Chọn cấu hình thư viện
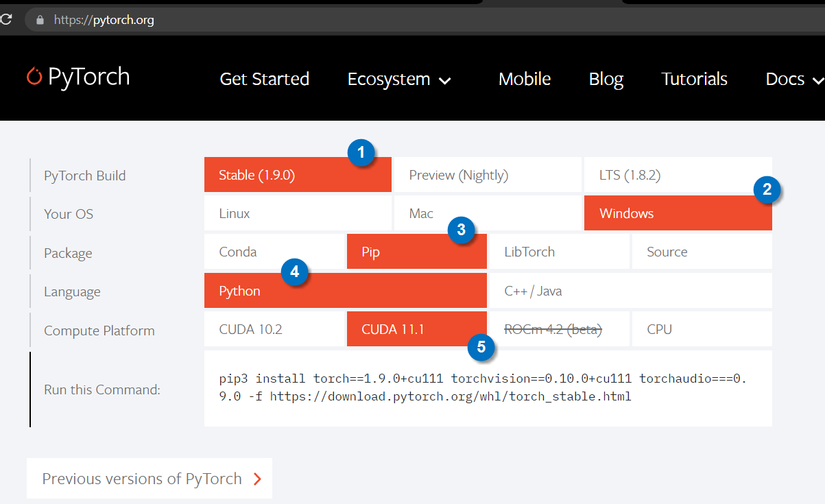
Ta có câu lệnh
pip3 install torch==1.9.0+cu111 torchvision==0.10.0+cu111 torchaudio===0.9.0 -f https://download.pytorch.org/whl/torch_stable.html
Khi đưa vào colab, hoặc Jupyter Notebook, bạn phải nhớ có dấu ! ở phía trước, tức là
!pip3 install torch==1.9.0+cu111 torchvision==0.10.0+cu111 torchaudio===0.9.0 -f https://download.pytorch.org/whl/torch_stable.html
Cài đặt các thư viện khác ngoài PyTorch
!pip install transformers requests beautifulsoup4 pandas numpy
Bắt đầu viết chương trình
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
import requests
from bs4 import BeautifulSoup
import re
tokenizer = AutoTokenizer.from_pretrained('nlptown/bert-base-multilingual-uncased-sentiment')
model = AutoModelForSequenceClassification.from_pretrained('nlptown/bert-base-multilingual-uncased-sentiment')
Mã hóa và tính toán (lượng hóa) cảm xúc
tokens = tokenizer.encode('I hated this, absolutely the worst', return_tensors='pt')
tokens
Kết quả
tensor([[ 101, 151, 39487, 10163, 10372, 117, 35925, 10563, 10103, 43060, 102]])
và
tokenizer.decode(tokens[0])
result = model(tokens)
result
Kết quả
SequenceClassifierOutput([('logits',
tensor([[ 4.8750, 1.7880, -0.8356, -3.0027, -2.0727]],
grad_fn=<AddmmBackward>))])
torch.argmax(result.logits)
Kết quả
tensor(0)
result.logits
trả về kết quả
tensor([[ 4.8750, 1.7880, -0.8356, -3.0027, -2.0727]],
grad_fn=<AddmmBackward>)
int(torch.argmax(result.logits))+1
Giá trị trả về là 1. Đây là giá trị của cảm xúc Tiêu cực.
Thử nghiệm với một văn bản khác:
tokens2 = tokenizer.encode('This is amazing, I loved it, great!', return_tensors='pt')
tokens2
result2 = model(tokens2)
int(torch.argmax(result2.logits))+1
Giá trị trả về là 5. Đây là giá trị của cảm xúc Tích cực.
Thử nghiệm thêm nữa với một văn bản khác, để xem giá trị cảm xúc trả về là bao nhiêu?
tokens3 = tokenizer.encode('It was good but could been better.', return_tensors='pt')
tokens3
result3 = model(tokens3)
int(torch.argmax(result3.logits))+1
Giá trị trả về là 3. Đây là giá trị của cảm xúc Trung lập.
Bài viết được dựa phần lớn từ video tutorial https://www.youtube.com/watch?v=szczpgOEdXs
Nguồn: viblo.asia