Lời tựa
Tiếp tục về topic monitoring và alerting trên Kubernetes dùng Prometheus và Grafana, hôm nay mình sẽ chia sẻ cách cấu hình rule cảnh báo và gửi notification khi có cảnh báo qua email.
Các bạn có thể tham khảo các bài viết trước của mình nếu chưa đọc để đi theo dòng cho nó trôi nhé 
- Tổng quan và hướng dẫn cài đặt Prometheus-AlertManager-Granfa dùng bộ kube-prometheus-stack (cài bằng helm). Link: https://viblo.asia/p/k8s-phan-8-monitoring-tren-kubernetes-cluster-dung-prometheus-va-grafana-Qbq5QRkEKD8
- Hướng dẫn cấu hình Prometheus để lấy metric của service. Link: https://viblo.asia/p/k8s-phan-9-toi-uu-hoa-cau-hinh-prometheus-dung-service-monitor-1Je5EAry5nL
Giới thiệu
Trong các phần trước mình đã giới thiệu về các thành phần của monitoring gồm Alert Manager – Prometheus – Grafana và cách lấy metric của service qua Prometheus để lưu vào Elastic Search.
Trong phần này mình sẽ chia sẻ với các bạn cách cấu hình rule để sinh cảnh báo và gửi thông tin cảnh báo ra bên ngoài sử dụng gmail.
Mục tiêu của bài viết hôm nay sẽ giúp các bạn:
- Hiểu cách cấu hình rule cho service
- Hiểu cách sử dụng Prometheus Rule để cấu hình rule cho service
- Hiểu cách cấu hình AlertManager để gửi cảnh báo
- Cách trouble-shoot các vấn đề phát sinh trong khi cấu hình
Trước hết các bạn hãy cùng review lại về luồng lấy metric và gửi cảnh báo của Prometheus và AlertManager như sau: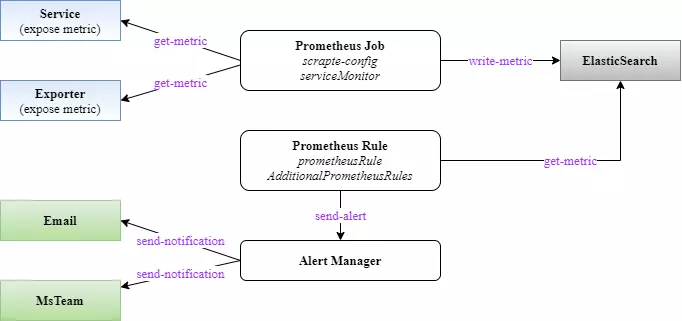
Luồng giám sát được mô tả như sau:
- Prometheus lấy thông tin metric từ các đối tượng cần giám sát và lưu vào elastic search
- Prometheus đọc các rule (là các hàm so sánh giá trị metric với các ngưỡng xác định) để quyết định những rule nào cần cảnh báo (alert) để đẩy về Alert Manager. Có 2 cách để cấu hình rule cho Prometheus trong bộ kube-prometheus-stack này, đều bằng cách tùy biến file helm-value của stack này:
- Cấu hình trực tiếp vào tham số additionalPrometheusRules:, ví dụ:
additionalPrometheusRules:-name: my-rule-file groups:-name: my_group rules:-record: my_record expr: 100 * my_record- Sử dụng đối tượng PrometheusRule để khai báo rule cho service. Để làm được việc này thì ta cần cấu hình tham số ruleNamespaceSelector và ruleSelector để chỉ định cách Prometheus đọc các PrometheusRule của K8S.
- Alert Manager sẽ có config riêng của nó để thực hiện việc “phân luồng” cảnh báo tới các người nhận khác nhau, việc này gọi là “route”. Thông tin người nhận (gọi là receiver) được cấu hình ở Alert Manager, hỗ trợ khá đa dạng từ email, slack, msteam, telegram…
Cấu hình rule trực tiếp vào helm-value
Là cách 1 đề cập bên trên, các bạn sẽ cấu hình trực tiếp các rule và trong cấu hình additionalPrometheusRules.
