Khi nhắc đến xử lý dữ liệu bảng thì đa số chúng ta sẽ lựa chọn Pandas để đọc và thao tác với dữ liệu, và mình cũng không ngoại lệ. Tuy nhiên, mình vừa đọc được một bài viết khá là hay để xem xem liệu rằng Pandas có phải là lựa chọn tốt nhất không? Ở bài viết này chúng ta sẽ cùng so sánh hiệu suất của các package: Pandas, Dask, Datatable.
Pandas
Pandas là một thư viện của Python được mọi người sử dụng rất nhiều, đặc biệt khi dùng để thao tác với các dạng dữ liệu bảng biểu, vừa nhanh chóng, đơn giản và cũng dễ dùng. Tuy nhiên nếu sử dụng file csv lớn thì sẽ rất tốn rất nhiều thời gian. Ở bài viết này mình sẽ không đề cập đến Pandas nhiều vì Pandas quá phổ biến và hữu ích.
Dask
Dask được sinh ra dùng để đọc file csv lớn – một vấn đề mà pandas gặp phải. Dask là một thư viện mã nguồn mở cung cấp tính năng song song linh hoạt, nâng cao cho tính toán phân tích. Nó nguyên bản chia tỷ lệ các package phân tích này thành các máy đa lõi và các cụm phân tán bất cứ khi nào cần. Khung dữ liệu của dask sử dụng API của Pandas, giúp mọi thứ trở nên cực kỳ dễ dàng đối với những người sử dụng và yêu thích Pandas.
Datatable
Datatable là một thư viện khác của Python tập trung vào cải thiện hiệu suất, mong muốn xử lý dữ liệu lớn (100GB)
với tốc độ tối đa ở trên 1 máy,. Trong khi đó, khả năng tưởng tác của Datatable và Pandas/Numpy cung cấp khả năng chuyển đổi tới một framework xử lý data khác một cách dễ dàng.
So Sánh
Ok. Bây giờ chúng ta cùng nhau thử dùng code để so sánh tốc độ xử lý của 3 thư viện này trực quan hơn nhé.
Đọc file csv
import pandas as pd
import dask.dataframe as dd
import datatable as dt
import matplotlib.pyplot as plt
Kiểm tra thời gian đọc của pandas, dask và datatable
Pandas
%%time
df = pd.read_csv("na_filled (1).csv")type(df)dask
%%time
df = dd.read_csv("na_filled (1).csv")type(df)datatable
%%time
df = dt.fread("na_filled (1).csv")type(df)Kết quả

Hình ảnh: thời gian chạy
show biểu đồ lên nhìn cho rõ nào.
fig = plt.figure()
ax = fig.add_axes([0,0,1,1])
ax.set_ylabel('ms')
ax.set_title('Speed of reading single csv file (4.7MB)')
lib =['pandas','dask','datatable']
perf =[67.1,11.3,39.7]
ax.bar(lib,perf)
plt.show()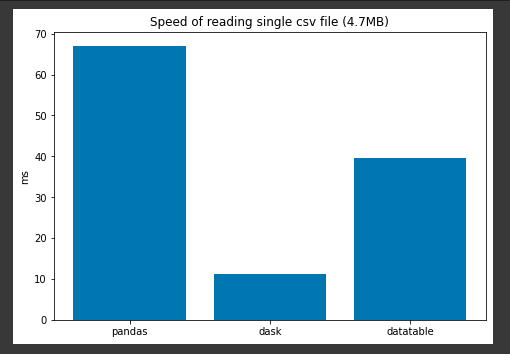
Hình ảnh: biểu đồ
Như ở 2 hình trên chúng ta có thể dễ dàng thấy được rằng thời gian đọc file của Dask nhanh hơn hẳn so với Pandas và Datatable. Datatable nhanh hơn Pandas 1 ít thời gian.
