Introduction
Image to Image translation là quá trình tạo ra phiên bản mới của một bức ảnh với một đặc trưng cụ thể. Ví dụ như chuyển từ ảnh grayscale sang ảnh màu, ảnh mặt người thật sang ảnh anime, tăng độ phân giải của ảnh



Để huấn luyện mô hình cho bài toán image to image translation theo hướng supervised learning, ta sẽ cần một lượng lớn các cặp ảnh input và label. Ví dụ như: ảnh màu và ảnh grayscale tương ứng với nó, ảnh mờ và ảnh đã được làm nét. Các ví dụ dữ liệu ở trên có thể được tạo ra khá dễ dàng bằng các phương pháp xử lý ảnh. Tuy nhiên, cũng có vô số trường hợp mà việc tạo ra cặp dataset như vật là gần như không thể:
- Style transfer ảnh từ mùa hè sang mùa đông (kiếm được ảnh phong cảnh trong các điều kiện khác nhau)
- Chuyển ảnh chụp sang phong cách của Van Gogh (tạch rồi sao gọi ông ấy về vẽ được nữa :v)
- Face filter mặt người sang anime
- Biến ngựa thường thành ngựa vằn (khó mà kiếm được ảnh của 1 con ngựa thường và ảnh của nó nhưng là ngựa vằn 😄).
Do các bộ dataset theo cặp gần như là không tồn tại hoặc khó để đánh nhãn nên các nhà nghiên cứu mới hướng tới giải quyết bài toán image to image translation theo hướng unsupervised với dữ liệu unpaired. Cụ thể hơn là ta có thể sử dụng bất kỳ hai tập ảnh không liên quan và các đặc trưng chung được trích xuất từ mỗi bộ sưu tập và sử dụng trong quá trình image translation. Đây được gọi là bài toán unpaired image-to-image translation.
Hiện nay, các cách tiếp cận tốt nhất cho bài toán image to image translation đều Generative Adversarial Network (GAN). Tiên phong cho bài toán unpaired image to image translation có thể kể đến mô hình: CycleGAN và DualGAN hay gần đây hơn là một cải tiến của CycleGAN là GANILLA – Generative Adversarial Networks for Image to
Illustration Translation
Generative Advesarial Network
Generative Adversarial Networks, là một họ các mô hình nổi tiếng với việc sử dụng các mô hình con đối nghịch nhau (Adversarial) để sinh ra (Generative) dữ liệu. GAN cấu tạo gồm 2 mạng nơron là Generator và Discriminator. Trong khi Generator sinh ra các dữ liệu giống như thật thì Discriminator cố gắng phân biệt đâu là dữ liệu được sinh ra từ Generator và đâu là dữ liệu thật có.
Một ví dụ nổi tiếng minh họa cho mô hình GAN là cuộc chiến giữa cảnh sátvà tội phạm làm tiền giả. Với dữ liệu có được là tiền thật, Generator giốngnhư tên tội phạm còn Discriminator giống như cảnh sát. Tên tội phạm sẽ cố gắng làm ra tiền giả mà cảnh sát cũng không phân biệt được. Còn cảnh sát sẽ phải phân biệt đâu là tiền thật và đâu là tiền giả. Mục tiêu cuối cùng của tên tội phạm là làm ra tiền mà cảnh sát cũng không phân biệt được đâu là thật và đâu là giả và mang tiền đi tiêu được. Cảnh sát cũng qua nhiều lần thấy tiền giả mà khả năng phân biệt cũng tăng lên. Từ đó, dẫn đến tội phạm sẽ phải nâng cấp khả năng làm tiền giả của mình.
Kiến trúc mô hình GANILLA
Bài báo GANILLA đã giới thiệu một domain mới trong bài toán style transfer: tranh minh họa cho sách trẻ em. So với các domain truyền thống trong các paper về image to image translation, tác giả bài báo cho rằng domain mới này có tính trừu tượng cao hơn

Các mô hình truyền thống như CycleGAN hay DualGAN gặp khó khăn trong việc cân bằng phong cách (style) trừu tượng trong tranh minh họa và nội dung (content) gốc của ảnh được transfer sang.
