1. Giới thiệu chung
Áp dụng học sâu vào lĩnh vực xử lý ảnh y tế từ trước tới nay luôn chiếm khá nhiều quan tâm của giới học giả nghiên cứu vì tính thách thức cũng như khả năng ứng dụng thực tế. Chính vì thế mà các mô hình ưu việt cứ cách một khoảng thời gian ngắn lại được đề xuất. Gần đây thầy cô trường đại học Bách Khoa Hà Nội kết hợp với các thầy cô khác đến từ đhqg Hồ Chí Minh và học viện nông nghiệp Việt Nam đã hợp tác nghiên cứu cho ra mô hình segmentation cho bài toán phân đoạn khối u đại tràng (colon polyp segmentation). Mô hình đạt kết quả rất khả quan trên một số tập dữ liệu của bài toán nói trên và hiện đang chiếm giữ top 1 trên tập dữ liệu CVC-ClinicDB. Công trình nghiên cứu có một số đóng góp mới như:
- Đề xuất mô hình mới sử dụng backbone transformer kết hợp phần head có kiến trúc Pyramid CNN
- Kỹ thuật sàng lọc đặc trưng sử dụng module residual attention mới nhằm cải thiện sự kết hợp giữa các feature map và làm mịn đường biên của mask đầu ra.
2. Colonformer
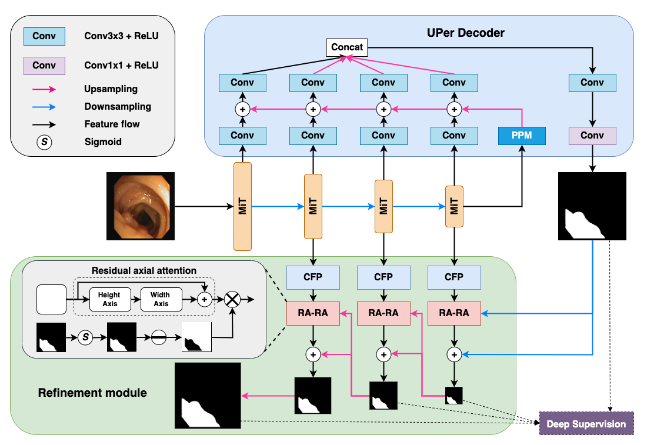
2.1 Encoder
Mô hình sử dụng backbone của Mix Transformer (MiT) đến từ paper “Segformer: Simple and efficient design for semantic segmentation with transformers” làm encoder. MiT có khả năng cho đầu ra là feature map với multi scale giống nhiều mạng CNN hiện nay, kích thước của feature map sẽ giảm dần theo cấp số mũ: H2i+1×W2i+1×Cifrac{H}{2^{i+1}} times frac{W}{2^{i+1}} times C_i, trong đó i∈{1,2,3,4}i in {1, 2, 3, 4}.
Mỗi block của MiT có 3 phần chính: Multi-head Self-Attention (MHSA) layers, Feed Forward Network (FFN), và Layer Norm. Một lý do khá quan trọng mà nhóm tác giả chọn MiT làm backbone chính là vì Mix – FFN. Thay vì sử dụng Positional Encoding (PE) như Vision Transformer thì FFN lại sử dụng một lớp tích chập 3×33 times 3. Kích thước dữ liệu đầu vào của PE bắt buộc phải không đổi, do đó nó không thể tận dụng đặc trưng không gian của những tập dữ liệu lớn như ImageNe nếu tập test có kích thước đầu vào khác tập train. Tất nhiên chúng ta có thể resize ảnh về kích thước mong muốn với thuật toán nội suy (interpolate), tuy nhiên việc thêm positional encoding theo một cách “không thống nhất” như vậy vô tình gây nhiễu cho ảnh đầu vào và làm giảm hiệu năng của mô hình. Trong khi đó, với ý tưởng sử dụng lớp tích chập có thể cung cấp thông tin vị trí cho mô hình Transformer, MiT sử dụng trực tiếp một lớp tích chập 3×33 times 3 cho nhiệm vụ này. Độ hiệu quả của sự thay đổi này đã được chỉ rõ trong paper gốc Segformer. Đồng thời rất nhiều mô hình SOTA hiện tại đều lấy backbone Segformer làm encoder, điều này cũng gián tiếp chứng minh sức mạnh của nó. Mix – FFN được thể hiện qua công thức như sau:
xout=MLP(GELU(Conv3x3(MLP(xin)))+xinx _ { o u t } = M L P ( G E L U ( C o n v _ { 3 x 3 } ( M L P ( x _ { i n } ) ) ) + x _ { i n }
