Mở đầu
Cơ chế Attention (Attention mechanism) là một cơ chế vô cùng hay và nhận được rất nhiều sự phát triển gần đây. Có những model được tạo thành lấy trọng tâm từ cơ chế này như: Transformer trong Attention is All You Need; VAN trong Visual Attention Network; ViT trong Vision Transformer;…
Trong bài viết này, mình sẽ giải thích nhanh về cơ chế Attention hay được sử dụng trong Computer Vision và các biến thể của chúng.
 Bài viết này sẽ không trình bày về Self-Attention, vì đã có quá nhiều bài nói về Self-Attention rồi
Bài viết này sẽ không trình bày về Self-Attention, vì đã có quá nhiều bài nói về Self-Attention rồi
Định nghĩa
Phương pháp mà tập trung sự chú ý (attention) đến các phần, vùng quan trọng trong ảnh và loại bỏ đi những vùng không quan trọng được gọi là cơ chế attention. Trong Computer Vision (CV), cơ chế attention là quá trình lựa chọn một cách có chọn lọc thông qua việc đánh trọng số khác nhau cho features dựa trên độ quan trọng của input.
Biểu diễn toán học:
Attention=f(g(x),x)Attention = f(g(x), x)
ở đây, g(x)g(x) là quá trình tạo attention để xem là nên tập trung vào phần/vùng nào. f(g(x),x)f(g(x), x) là quá trình xử lý input xx dựa trên thông tin là phần/vùng nào quan trọng thông qua g(x)g(x).
Sử dụng biểu diễn toán học trên biểu diễn Self-Attention (làm mẫu 1 lần thôi nhá, không có lần thứ 2 đâu nha)
Q,K,V=Linear(x)Q, K, V = Linear(x)
g(x)=Softmax(QK)g(x) = Softmax(QK)
f(g(x),x)=g(x)Vf(g(x), x) = g(x) V
Các loại Attention
Channel Attention
SE Module
Đại diện cho Channel Attention sẽ là SE Module từ Squeeze and Excitation Network (SENet).
Trong CNN, mỗi channel trong feature maps sẽ đại diện cho một thông tin. Việc áp dụng Attention lên chiều channel tức là mỗi channel sẽ có một trọng số riêng, do đó sẽ ảnh hưởng khác nhau tới đầu ra thay vì có ảnh hưởng như nhau.
SE Module gồm 2 phần (Hình 1): Phần Squeeze (thu) và phần Excitation (phóng). Phần Squeeze có trách nhiệm thu gom thông tin toàn cục (global information) sử dụng Global Average Pooling (GAP). Phần Excitation có trách nhiệm tạo attention trên chiều channel sử dụng 2 lớp Fully Connected (FC) với 2 activation function khác nhau, lần lượt là ReLU và Sigmoid.
Tại sao lại cần đến Squeeze? Để có thể tận dụng sự phụ thuộc vào chiều channel, ta xem xét tín hiệu đến từng channel trong output feature maps. Mỗi filter trong lớp Convolution chỉ hoạt động với một vùng, do vậy, mỗi channel trong output feature map sẽ không tận dụng được vùng ở ngoài filter đó. Do đó, ta thực hiện GAP để thu lại thông tin toàn cục trên chiều không gian của một channel.
Tại sao lại cần đến Excitation? Để tận dụng được thông tin tổng hợp trong Squeeze, ta thực hiện Excitation để thu được sự phụ thuộc theo chiều channel. Ta cần có 2 tiêu chí: (1) nó phải linh hoạt (học được một sự tương tác phi tuyến tính ở mỗi channel) và (2) nó học được mối quan hệ không loại trừ lẫn nhau vì ta muốn có nhiều channels có thể được chú ý tới cùng một lúc →rightarrow sử dụng Sigmoid làm activation function (thay vì Softmax như Self-Attention).
