Ở bài trước, chúng ta đã tìm hiểu về một mô hình thời gian liên tục sử dụng SDE. Nếu chúng ta bỏ đi hệ số diffusion, phương trình này sẽ trở thành phương trình vi phân toàn phần theo thời gian tt. Lúc này, việc thay đổi trạng thái sẽ trở nên tất định, do đó chúng ta có thể mô hình sự thay đổi của xác suất trạng thái theo thời gian, từ đó có thể mô hình một phiên bản tương tự của normalizing flow theo thời gian liên tục. Không chỉ vậy, cách làm này còn có thể sử dụng tương tự ResNet với kiến trúc bất kì.
ResNet và phương trình vi phân
Một mô hình ResNet về cơ bản có dạng sau
yt=yt−1+ft−1(yt−1)y_t=y_{t-1}+f_{t-1}(y_{t-1})
với t∈{1,2,…,T}tin{1,2,…,T}, yt,fty_{t}, f_{t} là đầu vào và biến đổi ở lớp thứ tt.
Nếu chúng ta coi tt là chuỗi số thực {t1,t2,…,tT}{t_1, t_2, …, t_T}, chúng ta có thể viết lại thành
yti=yti−1+(ti−ti−1)fti−1(yti−1).y_{t_i}=y_{t_{i-1}}+(t_i-t_{i-1})f_{t_{i-1}}(y_{t_{i-1}}).
Đây chính là cách xấp xỉ một phương trình vi phân bằng phương pháp Euler. Cụ thể hơn, khi T→∞Ttoinfty, cách làm này xấp xỉ phương trình sau
dytdt=f(t,yt)frac{dy_t}{dt}=f(t, y_t)
Từ góc nhìn này, ta có thể xem mạng neural như một quá trình thay đổi của một trạng thái yty_t theo thời gian, biểu diễn bởi phương trình vi phân (ordinary differential equation – ODE) như trên thay vì mô hình theo từng lớp như truyền thống. Đầu ra của mô hình sẽ là trạng thái tại thời điểm TT, được tìm bằng cách giải ODE với điều kiện đầu là đầu vào y0y_0. Mô hình này có thể sử dụng để thay thế bất kì mô hình ResNet nào. Hàm ff ở đây có thể là một kiến trúc tùy ý, nhận trạng thái yy và thời gian tt, trả về vector cùng chiều với yy.
Một tính chất quan trọng của ODE là liệu từ phương trình này có thể xác định được yty_t không. Định lý Picard–Lindelöf chỉ ra rằng trong trường hợp ff là Lipschitz theo yy, tồn tại ϵepsilon sao cho y(t)y(t) tồn tại và xác định duy nhất quanh [−ϵ,ϵ][-epsilon, epsilon]. Như vậy, để ODE định nghĩa tốt, chúng ta cần mô hình thỏa mãn tính chất Lipschitz.
Giải ODE
Với ODE với điều kiện đầu y0y_0 bên trên, trạng thái tại thời điểm tt sẽ được tính như sau
yt=y0+∫0tf(τ,yτ)dτy_t = y_0 + int_0^t f(tau, y_tau)dtau
Mục tiêu của chúng ta sẽ là xấp xỉ tích phân trên. Cách đơn giản nhất là phương pháp Euler: Với mỗi chuỗi t0<t1<…<tTt_0<t_1<…<t_T, chúng ta tính lần lượt TT giá trị tại những thời điểm trên như sau:
yi=yi−1+h⋅f(ti−1,yi−1),h=ti−ti−1y_i = y_{i-1} + hcdot f(t_{i-1}, y_{i-1}),quad h=t_i-t_{i-1}
Như đã nói ở trên, cách làm này giống với mô hình ResNet quen thuộc.
