Chào mọi người, hôm nay mình sẽ cùng mọi người học cách xử lý dữ liệu văn bản cũng như fine-tune model với text classification task.
Thêm các thư viện để xử lý dữ liệu
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from collections import defaultdict
from collections import Counter
from nltk.corpus import stopwords
import string
plt.style.use('ggplot')
import re
from tqdm import tqdm
Exploratory Data Analysis
Bộ data mình dùng cho nhiệm vụ này là disaster tweet trên kaggle, mọi người có thể tải qua link này: https://www.kaggle.com/c/nlp-getting-started/data
train = pd.read_csv('train.csv')
train.head(5)

print('There are {} rows and {} columns in train'.format(train.shape[0],train.shape[1]))
print('There are {} rows and {} columns in test'.format(test.shape[0],test.shape[1]))
Class distribution
x = train.target.value_counts()
sns.barplot(x.index, x)
plt.gca().set_ylabel('samples')
plt.show()
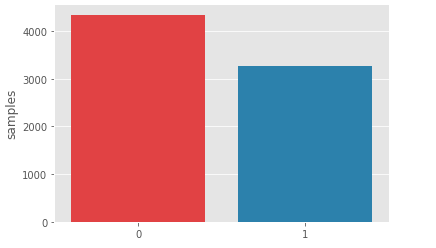
Ta có thể thấy rằng phân phối của tập train hơi lệch về phần non-disaster tweets . Nhưng ko sao chỉ là hơi lệch thôi 
Average word length in a tweet
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 5))
word = train[train['target']==1]['text'].str.split().map(lambda x: [len(i) for i in x])
sns.distplot(word.map(lambda x: np.mean(x)), ax=ax1, color='red')
ax1.set_title('Disaster tweets')
word = train[train['target']==0]['text'].str.split().map(lambda x: [len(i) for i in x])
sns.distplot(word.map(lambda x: np.mean(x)), ax=ax2, color='blue')
ax2.set_title('Not Disaster tweets')
plt.show()
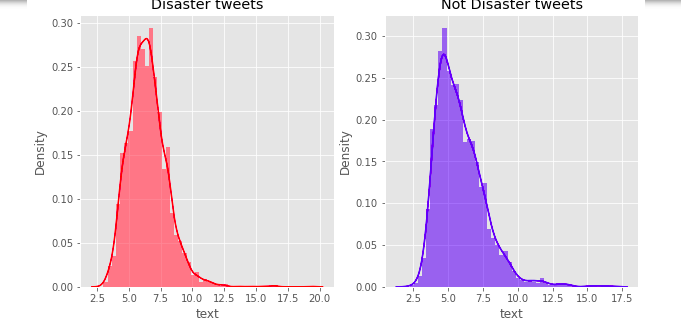
Ta có thể thấy rằng bên phía disaster tweets có lượng chữ dùng cho mỗi từ nhiều hơn(có thể là do nhấn mạnh).
Xem xét lượng stopwords trong các sample
Tạo một hàm tạo corpus riêng cho mỗi target để tiện so sánh
def create_corpus(target):
corpus = []
for x in train[train['target']==target]['text'].str.split():
for i in x:
corpus.append(i)
return corpus
Cùng thử xem các stopword nào hay được dùng nhất
stop = set(stopwords.words('english'))
corpus = create_corpus(0)
dic = defaultdict(int)
for word in corpus:
if word in stop:
dic[word] += 1
top = sorted(dic.items(), key=lambda x:x[1], reverse=True)[:10]
x, y = zip(*top)
sns.barplot(list(x), list(y))
plt.show()
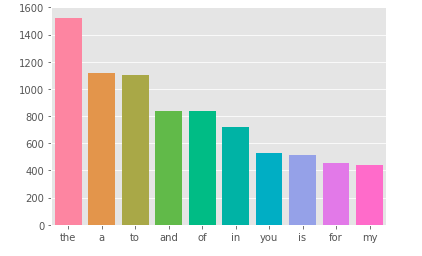
Tương tự với target = 1 ta có:
Trong nhiệm vụ text classification, stopwords đóng vai trò không quá quan trọng , chúng ta có thể xem xét loại bỏ chúng giúp giảm chiều dài câu.
