Khái niệm cần biết
- Dense Object Detector: Một mạng Object Detection thực hiện lấy mẫu các vị trí có khả năng tồn tại Object trong ảnh một cách cực dày đặc, để có thể bao phủ toàn bộ các hình dạng, vị trí và kích thước của object.
- Localization Quality: Chỉ số dùng để đánh giá chất lượng của bounding box. Ví dụ, trong FCOS, một nhánh phụ được thêm vào ngoài nhánh dự đoán chỉ số Bounding Box và dự đoán class đó là nhánh dự đoán centerness score. Đầu ra của nhánh centerness score sẽ dùng để đánh giá xem Bounding Box dự đoán được có nằm gần trung tâm của bức ảnh hay không? (Tác giả của FCOS cho rằng ở trung tâm bức ảnh sẽ có khả năng cực cao tồn tại object ở đó)
![image.png]()
- Class imbalanced: Sự mất cân bằng số lượng trong class. Cụ thể, trong trường hợp của Dense Object Detector, số lượng class background vượt trội hơn rất nhiều so với class foreground.
- Positive samples, positive targets: Các vị trí hoặc anchor box mà được phân vào class foreground
- Negative samples, negative targets: Các vị trí hoặc anchor box mà được phân vào class background
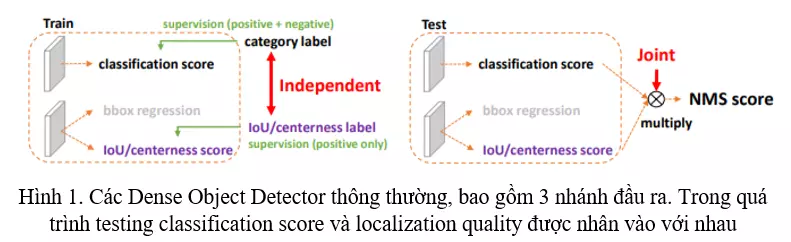
Đặt vấn đề
Gần đây, các Dense Object Detector đã dần trở thành xu hướng trong bài toán Object Detection, một phần là nhờ việc biểu diễn bounding box và đánh giá localization quality đã thúc đẩy sự phát triển của chúng. Thông thường, các Bounding Box được biểu diễn dưới dạng phân phối Dirac Delta (sẽ giải thích sau). Từ FCOS trở đi, một nhánh phụ thêm vào gọi là localization quality đã dần nhận được sự chú ý và được sử dụng nhiều hơn dưới các hình thức khác nhau (FCOS sử dụng centerness score, hay như trong IoU-aware sẽ sử dụng IoU score). Trong quá trình testing, Localization quality được kết hợp với classification score thông qua phép nhân ngay trước khi được đưa vào Non-Max Suppression để thực hiện loại bỏ các Bounding Box.
Tuy chúng mang đến những sự thành công cho Dense Object Detector, nhưng tác giả của Generalized Focal Loss quan sát thấy những vấn đề sau:
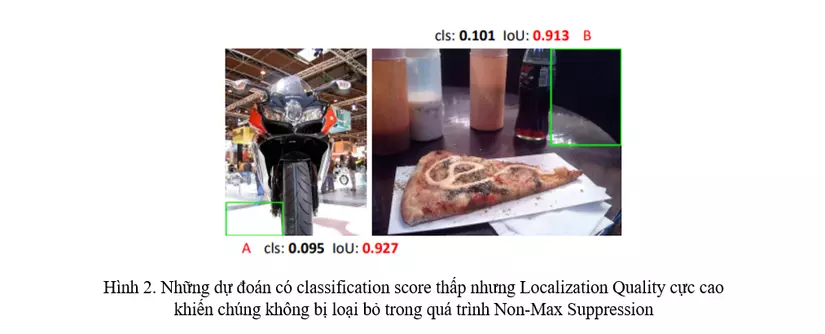
- Việc sử dụng localization quality và classification score trong training và testing không đồng bộ: (1) Localization Quality và Classification score trong training thì được tính riêng biệt, sử dụng 2 loss riêng biệt, nhưng trong testing thì chúng lại được nhân vào với nhau để thực hiện Non-Max Suppresion (Hình 1). (2) Localization Quality chỉ được tính thông qua các positive samples. Điều này gây ra hiện tượng trong quá testing, có những vị trí không tồn tại object và có classification score cực thấp nhưng localization quality lại có giá trị cực cao. Việc nhân 2 giá trị này vào vô tình xếp chúng lên trên những nơi có object nhưng mang giá trị localization quality thấp trong quá trình Non-Max Suppression, những vị trí đó sẽ được giữ lại và những vị trí có object sẽ bị loại bỏ (Hình 2).