Cách này có một số vấn đề:
- Khi số lượng rule lớn, file helm-value sẽ trở nên rất lớn, cồng kềnh và khó quản lý
- Mỗi khi cần tạo thêm rule lại phải update lại file helm-value này và update lại stack (bằng lệnh helm-upgrade)
- Khó troubleshoot khi cấu hình bị sai lỗi cú pháp sẽ không update dc vào Prometheus sẽ tốn công debug
Do đó mình không recommend sử dụng cách này, hoặc chỉ dùng để demo thôi thì ok
Cấu hình rule bằng cách sử dụng Prometheus Rule
Cách sử dụng của PrometheusRule giống như cách sử dụng của serviceMonitor vậy. Ý tưởng của cách làm này như sau:
- Bạn sẽ cấu hình Prometheus đọc các PrometheusRule ở các namespace nhất định mà khớp với các label nhất định
- Với mỗi service cần khai báo rule, ta sẽ tạo một file PrometheusRule dạng yaml, trong đó có 2 phần quan trọng:
- Label gán cho đối tượng PrometheusRule này phải match với cấu hình ruleSelector đã cấu hình ban đầu để đảm bảo nó được tạo ra thì sẽ được tự động load vào cấu hình rule của Prometheus
- Các cấu hình rule cảnh báo của service (là các biểu thức so sánh các metric với các tham số ngưỡng để sinh cảnh báo)
Như vậy cách làm này sẽ giải quyết triệt để được các vấn đề bên trên. Lúc này bạn sẽ quản lý các file yaml là các bộ rule cho các service, khi cần update thì sẽ update vào file yaml này và cập nhật vào k8s bằng lệnh kubectl apply. Và các bạn hoàn toàn có thể tái sử dụng các rule này cho cùng service khi triển khai cho các dự án khác. Thật là tiện lợi phải không nào
Cấu hình ruleSelector cho Prometheus
Về lý thuyết mình cần cấu hình 2 tham số:
- ruleNamespaceSelector: Để chỉ định sẽ đọc các PrometheusRule ở những namespace nào. Mình muốn đọc từ tất cả namespace nên để giá trị này là mặc định
- ruleSelector: Là cấu hình cách filter các đối tượng PrometheusRule sẽ được load vào Prometheus. Ở đây mình sẽ dùng cách là filter theo label và mình sẽ đọc rất cả các PrometheusRule có gán label có key app và có giá trị trong các giá trị sau: “kube-prometheus-stack”, “viettq-prometheus-rule”.
Giải thích thêm một chút ở đây là khi bạn cài bộ kube-prometheus-stack thì đi kèm với nó đã có các rule mặc định và gán label “app=kube-prometheus-stack, còn label “app=viettq-prometheus-rule” sẽ là cái mình gán cho các PrometheusRule được tạo về sau này.
Giờ mình sẽ cấu hình tham số trong file helm-value (theo các bài hướng dẫn trước của mình là file values-prometheus-clusterIP.yaml) của bộ kube-prometheus-stack như sau:
ruleNamespaceSelector:{}ruleSelector:matchExpressions:-key: app
operator: In
