
Auto Scaling Pod là gì?
Auto scaling pod là quá trình thực hiện tăng số lượng pod trong 1 node lên một số lượng đã được định sẵn hoặc không (mở rộng theo chiều ngang). Quá trình này được thực hiện khi xảy ra một hoặc nhiều sự kiện, ví dụ như: CPU đạt trên 70%, số lượng request đến server lớn hơn 500 req/s,…
Auto Scaling để làm gì?
Auto Scaling sẽ giúp ứng dụng tăng tài nguyên và từ đó sẽ giúp đáp ứng được nhiều yêu cầu từ client hơn, tránh gây ra quá tải, downtime cho application.
Sử dụng Horizontal Pod Autoscale (HPA) trong K8s
Horizontal pod autoscale được cài đặt sẵn ở trong cụm K8s có thể được sử dụng để scale up/down pod cho các đối tượng ReplicaSet hoặc Deployment.
Điều kiện tiên quyết
Dù HPA được cài đặt mặc định sẵn trong K8s tuy nhiên để có thể lấy được thông tin cho việc giám sát (CPU, Memory) thì phải cài đặt thêm metrics server tại đường dẫn:
https://github.com/kubernetes-sigs/metrics-server
HPA hoạt động thế nào?
Mỗi HPA sẽ có một điều kiện riêng để kiểm tra, nếu điều kiện đó (CPU > 70%) đạt thì sẽ tiến hành scale up và khi điều kiện không còn thỏa mãn sẽ scale down. Số pod sẽ được scale gấp đôi liên tục, ví dụ nếu đang có 3 pod chạy thì sẽ được scale lên 6 rồi 12 cho đến khi nào điều kiện không còn thỏa mãn (CPU < 70%) thì ngừng scale hoặc đến khi đạt giới hạn số pod được tạo trong node.
Số pod cần thiết sẽ được tính bằng công thức:
Hay số pod cần thiết sẽ bằng làm tròn lên của số pod hiện tại nhân với tỉ lệ của giá trị điều kiện hiện tại và giá trị điều kiện mong đợi.
Ví dụ: số pod hiện tại là 3, mức điều kiện để scale up là CPU > 50%, mức điều kiện hiện tại là 170%
=> 3 x (170/50) = 10,2 làm tròn lên 11 => số pod cần thiết là 11
- Mặc định cứ mỗi 15s HPA sẽ lấy thông tin từ metric server để so sánh điều kiện, thời gian lấy thông tin được xác định bởi tham số –horizontal-pod-autoscaler-sync-period.
- Nếu giá trị currentMetricValue / desiredMetricValue nhỏ hơn 1 hoặc gần bằng 1 (chênh lệch không đáng kể) thì bỏ qua tiếp tục lắng nghe từ metric server, giá trị không đáng kể này được xác định bằng tham số –horizontal-pod-autoscaler-tolerance.
- Nếu giá trị nhỏ hơn 1 thì sẽ mặc định tiếp tục lắng nghe trong 300s, nếu thông số vẫn nhỏ hơn 1 thì sẽ tiến hành scale down từ từ. Giá trị thời gian tiếp tục lắng nghe được xác định bởi tham số –horizontal-pod-autoscaler-downscale-stabilization.
Các thông số mặc định trên có thể thay đổi bằng trường behavior trong file yaml để tạo HPA.
Tham khảo thêm tại document chính thức.
Bài viết hướng dẫn trường behavior chi tiết
behavior:
scaleDown:
policies:
- type: Pods
value: 4
periodSeconds: 60
- type: Percent
value: 10
periodSeconds: 60
Tạo HPA
- Tạo bằng command line kubectl
kubectl autoscale deployment http-app --cpu-percent=70 --min=1 --max=10
Câu lệnh trên tạo HPA cho đối tượng Deployment http-app với điều kiện khi CPU > 70% và số pod có thể tăng giảm từ 1 đến 10 pod.
- Tạo HPA bằng file Yaml
Đầu tiên ta cần tạo 1 file auto-scale.yml và lưu nội dung như sau vào file
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: http-app
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: appdeploy
minReplicas: 1
maxReplicas: 10
targetCPUUtilizationPercentage: 70
Sau đó chạy file với kubectl để tạo HPA:
kubectl apply -f auto-scale.yml
Sử dụng command để kiểm tra HPA đã được tạo thành công hay chưa
kubectl get hpa
Ưu điểm:
- Được tích hợp sẵn nên tối ưu nhất cho các thành phần K8s.
- Thực hiện scale nhanh chóng.
Nhược điểm:
- Chỉ hỗ trợ 1 vài metric cơ bản (cpu, ram,..).
