Xin chào, đây là bài viết thứ 2 của mình trong chuỗi series về Face Anti-Spoofing.
Xin chào, ở bài viết trước, mình đã giới thiệu tổng quan các vấn đề trong bài toán Face Anti-Spoofing, bài toán chống giả mạo khuôn mặt. Những chia sẻ ở bài viết trước bao gồm: giới thiệu bài toán, các phương pháp tấn công giả mạo (face attack methods), các phương pháp chống tấn công giả mạo phổ biến (face anti-spoofing), và một số vấn đề vướng mắc của phương pháp chống giả mạo dựa trên Deep Learning.
Các bạn có thể xem lại bài viết đầu tiên ở đây : (Phần 1) Tổng quan về Face Anti-Spoofing – Bài toán chống giả mạo khuôn mặt
Trong bài viết trước, mình đã giới thiệu sơ lược trong các phương pháp thuộc loại Deep learning based, chủ yếu được phân ra làm 3 loại phương pháp chính:
- Hyprid method
- Common deep learning methods
- Generalized deep learning methods
Trong đó, các phương pháp chung (common method) được chia thành một số loại con như:
- End-to-end binary cross-entropy supervision: xem như một bài toán classification với 2 nhãn và sử dụng cross-entropy loss để giám sát huấn luyện.
- Pixel-wise auxiliary supervision: Pseudo Depth labels, Eeflection maps, Binary Mask label và 3D Point cloud maps là các điển hình cho phương pháp này.
- Generative model with pixel-wise supervision: sử dụng GAN
Paper mình muốn giới thiệu hôm nay thuộc Pseudo Depth labels:
-
Deep Spatial Gradient and Temporal Depth Learning for Face Anti-spoofing được trình bày tại CVPR 2020. Thường được trích dẫn trong các paper khác với cái tên FAS-SGTD.
-
Paper đã có official code tại: Github/clks-wzz/FAS-SGTD
Note: Bài viết có nhiều từ khóa tiếng anh mình không thể dịch chuẩn, xin phép để nguyên và mong nhận được góp từ độc giả)
1. Introduction
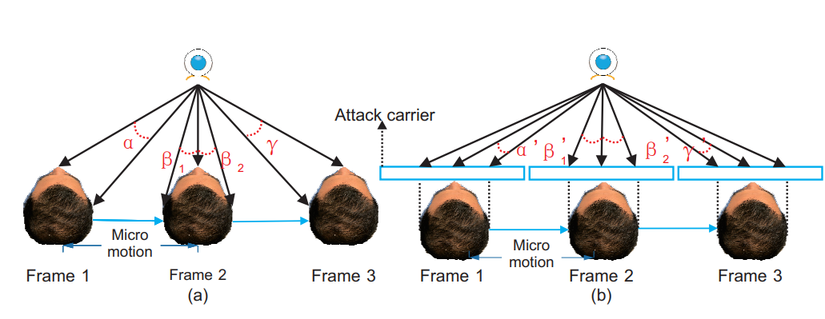
Paper bắt đầu bằng một mục tiêu: xây dựng một mô hình có thể tạo dựng bản đồ độ sâu (depth map) từ video thu được. Hiểu đơn giản, nếu trước camera là vật sống, bản đồ độ sâu sẽ có sự lồi lõm. Nếu trước camera là một tấm ảnh, như vậy bản đồ độ sâu thu được là một mặt phẳng.
Hoặc như trong hình ảnh trên do paper đưa ra, có thể nhận thấy sự khác biệt về góc độ giữa ảnh thật (ảnh a) và ảnh giả mạo (ảnh b).
Một điều nữa là tại thời điểm paper được trình bày (và kể cả bây giờ), hầu hết các nghiên cứu đều tập trung vào single-frame. Có nghĩa là nhận đầu vào là một ảnh tĩnh và cố phân biệt đó là ảnh giả mạo hay ảnh thật.
Tuy nhiên, paper tập trung tận dụng những ưu điểm của multi-frame, hay nói cách khác là nhận đầu vào là video. Mô hình sẽ cố gắng sự thay đổi khác nhau giữa các frame, từ đó tạo dựng lại bản đồ độ sâu.
Như vậy, paper này đề xuất 3 ý tưởng chính:
- Thứ nhất, đề xuất Residual Spatial Gradient Block (RSGB). RSGB học các đặc trưng của frame ảnh đầu vào, trong đó đặc biệt lưu tâm tới các manh mối phân biệt chi tiết nhỏ, đơn cử như spatial gradient magnitude.