values:- viettq-prometheus-rule
- kube-prometheus-stack
Sau đó update lại stack bằng lệnh helm upgrade:
helm -n monitoring upgrade prometheus-stack -f values-prometheus-clusterIP.yaml kube-prometheus-stack
Sau bước này thì Prometheus nó sẽ hiểu là nó sẽ đọc tất cả các đối tượng PrometheusRule ở tất cả các namespace mà có gán một trong label là “app=kube-prometheus-stack hoặc “app=viettq-prometheus-rule“
Khai báo PrometheusRule
Khi khai báo một PrometheusRule mới thì cái đầu tiên mình quan tâm là phải khai báo label match với cấu hình ruleSelector của Prometheus, cụ thể trong trường hợp này cần gán label là “app=viettq-prometheus-rule“
Ta khai báo file minio-AlertRule.yaml có nội dung như sau:
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:labels:app: viettq-prometheus-rule #Label này match với cấu hình ruleSelector để nó được load tự động vào Prometheusrole: alert-rules
name: viettq-minio-prometheus-rule #Đây là tên hiển thị trong danh sách PrometheusRule trên K8Sspec:groups:-name:"viettq-minio-rule"#Tên Rule hiển thị trên mục Rule của Prometheus trên web Prometheusrules:-alert: MinioDiskOffline #Tên của cảnh báofor: 1m #Thời gian đạt điều kiện trước khi sinh cảnh báo. expr: minio_cluster_nodes_offline_total != 1 #Điểu kiện so sánh để sinh cảnh báoannotations:message: Minio Disk offline
Sau đó apply nó vào namespace monitoring:
kubectl -n monitoring apply -f minio-AlertRule.yaml
Giải thích:
- Sau bước trên, ta đã tạo một đối tượng PrometheusRule trên K8S có tên là viettq-minio-prometheus-rule ở namespace monitoring
[[email protected] prometheus]$ kubectl -n monitoring get PrometheusRule
NAME AGE
viettq-minio-prometheus-rule 24h
- Đối tượng PrometheusRule này có gán label “app=viettq-prometheus-rule” nên sẽ được load vào cấu hình rule của Prometheus
- Phần spec của nó khai báo một rule có nội dung nôm na là “nếu điều kiện giá trị minio_cluster_nodes_offline_total khác 1 đúng trong vòng 1 phút trở lên thì sẽ sinh một cảnh báo có tên MinioDiskOffline và có thông tin thêm trong bản tin cảnh báo là Minio Disk offline
Giờ ta kiểm tra xem rule này được được load vào Prometheus hay chưa bằng cách vào web Prometheus, vào mục Rules: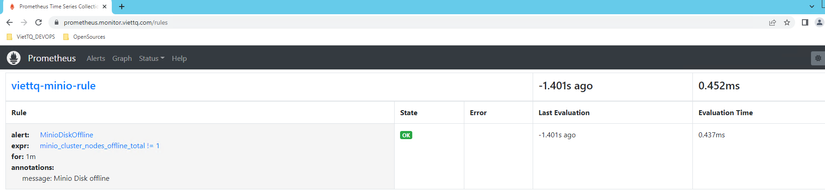
Như vậy rule này được load vào Prometheus thành công. Ta kiểm tra giá trị của metric minio_cluster_nodes_offline_total đang là bao nhiêu:
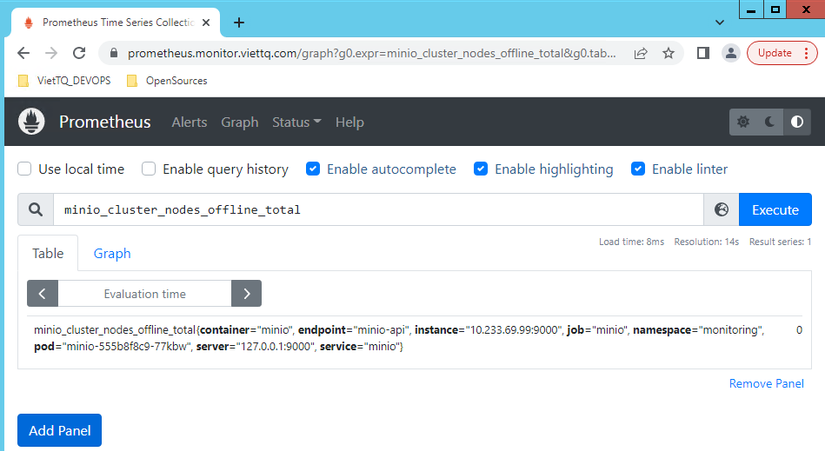
Kết quả giá trị minio_cluster_nodes_offline_total=0 do đó về lý thuyết thì sau 1 phút sẽ có cảnh báo.