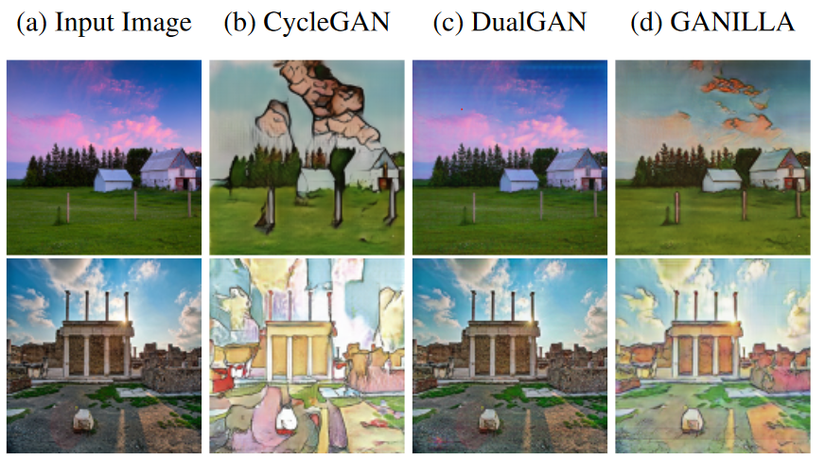
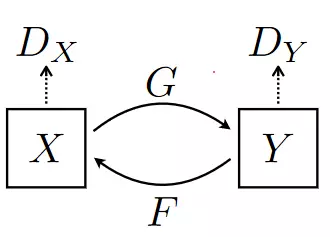
Để giải quyết vấn đề cân bằng giữa style và content, bài báo đề xuất một số thay đổi với kiến trúc generator của CycleGAN. Cũng giống như CycleGAN, GANILLA bao gồm 2 Generator và 2 Discriminator. Generator đầu tiên gọi là G, nhận đầu vào là ảnh từ domain X (tranh minh họa) và convert nó sang domain Y (ảnh chụp phong cảnh). Generator còn lại gọi là Y, có nhiệm vụ convert ảnh từ domain Y sang X. Mỗi mạng Generator có 1 Discriminator tương ứng với nó
- DYD_Y: phân biệt ảnh lấy từ domain Y và ảnh được translate G(x).
- DXD_X: phân biệt ảnh lấy từ domain X và ảnh được translate F(y).
Generator
Kiến trúc generator bao gồm 2 giai đoạn upsampling và downsampling
Phần downsampling là một mạng Resnet18 với một số sửa đổi:
- Thay thế lớp batch normalization bằng instance normalization
- Tại cuối mỗi khối residual, thay vì cộng feature map của input và output của khối, ta tiến hành concat.
Cụ thể hơn, phần sample sẽ bắt đầu bằng lớp convolution với filter 7×77 times 7 nối tiếp bởi lớp instance normalization, hàm kích hoạt ReLU và 1 lớp max pooling giảm kích thước feature map xuống 1/2. Tiếp theo, tương tự như kiến trúc resnet18, ta có 4 lớp con I, II, III, IV, mỗi lớp bao gồm 2 khối residual. Mỗi khối residual bao gồm 1 lớp convolution với filter 3×33 times 3, instance normalization, hàm kích hoạt ReLU theo sau bởi 1 lớp convolution và 1 lớp instance normalization nữa. Input của khối residual sẽ được concat với output của nó. Output của quá trình này sau đó được cho qua 1 lớp convolution và ReLU cuối cùng. Kích thước feature map sẽ giảm đi một nửa bằng convolution stride 2 sau mỗi lớp con trừ lớp I
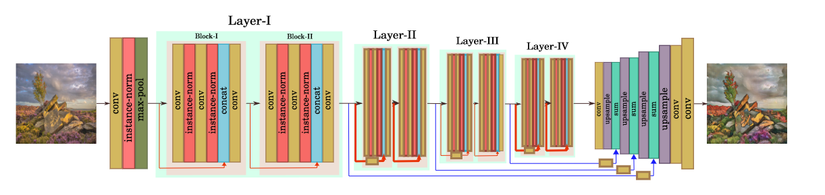
Trong phần upsampling, tác giả sử dụng skip connection giống mô hình Unet, để kết hợp các feature map từ lớp con của phần downsample với các output từ các lớp tích chập của phần upsampling. Ở đây, thay vì sử dụng concat, tác giả sử dụng phép cộng các feature map. Các kết nối tắt này giúp bảo toàn content của ảnh. Đầu tiên, output của lớp con IV từ downsample được cho qua 1 lớp convolution filter 1×11 times 1 và nearest neighbor upsampling để có kích thước bằng feature map của lớp con III. Quá trình này được tiếp tục ở các lớp con tiếp theo. Cuối cùng, ảnh output được tạo ra từ một lớp convolution 7×77 times 7 với 3 filter..