def odeint_euler(f, y0, t):
def step(state, t):
y_prev, t_prev = state
dt = t - t_prev
y = y_prev + dt * f(t_prev, y_prev)
return y, t
t_curr = t[0]
y_curr = y0
ys = []
for i in t[1:]:
y_curr, t_curr = step((y_curr, t_curr), i)
ys.append(y_curr)
return torch.stack(ys)
Một cách xấp xỉ phổ biến khác có sai số thấp hơn là phương pháp Runge-Kutta, xấp xỉ sai khác giữa các thời điểm bởi 4 giá trị
yi=yi−1+h6(k1+2k2+2k3+k4)y_i = y_{i-1}+frac{h}{6}(k_1+2k_2+2k_3+k_4)
k1=f(ti−1,yi−1)k2=f(ti−1+h2,yi−1+hk12)k3=f(ti−1+h2,yi−1+hk22)k4=f(ti−1+h,yi−1+hk3)begin{aligned}
k_1 &=f(t_{i-1}, y_{i-1})\
k_2 &=f(t_{i-1}+frac{h}{2}, y_{i-1}+hfrac{k_1}{2})\
k_3 &=f(t_{i-1}+frac{h}{2}, y_{i-1}+hfrac{k_2}{2})\
k_4&=f(t_{i-1}+h, y_{i-1}+hk_3)
end{aligned}
def odeint_rk4(f, y0, t):
def step(state, t):
y_prev, t_prev = state
dt = t - t_prev
k1 = dt * f(t_prev, y_prev)
k2 = dt * f(t_prev + dt/2., y_prev + k1/2.)
k3 = dt * f(t_prev + dt/2., y_prev + k2/2.)
k4 = dt * f(t + dt, y_prev + k3)
y = y_prev + (k1+ 2 * k2 + 2 * k3 + k4) / 6
return y, t
t_curr = t[0]
y_curr = y0
ys = []
for i in t[1:]:
y_curr, t_curr = step((y_curr, t_curr), i)
ys.append(y_curr)
return torch.stack(ys)
Tính thử một ví dụ với ODE sau
dytdt=yt,y0=2frac{dy_t}{dt}=y_t,quad y_0=2
ODE có nghiệm là yt=y0ety_t=y_0e^t. Dùng 100100 bước để xấp xỉ tích phân để tính y10y_{10}, hai cách tính trên cho kết quả như bên dưới
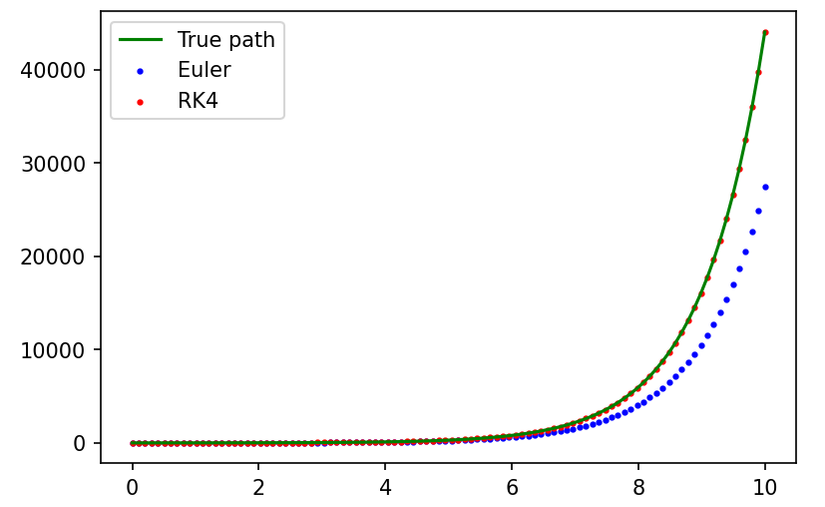
Ta có thể thấy phương pháp Euler cho kết quả không chính xác. Điều này thể hiện khoảng cách giữa các bước ảnh hưởng đến độ chính xác của phương pháp xấp xỉ. Do đó ta có thể xấp xỉ ODE chính xác hơn bằng cách chọn độ dài mỗi bước sao cho ước lượng lỗi tối ưu (việc này yêu cầu một cách để ước lượng lỗi, ví dụ như dùng một phương pháp khác để xấp xỉ, rồi tính sai khác giữa kết quả của hai phương pháp). Tuy nhiên điều này nảy sinh một vấn đề sau: Trong trường hợp ta muốn dùng minibatch, sai số giữa các ODE trong batch là khác nhau, do đó thời gian giữa các ODE sẽ khác nhau, việc xử lý toàn batch sẽ không giống như mạng neural thông thường. Một cách giải quyết là gộp chung toàn batch thành 1 ODE, các mốc thời gian sẽ dùng chung, tuy nhiên có thể tăng sai số. Đối với jax, ta có thể dùng vmap để tính song song các ODE trong batch (gần đây torch cũng có cài đặt vmap).
