Hello mọi người, hẳn là mọi người vẫn hay dùng Pandas để xử lý dữ liệu dạng DataFrame đúng không nhỉ? Hôm nay mình sẽ giới thiệu một thư viện mới Polars – một thư viện xử lý dữ liệu dạng bảng biểu được base trên Rust, tốc độ xử lý của thư viện này nhanh hơn cả Pandas mà mọi người vẫn hay dùng. Bên cạnh đó thư viện này cũng dễ dùng và hữu ích không thua kém gì Pandas. Chúng ta cùng nhau tìm hiểu nhé!!!
Polars có thể sử dụng với các ngôn ngữ lập trình như Rust | Python | NodeJS | …, bên cạnh đó còn có một số đặc điểm:
-
Đa luồng
-
Polars không sử dụng index cho DataFrame. Việc loại bỏ index giúp thao tác DataFrame dễ dàng hơn nhiều.
-
Polars đại diện cho dữ liệu bên trong bằng cách sử dụng mảng Mũi tên Apache trong khi Pandas lưu trữ dữ liệu bên trong bằng cách sử dụng mảng NumPy. Mảng Mũi tên Apache hiệu quả hơn nhiều trong các lĩnh vực như: thời gian tải, sử dụng bộ nhớ và tính toán.
-Polars hỗ trợ lazy evaluation. Polars kiểm tra các truy vấn của bạn, tối ưu hóa chúng và tìm cách tăng tốc truy vấn hoặc giảm mức sử dụng bộ nhớ.
Install Polars trong python
Mọi người có thể dùng 2 câu lệnh quen thuộc để cài đặt thư viện này như sau:
- với Pip
$ pip install polars
- Với conda
$ conda install polars
Tạo một Polars DataFrame
import polars as pl
df = pl.DataFrame({'Company':['Ford','Toyota','Toyota','Honda','Toyota','Ford','Honda','Subaru','Ford','Subaru'],'Model':['F-Series','RAV4','Camry','CR-V','Tacoma','Explorer','Accord','CrossTrek','Escape','Outback'],'Sales':[58283,32390,25500,18081,21837,19076,11619,15126,13272,10928]})
df
Kết quả thu được:
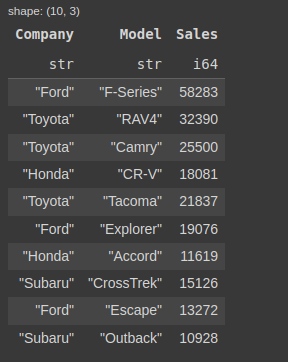
Hình: DataFrame
Check df types:

Sử dụng Polars
