Mở đầu
Nghĩ đi anh… đâu ai chung tình được mãi – đó là lời của một bài hát rất nổi tiếng gần đây. Trong tình yêu thì là vậy còn trong Machine Learning cũng có một hiện tượng như thế, mình tạm gọi là làm gì có mô hình nào tốt được mãi ngay cả khi chất lượng dữ liệu có tốt thì việc mô hình bị giảm chất lượng theo thời gian cũng thường xuyên diễn ra. Điều này có ý nghĩa và ảnh hưởng gì đến việc triển khai các mô hình AI trong thực tế, chúng ta sẽ cùng tìm hiểu trong bài hôm nay nhé.
Lỗi sai đến từ đâu
Các mô hình học máy thường phải đối mặt với các trường hợp dữ liệu bị hỏng, thiếu tính cập nhật hay không đầy đủ. Chất lượng của dữ liệu là một trong những nguyên nhân chính dẫn đến sai sót trên môi trường production. Nhưng có một vấn đề xảy ra rằng ngay cả khi dữ liệu được chuẩn bị kĩ lưỡng, đầy đủ chất lượng thì nó cũng không đảm bảo cho mô hình của chúng ta hoạt động tốt mãi mãi. Hiện tượng mô hình bị suy giảm về chất lượng vẫn diễn ra bất chấp các cố gắng trong việc cải thiện dữ liệu.
Có một vài thuật ngữ mà chúng ta sẽ cùng nhau thảo luận trong phần này như sau:
Model Decay
Chúng ta có thể gọi đó là sự trôi dạt (Drift), sự phân rã (decay) hay sự không ổn định của mô hình theo thời gian. Khi môi trường xung quanh thay đổi và hiệu suất của mô hình giảm dần theo thời gian. Độ đo cuối cùng là chất lượng mô hình. Đó có thể là độ chính xác, tỷ lệ lỗi trung bình hoặc một số KPI của ứng dụng, hiệu suất kinh doanh, chẳng hạn như tỷ lệ nhấp chuột vào quảng cáo chẳng hạn. Chúng ta cần một lưu ý nhỏ như sau:
Không có mô hình nào là chính xác mãi mãi, tuy nhiên tốc độ suy giảm chất lượng là khác nhau.
Có một vài mô hình cần cập nhật hàng năm (ví dụ như một số ứng dụng computer vision hay xử lý ngôn ngữ tự nhiên hoặc một số mô hình hoạt động trong môi trường ổn định), trong khi đó lại có một số mô hình cần phải cập nhật hàng ngày thậm chí hàng giờ (ví dụ như các mô hình trong dự đoán kết quả tài chính hay với các dữ liệu time series).
Sau khi mô hình được cập nhật, độ chính xác cần phải được cải thiện và thích ứng với những mẫu dữ liệu mới
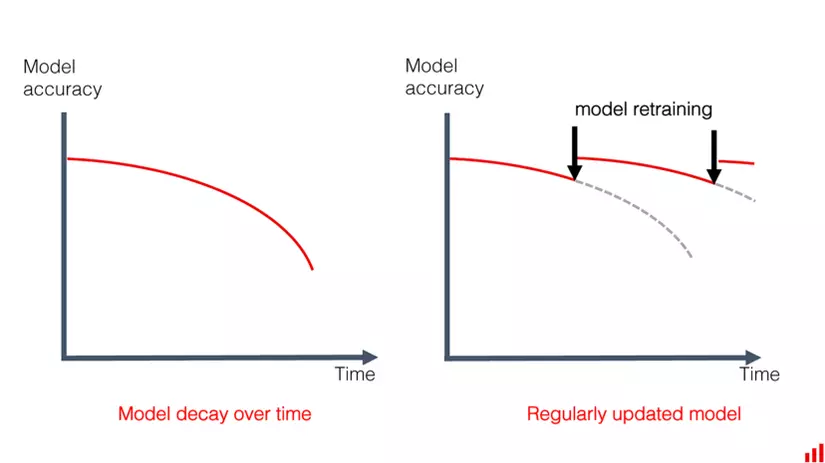
Thường có hai nguyên nhân dẫn đến sự suy giảm của mô hình đó là data Drift và concept Drift hoặc đôi khi là cả hai.
Data Drift
Còn có tên gọi khác như features Drift, population Drift hay covariate Drift, là hiện tượng khi input data bị thay đổi, phân phối của các đặc trưng có ý nghĩa bị thay đổi dẫn đến hiện tượng mô hình cũ không còn đáp ứng được độ chính xác với các distribution của dữ liệu nữa.