![image.png]()
- Sự biểu diễn Bounding Box không linh hoạt: Sự biểu diễn Bounding Box thường thấy có thể xem như là phân phối Dirac Delta. Việc biểu diễn này là thiếu linh hoạt, nó bỏ qua sự không rõ ràng hoặc sự không chắc chắn về ranh giới của object trong dataset (Hình 3).
![image.png]()
Để đưa sự không rõ ràng vào việc dự đoán Bounding Box, Yihui et al. trong Bounding box regression
with uncertainty for accurate object detection, thay vì sử dụng phân phối Dirac Delta, đã sử dụng phân phối Gauss với trung bình là nơi có khả năng cao nhất cho vị trí của Bounding Box đó, còn phương sai là độ không chắc chắn. Nếu model tự tin vào label của Bounding Box thì phương sai sẽ thu hẹp lại và có thể trở thành phân phối Dirac Delta (GIF bên dưới)![]()
Tuy nhiên, việc sử dụng phân phối Gauss là quá đơn giản để biểu diễn phân phối thực sự của các Bounding Box trong dataset. Thực tế thì, phân phối thực của Bounding Box còn tùy ý và linh hoạt hơn, đồng thời cũng không đối xứng như phân phối Gauss.

Ý tưởng chính
Vì vậy, nhóm tác giả của paper Generalized Focal Loss (GFL) đã thiết kế một sự biểu diễn mới cho Bounding Box và Localization Quality.
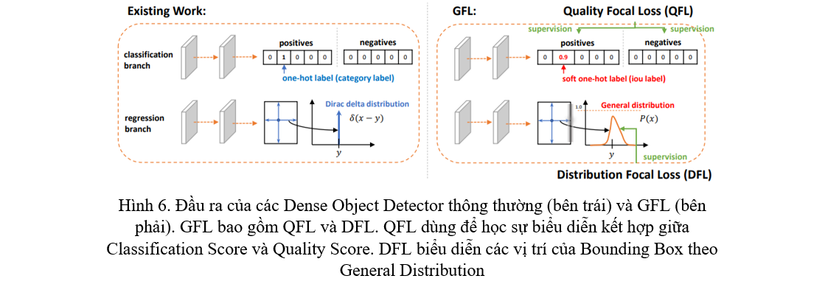
Với Localization Quality, GFL hợp nhất nó với Classification Score tạo thành một sự biểu diễn thống nhất: Một vector classification mà tại chỉ số index ứng với ground-truth (gt) category sẽ mang giá trị của Localization Quality. Bằng việc làm như vậy, ta có thể hợp nhất Classification Score và IoU score thành một biểu diễn duy nhất (gọi là “Classification-IoU joint representation”) (Hình 4)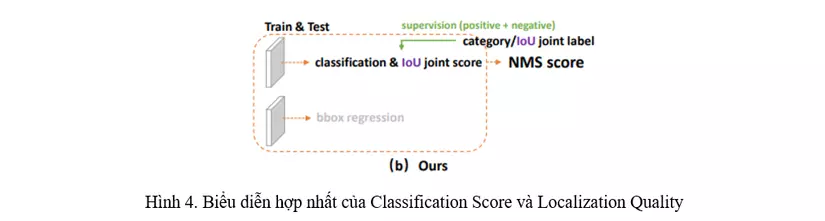
Từ đó, ta có thể loại bỏ đi sự không đồng bộ trong training và testing đã nhắc tới ở trên. Đồng thời, những negative samples lúc này sẽ được biểu diễn với Quality Score bằng 0 chứ không còn bị bỏ qua, khiến việc dự đoán Quality Score đáng tin cậy hơn.
