I. Bài toán Tìm kiếm nhị phân tổng quát
Ở bài viết trước, mình đã giới thiệu tới các bạn những khái niệm cơ bản nhất về bài toán tìm kiếm trong Tin học, cũng như giới thiệu về hai giải thuật Tìm kiếm tuần tự và Tìm kiếm nhị phân. Trong bài viết này, mình sẽ tập trung nói về giải thuật Tìm kiếm nhị phân, nhưng sẽ là áp dụng trong một lớp bài toán tổng quát hơn rất nhiều.
Ứng dụng trong việc tìm kiếm một khóa trên tập cho trước chỉ là một ứng dụng cơ bản của giải thuật Tìm kiếm nhị phân. Trên thực tế, Tìm kiếm nhị phân có thể được mở rộng để áp dụng cho một lớp bài toán tổng quát hơn nhiều, cụ thể là tìm kiếm kết quả trên một hàm số đơn điệu nhận tham số đầu vào là một số nguyên. Hàm số đơn điệu hiểu đơn giản là một hàm tăng hoặc hàm giảm, ví dụ như dãy số đã sắp xếp tăng dần trong bài toán cơ bản có thể coi là một hàm tăng.
Về bản chất, giải thuật Tìm kiếm nhị phân là một giải thuật phát triển từ thiết kế giải thuật Giảm để trị (Decrease and Conquer), nghĩa là tìm cách thu hẹp khoảng cách tìm kiếm lại ở mỗi bước, cho tới khi hai đầu mút của khoảng tìm kiếm chạm vào nhau, thì điểm chạm đó chính là kết quả bài toán. Còn nếu hai đầu mút không thể chạm vào nhau, nghĩa là kết quả bài toán không tồn tại.
Mặt khác, trong bài toán tìm kiếm nhị phân, kết quả bài toán đó thường phải thỏa mãn một tập điều kiện CC. Điều này dẫn đến việc cần phải xây dựng một hàm kiểm tra P:S→true,P:S rightarrow text{true}, với SS là không gian tìm kiếm chứa các ứng cử viên cho kết quả bài toán, còn hàm PP sẽ nhận vào một ứng cử viên x∈Sx in S và trả về giá trị true, falsetext{true, false} cho biết ứng cử viên đó có đáp ứng tập điều kiện CC hay không? Chẳng hạn, trong bài toán tìm kiếm nhị phân cơ bản (xem lại bài viết trước), thì đề bài có thể được viết lại thành: “Tìm chỉ số nhỏ nhất sao cho phần tử ở chỉ số đó có khóa lớn hơn hoặc bằng k?k?“. Khi đó, không gian tìm kiếm SS ban đầu sẽ bao gồm các giá trị [1,2,…,n][1, 2,…, n] (mọi chỉ số của mảng), và hàm P(x)=(boolean)(ax.key≥k)P(x) = text{(boolean)}(a_x.key ge k) trả về truetext{true} nếu ax.key≥ka_x.key ge k và trả về falsetext{false} nếu ax.key<ka_x.key < k.
II. Điều kiện áp dụng giải thuật Tìm kiếm nhị phân
1. Định lý chính (Main Theorem) của Tìm kiếm nhị phân
Khi các bạn bắt đầu giải một bài toán và dự đoán rằng nó có thể giải quyết bằng Tìm kiếm nhị phân, thì việc chứng minh tính đúng đắn của dự đoán đó là rất cần thiết. Rất may mắn, chúng ta có một định lý cho biết khi nào một bài toán có thể áp dụng Tìm kiếm nhị phân, đó là Định lý chính (Main Theorem).