Discriminator
GANILLA vẫn giữ nguyên kiến trúc CNN PatchGAN từ CycleGAN. Mô hình được tạo thành từ 3 khối, mỗi khối bao gồm 2 lớp convolution với kernel 4×44 times 4 theo sau bởi lớp instance normalization và hàm kích hoạt LeakyReLU. Khối đầu tiên sẽ có 64 filter và gấp đôi với mỗi khối ở sau. Output của Discriminator sẽ là một lưới 70×7070 times 70. Mỗi ô sẽ dự đoán xác suất là thật giả của một vùng tương ứng trên ảnh.
Loss function
Phần này cũng tương tự CycleGAN, bao gồm 2 loss thành phần
Adversarial loss
Gồm 2 GAN loss cho 2 cặp Generator và Discriminator
LGAN(G,DY,X,Y)=Ey ∼ pdata(y)[logDY(y)]+Ex ∼ pdata(x)[log(1−DY(G(x))]L_{GAN}(G, D_Y, X, Y) = E_{y sim ~ p_{data}(y)}[ logD_{Y}(y)] + E_{x sim ~ p_{data}(x)}[log(1- D_Y(G(x))]
Ladv(F,DX,Y,X)=Ex ∼ pdata(x)[logDX(x)]+Ey ∼ pdata(y)[log(1−DX(F(y))]L_{adv}(F, D_X, Y, X ) = E_{x sim ~ p_{data}(x)}[ logD_{X}(x)] + E_{y sim ~ p_{data}(y)}[log(1- D_X(F(y))]
Cycle consistency loss
Để đảm bảo khi ta translate ảnh X sang domain Y, sau đó translate ngược lại về X sẽ được ảnh ban đầu
Lcycle(G,F)=1n∑∣∣F(G(xi))−xi∣∣1+∣∣G(F(yi))−yi∣∣1L_{cycle}(G, F) = frac{1}{n}sum||F(G(x_i)) – x_i||_1+||G(F(y_i)) – y_i||_1
Full Loss
L=LGAN(G,DY,X,Y)+Ladv(F,DX,Y,X)+λLcycle(G,F)L =L_{GAN}(G, D_Y, X, Y) +L_{adv}(F, D_X, Y, X ) + lambda L_{cycle}(G, F)
Cài đặt mô hình
Để cài đặt và huấn luyện mô hình, mình sẽ sử dụng pytorch, fastai và UPIT.
Install các thư viện cần thiết
pip install fastai==2.3.0
pip install git+https://github.com/tmabraham/UPIT.git
Generator
from fastai.vision.allimport*from fastai.basics import*from typing import List
# CellclassBasicBlock_Ganilla(nn.Module):
expansion =1def__init__(self, in_planes, planes, use_dropout, stride=1):super(BasicBlock_Ganilla, self).__init__()
self.rp1 = nn.ReflectionPad2d(1)
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, stride=stride, padding=0, bias=False)
self.bn1 = nn.InstanceNorm2d(planes)
self.use_dropout = use_dropout
if use_dropout:
self.dropout = nn.Dropout(use_dropout)
self.rp2 = nn.ReflectionPad2d(1)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=0, bias=False)
self.bn2 = nn.InstanceNorm2d(planes)
self.out_planes = planes
self.shortcut = nn.Sequential()if stride !=1or in_planes != self.expansion*planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*planes, kernel_size=1, stride=stride, bias=False),
nn.InstanceNorm2d(self.expansion*planes))
self.final_conv = nn.Sequential(
nn.ReflectionPad2d(1),
nn.Conv2d(self.expansion * planes *2, self.expansion * planes, kernel_size=3, stride=1,
padding=0, bias=False),
nn.InstanceNorm2d(self.expansion * planes))else:
self.final_conv = nn.Sequential(
nn.ReflectionPad2d(1),
nn.Conv2d(planes*2, planes, kernel_size=3, stride=1, padding=0, bias=False),
nn.InstanceNorm2d(planes))defforward(self, x):
out = F.relu(self.bn1(self.conv1(self.rp1(x))))if self.use_dropout:
out = self.dropout(out)
out = self.bn2(self.conv2(self.rp2(out)))
inputt = self.shortcut(x)
catted = torch.cat((out, inputt),1)
out = self.final_conv(catted)
out = F.relu(out)return out
# CellclassPyramidFeatures(nn.Module):def__init__(self, C2_size, C3_size, C4_size, C5_size, fpn_weights, feature_size=128):super(PyramidFeatures, self).__init__()
self.sum_weights = fpn_weights #[1.0, 0.5, 0.5, 0.5]# upsample C5 to get P5 from the FPN paper
self.P5_1 = nn.Conv2d(C5_size, feature_size, kernel_size=1, stride=1, padding=0)
self.P5_upsampled = nn.Upsample(scale_factor=2, mode='nearest')#self.rp1 = nn.ReflectionPad2d(1)#self.P5_2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, stride=1, padding=0)# add P5 elementwise to C4
self.P4_1 = nn.Conv2d(C4_size, feature_size, kernel_size=1, stride=1, padding=0)
self.P4_upsampled = nn.Upsample(scale_factor=2, mode='nearest')#self.rp2 = nn.ReflectionPad2d(1)#self.P4_2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, stride=1, padding=0)# add P4 elementwise to C3