Ta tiếp tục kiểm tra Alert Manager xem có xuất hiện cảnh báo hay chưa: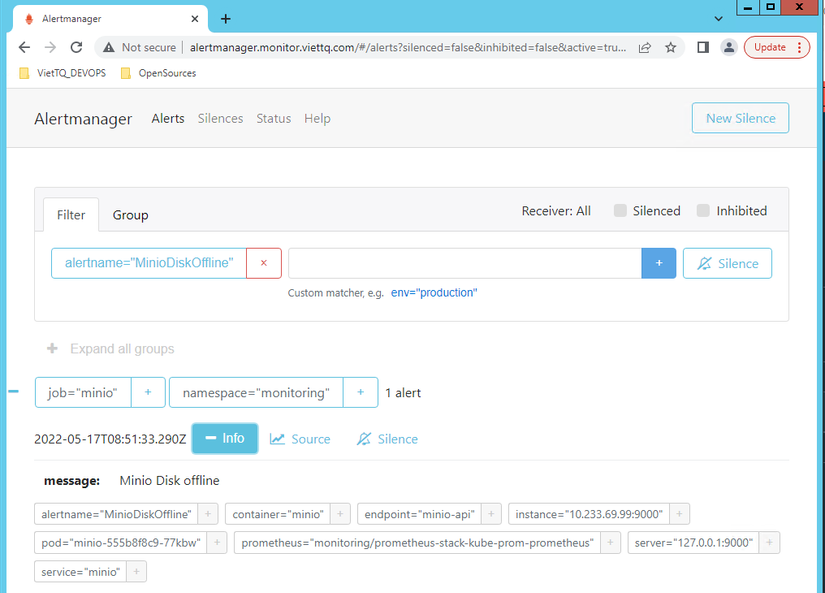
Như vậy là đã có cảnh báo. Việc cấu hình đang rất suôn sẻ.
Câu chuyện lại tiếp tục như sau. Khi bạn cấu hình rule và khi service cần giám sát có vấn đề và có cảnh báo thì bạn không thể nhìn vào màn hình của alert manager 24/7 được. Do đó bài toán đặt ra là cần phải gửi thông báo qua một kênh nào đó nhưng msteam, telegram hay email mỗi khi có cảnh báo để người trực hệ thống nắm được vào vào xử lý một cách chủ động. Đó là lúc bạn tiếp tục phải cấu hình cho Alert Manager!
Cấu hình Alert Manager gửi cảnh báo qua gmail
Cấu hình gmail để sử dụng cho app
Điều kiện cần là bạn có một account gmail dùng để gửi email cảnh báo. Sau đó bạn cần cấu hình App Password để sử dụng cho AlertManager kết nối tới máy chủ Gmail để gửi email. Ngoài ra cũng cần đảm bảo Alert Manager của bạn phải có kết nối internet để thông kết nối với gmail nhé!
Để thực hiện cấu hình App Password các bạn làm theo các bước như sau: Đăng nhập vào gmail của bạn, chọn Settings -> Security -> Signing in to Google -> App password (trong trường hợp ko thấy mục App Password thì có thể do bạn chưa cấu hình 2-Step Verification. Bạn hãy cấu hình 2-Step Verification trước rồi quay lại thực hiện lại bước này).
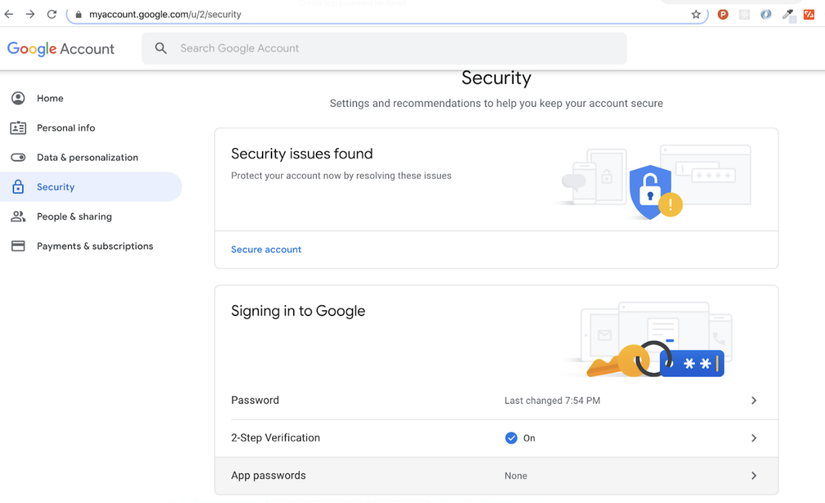
Sau khi thực hiện xong thì Copy password mới được tạo ra về để lát nữa sẽ dùng trong cấu hình của AlertManager.
