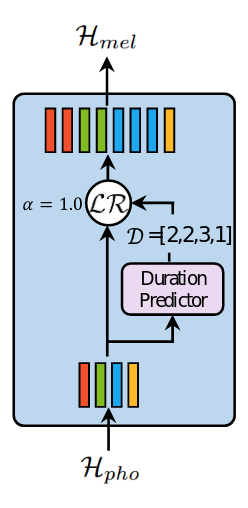
Thông thường, mỗi mô hình sẽ có các tham số để tính mel-spectrogram cố định, mỗi cửa sổ sẽ tương ứng với một thời gian nhỏ, mỗi một âm sẽ có độ dài khác nhau do đó sẽ tương ứng với số lượng các cửa sổ phổ khác nhau, ký hiệu số này là dd, gọi là thời lượng âm. Thời lượng âm sẽ được dự đoán qua bộ dự đoán “Duration Predictor”. Sau đó dựa vào dd, LR sẽ điều chỉnh kích thước của vector trạng thái ẩn bằng cách lặp lại các trạng thái một số lần bằng với thời lượng âm tương ứng trong dd Nghe trìu tượng quá nhỉ, hãy cùng xem xét ví dụ sau:
Giả sử Hpho=[h1,h2,…,hn]mathcal{H}_{pho} = [h_1, h_2, …, h_n] (nn là độ dài của chuỗi âm), với thời lượng âm D=[d1,d2,…,dn]mathcal{D} = [d_1, d_2, …, d_n] thỏa mãn Σi=1ndi=mSigma^{n}_{i=1} d_i = m với mm là độ dài chuỗi mel-spectrogram. Bộ điều chỉnh thời lượng âm LRmathcal{LR} là có tác dụng như một hàm:
Hmel=LR(Hpho,D,α)mathcal{H}_{mel} = mathcal{LR}(mathcal{H}_{pho},mathcal{D}, alpha)
với αalpha là một hyperparameter để xác định kích thước chuỗi mel-spectrogram Hmelmathcal{H}_{mel} và từ đó kiểm soát tốc độ của giọng đọc. Cụ thể hơn, xét
Hpho=[h1,h2,h3,h4]vaˋD=[2,2,3,1]mathcal{H}_{pho} = [h_1, h_2, h_3, h_4] và mathcal{D} = [2, 2, 3, 1]
thì với α=1alpha = 1:
Hmel=[h1,h1,h2,h2,h3,h3,h3,h4]mathcal{H}_{mel} = [h_1, h_1, h_2, h_2, h_3, h_3, h_3, h_4]
Khi α=1.3alpha = 1.3 hoặc α=0.5alpha = 0.5 thời lượng âm lúc này sẽ được điều chỉnh:
Dα=1.3=[2.6,2.6,3.9,1.3]≈[3,3,4,1]mathcal{D}_{alpha=1.3} = [2.6, 2.6, 3.9, 1.3] approx [3, 3, 4, 1]
Dα=0.5=[1,1,1.5,0.5]≈[1,1,2,1]mathcal{D}_{alpha=0.5} = [1, 1, 1.5, 0.5] approx [1, 1, 2, 1]
lúc này:
Hmel=[h1,h1,h1,h2,h2,h2,h3,h3,h3,h3,h4](α=1.3)mathcal{H}_{mel} =[h_1, h_1, h_1, h_2, h_2, h_2, h_3, h_3, h_3, h_3, h_4] (alpha=1.3)
Hmel=[h1,h2,h3,h3,h4](α=0.5)mathcal{H}_{mel} =[h_1, h_2, h_3, h_3, h_4] (alpha=0.5)
Ngoài điều chỉnh tốc độ đọc, LRmathcal{LR} còn có thể điều chỉnh thời lượng của các khoảng ngắt để cho giọng đọc đa dạng hơn.
3. Duration Predictor
Một thành phần không thể thiếu của Length Regulator chính là Duration Predictor – thành phần dự đoán mỗi âm vị tương ứng với bao nhiêu cửa sổ mel-spectrogram. Cấu trúc của Duration Predictor như sau:
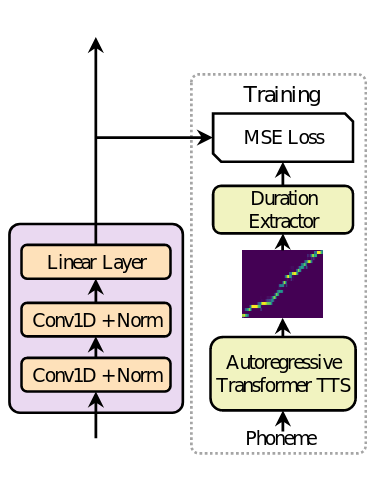
Mỗi khối Duration Predictor bao gồm 2 lớp Conv1D với hàm kích hoạt ReLU theo sau là layer normalization và lớp dropout, cuối cùng là một lớp Linear.
Tuy nhiên quá trình huấn luyện các tham số của Duration Predictor có hơi đặc biệt: tác giả sử dụng một mô hình gọi là “teacher model” dựa trên mạng hồi quy Transformer để trích xuất thời lượng của mỗi âm vị, cụ thể với mỗi cặp dữ liệu, trích xuất các attention alignments của decoder-to-encoder trong teacher model. Bởi vì mô hình sử dụng multi-head attention nên sẽ có nhiều head của attention. Tuy nhiên không phải tất cả các head này đều được sử dụng mà tác giả đã đưa ra một tỉ lệ (focus rate)
F=1S∑s=1Smax1≤t≤Tas,tF = frac{1}{S}sum_{s=1}^{S}{max_{1 leq t leq T} a_{s,t}}
trong đó SS và TT lần lượt là độ dài của chuỗi mel-spectrogram và chuỗi âm vị, as,ta_{s,t} là phần tử ở hàng ss-th cột tt-th của ma trận attention. Tính giá trị FF cho từng head và lấy head ứng có giá trị của FF là lớn nhất. Sau cùng, tính thời lượng của âm D=[d1,d2,…,dn]mathcal{D} = [d_1, d_2, …, d_n] theo công thức
di=∑s=1S[argmaxtas,t=i]d_i = sum_{s=1}^S [mathop{argmax}_{t} a_{s,t} = i]
Và cuối cùng chúng ta đã có được ground-truth của thời lượng âm Dmathcal{D}. Giá trị này sau đó được tính lỗi bằng MSE và được cập nhật các tham số của Duration Predictor.
III. Lời kết
Cảm ơn các bạn đã theo dõi bài viết của mình đến đây. Như vậy là mình vừa trình bày về kiến trúc của mô hính FastSpeech, một mô hình có tốc độ cao, mạnh mẽ và có khả năng kiểm soát các hệ thống Text To Speech. Cũng giống như các mô hình TTS khác, để có thể tạo ra được tiếng nói cần sử dụng thêm mô hình tổng hợp tiếng nói. Chi tiết các bạn có thể tham khảo trong bài báo gốc của tác giả. Ngoài ra trong bài báo tác giả còn nói đến quá trình chuẩn bị dữ liệu và huấn luyện mô hình, link của bài mình sẽ để dưới phần tham khảo. Một lần nữa cảm ơn các bạn đã theo dõi bài viết của mình, nếu có thể thì vui lòng cho mình xin 1 vote 😁.
Tham khảo
Nguồn: viblo.asia