self.P3_1 = nn.Conv2d(C3_size, feature_size, kernel_size=1, stride=1, padding=0)
self.P3_upsampled = nn.Upsample(scale_factor=2, mode='nearest')#self.rp3 = nn.ReflectionPad2d(1)#self.P3_2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, stride=1, padding=0)
self.P2_1 = nn.Conv2d(C2_size, feature_size, kernel_size=1, stride=1, padding=0)
self.P2_upsampled = nn.Upsample(scale_factor=2, mode='nearest')
self.rp4 = nn.ReflectionPad2d(1)
self.P2_2 = nn.Conv2d(int(feature_size),int(feature_size/2), kernel_size=3, stride=1, padding=0)#self.P1_1 = nn.Conv2d(feature_size, feature_size, kernel_size=1, stride=1, padding=0)#self.P1_upsampled = nn.Upsample(scale_factor=2, mode='nearest')#self.rp5 = nn.ReflectionPad2d(1)#self.P1_2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, stride=1, padding=0)defforward(self, inputs):
C2, C3, C4, C5 = inputs
i =0
P5_x = self.P5_1(C5)* self.sum_weights[i]
P5_upsampled_x = self.P5_upsampled(P5_x)#P5_x = self.rp1(P5_x)# #P5_x = self.P5_2(P5_x)
i +=1
P4_x = self.P4_1(C4)* self.sum_weights[i]
P4_x = P5_upsampled_x + P4_x
P4_upsampled_x = self.P4_upsampled(P4_x)#P4_x = self.rp2(P4_x)# #P4_x = self.P4_2(P4_x)
i +=1
P3_x = self.P3_1(C3)* self.sum_weights[i]
P3_x = P3_x + P4_upsampled_x
P3_upsampled_x = self.P3_upsampled(P3_x)#P3_x = self.rp3(P3_x)#P3_x = self.P3_2(P3_x)
i +=1
P2_x = self.P2_1(C2)* self.sum_weights[i]
P2_x = P2_x * self.sum_weights[2]+ P3_upsampled_x
P2_upsampled_x = self.P2_upsampled(P2_x)
P2_x = self.rp4(P2_upsampled_x)
P2_x = self.P2_2(P2_x)return P2_x
# CellclassResNet(nn.Module):def__init__(self, input_nc, output_nc, ngf, use_dropout, fpn_weights, block, layers):
self.inplanes = ngf
super(ResNet, self).__init__()# first conv
self.pad1 = nn.ReflectionPad2d(input_nc)
self.conv1 = nn.Conv2d(input_nc, ngf, kernel_size=7, stride=1, padding=0, bias=True)
self.in1 = nn.InstanceNorm2d(ngf)
self.relu = nn.ReLU(inplace=True)
self.pad2 = nn.ReflectionPad2d(1)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=0)# Output layer
self.pad3 = nn.ReflectionPad2d(output_nc)
self.conv2 = nn.Conv2d(64, output_nc,7)
self.tanh = nn.Tanh()if block == BasicBlock_Ganilla:# residuals
self.layer1 = self._make_layer_ganilla(block,64, layers[0], use_dropout, stride=1)
self.layer2 = self._make_layer_ganilla(block,128, layers[1], use_dropout, stride=2)
self.layer3 = self._make_layer_ganilla(block,128, layers[2], use_dropout, stride=2)
self.layer4 = self._make_layer_ganilla(block,256, layers[3], use_dropout, stride=2)
fpn_sizes =[self.layer1[layers[0]-1].conv2.out_channels,
self.layer2[layers[1]-1].conv2.out_channels,
self.layer3[layers[2]-1].conv2.out_channels,
self.layer4[layers[3]-1].conv2.out_channels]else:print("This block type is not supported")
sys.exit()
self.fpn = PyramidFeatures(fpn_sizes[0], fpn_sizes[1], fpn_sizes[2], fpn_sizes[3], fpn_weights)def_make_layer_ganilla(self, block, planes, blocks, use_dropout, stride=1):
strides =[stride]+[1]*(blocks -1)
layers =[]for stride in strides:
layers.append(block(self.inplanes, planes, use_dropout, stride))
self.inplanes = planes * block.expansion
return nn.Sequential(*layers)deffreeze_bn(self):'''Freeze BatchNorm layers.'''for layer in self.modules():ifisinstance(layer, nn.BatchNorm2d):
layer.eval()defforward(self, inputs):
img_batch = inputs
x = self.pad1(img_batch)
x = self.conv1(x)
x = self.in1(x)
x = self.relu(x)
x = self.pad2(x)
x = self.maxpool(x)
x1 = self.layer1(x)
x2 = self.layer2(x1)
x3 = self.layer3(x2)
x4 = self.layer4(x3)
out = self.fpn([x1, x2, x3, x4])# use all resnet layers
out = self.pad3(out)
out = self.conv2(out)
out = self.tanh(out)return out
defganilla_generator(input_nc, output_nc, ngf, drop, fpn_weights=[1.0,1.0,1.0,1.0], init_type='normal', gain=0.02,**kwargs):"""Constructs a ResNet-18 GANILLA generator."""