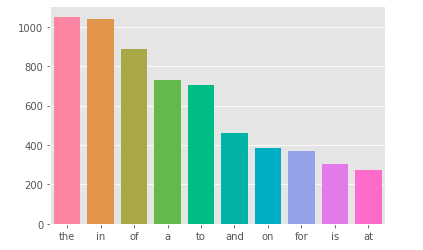
Xem xét lượng dấu câu
plt.figure(figsize=(10, 5))
corpus = create_corpus(1)
dic = defaultdict(int)
import string
special = string.punctuation
for word in corpus:
if word in special:
dic[word] += 1
top = sorted(dic.items(), key= lambda x: x[1], reverse=True)
x, y = zip(*top)
sns.barplot(list(x), list(y))
plt.show()
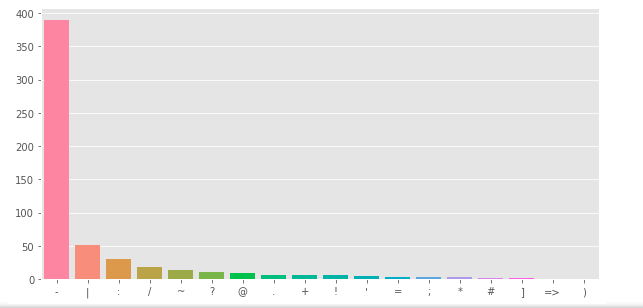
Tương tự với target = 0
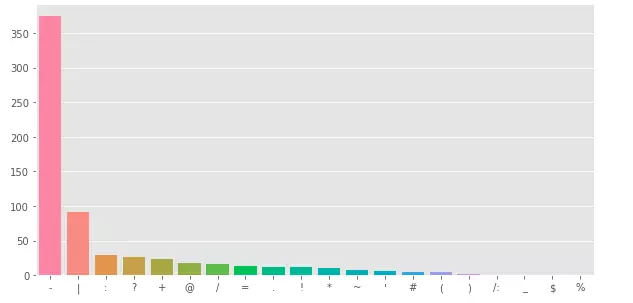
Data Cleaning
def remove_URL(text):
url = re.compile(r'httpS+|wwwS+')
return url.sub(r'', text)
def remove_html(text):
html = re.compile(r'<.*?>')
return html.sub(r'', text)
def remove_emoji(text):
emoji_pattern = re.compile("["
u"U0001F600-U0001F64F" # emoticons
u"U0001F300-U0001F5FF" # symbols & pictographs
u"U0001F680-U0001F6FF" # transport & map symbols
u"U0001F1E0-U0001F1FF" # flags (iOS)
u"U00002702-U000027B0"
u"U000024C2-U0001F251"
"]+", flags=re.UNICODE)
return emoji_pattern.sub(r'', text)
def remove_punct(text):
table = str.maketrans('', '', string.punctuation)
return text.translate(table)
def remove_tag(text):
tag = re.compile(r'@S+')
return tag.sub(r'', text)
def remove_stw(text):
for x in text.split():
if x.lower() in stop:
text = text.replace(x, "", 1)
return text
def remove_number(text):
num = re.compile(r'[-+]?[.d]*[d]+[:,.d]*')
return num.sub(r' NUMBER', text)
Do mình thấy việc xóa stopwords làm giảm hiệu suất mô hình đi 1 chút và RAM của mình vẫn còn để xử lý nên mình sẽ không xóa stopwords, nhưng mọi người có thể thử
def clean_tweet(text):
text = remove_URL(text)
text = remove_html(text)
text = remove_emoji(text)
text = remove_punct(text)
text = remove_tag(text)
text = remove_number(text)
# text = remove_stw(text) ở đây thì mình thấy xóa stopwords làm giảm hiệu xuất model của mình, các bạn có thể thử
return text
df['text'] = df['text'].map(lambda x: clean_tweet(x))
Ở đây ta sẽ đổi 1 số từ được viết tắt thành các từ hoàn chỉnh, giúp cho tokenizer hoạt động hiệu quả(Mình tham khảo ở link này: https://www.kaggle.com/ghaiyur/ensemble-models-versiong)
def word_abbrev(word):
return abbreviations[word.lower()] if word.lower() in abbreviations.keys() else word
df['text'] = df['text'].str.split().map(lambda x: [word_abbrev(i) for i in x]).map(lambda x: ' '.join(x))
Chia train-test set
Mình sẽ chia train-test theo tỷ lệ 0.7:0.3 do lượng dự liệu tương đối nhỏ.(Mình tham khảo qua video của Andrew Ng:
https://www.youtube.com/watch?v=1waHlpKiNyY)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(list(df['text']), list(df['target']), test_size=0.3)
Model
Ở đây mình dùng PyTorch và sử dụng thư viên transformers của Hugging Face để sử dụng pretrained Roberta. Có 2 hướng tiếp cận là fine-tuning và feature-based. Ở đây mình sẽ fine-tuning để cho mô hình Roberta có thể học được.
