1. Giới thiệu
Trong lĩnh vực thị giác máy tính bài toán về nhận diện vật thể – Object Detection đóng vai trò quan trọng vì nó mang lại nhiều ứng dụng to lớn. Nhiều năm trở lại đây, các mạng học sâu đã liên tục ra đời cho bài toán này. Như chúng ta đã biết thì trong các bài toán ML, DL nói chung imbalance problem có ảnh hưởng xấu đến chất lượng mô hình như thế này. Vì thế các vấn đề về sự mất cân bằng – imbalance problem trong bài toán Object Detection nhận được rất nhiều sự quan tâm và nghiên cứu. Trong bài này mình sẽ tổng hợp lại các imblance problem đã được nghiên cứu trong bài toán nhận diện vật thể.
2. Imbalance Problem
Có thể nhóm các loại imbalance problem thành 4 nhóm sau:
- Class imbalance: xảy ra khi có sự mất cân bằng giữa các class cần nhận diện trong bài toàn object detection.
- Scale imbalance: xảy ra khi các vật thể (object) có sự mất cân bằng về các kích thước
- Spatial imbalance: liên quan đến các yếu tố về vị trí của bbox
- Objective imbalance: liên quan đến việc mô hình phải tối ưu nhiều hàm loss (cụ thể classification và regression loss)
Dưới đây là pineline của một mạng detection cơ bản và các loại imbalance problem kể trên có thể xảy ra ở các phase nào.
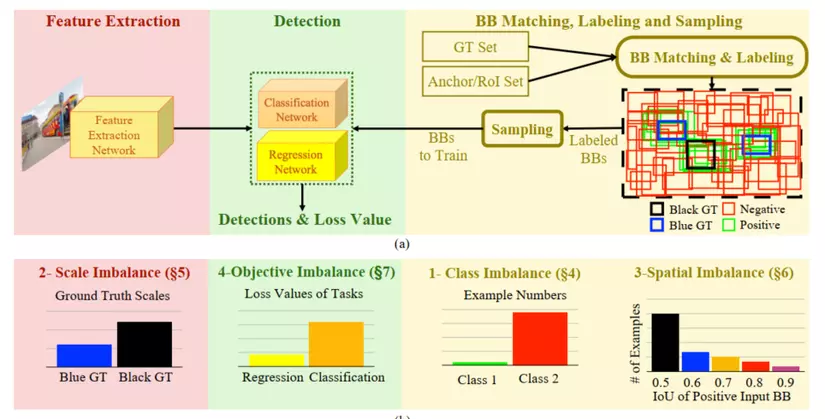
Tiếp theo ta sẽ cùng đi vào tìm hiểu từng cụ thể hơn từng loại Imbalance Problem trong bài toán Object Detection!
2.1. Class Imbalance
Foreground-Background class imbalance
Một số định nghĩa:
- Over-represented class: là class mà xuất hiện quá trình nhiều bộ dữ liệu hoặc trong các minibatch ở quá trình training
- Under-represented class: ngược lại, là class xuất hiện quá ít trong bộ dữ liệu hoặc trong các minibatch ở quá trình training
- Foreground class: IoU của anchor với ground-truth bounding box mà cho kết quả lớn hơn 1 ngưỡng thì coi đó là foreground class. Đây sẽ là vùng mang nhiều thông tin nhưng mà tần suất xuất hiện trong ảnh sẽ ít.
- Background class: ngược lại nếu IoU của anchor với ground-truth bounding box mà nhỏ hơn ngưỡng thì gọi đó là background class. Vùng này xuất hiện rất nhiều và mang những thông tin không quan trọng, vô nghĩa.
Như vậy, foreground-background class imbalance là khi foreground class là under-represented class còn background class là over-represented class. Nhìn chung, vấn đề này là không thể tránh khỏi vì hầu hết bounding box sẽ được đánh dấu là background.
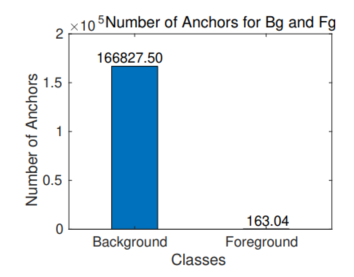
Solution
Vấn đề này nhận được nhiều sự quan tâm vì thế đã có nhiều nghiên cứu về giải pháp được đề xuất và có thể chia thành các nhóm:
- Hard sampling methods: Đơn giản nhất là random sampling đã được sử dụng trong R-CNN, là phương pháp phổ biến được dùng giúp loại bỏ imbalance problem. Cụ thể trong một tập các bounding box thì ta sẽ chọn ra các tập nhỏ positive example và negative example với số lượng bằng nhau và sử dụng để cho quá trình training. Khi đó đóng góp vào hàm loss của các positive và negative example là như nhau. Tiếp theo là các phương pháp hard-example mining methods lựa chọn ra các hard example (các case khó với giá trị loss cao) để training (SSD có áp dụng phương pháp này).