Cập nhật tham số
Ở bài trước, chúng ta đã làm quen với một mô hình thời gian liên tục với SDE bằng mô hình trực tiếp score theo thời gian. Tuy nhiên, đối với neural ODE, ta đang mô hình sự thay đổi của trạng thái theo thời gian. Do đó việc cập nhật gradient trở nên không hiển nhiên, yêu cầu tham số hóa lại đối với tham số của mô hình.
Phần này sẽ trình bày cách cập nhật gradient cho hai cách cài đặt automatic differentiation là tích vector-Jacobian (VJP) và tích Jacobian-vector (JVP). Chi tiết về hai cách cài đặt này có thể xem ở tài liệu tham khảo của thư viện jax.
Tính với tích vector-Jacobian (reverse mode)
Để cho thuận tiện, chúng ta sẽ viết lại phương trình vi phân dưới dạng sau
∂y(t,y0,θ)∂t=f(t,y(t,y0,θ),θ))frac{partial y(t, y_0, theta)}{partial t} = f(t, y(t, y_0, theta), theta))
Giả sử hàm mục tiêu được tính tại trạng thái cuối yTy_T tại thời điểm yTy_T thông qua hàm L(yT,θ)L(y_T,theta), từ định lí tồn tại duy nhất hàm này cũng có thể được tính từ trạng thái yty_t thông qua hàm Lt(yt,θ)L_t(y_t,theta).
Mục tiêu của chúng ta là đạo hàm đối với trạng thái ban đầu y0y_0 và tham số θtheta, nói cách khác là tính đạo hàm riêng ∂L0(y0,θ)∂y0frac{partial L_0(y_0,theta)}{partial y_0} và ∂L0(y0,θ)∂θfrac{partial L_0(y_0,theta)}{partial theta}.
Đặt
a(t,y0,θ)=∂Lt(yt,θ)∂yt,a(t,y_0,theta) = frac{partial L_t(y_t,theta)}{partial y_t},
chúng ta đã biết a(T,y0,θ)a(T, y_0,theta) và cần tính a(0,y0,θ)a(0,y_0,theta). Như vậy, chúng ta có thể mô hình sự thay đổi ∂a(t,y0,θ)∂tfrac{partial a(t, y_0,theta)}{partial t} của hàm aa theo thời gian tt, từ đó tính ra a(0,y0,θ)a(0,y_0,theta) bằng cách tích phân theo thời gian từ TT về 00.
Do ODE có nghiệm duy nhất xung quanh lân cận của y0y_0, ta có thể lấy đạo hàm riêng theo y0y_0 tại hai vế
∂2y(t,y0,θ)∂y0∂t=∂f(t,y(t,y0,θ),θ))∂y0frac{partial^2 y(t, y_0, theta)}{partial y_0partial t} = frac{partial f(t, y(t, y_0, theta), theta))}{partial y_0}
Đổi thứ tự đạo hàm riêng và áp dụng chain rule ta có
∂2y(t,y0,θ)∂t∂y0=∂f(t,y,θ)∂y∂y(t,y0,θ)∂y0.frac{partial^2 y(t, y_0,theta)}{partial tpartial y_0}=frac{partial f(t, y, theta)}{partial y}frac{partial y(t,y_0,theta)}{partial y_0}.