from transformers import RobertaTokenizer, RobertaModel
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
DEVICE = torch.device('cuda:1')
tokenizer = RobertaTokenizer.from_pretrained('roberta-base')
Ở đây mình sử dụng bidirectional LSTM cho nhiệm vụ downstream task(text classification) và Embedding đã được pre-trained của Roberta và trích xuất ra layer 12 của Roberta
class Classifier(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, dropout):
super(Classifier, self).__init__()
self.embedding = RobertaModel.from_pretrained('roberta-base')
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True, dropout=dropout, bidirectional=True)
self.out = nn.Linear(hidden_size*2, 2)
self.num_layers = num_layers
self.hidden_size = hidden_size
def forward(self, X, init):
embedded = self.embedding(X).last_hidden_state
out, _ = self.lstm(embedded, init)
output = self.out(out[:, -1, :])
return output
def initialize(self, bsz):
return (torch.zeros(2 * self.num_layers, bsz, self.hidden_size, device=DEVICE),
torch.zeros(2 * self.num_layers, bsz, self.hidden_size, device=DEVICE))
Khởi tạo model
from transformers import AdamW
from torch.optim.lr_scheduler import StepLR
batch_size = 32
model = Classifier(768, 256, 2, 0.1).to(DEVICE)
criterion = nn.CrossEntropyLoss()
optimizer = AdamW(model.parameters(), lr=5e-5, eps=1e-8)
train_iter = [i for i in zip(X_train, y_train)]
test_iter = [i for i in zip(X_test, y_test)]
scheduler = StepLR(optimizer, step_size=15, gamma=0.1)
Tạo hàm train theo epoch
from torch.utils.data import DataLoader
def train_epoch(model, optimizer):
model.train()
losses = 0
train_dataloader = DataLoader(train_iter, batch_size=batch_size, shuffle=True)
correct = 0
total = 0
for X, y in tqdm(train_dataloader, colour='green'):
tokens = tokenizer(X, return_tensors='pt', padding=True)['input_ids'].to(DEVICE)
init = model.initialize(tokens.size(0))
y = y.to(DEVICE)
output = model(tokens, init)
_, predicted = torch.max(output.data, 1)
total += y.size(0)
correct += (predicted == y).sum().item()
optimizer.zero_grad()
loss = criterion(output, y)
loss.backward()
optimizer.step()
losses += loss.item()
print('Accuracy: ', 100 * correct / total, "%" )
return losses / len(train_dataloader)
Tạo hàm test
def test(model):
model.eval()
correct = 0
total = 0
test_dataloader = DataLoader(test_iter, batch_size=32, shuffle=False)
for X, y in tqdm(test_dataloader, colour='green'):
tokens = tokenizer(X, return_tensors='pt', padding=True)['input_ids'].to(DEVICE)
init = model.initialize(tokens.size(0))
y = y.to(DEVICE)
output = model(tokens, init)
_, predicted = torch.max(output.data, 1)
total += y.size(0)
correct += (predicted == y).sum().item()
print('Accuracy: ', 100 * correct / total, "%" )
Training
from timeit import default_timer as timer
NUM_EPOCHS = 100
for epoch in range(1, NUM_EPOCHS+1):
start_time = timer()
train_loss = train_epoch(model, optimizer)
scheduler.step()
end_time = timer()
print((f"Epoch: {epoch}, Train loss: {train_loss:.3f}, "f"Epoch time = {(end_time - start_time):.3f}s"))
test(model)
Tổng kết
Như vậy mình đã cùng mọi người tìm hiểu về cách xử lý dữ liệu dạng text và fine-tune một pretrained models. Mong là bài viết có ích cho mọi người.
Tài liệu tham khảo
https://www.kaggle.com/gunesevitan/nlp-with-disaster-tweets-eda-cleaning-and-bert
https://www.kaggle.com/shahules/basic-eda-cleaning-and-glove
Nguồn: viblo.asia