Định lý chính cho biết rằng: Một bài toán với không gian chứa các ứng cử viên là SS chỉ có thể áp dụng Tìm kiếm nhị phân nếu và chỉ nếu hàm kiểm tra PP của bài toán thỏa mãn:
{∀x,y∈S ∣ y>x ∧ P(x)=true}⇒P(y)=true (1){forall x, y in S | y > x wedge P(x) = text{true}} Rightarrow P(y) = text{true} (1)
Điều này cũng tương đương với tính chất:
{∀x,y∈S ∣ y<x ∧ P(x)=false}⇒P(y)=false (2){forall x, y in S | y < x wedge P(x) = text{false}} Rightarrow P(y) = text{false} (2)
Dễ thấy, nếu ta xây dựng hàm P(x)P(x) cho mọi phần tử x∈S,x in S, thì ta sẽ thu được một dãy liên tiếp các giá trị falsetext{false} liền kề với một dãy liên tiếp các giá trị falsetext{false}. Ngoài ra, chỉ cần điều chỉnh hàm PP theo hướng ngược lại, các bạn cũng sẽ xây dựng được định lý chính tạo ra hàm P(x)P(x) là một dãy gồm toàn giá trị truetext{true} ở phía trước, theo sau là một dãy gồm toàn giá trị falsetext{false}. Tuy nhiên ở đây mình chỉ viết một trường hợp để tránh dài dòng.
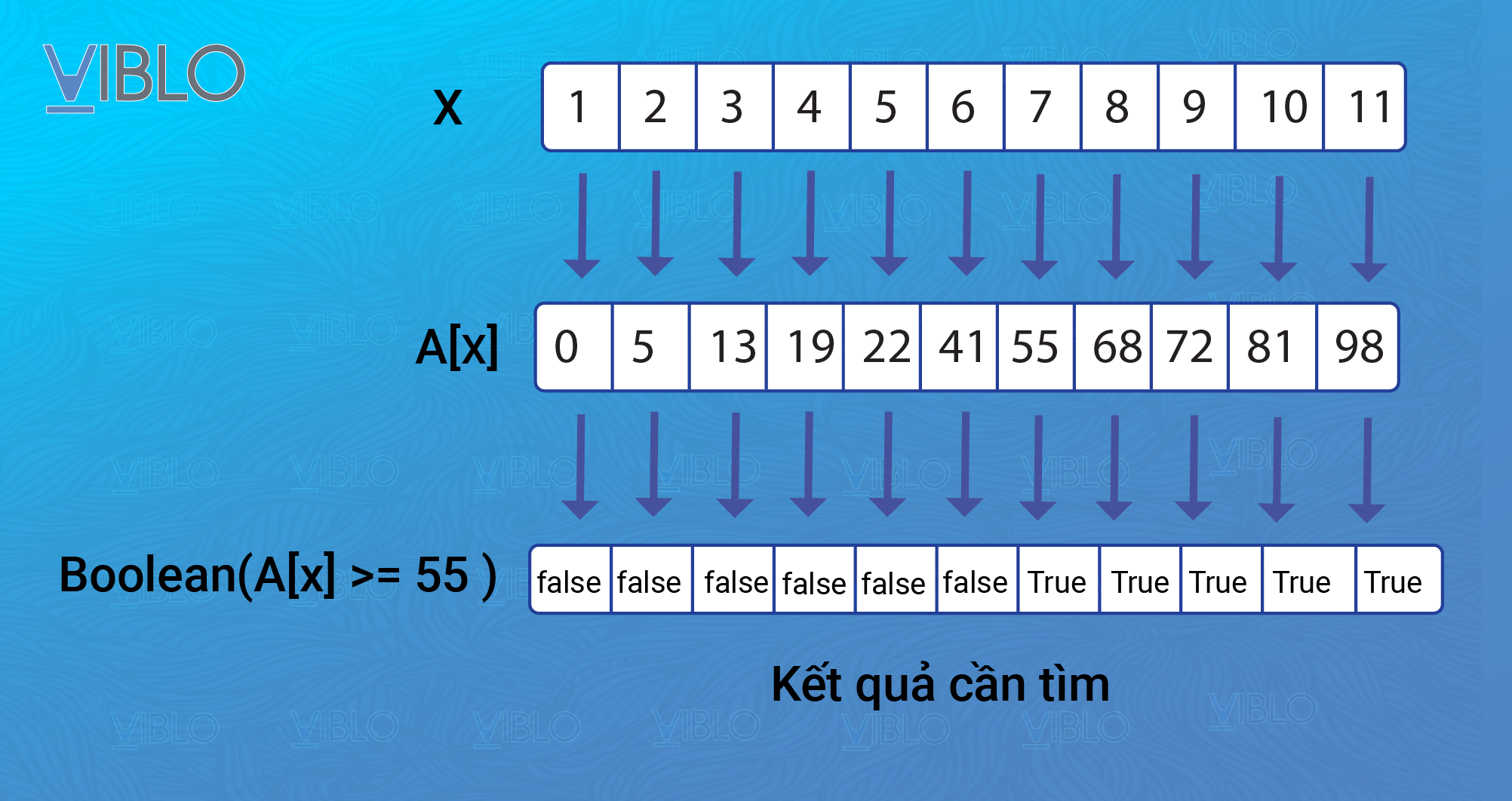
Minh họa việc xây dựng hàm P(x)P(x) cho bài toán xác định vị trí của phần tử k=55k = 55 trong mảng bằng tìm kiếm nhị phân
Từ những điều trên, các bạn sẽ xây dựng được một thông tin rất quan trọng, đó là điều kiện cần và đủ để một bài toán có thể giải được bằng tìm kiếm nhị phân. Cùng phân tính hai tính chất của định lý chính để làm rõ điều này:
- Tính chất (1)(1) cho biết: Nếu xx hợp lệ thì mọi phần tử y>xy > x đều hợp lệ. Tính chất này giúp chúng ta loại đi nửa sau của không gian tìm kiếm do đã biết chắc xx là phần tử nhỏ nhất trong nửa sau hợp lệ, ta ghi nhận xx là kết quả tạm thời và tiếp tục tìm xem có phần tử nào ở nửa đầu (nhỏ hơn xx) hợp lệ hay không.
- Tính chất (2)(2) cho biết: Nếu xx không hợp lệ thì mọi phần tử y<xy < x đều không hợp lệ. Tính chất này giúp chúng ta loại đi nửa trước của không gian tìm kiếm do đã biết chắc chúng không hợp lệ, ta chỉ quan tâm những phần tử ở nửa sau (lớn hơn xx) mà ta chưa biết thông tin chúng có hợp lệ hay không.
Vì dãy kiểm tra P(S)P(S) đã là một tập gồm hai đoạn true – falsetext{true – false} liên tiếp nhau, nên áp dụng tìm kiếm nhị phân, các bạn hoàn toàn có thể tìm ra giá trị xx nhỏ nhất thỏa mãn P(x)=true,P(x) = text{true}, hoặc giá trị xx lớn nhất thỏa mãn P(x)=falseP(x) = text{false}. Điều mấu chốt ở đây chỉ còn lại là làm sao xây dựng được một hàm PP hợp lý với điều kiện trong định lý chính.
Như vậy, mình có thể tổng kết dấu hiệu nhận biết các bài toán tìm kiếm nhị phân dạng tổng quát như sau:
- Đề bài yêu cầu tìm kết quả lớn nhất hoặc nhỏ nhất (còn gọi là bài toán tối ưu).
- Giả sử đề bài yêu cầu tìm kết quả lớn nhất thỏa mãn tập điều kiện CC. Nếu như có thể nhận xét được rằng: Chỉ cần tồn tại một kết quả XX thỏa mãn tập điều kiện CC thì mọi kết quả nhỏ hơn XX đều thỏa mãn tập điều kiên C,C, thì kết quả lớn nhất có thể tìm được bằng tìm kiếm nhị phân (áp dụng định lý chính).