Attention g(x)g(x) sẽ được tạo ra như sau:
g(x)=σ(W2δ(W1,GAP(x)))g(x) = sigma(W_2delta(W_1, GAP(x)))
với GAPGAP là phép Global Average Pooling, W1∈R(C/r)×CW_1 in R^{(C/r) times C} là weight của layer Linear1Linear_1, δdelta là ReLU, W2∈RC×(C/r)W_2 in R^{C times (C/r)} là weight của layer Linear2Linear_2, σsigma là Sigmoid.
Ở đây, ta hoàn toàn có thể chỉ cần sử dụng một lớp Linear với hàm Sigmoid là đã hoàn thiện Excitation rồi, nhưng sử dụng một lớp Linear phụ nữa để giảm số channel xuống theo tỉ lệ rr lần để tính toán được nhẹ hơn.
Output feature maps sẽ được tính như sau:
x^=g(x)×xhat{x} = g(x) times x
g(x)g(x) là vector attention được tạo ra thông qua Squeeze and Excitation, có chiều 1×1×C1 times 1 times C với CC là số channel của input feature maps. Tức là output feature maps sẽ được tạo ra bằng cách nhân từng phần tử trong channel ii của input feature maps với một phần trong channel ii của g(x)g(x).
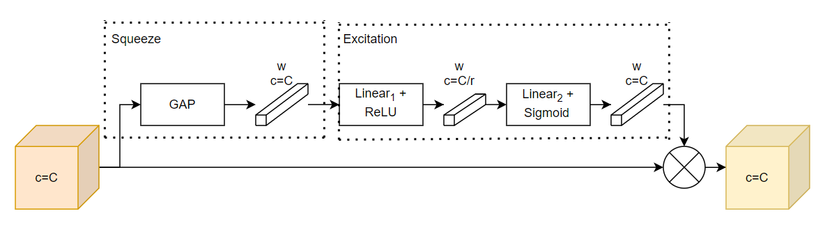
Code Pytorch:
import torch.nn as nn
classSEModule(nn.Module):def__init__(self, channels, reduction_rate=16):super(SEModule, self).__init__()
self.squeeze = nn.AdaptiveAvgPool2d(1)
self.excitation = nn.Sequential(
nn.Conv2d(in_channels=channels,
out_channels=channels // reduction_rate,
kernel_size=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=channels // reduction_rate,
out_channels=channels,
kernel_size=1),
nn.Sigmoid())defforward(self, x):
attention = self.squeeze(x)
attention = self.excitation(attention)return attention * x
Spatial Attention
Deformable Convolution
Mặc dù Self-Attention là một đại diện sáng giá hơn để nói về Spatial Attention nhưng như đã nói ở phần mở đầu: không có Self-Attention đâu.
Trước tiên ta phải tìm hiểu về tính chất của phép Convolution (Conv) và tại sao nó lại không tốt. Tính chất của Conv là Translation Equivariance. Tức là nếu sử dụng phép biến đổi đơn giản lên một vật trong input thì vật đó tại output cũng bị biến đổi (Hình 2). Điều này là không nên mong muốn vì nếu chỉ dịch vật đó đi một khoảng mà lại ảnh hưởng đến kết quả tại output, khiến prediction đưa ra là sai.