Cấu hình Alert Manager
Cấu hình Alert Manager có một số tham số quan trọng là route và receiver. Hiểu nôm na là các cấu hình route (điều hướng) làm nhiệm vụ phân tích các cảnh báo theo các lable để chuyển hướng tới các receiver (nơi nhận) khác nhau.
Cấu hình route có thể giải thích theo một vài usecase như sau cho các bạn dễ hiểu:
- Routing theo namespace để điều hướng người nhận cảnh báo tới người quản lý namespace tương ứng đó:
- Cấu hình các cảnh báo đến từ namespace “dev” tới receiver là dev-team, receiver này là gửi email tới nhóm dev
- Cấu hình các cảnh báo đến từ namespace “prod” tới receiver là ope-team, receiver này là gửi email tới nhóm operation
- Routing theo loại service để điều hướng người nhận cảnh báo tới người quản lý service tương ứng đó:
- Cấu hình các cảnh báo liên quan tới database tới nhóm DBA
- Cấu hình các cảnh báo liên quan tới opensource khác (ngoài db) tới nhóm devops
- Cấu hình các cảnh báo liên quan tới ứng dụng inhouse tới nhóm dev
Các cách cấu hình route này các bạn tự tìm hiểu thêm, trong nội dung bài này mình không đề cập sâu tới vấn đề này.
Trong cấu hình receiver thì tùy từng loại (email, webhook..) mà có các tham số cấu hình khác nhau nhưng nói chung nó chứa thông tin để gửi cảnh báo tới nơi nhận đó.
Để cấu hình gửi cảnh báo qua email cho Alert Manager thì mình cần update lại file helm-value (theo các bài hướng dẫn trước của mình là file values-prometheus-clusterIP.yaml) của bộ kube-prometheus-stack như sau:
alertmanager:enabled:trueconfig:global:resolve_timeout: 5m
route:group_by:['namespace','job']group_wait: 5s
group_interval: 5s
repeat_interval: 5m
receiver:'gmail'routes:-receiver:'gmail'group_wait: 10s
matchers:- namespace="monitoring"
receivers:-name:'gmail'email_configs:-to:[email protected]from:[email protected]smarthost: smtp.gmail.com:587auth_username:'[email protected]'auth_identity:'[email protected]'auth_password:'jlmxxrshxtibeuhw'templates:-'/etc/alertmanager/config/*.tmpl'Sau đó update lại stack để cập nhật cấu hình mới:
helm -n monitoring upgrade prometheus-stack -f values-prometheus-clusterIP.yaml kube-prometheus-stack
Lúc này bạn vào web của Alert Manager, vào mục status sẽ thấy cấu hình được cập nhật:
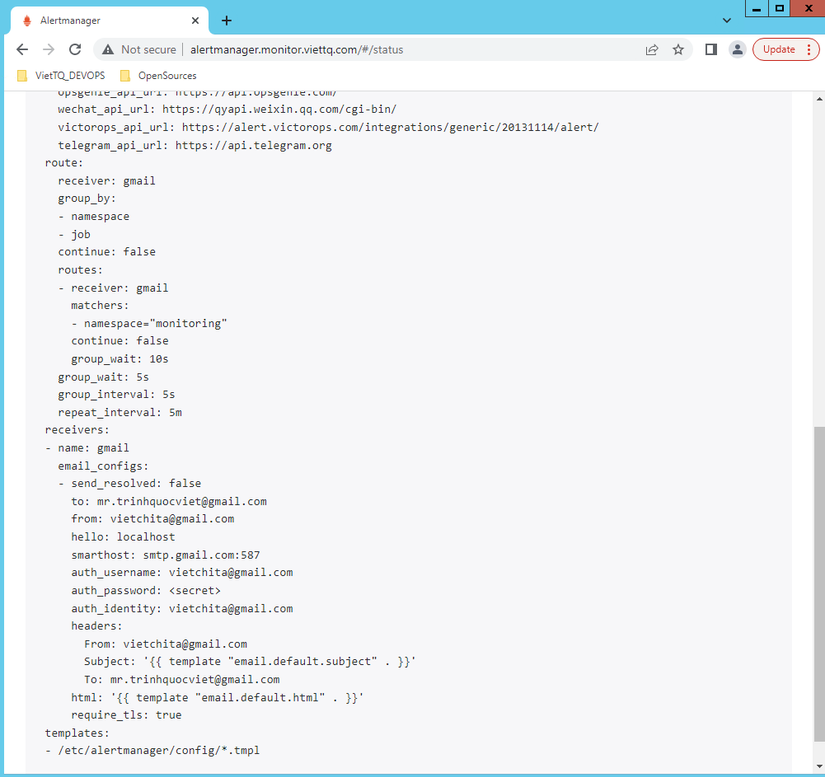
Giải thích cấu hình bên trên:
- Mặc định mọi cảnh báo sẽ được gán vào receiver mặc định là gmail, nếu nó match bất cứ route nào tiếp theo thì nó sẽ được đổi sang cấu hình receiver của route đó
- Mình có cấu hình một route là với các cảnh báo đến từ namespace=”monitoring” sẽ được điều hướng tới receiver gmail (bản chất vẫn là 1 cái receiver vì mình lười ko muốn tạo nhiều )
- Trong cấu hình receiver thì mình cấu hình thông tin email gồm:
- to: Địa chỉ email nhận cảnh báo
- from: địa chỉ email gửi cảnh báo
- smarthost: địa chỉ server mail
- auth_username, auth_identity dùng luôn địa chỉ gmail
- auth_password: Chính là thông tin app password đã tạo ở bước cấu hình gmail bên trên
Kiểm tra cảnh báo gửi đi
Nếu bạn không thấy có cảnh báo gửi đi thì check log của Alert Manager xem lỗi ở đâu nhé, có thể do cấu hình user/pass hay địa chỉ mail server sai, hoặc không có kết nối internet.. thì fix các issue đó và thử lại thôi.
Ví dụ check log như sau:
[[email protected] prometheus]$ kubectl -n monitoring logs -f --tail=10 alertmanager-prometheus-stack-kube-prom-alertmanager-0 -c alertmanager --timestamps
2022-05-17T11:30:36.887333564Z ts=2022-05-17T11:30:36.887Z caller=dispatch.go:354 level=error component=dispatcher msg="Notify for alerts failed" num_alerts=1 err="gmail/email[0]: notify retry canceled after 5 attempts: establish connection to server: dial tcp: i/o timeout"
2022-05-17T11:30:36.887386035Z ts=2022-05-17T11:30:36.887Z caller=dispatch.go:354 level=error component=dispatcher msg="Notify for alerts failed" num_alerts=1 err="gmail/email[0]: notify retry canceled after 5 attempts: establish connection to server: dial tcp: i/o timeout"
2022-05-17T11:30:36.960541310Z ts=2022-05-17T11:30:36.960Z caller=dispatch.go:354 level=error component=dispatcher msg="Notify for alerts failed" num_alerts=1 err="gmail/email[0]: notify retry canceled after 5 attempts: establish connection to server: dial tcp: i/o timeout"
2022-05-17T11:30:38.107007445Z ts=2022-05-17T11:30:38.106Z caller=dispatch.go:354 level=error component=dispatcher msg="Notify for alerts failed" num_alerts=1 err="gmail/email[0]: notify retry canceled after 4 attempts: establish connection to server: dial tcp: i/o timeout"