Mô hình vẫn hoạt động tốt trên dữ liệu tương tự như dữ liệu “cũ”. Đây được coi như một điều kiện tiêu chuẩn để mô hình hoạt động. Nhưng trong điều kiện thực tế, mô hình trở nên ít hữu ích hơn rất nhiều vì chúng ta đang xử lý một features space mới.
Ví dụ về mô hình dự đoán xu hướng
Các hệ thống thương mại điện tử có một nguồn thu khá lớn từ quảng cáo. Ngay sau khi người dùng vào sử dụng hệ thống, mô hình gợi ý quảng cáo sẽ có nhiệm vụ dự đoán ra các loại sản phẩm mà người dùng có khả năng sẽ mua và gửi cho họ các ưu đãi phù hợp.
Trước đây, việc suggestion được thực hiện đa phần trên các dữ liệu mà người dùng đã thực hiện mua sắm trên hệ thống trước đó. Tuy nhiên sau khi áp dụng các chiến lược marketing online thì có rất nhiều người dùng đến từ các nguồn khác nhau như Facebook, Google … .và hệ thống AI hoàn toàn chưa được học với những mẫu dữ liệu dạng này trước đó.
Tuy nhiên, chất lượng tổng thể của mô hình sẽ không quá ảnh hưởng nếu như số lượng những người dùng mới này là ít. Vấn đề sẽ thật sự nghiệm trọng nếu như lượng người dùng này trở nên nhiều hơn.
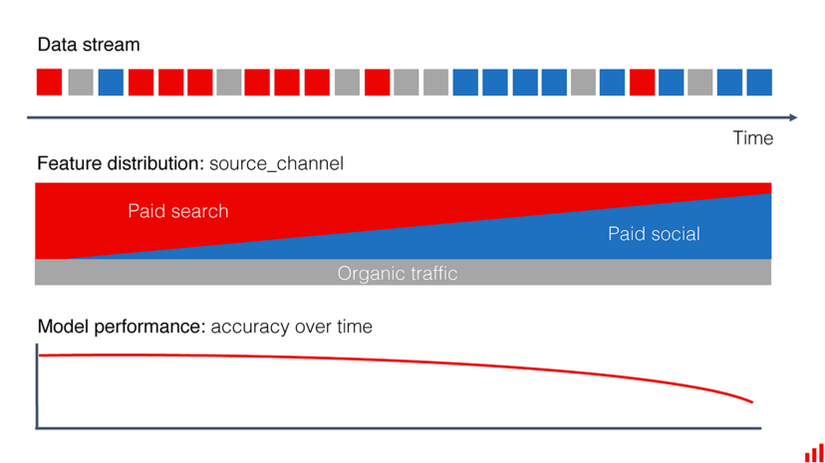
Khi tiến hành debug chúng ta sẽ thấy có sự khác biệt về phân phối của các thuộc tính như source_channel thể hiện nơi mà người dùng đến hệ thống (Ví dụ Facebook, Google hay Hệ thống hiện tại).
Việc monitoring các vấn đề này sẽ giúp chúng ta cảnh báo được hiện tượng Drift một cách sớm nhất có thể.
Những điều tương tự cũng xảy ra khi áp dụng một mô hình ở một khu vực địa lý mới hoặc độ tuổi của các người dùng hệ thống bị thay đổi

Để đối phó với hiện tượng này chúng ta cần training lại mô hình với các mẫu dữ liệu mới hoặc có những chiến lược phát hiện sớm để đưa ra các logic xử lý phù hợp.
Training-serving skew
Sự sai khác về dữ liệu lúc huấn luyện mô hình và khi chạy trên môi trường thực tế là điều rất hay xảy ra. Thông thường điều này xuất hiện khi dữ liệu huấn luyện khá sạch trong khi dữ liệu thực tế lại xuất hiện nhiều trường hợp khác nhau. Đôi lúc chúng ta cũng không thể lường hết được điều này trong quá trình huấn luyện bởi có những mẫu dữ liệu chỉ có thể xuất hiện khi sử dụng trong thực tế.
Chúng ta có thể xem ví dụ về hiện tượng này quá hình dưới dây. Cùng là một bài toán đơn giản về nhận dạng chữ viết tay nhưng tập dữ liệu training và tập dữ liệu inference trong thực tế đang khác nhau rất nhiều

Thông thường, khi xuất hiện training-serving skew thì việc tiếp tục cập nhật mô hình để thích ứng được với các kiểu dữ liệu mới là cần thiết.