2.2 Decoder
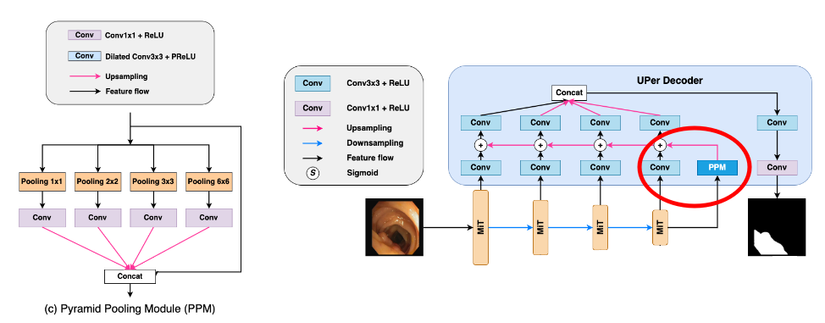
Để bắt được thông tin toàn cục tốt hơn, nhóm tác giả đầu tiên đưa feature map từ block cuối cùng của encoder qua module PPM (Pyramid Pooling Module) [2]. PPM module sẽ đồng thời tạo ra multi-scale output với feature map đầu vào thông qua các lớp pyramid pooling. Chi tiết hơn thì feature map sẽ được đồng thời đưa qua 4 lớp [pooling + conv] rồi sau đó lại gộp về làm một. Ý tưởng tạo nên khối này xuất phát từ một vấn đề xuất hiện trong khá nhiều mạng Convolution: theo lý thuyết thì những lớp tích chập càng ở sâu sẽ có receptive field càng lớn và nó phải đủ lớn để bao được hết thông tin của ảnh đầu vào, thế nhưng thực tế thì ngược lại. Điều này làm cho mô hình không thể “nhìn” được toàn bộ bức ảnh qua receptive field, từ đó không thể lấy đủ thông tin ngữ nghĩa toàn cục. Khối PPM sẽ có nhiệm vụ tạo ra đặc trưng toàn cục đủ tốt để giải quyết vấn đề này. Thông tin sau khi đi qua khối PPM sẽ được kết hợp với đặc trưng ở các mức scale khác nhau sau đó concat lại để cho ra output mask. Mask này sẽ dành cho nhiệm vụ deep supervison với khối refinement module ở phần sau.
2.3 Refinement Module
Như tên gọi của nó thì refinement module có tác dụng chính là làm mịn và cho ra output map chính xác hơn. Khối này bao gồm Channel-wise Feature Pyramid (CFP) module và Reverse attention module kết hợp với residual axial attention block cho nhiệm vụ tịnh tiến gia tăng độ chính xác của đường biên polyp . Thông thường những khối polyp nhỏ rất khó bị phát hiện vì màu của nó gần giống với thành ruột, do đó nhóm tác giả quyết định sử dụng reverse attention để làm nổi bật đường biên bao của polyp, giúp mô hình dễ tập trung hơn vào những khối polyp nhỏ.
Reverse attention bắt nguồn từ paper “Reverse Attention for Salient Object Detection”. Ý tưởng của nó là tạo pseudo prediction map từ conv1x1conv1x1, lúc đấy thì pixel mà mô hình tự tin sẽ có giá trị cao và ngược lại. Sau đó ouput map này sẽ được đưa qua công thức : −1∗(sigmoid(xout))+1-1*(sigmoid(x_{out})) + 1 để thực hiện bước tạo attention weight ngược vào phần background + biên và supress phần polyp , cuối cùng nhân attention weight vừa tạo với feature map để làm nổi bật phần biên.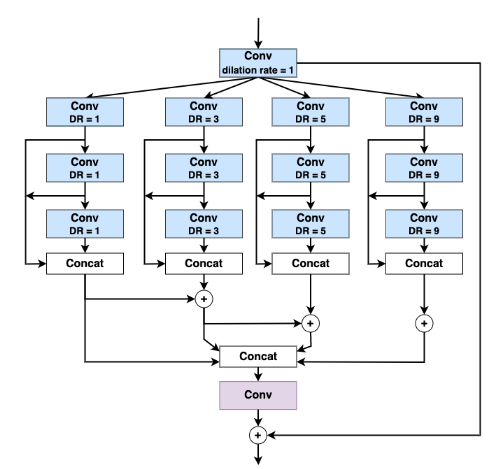
CFP module được lấy ý tưởng từ paper “Caranet: Context axial reverse attention network for segmentation
of small medical objects” , khối này được sử dụng với mục tiêu trích xuất đặc trưng. Nó cho phép model “quan sát” feature map dưới nhiều scale view khác nhau do có 4 nhánh riêng biệt với tỉ lệ dilation khác nhau để bắt thông tin ở nhiều mức, sau đó người ta không ghép chúng lại thành một khối một cách đột ngột mà kết hợp dần dần các feature để tránh mất mát thông tin.