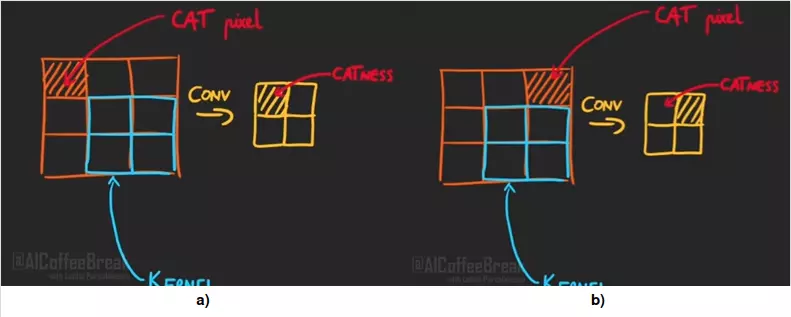
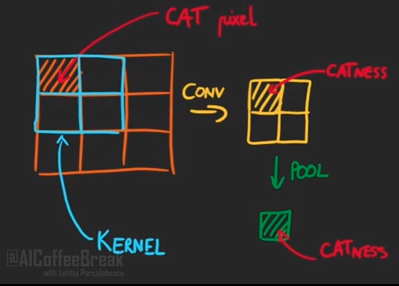
Vậy tại sao Convolutional Neural Network (CNN) vẫn tốt? Thứ nhất là trong CNN không chỉ có Conv, mà còn có cả Max Pooling (MP). Điều này một phần nào biến CNN thành Translation Invariance (chỉ một phần thôi) (Hình 3). Thứ hai, khi training CNN, ta sử dụng rất nhiều các loại augmentation như dịch, xoay, lật ảnh,… nên CNN có thể học được phần bị dịch chuyển đó.
Deformable Convolution (DCN) ra đời để giải quyết nhược điểm của Conv nói trên. Conv bình thương chỉ thực hiện tính toán trên một vùng có kích thước bằng kích thước của kernel size, còn DCN sẽ tính toán trên một vùng khá tự do (Hình 4).
Vậy làm thế nào để DCN di chuyển các vùng tính toán? DCN sẽ gồm 2 phần: phần Conv thông thường và phần tìm ra điểm dịch chuyển. Phần tìm ra điểm dịch chuyển được thực hiện thông qua một Conv với số filter là 2, đại diện cho độ dịch chuyển trên trục xx và độ dịch chuyển trên trục yy
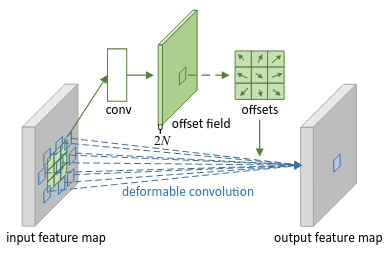
Cụ thể hơn nhé. Cảnh báo là lại có toán
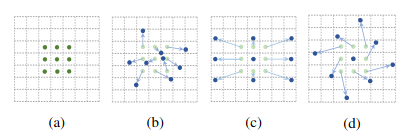
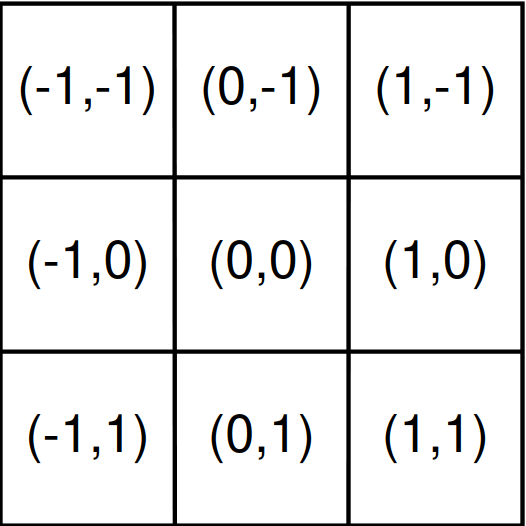
Xét một Conv thông thường, gồm 2 bước: Lấy tập hợp các điểm dịch chuyển thông thường từ tâm để tính toán, gọi là ℜRe và tính tổng trọng số trên feature maps tại những điểm dịch chuyển. ℜRe định nghĩa độ lớn của Receptive Field (Hình 6).