(Bạn có thể bỏ qua nếu muốn, không liên quan đến paper) Spatial gradient magnitude là gì?
để hiểu kỹ nó là gì bạn có thể xem ở đây: Youtube – How I find the magnitude of a gradient. Về cơ bản, gradient trong hình ảnh là sự thay đổi về cường độ hoặc màu sắc trong ảnh. Về mặt toán học, gradient của một hàm hai biến (ở đây là hàm cường độ ảnh) tại mỗi điểm ảnh là một vectơ 2D với các thành phần được cho bởi đạo hàm theo phương ngang và phương thẳng đứng. Tại mỗi điểm ảnh, vectơ gradient hướng theo hướng có cường độ tăng lớn nhất có thể, và độ dài của vectơ gradient tương ứng với tốc độ thay đổi theo hướng đó. Nếu bạn từng dùng OpenCV, hẳn sẽ biết Cany Edge detection, một cơ chế trích xuất thông tin về cạnh dựa dựa trên tính toán gradient magnitude.
-
Thứ hai, như đã nói, paper muốn tận dụng ưu thế của multi frames, điều mà các paper ở thời điểm lúc đó chưa đề cập tới. Paper đề xuất Spatio-Temporal Propagation Module
(STPM) để tận dụng thông tin về thời gian giữa các frames. -
Thứ ba, paper đề xuất Contrastive Depth Loss để giám sát chặt ché hơn việc học độ sâu.
-
Và cuối cùng là bộ dataset Double-modal Anti-spoofing Dataset (DMAD) được xây dựng từ PRNet.
Bắt đầu thôi =))))
2. Network Struture
Dưới dây là toàn bộ kiến trúc chính của mô hình đề xuất.

(bạn có thể xem ảnh rõ nét và nhiều thông tin hơn trong paper)
-
Đầu tiên, đối với mỗi frame, paper đề xuất sử dụng các khối RSGB liên tiếp (khối màu vàng) làm backbone để trích xuất ra các fine-grained spatial features vởi đủ các level, low-level, mid-level và hight-level. Kết quả thu đc multi-level features đó được concat lại để dự đoán depth map sơ bộ cho mỗi frame.
-
Thứ hai, để nắm bắt thông tin giữa multi frames, STPM được thêm vào giữa các frame. STPM bao gồm các khối STSTB và ConvGRU.
-
Cuối cùng, thông tin thi được từ backbone, kết hợp với thông tin đầu ra ở một nút ConvGRU để refine, thu được kết quả cuối temporal depth maps để đưa vào hàm loss Contractive Depth Loss CDL
Giờ chúng ta sẽ đi vào chi tiết.
2.1 Residual Spatial Gradient Block – RSGB
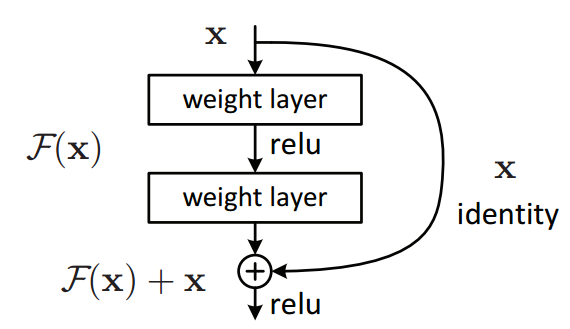
Ở đây, để kết hợp thông tin từ nhiều level, mô hình sử dụng một ý tưởng rất cơ bản từ kiến trúc ResNet, đó là Residual Block.
Cách phổ biến nhất để ước tính độ dốc hình ảnh (tính toán spatial gradient magnitude) là chuyển đổi một hình ảnh với một kernel như Sobel operatior hoặc Prewitt operation .
Và trong paper này sử dụng toán tử Sobel, rất thường thấy để trích xuất thông tin về cạnh.
Fhor(x)=[−10+1−20+2−10+1]⊙x F_{h o r}(x)=left[begin{array}{ccc}-1 & 0 & +1 \-2 & 0 & +2 \-1 & 0 & +1end{array}right] odot x
Fver(x)=[−1−2−1000+1+2+1]⊙x F_{v e r}(x)=left[begin{array}{ccc}-1 & -2 & -1 \0 & 0 & 0 \+1 & +2 & +1end{array}right] odot x
Thu được:
y=ϕ(N(F(x,{Wi})+N(Fhor(x′)2+Fver(x′)2))) y=phileft(mathcal{N}left(Fleft(x,left{W_{i}right}right)+mathcal{N}left(F_{text{hor}}left(x^{prime}right)^{2}+F_{ver}left(x^{prime}right)^{2}right)right)right)
Trong đó, Nmathcal{N} và ϕphi lần lượt là ký hiện của activation function ReLu và normalization layer. Đồng thời có thể thấy rằng RSGB được thêm vào tất cả các khối, từ đó có thể trích xuất được multiple level features.