Với sự biểu diễn Bounding Box, GFL sử dụng phân phối tùy ý (gọi là General Distribution) bằng việc học trực tiếp phân phối xác suất rời rạc ở trên miền liên tục. Từ đó, ta có thể thu được vị trí Bounding Box chính xác hơn, mà vẫn có thể đưa ra đa dạng các loại phân phối (Hình 5)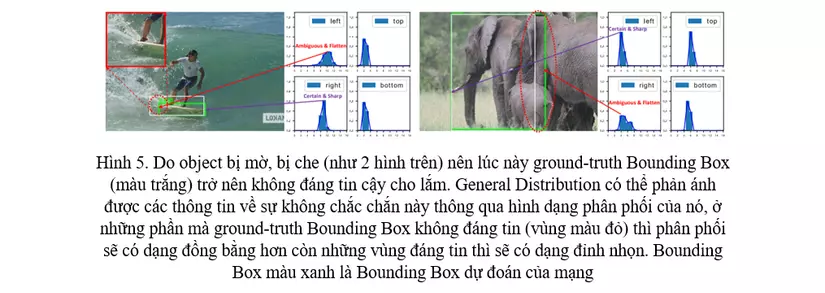
Với Dense Object Detector, nhánh Classification được tối ưu sử dụng Focal Loss (FL). FL có thể giải quyết được vấn đề class imbalanced thông qua việc biến đổi cross entropy loss. Tuy nhiên, trong trường hợp của Classification-IoU joint representation, ngoài việc vẫn còn class imbalanced, ta đối mặt với một vấn đề mới đó là giá trị của nhánh Classification-IoU joint nằm trong miền liên tục, trong khoảng [0,1][0, 1], nhưng FL lại chỉ sử dụng đối với giá trị rời rạc 0,1{0, 1}. Nhóm tác giả của GFL đã giải quyết vấn đề này bằng việc biến đổi FL để sử dụng trong miền liên tục, từ đó gọi là Generalized Focal Loss (GFL). GFL được chia làm 2 thành phần gọi là Quality Focal Loss (QFL) và Distribution Focal Loss (DFL) dùng để tối ưu 2 vấn đề: QFL tập trung vào việc sinh ra các giá trị liên tục trong khoảng [0,1][0, 1] đại diện cho Localization Quality tương ứng với category đó, DFL làm cho mạng liên tục tập trung vào việc học các giá trị xung quanh vị trí trong miền liên tục của gt Bounding Box dưới dạng General Distribution. Chú ý rằng ở đây, chúng ta sẽ dùng 2 hàm loss cho việc regression của Bounding Box: 1 là GIoU Loss, dùng để regress Bounding Box đến gt, còn DFL khiến mạng tập trung vào việc dựng lên một General Distribution cho Bounding Box đó.
Phương pháp cụ thể
Focal Loss (FL).
FL được dùng trong trường hợp mà Dense Object Detector gặp hiện tượng imbalanced giữa foreground và background. Công thức dạng đơn giản của FL như sau:
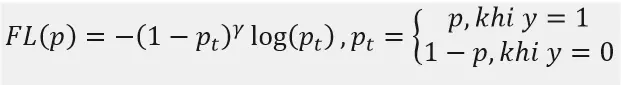
với yy là 0 hoặc 1 và pp nằm trong khoảng [0,1][0, 1] là sắc xuất của class với y=1y=1. Chia FL làm 2 phần, phần thứ nhất là cross entropy thông thường −log(pt)-log(p_{t}) , phần thứ hai là hệ số khuếch đại (1−pt)γ(1-p_{t})^{gamma}
Quality Focal Loss (QFL).
Để giải quyết vấn đề không đồng bộ giữa training và testing, ta sẽ sử dụng một sự biểu diễn kết hợp giữa Localization Quality (IoU Score) và Classification Score, gọi là Classification-IoU, biến sự biểu diễn thông thường là dạng one-hot thành dạng số thực với y nằm trong khoảng [0,1][0, 1] (Xem nhánh Classification ở Hình 6). Với y=0y=0 lúc này là các negative samples, còn y nằm trong khoảng (0,1](0, 1] là IoU score của các positives samples. IoU score được tính theo chỉ số IoU giữa Bounding Box được dự đoán và gt Bounding Box. Ở đây, ta sử dụng hàm sigmoid làm hàm kích hoạt cho đầu ra, kí hiệu là σsigma.