- Trong trường hợp đề bài yêu cầu tìm kết quả nhỏ nhất, thì ta xây dựng định lý chính ngược lại.
2. Cài đặt tổng quát
Trước khi cài đặt giải thuật Tìm kiếm nhị phân, các bạn cần phải trả lời những câu hỏi sau:
- Các giá trị P(x)P(x) của hàm kiểm tra PP đã có dạng false – truetext{false – true} (falsetext{false} liên tiếp rồi tới truetext{true}) hoặc ngược lại hay chưa? Cài đặt tổng quát phía dưới sẽ mặc định dãy P(x)P(x) có dạng false – true,text{false – true}, nếu các bạn muốn làm ngược lại thì chỉ cần đảo hàm PP là xong.
- Mục tiêu của các bạn là tìm phần tử xx nhỏ nhất thỏa mãn P(x)=trueP(x) = text{true} hay tìm phần tử xx lớn nhất thỏa mãn P(x)=false?P(x) = text{false}? Mình sẽ trình bày cả hai cách bên dưới.
- Phạm vi tìm kiếm đã đủ rộng hay chưa? Nhiều trường hợp các bạn có thể chọn một phạm vi tìm kiếm thật lớn mà không sợ bị quá thời gian, vì thời gian thực thi của giải thuật chỉ là O(log(n)),Obig(log(n)big), miễn là khoảng tìm kiếm đó chắc chắn chứa nghiệm của bài toán.
- Nếu bài toán có nghiệm, hãy đảm bảo rằng khoảng tìm kiếm [l,r][l, r] phải là một khoảng đóng luôn luôn chứa nghiệm của bài toán (tức là phải tồn tại xx nhỏ nhất thỏa mãn P(x)=trueP(x) = text{true} trong khoảng này).
- Không gian tìm kiếm có chứa số âm hay không? Nếu không gian tìm kiếm có chứa số âm thì việc chọn mid=⌊(l+r)2⌋text{mid} = left lfloor{frac{(l + r)}{2}} right rfloor sẽ gây ra lỗi, mình sẽ giải thích cụ thể bên dưới. Mặc định các cài đặt dưới đây sẽ coi khoảng tìm kiếm ở dạng tổng quát gồm cả các số âm.
Cài đặt 1: Tìm xx nhỏ nhất mà P(x)=trueP(x) = text{true}:
boolP(int x){// Logic của hàm kiểm tra.returntrue;// Thay bằng logic phù hợp với bài toán.}intbinary_searching(int l,int r){// Biến res dùng để lưu nghiệm tối ưu, ban đầu gán nó bằng l - 1, // coi như chưa có nghiệm.int res = l -1;while(l <= r){int mid = l +(r - l)/2;if(P(mid)==true){
res = mid;
r = mid -1;}else
l = mid +1;}// Nếu res = l - 1 giống như ban đầu thì bài toán vô nghiệm.if(res == l -1)return-1;return res;}Cài đặt 2: Tìm xx lớn nhất mà P(x)=falseP(x) = text{false}:
boolP(int x){// Logic của hàm kiểm tra.returntrue;// Thay bằng logic phù hợp với bài toán.}intbinary_searching(int l,int r){// Biến res dùng để lưu nghiệm tối ưu, ban đầu gán nó bằng l - 1, // coi như chưa có nghiệm.int res = l -1;while(l <= r){int mid = l +(r - l)/2;if(P(mid)==false){
res = mid;
l = mid +1;}else
r = mid -1;}// Nếu res = l - 1 giống như ban đầu thì bài toán vô nghiệm.if(res == l -1)return-1;return res;}Bạn đọc có thể sẽ thắc mắc rằng tại sao không đặt mid=⌊(l+r)2⌋text{mid} = left lfloor{frac{(l + r)}{2}} right rfloor như ở giải thuật cơ bản, mà lại đặt mid=l+⌊(r−l)2⌋text{mid} = l + left lfloor{frac{(r – l)}{2}} right rfloor. Lí do là vì, ta luôn muốn kết quả phép chia được làm tròn xuống về gần với cận dưới (chẳng hạn như phần tử ở giữa của đoạn [5,10][5, 10] sẽ là 77 chứ không phải 88). Nếu như trong khoảng tìm kiếm có số âm, thì khi (l+r)<0(l + r) < 0 sẽ dẫn đến kết quả phép chia cho 22 bị làm tròn lên. Tuy nhiên, trong phần lớn trường hợp, việc tìm kiếm chỉ diễn ra trên tập số nguyên không âm nên vấn đề nói trên sẽ không xảy ra.