Nhóm tác giả của CaraNet cũng đề xuất axial attention block để tăng cường sức mạnh của reverse attention với mục tiêu lọc thông tin cần thiết cho quá trình làm mịn output map. Tuy nhiên axial attention không phải lúc nào cũng tốt vì cũng có khả năng nó sẽ lọc luôn thông tin đường biên mà reverse attention đã đạt được. Do đó, nhóm tác giả ColonFormer đề xuất tạo thêm một nhánh kết nối tắt cho phép model tự bỏ hoặc giữ axial attention trong quá trình học. Sự kết hợp nói trên đã cho ra đời khối Residual Axial Reverse Attention (RA-RA).
2.4 Loss function
ColonFormer sử dụng hàm loss được kết hợp từ 2 hàm loss weighted Focal loss và weighted IoU loss để huấn luyện mô hình. Hàm focal loss sẽ đánh vào phân phối pixel của output map và sẽ quan tâm đến từng pixel một, do bài toán polyp thường cho ra output map bị mất cân bằng. Điều này chủ yếu là vì polyp chỉ chiếm một phần nhỏ trong ảnh đầu vào và phần lớn còn lại là background, vì vậy mà groundtruth map có sự mất cân bằng giữa 2 nhãn {polyp, background}. Ở hướng ngược lại thì weighted iou loss lại là hàm loss đánh vào từng vùng pixel để lấy ra mối tương quan của các pixel ở gần nhau.
Với giả thiết rằng có một số pixel (polyp, đường biên) quan trọng hơn những pixel khác khi đóng góp vào quá trình huấn luyện, nhóm tác giả lấy ý tưởng đánh trọng số cho các pixel trong hàm loss trong paper “F3F^3 net: Fusion, feedback and focus for salient object detection” để giải quyết vấn đề trên. Trọng số βij{ beta _ { i j } } cho pixel (i,j)( i, j ) đại biểu cho mối quan hệ của pixel trung tâm và lân cận của nó:
βij=∣∑m,n∈Nijgmn∣Nij∣−gij∣beta _ { i j } = | frac { sum _ { m, n in N _ { i j } } g _ { m n } } { | N _ { i j } | } – g _ { i j } |
Trong đó NijN _ { i j } là vùng lân cận 31×3131times31 của pixel (i,j)(i,j) và gi,jg_{i,j} là nhãn của pixel (i,j)(i, j). Phương pháp đánh trọng số như vậy sẽ cho phép mô hình tập trung nhiều hơn vào vùng biên.
Giả sử pi,jp_{i,j} là dự đoán xác suất của mô hình cho pixel (i,j)(i,j), ta có qi,jq_{i,j}:
qij={pij, if gij=11−pij, otherwise q_{i j}=left{begin{array}{cc}
p_{i j}, & text { if } g_{i j}=1 \
1-p_{i j}, & text { otherwise }
end{array}right.