Vì hiện tượng imbalaced class giữa positive samples và negative samples vẫn còn nên ý tưởng của FL cần được áp dụng. Tuy nhiên, FL chỉ áp dụng được với label y rời rạc, tức 0 hoặc 1. Nhưng việc sử dụng Classification-IoU làm cho label y có dạng liên tục nằm trong khoảng [0,1][0, 1]. GFL đã mở rộng FL như sau:
(1) Đối với phần cross entropy−log(pt)-log(p_{t}) được mở rộng thành −((1−y)log(1−σ)+ylog(σ))-((1-y)log(1-sigma)+ylog(sigma))
(2) Đối với phần hệ số khuếch đại(1−pt)γ(1-p_{t})^{gamma} được biến đổi thành giá trị tuyệt đối của hiệu giữa σ và y ∣y−σ∣β (β≥0)|y-sigma|^{beta} (betageq0)
Kết hợp lại, chúng ta thu được công thức của Quality Focal Loss (QFL) như sau:![]()
Distribution Focal Loss (DFL).
GFL sử dụng khoảng cách từ tâm tới 4 cạnh của Bounding Box để làm regression target (Xem nhánh regression ở Hình 6). Thay vì sử dụng phân phối Dirac Delta hay phân phối Gauss, GFL sử dụng General Distribution P(x)P(x). Cho trước khoảng giá trị của yy với cực tiểu là y0y_{0} và cực đại là yny_{n} đại diện cho sự không chắc chắn, giá trị dự đoán y^{hat{y}} sẽ được tính như sau:
Để phù hợp với CNN, GFL biến đổi tích phân trên miền liên tục thành dạng biểu diễn trên miền rời rạc, bằng việc rời rạc hóa khoảng [y0,yn][y_{0},y_{n}] thành tập hợp các điểm {y0,y1,…,yi,yi+1,…,yn−1,yn}{y_{0},y_{1},…,y_{i},y_{i+1},…,y_{n-1},y_{n}} có khoảng cách bằng nhau gọi là ΔDelta. Sử dụng tính chất của phân bố rời rạc ∑i=0nP(yi)=1sum_{i=0}^{n}P(y_{i})=1, giá trị của y^{hat{y}} có thể biểu diễn dưới dạng:
y^=∑i=0nP(yi)yihat{y}=sum_{i=0}^{n}P(y_{i})y_{i}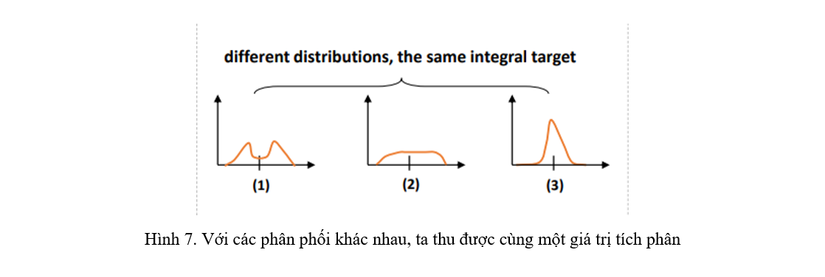
Tuy nhiên, có rất nhiều giá trị của P(x)P(x) mà có cùng cực tiểu và cực đại, dẫn đến kết quả của tích phân là yy, như biểu diễn trong Hình 7. Vì vậy, GFL tối ưu hóa hình dạng của phân phối P(x)P(x) bằng việc tập trung vào các giá trị ở gần với yy. Hơn nữa, trong những ví dụ mà tồn tại sự không chắc chắn của Bounding Box (Hình 3, Hình 5), thì những giá trị của Bounding Box đó cũng nằm rất gần với gt Bounding Box. DFL sẽ khiến mạng tập trung vào các giá trị ở gần gt Bounding Box yy bằng việc khuếch đại xác suất của yiy_{i} và yi+1y_{i+1} (2 giá trị ở gần vs gt Bounding Box nhất, với yi≤y≤yi+1y_{i}leq yleq y_{i+1}. Vì việc regress Bounding Box chỉ áp dụng lên positive samples nên ta không cần phải lo về class imbalanced nữa. Từ đó, công thức của DFL sẽ được biểu diễn như sau:![]()
Training sử dụng GFL
Ta có hàm Loss khi sử dụng GFL như sau:
với LQ{mathcal{L}}_{mathcal{Q}} là QFL và LD{mathcal{L}}_{mathcal{D}} là DFL. LB{mathcal{L}}_{mathcal{B}} là GIoU Loss, NposN_{p o s} là số lượng positive samples. λ0lambda_{0} và λ1lambda_{1} là hệ số cân bằng cho LB{mathcal{L}}_{mathcal{B}} và LD{mathcal{L}}_{mathcal{D}}. Tổng từng phần được tính trên toàn bộ các giá trị zz trên một feature map của FPN. 1{cz∗>0}{bf1}_{{c_{z}^{*}>0}} là indicatior function.