ℜ=[(0,0),(−1,−1),(−1,0),(0,−1),…,(1,0),(0,1),(1,1),…]Re = [(0, 0), (-1, -1), (-1, 0), (0, -1),…,(1,0), (0,1),(1,1),…]
Với mỗi điểm p0p_0 trên output feature maps yy, ta có:
y(p0)=∑pn∈ℜw(pn)⋅x(p0+pn)y(p_0) = sum_{p_n in Re} w(p_n) cdot x(p_0 + p_n)
với pnp_n là các phần tử trong ℜRe
Trong DCN, tập hợp ℜRe được biến đổi bằng cách thêm những offset ΔpnDelta p_n. Offset ΔpnDelta p_n được học thông qua một Conv như đã nói ở trên, ta có:
y(p0)=∑pn∈ℜw(pn)⋅x(p0+pn+Δpn)y(p_0) = sum_{p_n in Re} w(p_n) cdot x(p_0 + p_n + Delta p_n)
Chú ý rằng, ΔpnDelta p_n thường có giá trị phân số (do là kết quả của quá trình tính toán bởi Conv), nên pn+Δpnp_n + Delta p_n là một điểm khác với thông thường như trong ℜRe. Vì vậy, để tính được x(p0+pn+Δpn)x(p_0 + p_n + Delta p_n), ta phải tính thông qua 2 phép tính:
x(p0+pn+Δpn)=∑qG(q,p0+pn+Δpn)⋅x(q)x(p_0 + p_n + Delta p_n) = sum_q G(q, p_0 + p_n + Delta p_n) cdot x(q)
với qq là toàn bộ các điểm thông thường trong ℜRe, G(⋅,⋅)G(cdot, cdot) là một phép bilinear interpolation
Channel và Spatial Attention kết hợp
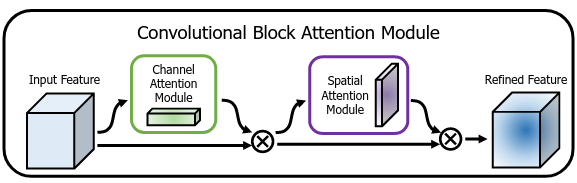
CBAM
CBAM bao gồm 2 phần là Channel Attention và Spatial Attention. Input feature maps sẽ được thực hiện Channel Attention trước, sau đó thực hiện tiếp Spatial Attention (Hình 7).
Channel Attention (Hình 8). Tương tự cách làm như SE Module, nhưng trong phần Squeeze của CBAM lại sử dụng đồng thời cả GAP và cả GMP (Global Max Pooling). Tác giả của CBAM nói rằng GMP cũng thu thập thông tin quan trọng của vật thể nhưng theo một khía cạnh khác. Sau đó, features thu được thì GMP và GAP đều được cho đi qua chung phần Excitation chứ k phải là 2 phần Excitation riêng biệt, tạo ra 2 vector. 2 Vector này sau đó được cộng vào với nhau và cũng lấy sigmoid như trong SE Module.
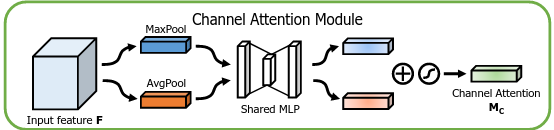
Code:
import torch.nn as nn
classChannelAttention(nn.Module):def__init__(self, channels, reduction_rate=16):super(ChannelAttention, self).__init__()
self.squeeze = nn.ModuleList([
nn.AdaptiveAvgPool2d(1),
nn.AdaptiveMaxPool2d(1)])
self.excitation = nn.Sequential(
nn.Conv2d(in_channels=channels,
out_channels=channels // reduction_rate,
kernel_size=1),
nn.ReLU(),
nn.Conv2d(in_channels=channels // reduction_rate,
out_channels=channels,
kernel_size=1))
self.sigmoid = nn.Sigmoid()defforward(self, x):# perform squeeze with independent Pooling
avg_feat = self.squeeze[0](x)
max_feat = self.squeeze[1](x)# perform excitation with the same excitation sub-net
avg_out = self.excitation(avg_feat)
max_out = self.excitation(max_feat)# attention
attention = self.sigmoid(avg_out + max_out)return attention * x
Spatial Attention (Hình 8). Spatial Attention của CBAM không phải dạng hard-core như DCN. Cách thực hiện Spatial Attention của CBAM rất đơn giản, tương tự như Channel Attention. Thay vì thực hiện GAP và GMP theo chiều channel, ta thực hiện GAP và GMP theo chiều spatial của feature maps, tạo ra 2 feature maps tổng hợp với số chiều channel là 1. 2 feature maps này sau đó được concatenate lại và đi qua một 7×77 times 7 Conv kèm Sigmoid với số filter là 1 để tạo ra attention. Đáng chú ý là ở đây ta phải dùng một Conv có kernel size to để có thể tính toán được vùng thông tin rộng hơn, chứ dùng 3×33 times 3 Conv thì vùng tính toán được của ta sẽ rất hẹp, giảm đi hiệu suất của attention được tạo ra.