Quay lại với hàm mục tiêu, áp dụng chain rule ta được
∂L0(y0,θ)∂y0=∂Lt(yt,θ)∂yt∂y(t,y0,θ)∂y0frac{partial L_0(y_0,theta)}{partial y_0} = frac{partial L_t(y_t,theta)}{partial y_t}frac{partial y(t,y_0,theta)}{partial y_0}
Từ hai điều trên, ta có thể mô hình sự thay đổi của a(t,y0,θ)a(t, y_0,theta) theo thời gian như sau
∂a(t,y0,θ)∂t=−a(t,y0,θ)∂f(t,y,θ)∂yfrac{partial a(t,y_0, theta)}{partial t} = – a(t,y_0,theta)frac{partial f(t,y,theta)}{partial y}
Lúc này a(0,y0,θ)a(0, y_0,theta) có thể tính bởi
a(0,y0,θ)=a(T,y0,θ)−∫T0a(t,y0,θ)∂f∂ydta(0, y_0,theta) = a(T,y_0,theta)-int_T^0 a(t,y_0,theta)frac{partial f}{partial y} dt
Để tính a(t,θ)∂f∂ya(t,theta)frac{partial f}{partial y}, chúng ta sẽ dùng vector-Jacobian với đầu vào là yy. Trạng thái này có thể được tính lại bằng ODE ban đầu, hoặc có thể sử dụng lại chính trạng thái đã tính trong quá trình forward nếu sử dụng cũng một cách để xấp xỉ.
Tiếp theo chúng ta sẽ tính đạo hàm riêng với tham số của mô hình, áp dụng chain rule ta được
∂L0(y0,θ)∂θ=∂Lt(yt,θ)∂yt∂yt∂θ+∂Lt(yt,θ)∂θfrac{partial L_0(y_0,theta)}{partial theta} = frac{partial L_t(y_t,theta)}{partial y_t} frac{partial y_t}{partial theta}+frac{partial L_t(y_t,theta)}{partial theta}
Tương tự như trên, nếu chúng ta có thể mô hình được sự thay đổi của b(t,y0,θ)=∂Lt(yt,θ)∂θb(t, y_0,theta)=frac{partial L_t(y_t,theta)}{partial theta} theo thời gian, b(0,y0,θ)=∂L0(y0,θ)∂θb(0,y_0,theta)=frac{partial L_0(y_0,theta)}{partial theta} có thể tính bằng cách tích phân từ trạng thái ∂LT(yT,θ)∂θfrac{partial L_T(y_T,theta)}{partial theta}.
Lấy đạo hàm theo tt ở hai vế, ta có
∂a(t,y0,θ)∂t∂y∂θ+a(t,y0,θ)∂2y∂t∂θ+∂b(t,y0,θ)∂t=0frac{partial a(t, y_0,theta)}{partial t}frac{partial y}{partial theta}+a(t,y_0,theta)frac{partial^2 y}{partial tpartial theta}+frac{partial b(t,y_0,theta)}{partial t} = 0
Tương tự như trạng thái đầu y0y_0, ta có thể giả sử ODE thỏa mãn quanh lân cận của θtheta và lấy đạo hàm theo θtheta ở hai vế, sau đó đổi thứ tự đạo hàm và áp dụng chain rule
∂2y(t,y0,θ)∂t∂θ=∂f(t,y,θ)∂y∂y(t,y0,θ)∂θ+∂f(t,y,θ)∂θ.frac{partial^2 y(t, y_0,theta)}{partial tpartial theta}=frac{partial f(t, y, theta)}{partial y}frac{partial y(t,y_0,theta)}{partial theta} + frac{partial f(t,y,theta)}{partial theta}.
Thay ∂a∂tfrac{partial a}{partial t} và ∂2y∂t∂θfrac{partial^2y}{partial tpartial
theta}, ta được
−a(t,y0,θ)∂f(t,y,θ)∂y∂y(t,y0,θ)∂θ+a(t,y0,θ)(∂f(t,y,θ)∂y∂y(t,y0,θ)∂θ+∂f(t,y,θ)∂θ)+∂b(t,y0,θ)∂t=0-a(t,y_0,theta)frac{partial f(t,y,theta)}{partial y}frac{partial y(t,y_0,theta)}{partial theta}+a(t,y_0,theta)left(frac{partial f(t, y, theta)}{partial y}frac{partial y(t,y_0,theta)}{partial theta} + frac{partial f(t,y,theta)}{partial theta}right)+frac{partial b(t,y_0,theta)}{partial t} = 0
Suy ra
∂b(t,y0,θ)∂t=−a(t,y0,θ)∂f(t,y,θ)∂θ.frac{partial b(t,y_0,theta)}{partial t} = -a(t,y_0,theta)frac{partial f(t,y,theta)}{partial theta}.