Kết quả
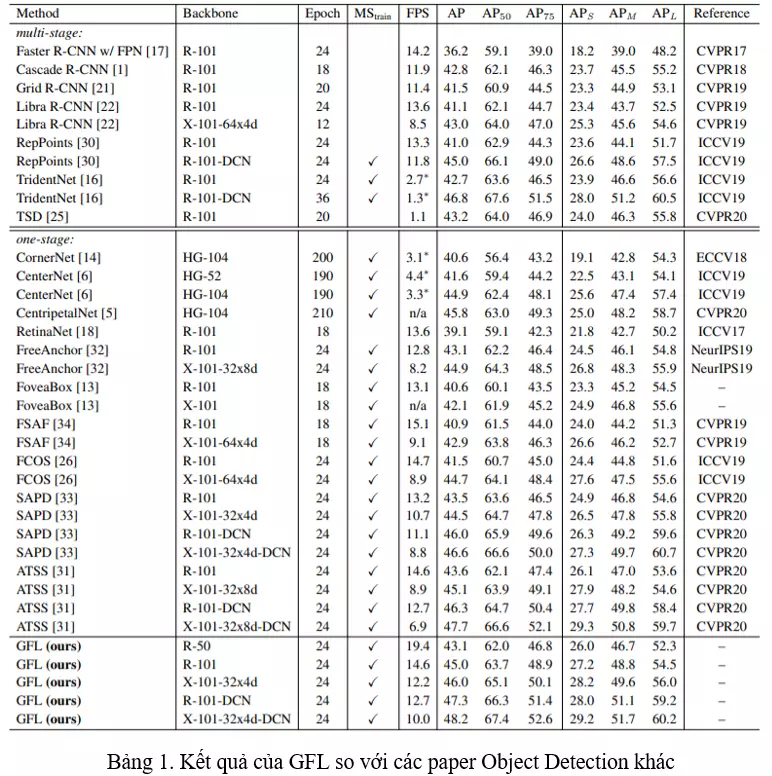
TL;DR
Mình sẽ tóm tắt lại paper cho những ai cảm thấy quá sức với những công thức toán học ở bên trên, để có thể nắm được ý tưởng của paper này theo phong cách 3W.
[W]hat
- Một hàm loss mới cho những mạng Object Detection one-stage.
[W]hy
- Nhánh Classification Score và Localization Quality trong training và testing không đồng bộ với nhau, dẫn đến việc thực hiện NMS trong testing không hiệu quả, kết quả của mạng bị giảm rõ rệt so với training (Hình 1, Hình 2).
- Các hàm loss cho Bounding Box trong các mạng Object Detection khác chưa thực sự quan tâm đến những object có ranh giới không rõ ràng (Hình 3, Hình 5).
Ho[W]
- Hợp nhất nhánh Classification Score và Localization Quality, tạo ra một hàm loss gọi là QFL cho sự hợp nhất này (Hình 4).
- Mô hình hóa Bounding Box dưới dạng một phân phối tự do, giúp Bounding Box dự đoán ra kết quả hợp lý hơn cả người label trong một số dataset (Hình 5). Tạo ra một hàm loss gọi là DFL cho phân phối này.
- GFL là sự kết hợp của QFL và DFL.
Nguồn: viblo.asia