Tiếp theo check columns và rows cũng tương tự như Pandas
df.columns
df.rows
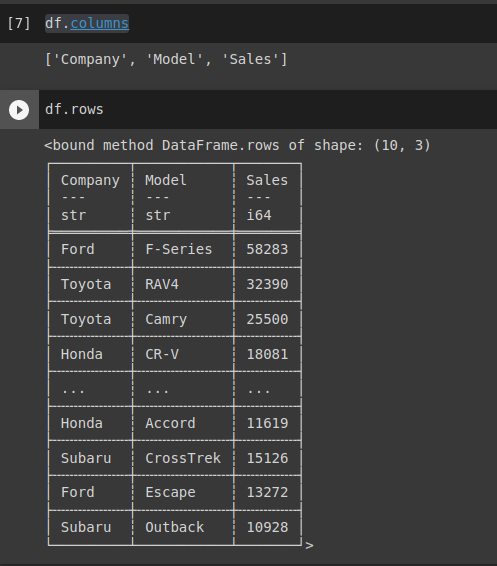
Hình: check columns và rows
Select columns
Ở pandas thì việc lấy ra các cột cũng khá đơn giản, trong polars cũng tương tự, chúng ta cùng xem xem nhé
Mình sẽ thử lấy ra cột Model
df.select('Model')Kết quả thu được :
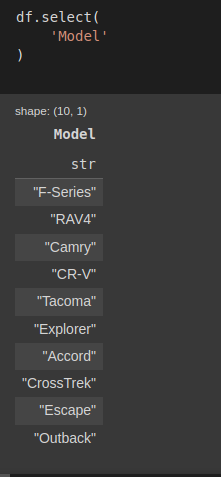
Hình: select cột Model
Và khi muốn lấy ra 2 cột thì chúng ta phải select dưới dạng list:
df.select(['Model','Company'])Kết quả thu được:
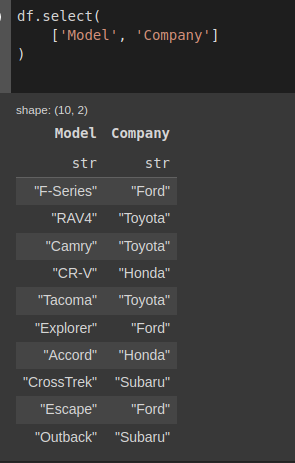
Hình: select 2 cột
Và chúng ta cũng có thể select các cột theo kiểu dữ liệu như dưới đây:
df.select(
pl.col(pl.Int64)# all Int64 columns)Kết quả thu được:
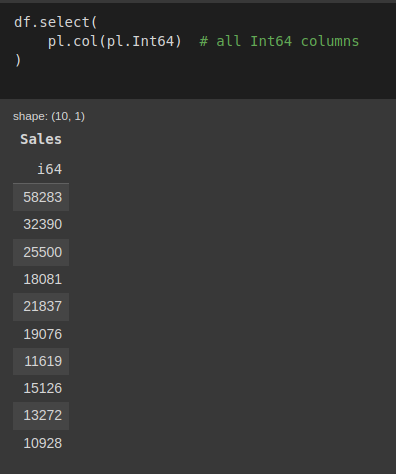
Hình: select theo kiểu dữ liệu
Và cũng có thể vừa lựa chọn vừa sort theo cột luôn:
df.select(
pl.col(['Model','Sales']).sort_by('Sales'))Kết quả thu được sẽ được sort theo thứ tự tăng dần của cột Sales
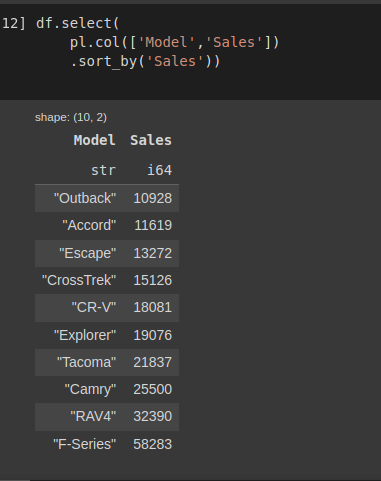
Hình: select và sort
Select theo rows
Tương tự thì mình cũng có thể select theo từng hàng.
- Lấy hàng đầu tiên trong bảng dữ liệu.
df.row(0)# get the first row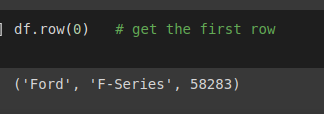
Hình: lấy hàng đầu tiên
Sử dụng filter để lấy tất cả các hàng có một giá trị nào đó
df.filter(
pl.col('Company')=='Toyota')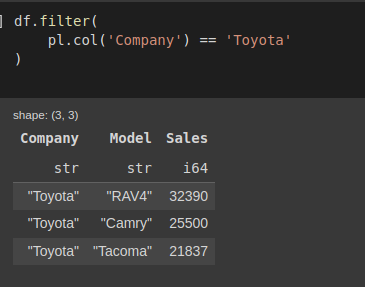
Hình: lấy tất cả các hàng có cùng 1 giá trị nào đó
Select columns và rows
Chúng ta có thể lấy ra cột Model với Company và toyota
df.filter(
pl.col('Company')=='Toyota').select('Model')Kết quả thu được:
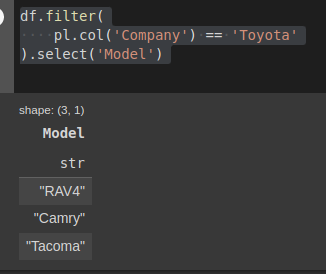
Hình: lấy ra cột Model với Company và toyota
Cleaning dữ liệu
Mọi người có thể down tập dữ liệu ở đây.