Lưu ý xx là input feature map, x′x’ là input feature map đã qua convolution 1×1. Bởi vì ở nhánh thứ nhất, x sau khi đi qua 3×3 convolution đã có sự thay đổi về số kênh, nên ở nhánh còn lại cũng cần sử dụng 1×1 convolution để thay đổi số kênh, cuối cùng được hai bên nhất quán số kênh để thức hiện phép cộng ở cuối.
(Tại sao không nhân n kênh sobel mà lại nhân sobel rồi nhân 1×1 conv? → giảm chi phí tính toán (pointwise convolution))
(Tại sao lại có bình phương? → Hợp của vector phương ngang và vecto pương dọc thôi :vvv Đồng thời, phần triển khai code github cung cấp 3 loại: giữ nguyên, căn bậc hai và không học. )
net = slim.conv2d(input, out_dim,[3,3],stride=[1,1],activation_fn=None,scope=name+'/conv',padding='SAME')
gradient_x = spatial_gradient_x(input, name)
gradient_y = spatial_gradient_y(input, name)if gradient_type =='type0':
gradient_gabor = tf.pow(gradient_x,2)+ tf.pow(gradient_y,2)
gradient_gabor_pw = slim.conv2d(gradient_gabor, out_dim,[1,1],stride=[1,1],activation_fn=None,scope=name+'/rgc_pw_gabor',padding='SAME')
gradient_gabor_pw = slim.batch_norm(gradient_gabor_pw, is_training=is_training, activation_fn=None, scope= name +'/gabor_bn')
net = net + gradient_gabor_pw
elif gradient_type =='type1':
gradient_gabor = tf.sqrt(tf.pow(gradient_x,2)+ tf.pow(gradient_y,2)+1e-8)
gradient_gabor_pw = slim.conv2d(gradient_gabor, out_dim,[1,1],stride=[1,1],activation_fn=None,scope=name+'/rgc_pw_gabor',padding='SAME')
gradient_gabor_pw = slim.batch_norm(gradient_gabor_pw, is_training=is_training, activation_fn=None, scope= name +'/gabor_bn')
net = net + gradient_gabor_pw
elif gradient_type =='type2':
net = net
2.2 Spatio-Temporal Propagation Module – STPM
- Giữa 2 frame liên tiếp, paper đề xuất khối ngắn hạn Short-term Spatio-Temporal Block (STSTB). Nhìn vào hình có thể thấy kiến trúc bao gồm các khối STSTB nhỏ, tích lũy thông tin dần dần trong khi các frame lần lược đi qua các CN block.
- Giữa các frame liên tiếp dùng thêm một kiến trúc ConvGRU (nếu coi các STSTBs là chạy ngang thì ConvGRU là chạy dọc, mang theo thông tin (STSTB feature) thu được từ frame đầu tới frame cuối.
2.2.1 Short-term Spatio-Temporal Block – STSTB
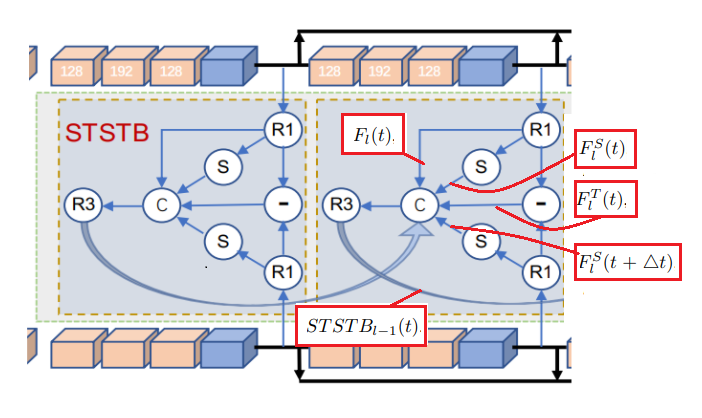
STSTB trích xuất thông tin không-thời gian tổng quát ngắn hạn (short-term spatio-tempoal information) bằng cách tổng hợp 5 loại features:
- Current compressed features Fl(t)F_l(t)
- Temporal gradient features FlT(t)F_l^T(t)
- Current spatial gradient feature FlS(t)F_l^S(t)
- Future spatial gradient features FlS(t+δt)F_l^S(t + delta t)
- STSTB features from the previous level STSTBl−1(t)STSTB_{l-1}(t)
Lưu ý, convolution 1×1 đã được thêm vào.