Đọc nhiều file cùng một lúc
Vì quá lười thêm nhiều file nên mình đọc luôn 4 file ở trên cùng 1 lúc =)))
pandas
%%time
files =["na_filled (1).csv","na_filled (1).csv","na_filled (1).csv","na_filled (1).csv"]
combined =[]for f in files:
combined.append(pd.read_csv(f))
combined_df = pd.concat(combined,ignore_index=True)dask
%%time
df = dd.read_csv(files)datatable
%%time
df = dt.iread(files)
df = dt.rbind(df)
df = df.to_pandas()Kết quả
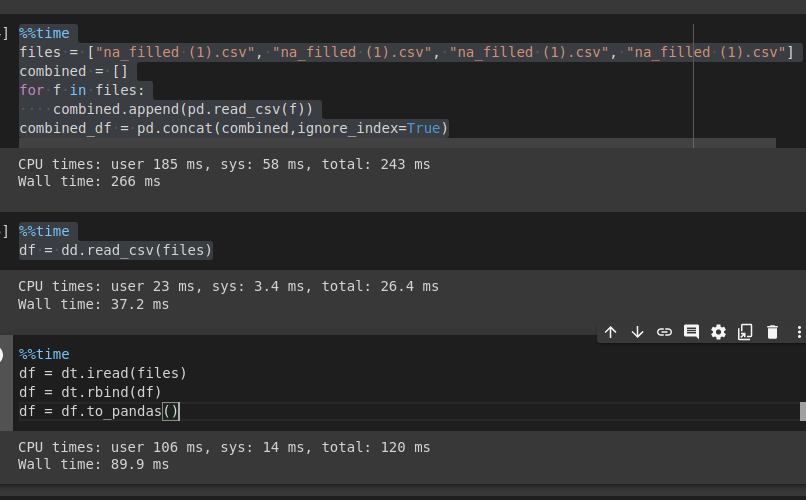
Hình ảnh: thời gian chạy nhiều file
Plot lên cho trực quan hơn nè.
fig = plt.figure()
ax = fig.add_axes([0,0,1,1])
ax.set_ylabel('s')
ax.set_title('Speed of reading multiple csv files')
lib =['pandas','dask','datatable']
perf =[87,21,140]
ax.bar(lib,perf)
plt.show()
Hình: Biểu đồ
Nhìn vào 2 hình trên thì Dask vẫn nhanh nhất (như mình có nói ở trên đối với dữ liệu csv lớn thì Dask rất hiệu quả) , tuy nhiên khi chạy nhiều file thì Pandas lại đọc nhanh hơn datatable.
Kết luận
Như mình có đề cập ở trên thư viện Dask rất tiện với file csv lớn mà thư viện Pandas khó xử lý, tuy nhiên mình lại không có dữ liệu lớn như vậy để đọc ở đây  . Nếu dữ liệu csv hay excel lớn quá mà bạn không thể đọc được thì nghĩ ngay tới Dask nhé. Đối với Datatable thì khi bạn có dữ liệu khoảng 100GB thì dùng sẽ hiệu qủa hơn ạ.
. Nếu dữ liệu csv hay excel lớn quá mà bạn không thể đọc được thì nghĩ ngay tới Dask nhé. Đối với Datatable thì khi bạn có dữ liệu khoảng 100GB thì dùng sẽ hiệu qủa hơn ạ.
Nếu làm việc với dữ liệu bình thường hoặc để phục vụ nghiên cứu hay học tập thì Pandas vẫn là lựa chọn tốt nhất, hữu ích nhất và lý tưởng nhất và quan trọng là cực kì dễ dùng cũng như có nhiều nguồn để tham khảo. Bởi vì lượng người dùng của Pandas rất nhiều.
Cuối cùng mình xin cảm ơn các bạn đã đọc hết bài viết của mình. Chúc các có bạn một kì nghỉ lễ VUI Vẻ ạ. Upvote cho mình nha .
Reference
[1] https://towardsdatascience.com/pandas-vs-dask-vs-datatable-a-performance-comparison-for-processing-csv-files-3b0e0e98215e [2] https://mungingdata.com/pandas/read-multiple-csv-pandas-dataframe/Nguồn: viblo.asia