Concept Drift
Concept Drift xuất hiện trong trường hợp mà partern ẩn mà mô hình học được từ dữ liệu bị thay đổi. Ngược lại với data Drift, trong concept Drift có thể distribution của dữ liệu đầu vào không thay đổi nhưng mối liên quan giữa các đặc trưng đầu vào với target có sự thay đổi. Hay nói cách khác, ý nghĩa của những gì chúng ta đang cố gắng dự đoán đã bị thay đổi. Điều đó làm cho mô hình bị kém đi hoặc lỗi thời theo thời gian
Concept Drift có thể đến từ một vài nguyên nhân như sau:
Gradual concept drift
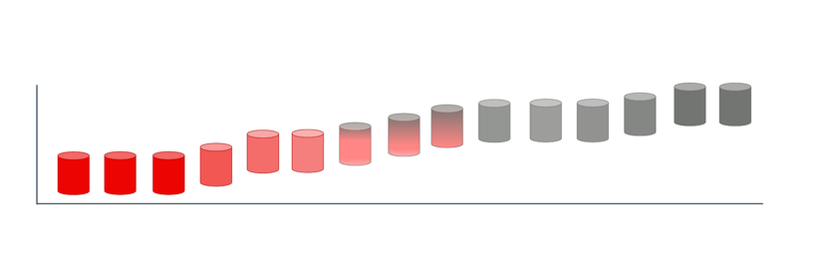
Quá trình Drift được diễn ra một cách từ từ, dần dần. Khi thế giới xung quanh thay đổi và mô hình của chúng ta dần dần trở nên lạc hậu đi, đó là lúc chúng ta cần phải bổ sung thêm các dữ liệu mới và cập nhật lại mô hình.
Một số ví dụ cho loại Drift này như:
- Công ty đối thủ ra mắt sản phẩm mới: dẫn đến khách hàng có nhiều lựa chọn hơn và hành vi của khách hàng thay đổi dẫn đến mô hình dự đoán về doanh thu cần được cập nhật
- Các quy định mới về tín dụng thay đổi dẫn đến một số yếu tố ảnh hưởng đến điểm rủi ro không còn đúng nữa. Chúng ta cần cập nhật mô hình credit scoring.
Sudden concept Drift
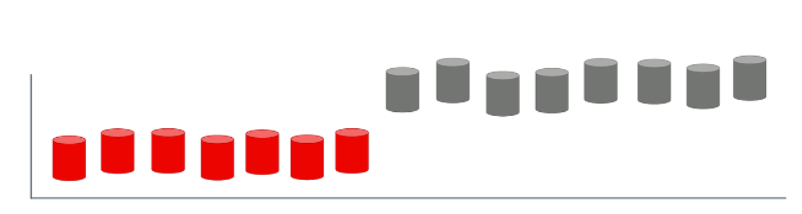
Tiêu biểu trong trường hợp này đó là các bài toán có biến động theo mùa seasoning data hay đơn giản có một yếu tố khách quan nào đó đột ngột xuất hiện làm thay đổi toàn bộ điều kiện xung quanh (ví dụ như đại dịch COVID 19 xuất hiện làm cho tất cả các cửa hàng phải đóng cửa và khiến cho mô hình không thể dự đoán được trong trường hợp này).
Giải pháp nào cho Drift

Retrain lại mô hình
Chúng ta có thể nghĩ ngay đến phương pháp đơn giản nhất để đối mặt với hiện tượng Drift đó chính là huấn luyện lại mô hình. Chúng ta có thể có các phương pháp huấn luyện như sau dựa trên dữ liệu đầu vào:
- Huấn luyện mô hình trên toàn bộ dữ liệu thu thập được (gồm cả cũ và mới)
- Huấn luyện mô hình trên dữ liệu cũ và mới nhưng với trọng số cao hơn trên dữ liệu mới
- Huấn luyện mô hình chỉ trên dữ liệu mới.
Một số giải pháp khác
Đâu đó chung ta cũng đã nghe đến một số phương pháp như:
- Domain Adaptation
- Out-of-distribution detection
- Outlier detection
- …
Kết luận
Drift là một hiện tượng rất phổ biến trong thực tế và cần phải có những giải pháp khắc phục nó nếu không muốn mô hình của chúng ta càng ngày càng kém đi. Có hai loại Drift cơ bản là Data Drift và Concept Drift, mỗi một loại sẽ cần những biện pháp khắc phục khác nhau. Trong bài tiếp theo chúng ta sẽ cùng nhau tìm hiểu về cách Monitoring các vấn đề của mô hình trên môi trường Production. Hẹn gặp lại các bạn trong bài tiếp theo
Nguồn: viblo.asia