- Soft sampling methods: Thay vì chọn xem nên lấy hay loại như Hard sampling methods thì phương pháp này đặt hệ số cho foreground và background class. Thông thường thì các background class sẽ có hệ số nhỏ hơn và do đó đóng góp ít hơn vào hàm loss. Các giá trị trọng số này cũng được đặt theo nhiều tiêu chí khác nhau. YOLO có sử dụng phương pháp này.
- Generative methods: Thay vì phải lựa chọn các hard example thì phương pháp này ứng dụng các mô hình sinh như GAN để sinh ra các hard example. Ngoài ra, có thể tạo ra các ảnh mới bằng các phương pháp augmentation.
Foreground-Foreground class imbalance
Theo định nghĩa trong trường hợp này thì cả over-represented class và under-represented class đều là foreground class. Ví dụ như bài toán nhận diện các không đeo khẩu trang (class 0), người đeo khẩu trang (class 1) và đeo khẩu trang không đúng cách (class 2) trong challange của Datacomp thì class 1 có số lượng rất lớn trong khi class 2 thì rất ít. Cụ thể hơn thì foreground-foreground class imbalance được chia thành 2 mức: dataset-level và batch-level
-
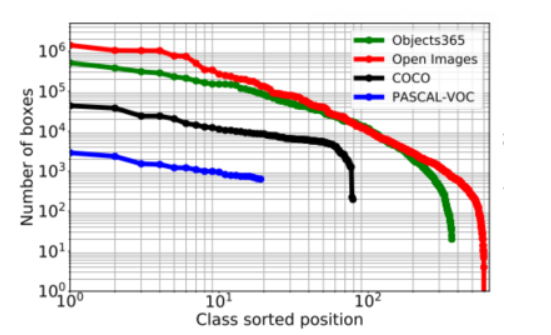
Dataset-level: trong tự nhiên, các object sẽ xuất hiện với tuần suất khác nhau vì vậy sự mất cân bằng giữa các class trong dataset là không tránh khỏi. Hình dưới là thông kế số lượng các object class trên các tập dataset khác nhau. Như vậy có thể thấy rằng hiện tượng overfit đối với các over-represented class là khó tránh khỏi.

-
Batch-level: trong quá trình training thì phân phối các object class trong 1 batch có thể không đồng đều, đặc biệt khi kích thước của batch nhỏ. Trong trường hợp này, một over-represented class ở dataset-level cũng có thể trở thành under-represented level khi trong 1 batch. Kể cả khi các class ở dataset có phân phối đồng đều thì hiện tượng này vẫn xảy ra trong quá trình training. Như hình dưới a) là phân phối của class person và parking meter trong dataset nhưng khi trong một batch thì trường hợp như b) có thể xảy ra.


Solution
- Đối với dataset-level có thể áp dụng các mô hình sinh để tạo ra ảnh mới hoặc bounding box mới, ngoài ra cũng có thể tập trung augment thêm các under-represented class.
- Đối với batch-level có một phương pháp là Online foreground balanced (OFB) sampling sẽ chọn các bounding box cho 1 batch theo xác suất sao cho phân phối của các class trong một batch là uniform.
- Một số cách khác là sử dụng phương pháp under-sampling cho các over-represented class, over-sampling cho các under-represented class hoặc là dùng 1 hàm loss riêng để giải quyết vấn đề mất cân bằng giữa các foreground class.
2.2. Scale Imbalance
Object/Box-Level Scale Imbalance
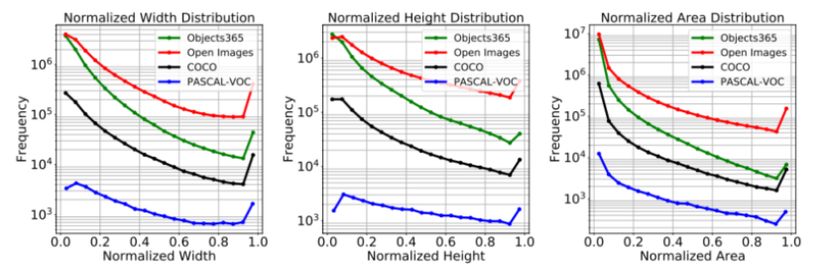
Vấn đề này được định nghĩa là là các object hay các ground-truth bounding boxes trong dataset có các kích thước khác nhau, trong đó một vài kích thước rơi vào trường hợp over-represented. Hình dưới đã thể hiện sự mất cân bằng về chiều cao, chiều rộng và diện tích của object trong các bộ dataset khác nhau.