import polars as pl
q =(
pl.scan_csv('/content/test_clean.csv'))
df = q.collect()
df.head()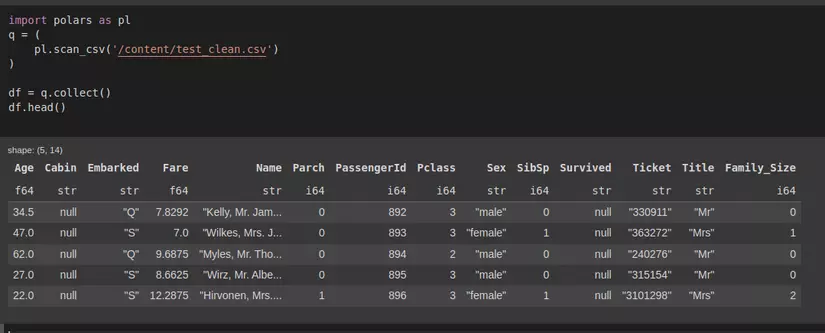
hình: data
check null data
select(pl.col('Cabin').is_null())với hàm is_null() này giá trị trả về là boolean, nếu bạn muốn tính tổng giá trị null thì thực hiện như sau:
df.select(pl.col('Cabin').is_null().sum())Kết quả trả về:
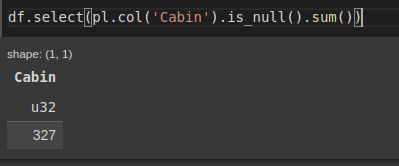
Tính giá trị null cho các cột
for col in q.collect():print(f'{col.name} - {col.is_null().sum()}')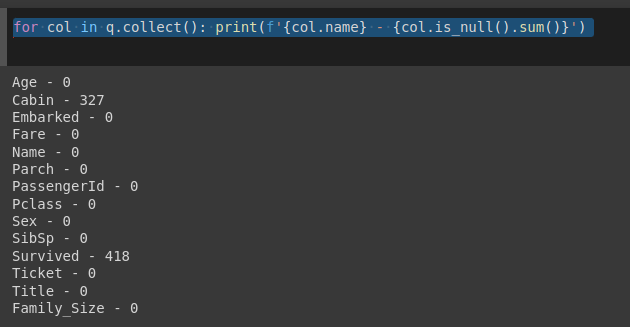
kết quả thu được như hình trên.
Fill các gía trị null
df.fill_null(strategy='backward').fill_null(strategy='forward').select(pl.col('Cabin').is_null().sum())Kết quả thu được:

Mọi người cũng có thể fill_null bằng các giá trị mong muốn khác
Drop các giá trị null
q =(
pl.scan_csv('/content/test_clean.csv').drop_nulls(subset=['Age','Embarked']))
q.collect()Xóa các giá trị duplicate
Khởi tạo 1 dataframe mới:
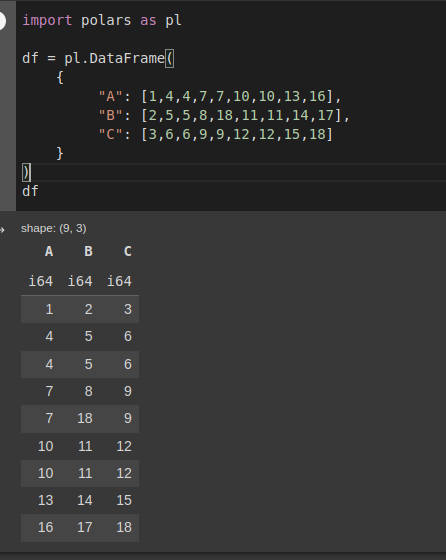
import polars as pl
df = pl.DataFrame({"A":[1,4,4,7,7,10,10,13,16],"B":[2,5,5,8,18,11,11,14,17],"C":[3,6,6,9,9,12,12,15,18]})
df
Sử dụng hàm unique() để xóa duplicate
Kết quả thu được:
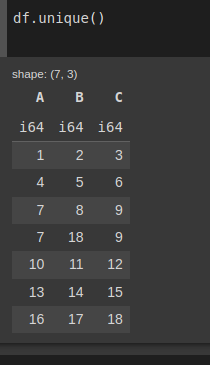
Hình: xóa duplicate
Kết Luận
Mình đã giới thiệu một cách đơn giản nhất về thư viện Polars này, nếu nhìn tổng thể thì nó khá giống Pandas và dễ dùng, vì vậy đây cũng là một lựa chọn nếu như bạn muốn sử dụng một FrameWork mới để làm việc với dữ liệu dạng bảng. Cảm ơn mọi người đã theo dõi bài viết của mình. Nếu cảm thấy hữu ích thì Upvoted cho mình nhé.
Reference
https://github.com/pola-rs/polars
https://pola-rs.github.io/polars-book/user-guide/quickstart/intro.html
https://www.codemag.com/Article/2212051/Using-the-Polars-DataFrame-Library
https://towardsdatascience.com/getting-started-with-the-polars-dataframe-library-6f9e1c014c5c
Nguồn: viblo.asia