model = ResNet(input_nc, output_nc, ngf, drop, fpn_weights, BasicBlock_Ganilla,[2,2,2,2],**kwargs)return model
PatchGAN Discrminator
defconv_norm_lr(ch_in:int, ch_out:int, norm_layer:nn.Module=None, ks:int=3, bias:bool=True, pad:int=1, stride:int=1,
activ:bool=True, slope:float=0.2, init=nn.init.normal_, init_gain:int=0.02)->List[nn.Module]:
conv = nn.Conv2d(ch_in, ch_out, kernel_size=ks, padding=pad, stride=stride, bias=bias)if init:if init == nn.init.normal_:
init(conv.weight,0.0, init_gain)else:
init(conv.weight)ifhasattr(conv,'bias')andhasattr(conv.bias,'data'): conv.bias.data.fill_(0.)
layers =[conv]if norm_layer isnotNone: layers.append(norm_layer(ch_out))if activ: layers.append(nn.LeakyReLU(slope, inplace=True))return layers
defdiscriminator(ch_in:int, n_ftrs:int=64, n_layers:int=3, norm_layer:nn.Module=None, sigmoid:bool=False)->nn.Module:
norm_layer = ifnone(norm_layer, nn.InstanceNorm2d)
bias =(norm_layer == nn.InstanceNorm2d)
layers = conv_norm_lr(ch_in, n_ftrs, ks=4, stride=2, pad=1)for i inrange(n_layers-1):
new_ftrs =2*n_ftrs if i <=3else n_ftrs
layers += conv_norm_lr(n_ftrs, new_ftrs, norm_layer, ks=4, stride=2, pad=1, bias=bias)
n_ftrs = new_ftrs
new_ftrs =2*n_ftrs if n_layers <=3else n_ftrs
layers += conv_norm_lr(n_ftrs, new_ftrs, norm_layer, ks=4, stride=1, pad=1, bias=bias)
layers.append(nn.Conv2d(new_ftrs,1, kernel_size=4, stride=1, padding=1))if sigmoid: layers.append(nn.Sigmoid())return nn.Sequential(*layers)Training
Việc huấn luyện mô hình khá đơn giản với sự hỗ trợ của UPIT và fastai. Ở đây mình sẽ sử dụng bộ dataset monet2photo. Cấu trúc thư mục của dataset sẻ như thế này


from fastai.vision.allimport*from upit.data.unpaired import get_dls
from upit.models.ganilla import*from upit.train.cyclegan import cycle_learner
from upit.tracking.wandb import SaveModelAtEndCallback
image_path = Path('monet2photo')
trainA_path = image_path /'trainA'
trainB_path = image_path /'trainB'
ganilla = GANILLA(3,3,64)
dls = get_dls(trainA_path, trainB_path, load_size=256, crop_size=224, num_workers=4)
learn = cycle_learner(dls,
ganilla,
opt_func=partial(Adam,mom=0.5,sqr_mom=0.999),
cbs=[SaveModelAtEndCallback()],
show_imgs=False)
learn.fit(50,50,1e-4)Kết quả



Extra: Ghibli dataset

Kết quả khi train trên bộ ảnh crop ra từ phim Ghibli (link)



References
Nguồn: viblo.asia