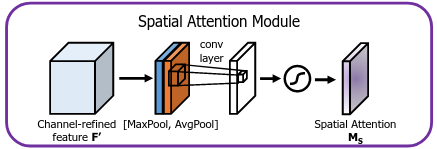
Code:
import torch.nn as nn
classSpatialAttention(nn.Module):def__init__(self, kernel_size=7):super(SpatialAttention, self).__init__()
self.conv = nn.Conv2d(
in_channels=2,
out_channels=1,
kernel_size=kernel_size,
padding=kernel_size //2)
self.sigmoid = nn.Sigmoid()defforward(self, x):# mean on spatial dim
avg_feat = torch.mean(x, dim=1, keepdim=True)# max on spatial dim
max_feat, _ = torch.max(x, dim=1, keepdim=True)
feat = torch.cat([avg_feat, max_feat], dim=1)
out_feat = self.conv(feat)
attention = self.sigmoid(out_feat)return attention * x
Toàn bộ CBAM có code như sau:
classCBAM(nn.Module):def__init__(self, channels, reduction_rate=16, kernel_size=7):super(CBAM, self).__init__()
self.channel_attention = ChannelAttention(channels,
reduction_rate)
self.spatial_attention = SpatialAttention(kernel_size)defforward(self, x):
out = self.channel_attention(x)
out = self.spatial_attention(out)return out
3D Attention
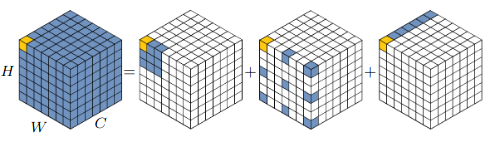
Trong SE Module, ta có thể attention để tinh chỉnh độ quan trọng của từng channel có dạng một vector. Tức là khi thực hiện nhân, toàn bộ vị trí trong một channel ii sẽ nhân với cùng một giá trị là vị trí ii trong vector attention. Việc tương tự cũng xảy ra với cả Spatial và Channel Attention trong CBAM. Tuy nhiên, với loại 3D Attention này, từng vị trí trong từng channel sẽ được nhân với một hệ số khác nhau (Như kiểu ta nhân 2 feature maps có chiều (B,C,H,W)(B, C, H, W) với nhau á).
LKA/MSCA
Đây là 2 Attention module mới có hiệu năng cực kì cao, được lấy từ 2 paper cùng tác giả là: “Visual Attention Network” và “SegNeXt: Rethinking Convolutional Attention Design for Semantic Segmentation”. Mình đã được dịp trao đổi với tác giả của 2 paper này, và họ lấy ý tưởng 3D Attention từ paper “Residual Attention Network for Image Classification”. Nhưng mình thấy LKA/MSCA dễ hiểu và hiệu năng tốt hơn hẳn nên mình trình bày tại đây luôn.
LKA (Large Kernel Attention)
Gần đây, Self-Attention thực sự đã thống trị trong không chỉ các bài toán liên quan đến ngôn ngữ mà còn cả những bài toán liên quan đến ảnh. Một trong những lý do hay được cho rằng Self-Attention rất mạnh là lý do tạo được Attention rất xa, có thể liên kết các phần xa nhau trong feature maps với nhau. Tuy nhiên, Self-Attention trong Vision thiếu đi Local Receptive Field (khả năng nhìn thấy những vật thể trong một vùng nhỏ – điều này là do cơ chế chia patch của ViT). Để có một Conv có khả năng liên kết các phần xa nhau, ta có thể tăng kernel size của Conv lên. Tuy nhiên việc này lại cực kì nặng trong tính toán. Thêm nữa, cả Conv và Self-Attention đều chưa chú tâm đến khả năng thay đổi trên chiều channel, hay còn gọi là không có Channel Attention đó.