Sobel based Deepwise convolution được áp dụng để tính current và future spatial gradient features, trong khi đó element-wise subtraction đc áp dụng với temporal feature.
Điều paper đã thêm vào so với paper tiền đề OFF (Optical Flow guided Feature ) là future spatial gradient features FlS(t+δt)F_l^S(t + delta t).
2.2.2 ConvGRU
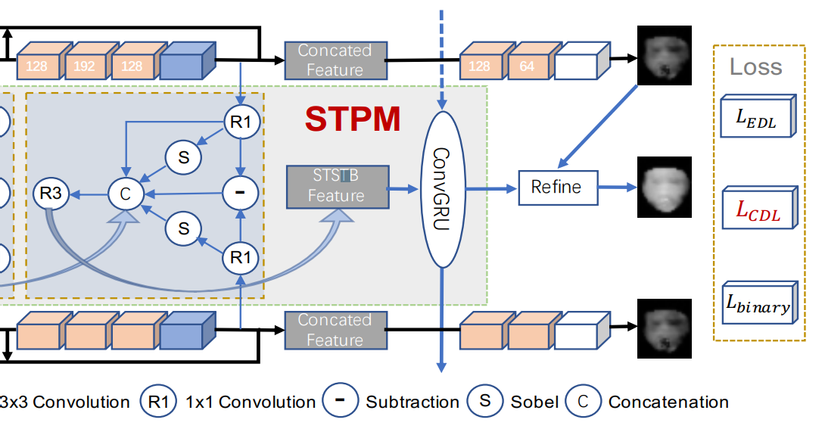
Module STSTB mặc dù có thể trao đổi thông tin giữa 2 frame, nhưng khả năng biểu diễn lại khá hạn chế, khi đó, cần có một cơ chế khác để truyền thông tin đi xa hơn, xuyên suốt các frame.
LSTM hoặc GRU có thể đảm bảo được thông tin thời gian tầm xa, nhưng lại loại bỏ đi các yếu tố về thông tin không gian, do đó, ConvGRU được phát triển để đảm bảo truyền được cả thông tin không-thời gian tầm xa
Cụ thể, ConvGRU là 1 biến thể của GRU với:
Rt=σ(Kr⊗[Ht−1,Xt]),Ut=σ(Ku⊗[Ht−1,Xt])H^t=tanh(Kh^⊗[Rt∗Ht−1,Xt])Ht=(1−Ut)∗Ht−1+Ut∗H^tbegin{aligned}R_{t} &=sigmaleft(K_{r} otimesleft[H_{t-1}, X_{t}right]right), U_{t}=sigmaleft(K_{u} otimesleft[H_{t-1}, X_{t}right]right) \hat{H}_{t} &=tanh left(K_{hat{h}} otimesleft[R_{t} * H_{t-1}, X_{t}right]right) \H_{t} &=left(1-U_{t}right) * H_{t-1}+U_{t} * hat{H}_{t}end{aligned}
Trong đó
- Xt,Yt,Ut,RtX_t, Y_t, U_t, R_t lần lượt là ma trận input, output, update gate và reset gate.
- Kr,Ku,Kh^K_r, K_u, K_{hat{h}} lần lượt là kernel trong lớp convolution
- ⊗,∗,σotimes, *, sigma lần lượt là covolution operation, phép nhân element-wise và hàm kích hoạt sigmoid
2.2.3 Depth Map Refinement
DsingleD_{single} thu được từ RSGB based backbone, và DmultiD_{multi} thu được từ STPM. Sau đó ta thu được:
Drefined t=(1−α)⋅Dsingle t+α⋅Dmulti t,α∈[0,1] mathrm{D}_{text {refined }}^{t}=(1-alpha) cdot mathrm{D}_{text {single }}^{t}+alpha cdot mathrm{D}_{text {multi }}^{t}, alpha in[0,1]
Dùng DmultiD_{multi} để refine , DsingleD_{single} thu được DrefinedD_{refined}. (Độ sâu dự đoán DPD_{P})
Hệ số αalpha được thay đổi, tùy theo mục đích muốn tăng tính quan trọng của yêu tố thời gian hay yếu tố không gian.