Một câu hỏi nữa là giá trị của điều kiện đầu là gì. Chúng ta có thể nhận ra hàm mất mát được tính dựa trên trạng thái cuối yTy_T mà không cần đến tham số của quá trình, do đó b(T,y0,θ)=∂L(yT,θ)∂θ=0b(T,y_0,theta)=frac{partial L(y_T,theta)}{partial theta}=0.
Từ đây ta có thể tính được
∂L0(y0,θ)∂θ=b(0,y0,θ)=−∫T0a(t,y0,θ)∂f(t,y,θ)∂θdt.frac{partial L_0(y_0,theta)}{partial theta}=b(0,y_0,theta)=-int_T^0 a(t,y_0,theta)frac{partial f(t,y,theta)}{partial theta}dt.
Tổng hợp lại, để tìm đạo hàm riêng theo trạng thái ban đầu và tham số của mô hình, ta sẽ giải hệ phương trình vi phân sau
d[ytatbt]=[f(t,y,θ)−at∂f∂y−at∂f∂θ]dtdbegin{bmatrix}
y_t \
a_t \
b_t
end{bmatrix}
=
begin{bmatrix}
f(t,y,theta)\
-a_tfrac{partial f}{partial y}\
-a_tfrac{partial f}{partial theta}
end{bmatrix}dt
với trạng thái ban đầu là
[yTaTbT]=[yTdL(yT)dyT0]begin{bmatrix}
y_T \
a_T \
b_T
end{bmatrix}=begin{bmatrix}
y_T\
frac{d L(y_T)}{d y_T}\
0
end{bmatrix}
Tính với tích Jacobian-vector (forward mode)
Đối với cách cài đặt này, ta quan tâm đến vi phân của yTy_T khi biết vi phân của y0y_0 và θtheta. Ta có
dyt=∂y(t,y0,θ)∂y0dy0+∂y(t,y0,θ)∂θdθdy_t = frac{partial y(t, y_0,theta)}{partial y_0}dy_0 + frac{partial y(t, y_0,theta)}{partial theta}dtheta
với mọi tt (dyt,dy0,dθdy_t, dy_0, dtheta kí hiệu vector tiếp tuyến). Tương tự phần trên, ta nghĩ đến việc tìm sự thay đổi của dytdy_t theo thời gian.
ddtdyt=∂2y(t,y0,θ)∂t∂y0dy0+∂2y(t,y0,θ)∂t∂θdθ.frac{d}{dt}dy_t= frac{partial^2 y(t, y_0,theta)}{partial tpartial y_0}dy_0 + frac{partial^2 y(t, y_0,theta)}{partial tpartial theta}dtheta.
Đặt u(t,y0,θ,dy0)=∂y(t,y0,θ)∂y0dy0,v(t,y0,θ,dθ)=∂y(t,y0,θ)∂θdθu(t, y_0, theta, dy_0)=frac{partial y(t, y_0,theta)}{partial y_0}dy_0, v(t,y_0, theta, dtheta) = frac{partial y(t, y_0,theta)}{partial theta}dtheta. Ở phần trên chúng ta đã có
∂u∂t=∂f∂yufrac{partial u}{partial t}=frac{partial f}{partial y}u
∂v∂t=∂f∂yv+∂f∂θdθfrac{partial v}{partial t}=frac{partial f}{partial y}v + frac{partial f}{partial theta}dtheta
Do đó
∂(u+v)∂t=∂f∂y(u+v)+∂f∂θdθfrac{partial (u+v)}{partial t}=frac{partial f}{partial y}(u+v) + frac{partial f}{partial theta}dtheta
Việc còn lại là tìm điều kiện đầu. Tại thời điểm 00, y=y0y=y_0, do vậy u(0)=dy0,v(0)=0u(0)=dy_0, v(0)=0. Lúc này việc tìm vi phân tại yTy_T tương đương với việc giải ODE
ddtwt=∂f∂ywt+∂f∂θdθfrac{d}{dt}w_t=frac{partial f}{partial y}w_t + frac{partial f}{partial theta}dtheta
với điều kiện đầu w0=dy0w_0=dy_0.