LKA ra đời để khắc phục các nhược điểm nêu trên: Có khả năng liên kết xa + gần, nhẹ và bao gồm cả Channel Attention. Bản chất của LKA là một Conv có kernel size lớn (Large Kernel Conv) kèm theo Channel Attention.
Nhưng tại sao LKA lại nhẹ? LKA đã tận dụng triệt để Depth-wise Conv (được sử dụng trong MobileNet) để cho module này vô cùng nhẹ. Ta có thể phân tách Large Kernel Conv thành 3 thành phần: Spatial Local Conv (Conv cho các vùng nhỏ) sử dụng Depth-wise Conv (DWConv), Spatial Long-range Conv (Conv để liên kết các phần xa) sử dụng Depth-wise Dilated Conv (DW-DConv) và Channel Conv/Point Wise Conv (PWConv) (1×11 times 1 Conv). Cụ thể, một Conv có kernel K×KK times K sẽ được tách thành một ⌈Kd⌉×⌈Kd⌉lceil frac{K}{d} rceil times lceil frac{K}{d} rceil DW-DConv với dilation rate dd, một (2d−1)×(2d−1)(2d-1) times (2d-1) DWConv và 1×11 times 1 Conv (Hình 9).
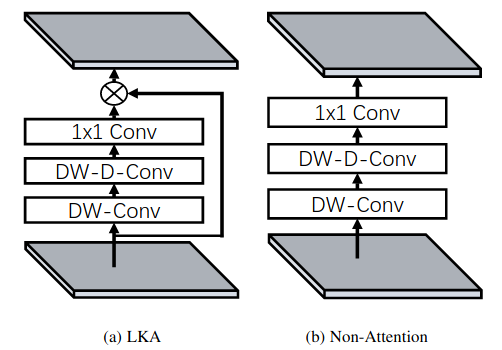
Sau khi phân tách, 3 Conv trên (DWConv, DW-DConv, PWConv) có thể tạo thành một lớp tính toán thông thường (Hình 10b). Tuy nhiên tác giả của VAN lại sử dụng nó như một cơ chế Attention (Hình 10a) và cho kết quả cao hơn hẳn. Vì vậy, quá trình tính toán như sau:
Attention=Conv1×1(DW-DConv(DWConv(x)))Attention = text{Conv}_ {1 times 1}(text{DW-DConv}(text{DWConv}(x)))
Output=Attention⋅xOutput = Attention cdot x
Code:
classLargeKernelAttn(nn.Module):def__init__(self,
channels):super(LargeKernelAttn, self).__init__()
self.dwconv = nn.Conv2d(
in_channels=channels,
out_channels=channels,
kernel_size=5,
padding=2,
groups=channels
)
self.dwdconv = nn.Conv2d(
in_channels=channels,
out_channels=channels,
kernel_size=7,
padding=9,
groups=channels,
dilation=3)
self.pwconv = nn.Conv2d(
in_channels=channels,
out_channels=channels,
kernel_size=1)defforward(self, x):
weight = self.pwconv(self.dwdconv(self.dwconv(x)))return x * weight
MSCA (Multi Scale Conv Attention)
MSCA tiếp tục ý tưởng phân tách một Large Kernel Conv thành các Conv nhỏ hơn. Tuy nhiên, MSCA mục đích là để sử dụng trong Segmentation nên có hơi đặc biệt hơn chút.