Solution
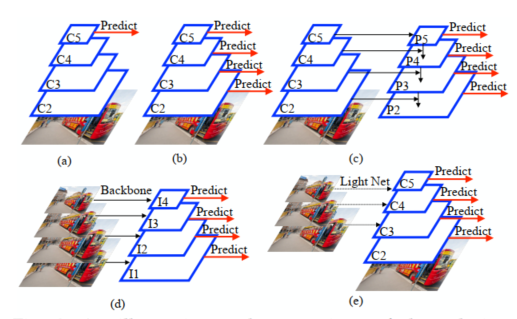
Có thể giải quyết bằng việc sử dụng các feature tại các “level” khác nhau để dự đoán. Cụ thể như hình dưới a) là chỉ dự đoán bằng feature cuối cùng của backbone (chưa áp dụng phương pháp để giải quyết hiện tượng trên). Hình b) thì sử dụng feature ở các level khác nhau để dự đoán. Hình c) kết hợp các feature tại các level khác nhau để dự đoán. Hình d) và e)cho các ảnh với độ phân giải khác nhau để thu được các feature khác nhau và dùng chúng để dự đoán. Trừ hình a) thì các hình còn lại đều giúp giảm thiểu ảnh hưởng của scale imbalance problem.
Feature-level Imbalance
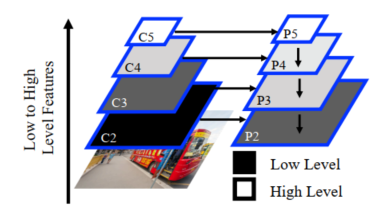
Khi áp dụng các phương pháp để giảm thiểu ảnh hưởng của Object/Box-Level Scale Imbalance đặc biêt là phương pháp kết hợp các feature tại các level khác nhau và dùng chúng để dự đoán vô tình gây ra hiện tượng feature-level imbalance. Cụ thể như hình dưới màu sắc thể hiện sự tương ứng của các feature với nhau, cặp C5 – P5, C4 – P4 thì có vẻ khá phù hợp với nhau tuy nhiên cặp C2 – P2 và C3 – P3 thì lại có sự khác biệt về feature-level và gây ra hiện tượng kể trên.
Solution
Có khá nhiều phương pháp được đề xuất để giải quyết hiện tượng này. Tuy nhiên có lẽ mình sẽ tìm hiểu vào bài viết, vì nó có nhiều phương pháp khá dài và mình chưa đọc kĩ ^^! Vì thế mình sẽ chỉ liệt kê các phương pháp ra: PANet, Libra FPN, Parallel-FPN, Zoom Out and In, Mutil-level FPN, NAS-FPN.
2.3. Spatial Imbalance
Imbalance in Regression Loss
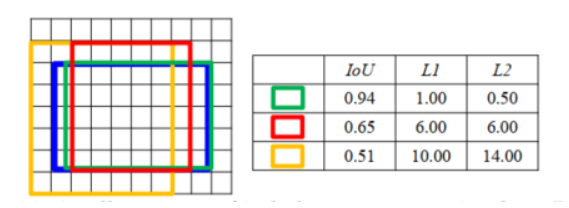
Regression loss liên quan đến việc mô hình tìm ra bounding box gần với ground truth nhất, tuy nhiên mỗi bouding box mà mô hình dự đoán trong quá trình train lại đóng góp khác nhau cho hàm loss. Ví dụ như hình dưới, màu xanh lam là ground truth, ba màu còn lai là bounding boxes được dự đoán. L1 và L2 là các regression loss, có thể thấy rằng đóng góp đến hàm loss L2 của bounding box màu vàng là lớn hơn so với L1, ngược lại của bounding box màu xanh lá thì lại nhỏ hơn.