Ghi chú: Với cả hai cách cài đặt, ta đều phải tích phân ngược theo thời gian. Điều này yêu cầu phương pháp xấp xỉ ODE phải thỏa mãn tính chất thời gian khả nghịch, cụ thể hơn khi giải ODE theo chiều thuận rồi từ đó giải theo chiều nghịch, ta được chính xác điều kiện đầu. Các phương pháp giải ODE bậc nhất (bao gồm phương pháp Euler, Runge-Kutta) không thoả mãn tính chất này.
Ví dụ
Trong phần này mình sẽ minh họa với pytorch, sử dụng hàm vjp và jvp. Hai hàm này nhận vào một hàm bất kì có đầu vào và đầu ra là tensor, rồi tính VJP/JVP tại đầu vào theo một vector tiếp tuyến nào đó.
Đối với VJP/JVP theo tham số của mô hình, chúng ta có thể xóa attribute rồi đặt lại để đưa tham số vào đối số của hàm forward, xem cụ thể tại đây
def del_attr(obj, names):
if len(names) == 1:
delattr(obj, names[0])
else:
del_attr(getattr(obj, names[0]), names[1:])
def set_attr(obj, names, val):
if len(names) == 1:
setattr(obj, names[0], val)
else:
set_attr(getattr(obj, names[0]), names[1:], val)
def make_functional(mod):
orig_params = tuple(mod.parameters())
names = []
for name, p in list(mod.named_parameters()):
del_attr(mod, name.split("."))
names.append(name)
return orig_params, names
def load_weights(mod, names, *params):
for name, p in zip(names, params):
set_attr(mod, name.split("."), p)
def del_weights(mod):
for name, p in list(mod.named_parameters()):
del_attr(mod, name.split("."))
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.module = nn.Sequential(nn.Linear(4, 5), nn.LeakyReLU(), nn.Linear(5,3),nn.Tanh())
def get_params(self):
self.params, self.names = make_functional(self)
def forward(self, t, state, *args):
if len(args) == 0:
load_weights(self, self.names, *self.params)