VÌ tính chất của bài toán Segmentation, nên việc tận dụng Multi Scale Context (các features có kích cỡ khác nhau) là cần thiết. Có nhiều paper đã áp dụng Multi Scale Context vào phần Decoder của model Segmentation như SPP, ASPP, Lawin,… nhưng SegNeXt áp dụng luôn vào backbone thông qua MSCA.
MSCA bao gồm 3 phần: DWConv để lấy thông tin cho vùng nhỏ, Multi Scale Strip Feature để tận dụng đồng thời Multi Scale Context và Strip Feature thông qua nhiều nhánh Depthwise Strip Conv (DW-SConv), và đương nhiên là không thể thiếu PWConv ($1 times 1 Conv) đóng vai trò như một Channel Attention (Hình 11).
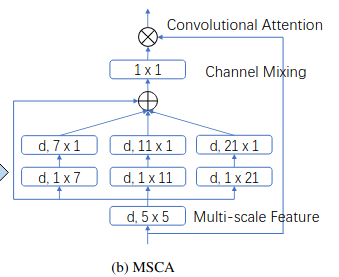
Ở đây, MSCA vẫn tận dụng Large Kernel, nhưng không giống như LKA, nó không sử dụng K×KK times K DWConv mà tách thành 1×K1 times K DWConv và K×1K times 1 DWConv. Đây gọi là Depthwise Strip Conv vì: (1) Strip Conv nhẹ và (2) bắt được các object có dạng strip (mảnh, dài). Ý tưởng của việc đến từ paper “Strip Pooling: Rethinking Spatial Pooling for Scene Parsing”
Code:
classMultiScaleStripAttn(nn.Module):def__init__(self,
channels):super(MultiScaleStripAttn, self).__init__()
self.dwconv = nn.Conv2d(
in_channels=channels,
out_channels=channels,
kernel_size=5,
padding=2,
groups=channels
)
self.scale_7 = nn.Sequential(
nn.Conv2d(
in_channels=channels,
out_channels=channels,
kernel_size=(1,7),
padding=(0,3),
groups=channels
),
nn.Conv2d(
in_channels=channels,
out_channels=channels,
kernel_size=(7,1),
padding=(3,0),
groups=channels
))
self.scale_11 = nn.Sequential(
nn.Conv2d(
in_channels=channels,
out_channels=channels,
kernel_size=(1,11),
padding=(0,5),
groups=channels
),
nn.Conv2d(
in_channels=channels,
out_channels=channels,
kernel_size=(11,1),
padding=(5,0),
groups=channels
))
self.scale_21 = nn.Sequential(
nn.Conv2d(
in_channels=channels,
out_channels=channels,
kernel_size=(1,21),
padding=(0,10),
groups=channels
),
nn.Conv2d(
in_channels=channels,
out_channels=channels,
kernel_size=(21,1),
padding=(10,0),
groups=channels
))
self.pwconv = nn.Conv2d(
in_channels=channels,
out_channels=channels,
kernel_size=1)defforward(self, x):
base_weight = self.dwconv(x)
weight1 = self.scale_7(base_weight)
weight2 = self.scale_11(base_weight)
weight3 = self.scale_21(base_weight)
weight = base_weight + weight1 + weight2 + weight3
weight = self.pwconv(weight)return x * weight
Kết
Phía trên là một số dạng kĩ thuật Attention được sử dụng trong Computer Vision khá là phổ biến (tất nhiên là trừ Self-Attention). Hy vọng các bạn có thể áp dụng kĩ thuật này vào model của bản thân và cải thiện hiệu năng
Reference
- Não
- Squeeze-and-Excitation Networks: https://arxiv.org/abs/1709.01507
- Deformable Convolutional Networks: https://arxiv.org/abs/1703.06211
- CBAM: Convolutional Block Attention Module: https://arxiv.org/abs/1807.06521
- Visual Attention Network: https://arxiv.org/abs/2202.09741
- SegNeXt: Rethinking Convolutional Attention Design for Semantic Segmentation: https://arxiv.org/abs/2209.08575
Nguồn: viblo.asia