2.3 Contractive Depth Loss
Bởi vì đây là bài toán classification với 2 nhãn, ta thường nghĩ tới việc dùng Euclidean Distance Loss (EDL).
LEDL=∥DP−DG∥22 L_{EDL} = left | D_P – D_G right |_2^2
Tuy nhiên, nhận thấy EDL chỉ từng pix giám sát từng pixel một riêng biệt, không bận tâm tới sự khác biết (ở đây là độ sâu) giữa các pixel liền kề nhau. Paper đề xuất Contractive Depth Loss CDL để giám sát chặt ché hơn mỗi quan hệ giữa các pixel cạnh nhau. Cụ thể ở đây là 1 pixel với 8 pixel xung quanh nó.
Sau đó, paper tiếp tục xem xét thêm một binary loss khi tìm kiếm sự khác biệt giữa living và spoofing depth map.
Lbinary=−BG∗log(fcs(Davg)) L_{binary} = -B_G * log(f_{cs}(D_{avg}))
Trong đó:
BGB_G là binary groundtruth label.
DavgD_{avg} là average pooling map của$left { D_{refined}^t right }_{t=1}^{N_f-1}$
fcsf_{cs} : dùng 2 lớp fully connected và 1 lớp softmax để biến đổi depth maps về dạng nhị phân.
Loverall=β.Lbinary+(1−β).(LEDL+LCDL)) L_{overall} = beta . L_{binary} + (1 – beta) . (L_{EDL} + L_{CDL}))
βbeta là hype-parameter, là trade-of giữa binary loss và depth loss trong final overall loss. Về cơ bản, giám sát độ sâu vẫn là yếu tố quyết định, trong khi giám sát nhị phân đóng vai trò trợ lý để phân biệt các loại bản đồ độ sâu khác nhau.
3. Result
Bộ dataset, cụ thể là label depth map được xây dựng từ PRNet. Đây là mô hình thường được sử dụng để tái tạo lại khuông mặt 3D từ ảnh 2D. Hiện tại official code của PRNet hỗ trợ nhiều ứng dụng như Face Alignment, 3D Face Reconstruction, 3D Face Estimation, Face Swapping. Bạn có thể xem vầ PRNet tại đây.
Trong paper SGTD, nhóm tác giả đã sử dụng PRNet để tại bản đồ độ sâu cho các sample living, trong khi đó mặc định bản đồ độ sâu của sample spoofing là một mặt phẳng. Việc fix cứng là một mặt phẳng cũng là một điểm hạn chế mà paper đã thừa nhận. Trên thực tế ảnh Spoofing vẫn có thể có độ lồi lõm (dù nhẹ hơn ảnh thật). Nếu có một bộ dataset tốt hơn, hãy thử với nó.
Dưới đây là một ví dụ về dataset đã được sử dụng.

Vào thời điểm paper được trình bày (2020), paper đưa ra kết quả đánh bại hầu hết các nghiên cứu tại thời điểm. Chi tiết kết quả trên từng bộ benchmark bạn có thể tìm thấy trong paper. Về cơ bản, vẫn là sử dụng CNN với một số kernel đặc biệt kết hợp GRU để truyền thông tin đi xa, tuy nhiên nó đem lại hiệu quả tốt hơn chúng ta tưởng.
4. Kết
Kể cả như thế, Face Anti-Spoofing vẫn là bài toán còn nhiều thách thức. Nhìn vào paper trên có thể thấy dễ dàng ngay lợi thế lớn nhất của nó là kết hợp thông tin giữa các frame lại, nhưng một thực tế việc đợi nhiều frames để thu được kết quả live hay spoofing sẽ gây ra độ trễ về mặt thời gian. Bạn có thể tách riêng chỉ sử dụng phần ứng dụng của single frame (RSGB) cũng có thể đem lại kết quả tưởng đối ổn (senpai của mình bảo thế :vvv). Như vậy, việc có một hình đủ nhẹ, đủ nhanh, và quan trọng nhất, có thể ứng phó với rất rất nhiều cách tấn công đa dạng là một bài toán khó.
Nếu bài viết trên hữu ích, có thể để lại một Upvote giúp mình thêm động lực 😀
Đón đọc các bài viết tiếp theo của series.
Nguồn: viblo.asia