elif len(args) > 0:
del_weights(self)
load_weights(self, self.names, *args)
return self.module(torch.cat([t.view(1), state]))
model = Model()
model.get_params()
Khi tính JVP/VJP, chúng ta cần giải hệ ODE, do đó thuật toán cần được chỉnh sửa một chút
def odeint_rk4_system(f, y0, t):
"""
y0 : list of states
f : func returns list of states
"""
def step(state, t):
y_prev, t_prev = state
dt = t - t_prev
k1 = [dt * i for i in f(t_prev, y_prev)]
k2 = [dt * i for i in f(t_prev + dt/2., [y + j1/2. for y, j1 in zip(y_prev, k1)])]
k3 = [dt * i for i in f(t_prev + dt/2., [y + j2/2. for y, j2 in zip(y_prev, k2)])]
k4 = [dt * i for i in f(t + dt, [y + j3 for y, j3 in zip(y_prev, k3)])]
y = [i + (j1+ 2 * j2 + 2 * j3 + j4) / 6 for i, j1, j2, j3, j4 in zip(y_prev, k1, k2, k3, k4)]
return y, t
t_curr = t[0]
y_curr = y0
ys = []
for i in t[1:]:
y_curr, t_curr = step((y_curr, t_curr), i)
ys.append(y_curr)
return ys
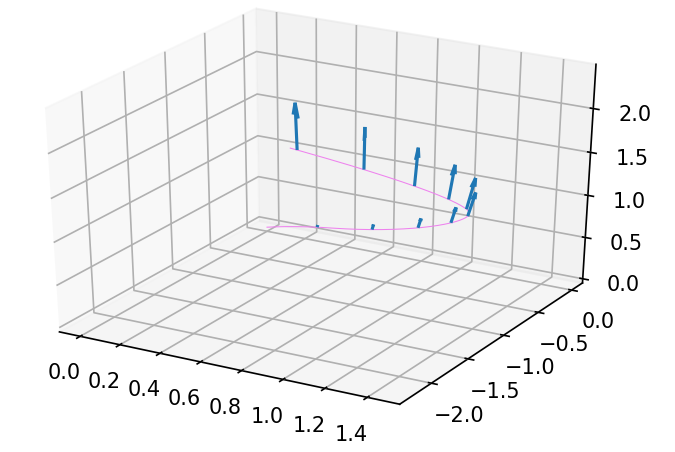
Chúng ta sẽ mô hình đạo hàm theo thời gian của vị trí 1 điểm trong R3mathbb{R}^3 với phương pháp Runge-Kutta bậc 4, được kết quả như hình dưới
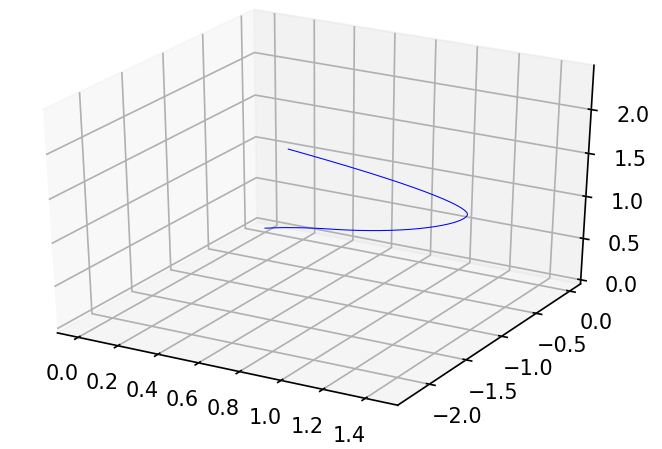
Với vector tiếp tuyến [0,0,1][0, 0, 1] tại điều kiện đầu, pushforward theo thời gian được vector tiếp tuyến tại từng thời điểm như sau
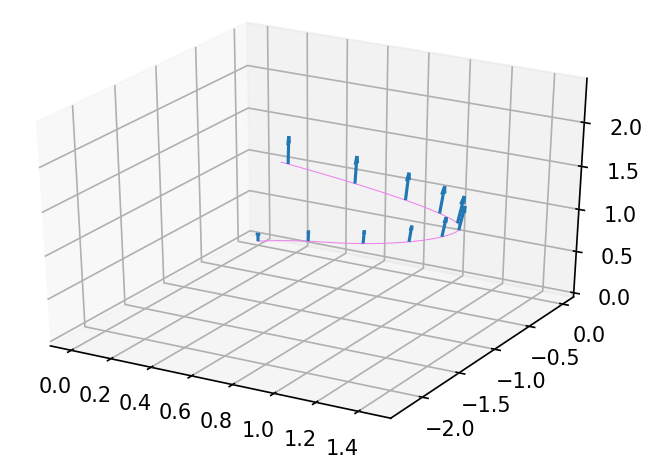
Với vector tiếp tuyến tại TT, chúng ta kéo lùi lại y0y_0 và θtheta. Áp dụng JVP với dy0dy_0 được kết quả như hình
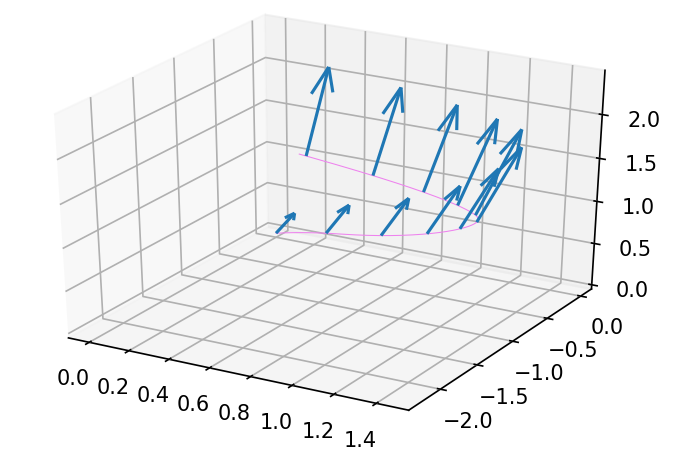
Áp dụng JVP với dθdtheta được kết quả sau
Code sử dụng trong bài có thể xem ở đây.
Trong bài tiếp theo, chúng ta sẽ tìm hiểu về mô hình continuous normalizing flow với neural ODE, và liên hệ với SDE ở bài trước.
Tham khảo
Nguồn: viblo.asia