Như vậy công thức weighted focal loss và weighted iou loss sẽ được biểu diễn như sau :
Lwfocal=−∑i=1H∑j=1W(1+λβij)α(1−qij)∑i=1H∑j=1W(1+λβij)L _ { w f o c a l } = – frac { sum _ { i = 1 } ^ { H } sum _ { j = 1 } ^ { W } left ( 1 + lambda beta i j right ) alpha left ( 1 – q _ { i j } right ) } { sum _ { i = 1 } ^ { H } sum _ { j = 1 } ^ { W } left ( 1 + lambda beta _ { i j } right ) }
Luiou=1−∑i=1H∑j=1W(gij∗pij)∗(1+λβij)∑i=1H∑j=1W(gij+pij∗pij)∗(1+λβij)L _ { u i o u } = 1 – frac { sum _ { i = 1 } ^ { H } sum _ { j = 1 } ^ { W } left ( g _ { i j } * p _ { i j } right ) * left ( 1 + lambda beta _ { i j } right ) } { sum _ { i = 1 } ^ { H } sum _ { j = 1 } ^ { W } left ( g _ { i j } + p _ { i j } * p _ { i j } right ) * left ( 1 + lambda beta _ { i j } right ) }
Trong đó γ,αgamma, alpha là các tham số có thể tinh chỉnh.
Cuối cùng, hàm loss của Colonformer sẽ được tính dựa trên trung bình cộng của 2 hàm loss kể trên:
Ltotal=Lufocal+Luiou2L _ { t o t a l } = frac { L _ { u f o c a l } + L _ { u i o u } } { 2 }
Có một điều cần chú ý là mô hình ColonFormer cho nhiều đầu ra với nhiều multi scale, do đó hàm loss LtotalL _ { t o t a l } trên sẽ được áp dụng cho từng mức scale và cộng tổng lại để tính gradient.
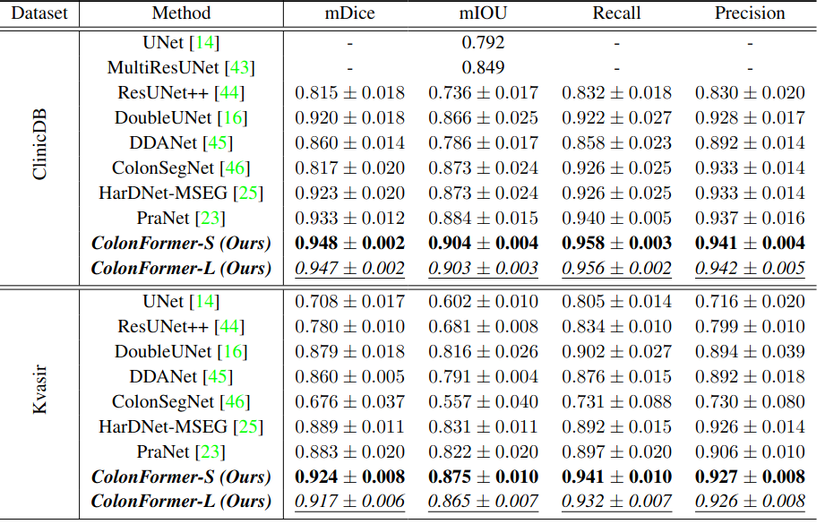
3. Kết quả

4. Kết luận
Mặc dù theo mình thấy thì nhóm tác giả chưa thực sự đưa ra ý tưởng nào mới, chỉ là kết hợp các ý tưởng đã có sẵn, nhưng sự kết hợp này đã tạo nên một mô hình thực sự mạnh. Tuy nhiên mình thấy trong paper còn một số chỗ chỗ chưa thực sự hợp lý cho lắm. Thứ nhất, mô hình chưa có sự ổn định, nhóm tác giả phải huấn luyện mô hình 5 lần và lấy trung bình kết quả, do đó rất khó reproduce lại kết quả SOTA. Thứ hai, mô hình chi train 20 epoch, không augmentation như các bài nghiên cứu khác thường làm. Mình cũng không rõ là nếu thêm augmentation hay thêm số epoch train thì mô hình đạt kết quả tệ hơn hay như nào, nhưng thông thường thì 20 epoch là chưa đủ cho mô hình segmentation hội tụ. Trong tương lai, nhóm tác giả sẽ hướng đến những mô hình light-weight hay sparse self-attention layer để giảm độ phức tạp tính toán, đồng thời cũng sẽ tìm kiếm các cách kết hợp khác nhau cho transformer và cnn
Reference
[1]. Nguyen Thanh Duc, Nguyen Thi Oanh, Nguyen Thi Thuy, Tran Minh Triet, and Dinh Viet Sang. Colonformer: An efficient transformer based method for colon polyp segmentation. arXiv preprint arXiv:2205.08473, 2022.[2] Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, and Jiaya Jia. Pyramid scene parsing network. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2881–2890, 2017.
Nguồn: viblo.asia