2022-05-17T11:30:38.107049546Z ts=2022-05-17T11:30:38.106Z caller=dispatch.go:354 level=error component=dispatcher msg="Notify for alerts failed" num_alerts=1 err="gmail/email[0]: notify retry canceled after 4 attempts: establish connection to server: dial tcp: i/o timeout"
2022-05-17T11:30:40.062397446Z ts=2022-05-17T11:30:40.062Z caller=notify.go:732 level=warn component=dispatcher receiver=gmail integration=email[0] msg="Notify attempt failed, will retry later" attempts=1 err="establish connection to server: dial tcp: lookup smtp.gmail.com on 169.254.25.10:53: server misbehaving"
2022-05-17T11:30:40.062444270Z ts=2022-05-17T11:30:40.062Z caller=notify.go:732 level=warn component=dispatcher receiver=gmail integration=email[0] msg="Notify attempt failed, will retry later" attempts=1 err="establish connection to server: dial tcp: lookup smtp.gmail.com on 169.254.25.10:53: server misbehaving"
2022-05-17T11:30:40.062449859Z ts=2022-05-17T11:30:40.062Z caller=notify.go:732 level=warn component=dispatcher receiver=gmail integration=email[0] msg="Notify attempt failed, will retry later" attempts=1 err="establish connection to server: dial tcp: lookup smtp.gmail.com on 169.254.25.10:53: server misbehaving"
2022-05-17T11:30:40.062453056Z ts=2022-05-17T11:30:40.062Z caller=notify.go:732 level=warn component=dispatcher receiver=gmail integration=email[0] msg="Notify attempt failed, will retry later" attempts=1 err="establish connection to server: dial tcp: lookup smtp.gmail.com on 169.254.25.10:53: server misbehaving"
2022-05-17T11:30:40.062455661Z ts=2022-05-17T11:30:40.062Z caller=notify.go:732 level=warn component=dispatcher receiver=gmail integration=email[0] msg="Notify attempt failed, will retry later" attempts=1 err="establish connection to server: dial tcp: lookup smtp.gmail.com on 169.254.25.10:53: server misbehaving"
Lúc này mình bị lỗi vì máy chủ mất internet nên nó không thông được tới mail server của gmail . Sau khi check lại kết nối ok thì ko thấy log lỗi nữa.
Kiểm tra hộp thư đến để thấy cảnh báo đã được gửi đến: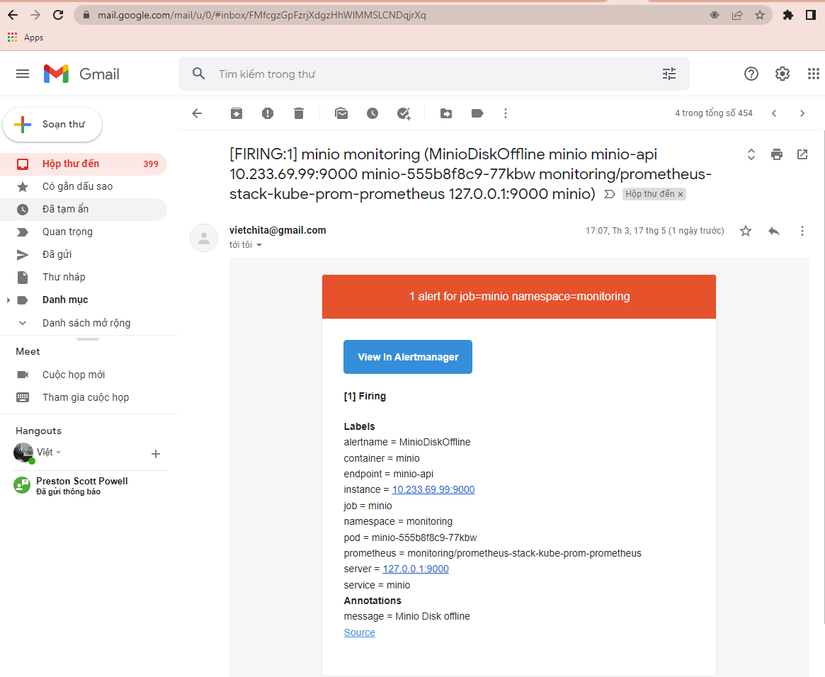
ok như vậy là đã thông luồng cảnh báo rồi. Các bạn có thể tìm hiểu thêm về cách đẩy cảnh báo qua các kênh khác như telegram, msteam.. nói chung nó cũng khá đơn giản không khác qua email là mấy. Chúc các bạn thành công!
Nguồn: viblo.asia