Solution
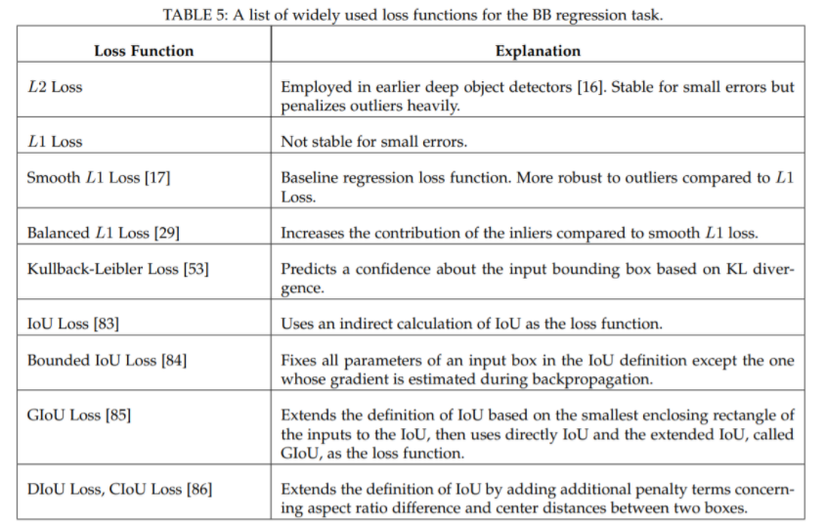
Đã có nhiều hàm regression loss ra đời để khắc phục có thể kể đến như: Smooth L1 Loss, Balanced L1 Loss, KL Loss hay các loss dùng thẳng giá trị IoU để tính như IoU Loss, Bounded IoU Loss, GIoU Loss, DIoU Loss và CIoU Loss. Dưới đây là bảng tổng hợp một số regression loss
Object Location Imbalance
Phân phối về vị trí của vật thể trong các ảnh không đồng đều cũng được coi là một imbalance problem. Hầu hếu các mô hình nhận diện vật thể đều dùng các anchor như là các cửa sổ trượt (sliding window) và các anchor này sẽ được phân phối đồng đều trên ảnh vì vậy mỗi vị trí của ảnh sẽ có tầm quan trọng như nhau. Tuy nhiên, vị trí của vật thể trong ảnh lại không tuân theo phân phối uniform, ví dụ như hình dưới minh họa vị trí tâm của vật thể trong ảnh của các bộ dữ liệu khác nhau (kích thước ảnh đã được chuẩn hóa)
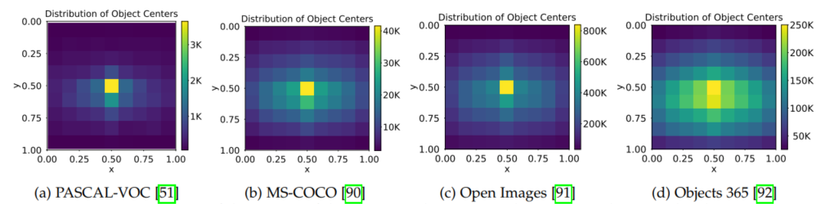
Solution
Dựa vào feature của backbone thì nhánh prediction sẽ được thiết kế và dự đoán các vùng có vật thể từ đó có thể tạo ra các anchor phù hợp về vị trí và kích thước. Có hai phương pháp có thể kể đến là Guided Anchoring và Free Anchor.
2.4. Objective Imbalance
Như tên gọi thì vấn đề này liên quan đến các hàm mục tiêu (hàm loss) được mô hình sử dụng trong quá trình training. Bài toán object detection là sự kết hợp của bài toán phân loại ảnh (image classification) và định vị vật thể (object localization) nên hàm loss của nó cũng phải là multi-task loss. Do đó, điều này có thể dẫn đến việc mất cân bằng giữa các task như sau:
-
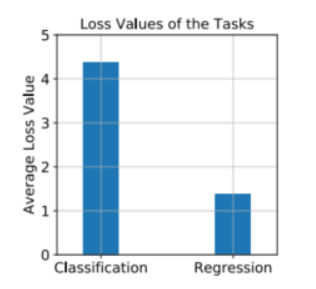
Norm của gradient có thể khác nhau giữa các task. Ví dụ như hình thì loss của task classification đang chiếm ưu thế hơn loss của task regression

-
Khoảng giá trị của hàm loss của mỗi task có thể khác nhau khiến cho việc tối ưu các hàm loss cũng khó khăn hơn.
-
Độ phức tạp của các task cũng khác nhau nên tốc độ học các task của mô hình là khác nhau dẫn đến việc cản trở quá trình training.

Solution
- Áp dụng Task Weighting để cân bằng loss, bằng cách sử dụng các weighting factor cho các loss của các task. Giá trị này có thể xác định bằng các sử dụng các tập val.
- Một cách tiếp cận nữa là kết hợp task classification và regression (Classification-Aware Regression Loss – CARL)
3. Kết luận
Khi tham gia challenge về nhận diện người đeo khẩu trang mình đã gặp phải vấn đề là bộ dữ liệu rơi vào trường hợp Foreground-Foreground class imbalance ở dataset-level. Tuy nhiên, mình đã dành thời gian để tìm hiểu thêm các imbalance problem liên quan đến bài toán object detection và tổng hợp lại thành một bài viết. Nội dung mình tham khảo chủ yếu từ paper Imbalance Problems in Object Detection: A
Review.
Nguồn: viblo.asia