Sử dụng KEDA để auto scale pod K8s
KEDA (https://keda.sh/) có nghĩa là Kubernetes-based Event Driven Autoscaler, KEDA giúp scale ứng dụng chúng ta theo những sự kiện cấu hình trước. KEDA thì khá nhẹ và cài đặt cũng rất dễ dàng chỉ với 1-2 command
KEDA hoạt động thế nào?
KEDA sẽ hoạt động với vai trò như một Metric Server biên dịch các metric nhận được từ external server về cấu trúc mà HPA có thể hiểu được để tiến hành Scale thông qua HPA. Như vậy khi sử dụng KEDA thì ta sẽ không cần phải cài thêm metrics server từ K8s như bên trên.
Với KEDA ta có 1 khái niệm ScaledObject, khi tạo ScaleObject nó cũng sẽ tự tạo thêm 1 HPA để thực hiện việc scale pod.
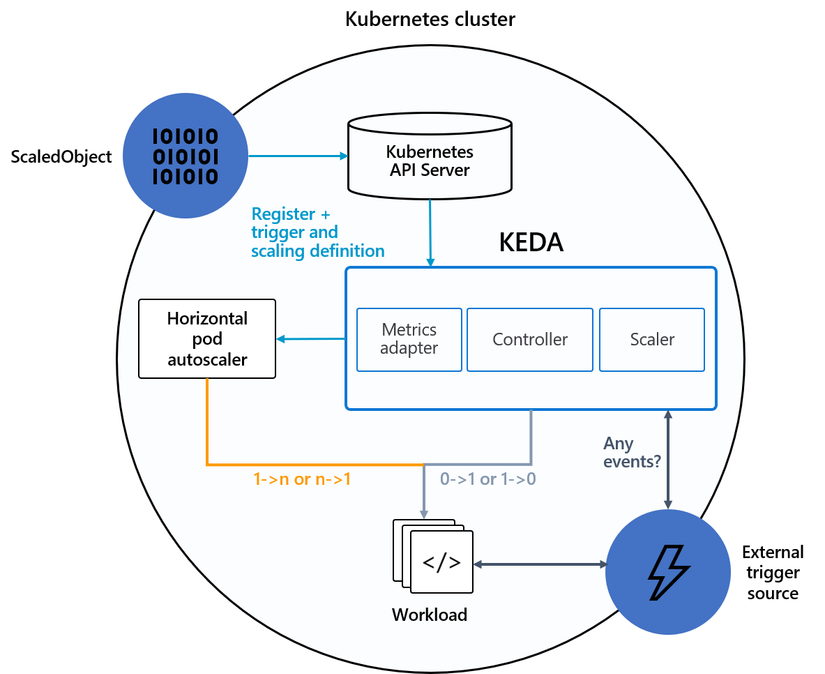
KEDA lấy metric từ đâu?
KEDA hỗ trợ rất nhiều nguồn để có thể lấy dữ liệu tạo ra các event tùy chỉnh (MySQL, Prometheus,…), xem tất cả nguồn hỗ trợ và document cho từng nguồn tại đây.
Cài đặt KEDA
Cài đặt bằng Helm
helm repo add kedacore https://kedacore.github.io/charts
helm repo update
kubectl create namespace keda
helm install keda kedacore/keda --namespace keda
Cài đặt bằng Yaml file
kubectl apply -f https://github.com/kedacore/keda/releases/download/v2.4.0/keda-2.4.0.yaml
Tạo Scaled Object
Ở phần này mình sẽ tạo một ScaleObject để lấy metric từ Prometheus và tạo ra sự kiện. Đầu tiên tạo file yaml scaleObject.yml với nội dung
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: prometheus-scale
namespace: default
spec:
scaleTargetRef:
name: appdeploy (1)
minReplicaCount: 3 (2)
maxReplicaCount: 10 (3)
triggers:
- type: prometheus (4)
metadata:
serverAddress: http://103.56.156.199:9090/ (5)
metricName: total_http_request (6)
threshold: '60' (7)
query: sum(irate(by_path_counter_total{}[60s])) (8)
Giải thích:
- Tên của Deployment muốn scale
- Số lượng pod nhỏ nhất
- Số lượng pod lớn nhất
- Kiểu external Server
- Địa chỉ external Server
- Tên metric
- Giá trị sẽ gọi event (ở đây nếu số req/s > 60 )
- Câu query lấy dữ liệu từ external Server
Chạy câu lệnh để tạo đối tượng ScaledObject:
kubectl apply -f scaledObject.yml
Sau khi tạo xong ta sẽ có đối tượng như hình:


Ưu điểm:
- Hỗ trợ nhiều loại metrics khác nhau
Nhược điểm:
- Sẽ tốn thêm 1 phần tài nguyên để chạy các thành phần của KEDA
Nguồn: viblo.asia