III. Tìm kiếm nhị phân trên tập số thực
Tìm kiếm nhị phân cũng có thể được áp dụng khi không gian tìm kiếm là một đoạn số thực. Thường thì việc xử lý sẽ đơn giản hơn với số nguyên do ta không phải bận tâm về việc dịch chuyển cận, chỉ cần gán trực tiếp l=midl = mid hoặc r=mid,r = mid, do đối với số thực thì hai cận không bao giờ chạm hẳn vào nhau được.
Đối với số thực, ta sẽ không thể tìm được một kết quả chính xác, mà chỉ thu được kết quả xấp xỉ. Giải pháp ở đây là sử dụng độ chính xác epsilon: Dừng thuật toán khi r−l≤epsr – l le eps (thường epseps rất nhỏ, rơi vào khoảng 10−810^{-8} là an toàn). Phương pháp này thường được sử dụng chủ yếu, đặc biệt trong các bài toán có thời gian ràng buộc chặt.
Cài đặt: Dưới đây là cài đặt tìm xx nhỏ nhất thỏa mãn P(x)=trueP(x) = text{true}:
boolP(double x){// Logic của hàm kiểm tra.returntrue;// Thay bằng logic phù hợp với bài toán.}doublebinary_searching(double l,double r){double eps =1e-8;while(r - l > eps){double mid = l +(r - l)/2;if(P(mid)==false)
r = mid;else
l = mid;}// trung bình cộng lo và hi xấp xỉ ranh giới giữa false và true.return l +(r - l)/2;}IV. Bài toán ví dụ
Nếu như các bạn vẫn còn cảm thấy khó hiểu sau khi đọc xong những lý thuyết dài dòng bên trên, thì hãy cùng nhau đi vào một số bài toán ví dụ để hiểu thêm về cách áp dụng tìm kiếm nhị phân trong bài toán tối ưu nha!
Bài toán 1
Một xưởng gói quà công nghiệp có n (1≤n≤105)n (1 le n le 10^5) món quà khác nhau cần gói. Để giảm thiểu thời gian gói quà, công ty này sử dụng một dây chuyền gồm m (1≤m≤105)m (1 le m le 10^5) máy gói quà tự động, máy thứ ii có thời gian gói là ti (ti≤109,1≤i≤m)t_i (t_i le 10^9, 1≤i≤m). Do thời gian gấp rút, công ty muốn tính toán xem cần tối thiểu bao lâu để nn món quà được gói xong.
Yêu cầu: Hãy tính thời gian tối thiểu để nn món quà được gói xong? Coi rằng mỗi máy gói quà đều có thể gói liên tục, bỏ qua thời gian vận chuyển các món quà.
Ý tưởng:
- Cách làm đơn giản nhất là duyệt qua tất cả các thời gian t≤max(ti),t le text{max}(t_i), kiểm tra xem với thời gian đó thì tổng số món quà gói được bằng bao nhiêu? Nếu tổng số đó lớn hơn hoặc bằng nn thì đáp án chính là tt. Dễ thấy cách làm này có độ phức tạp O(max(ai)×n),O(text{max}(a_i) times n), không thể vượt qua ràng buộc về thời gian.
- Có thể cải tiến dựa trên nhận xét sau: Nếu như trong thời gian TT mà có thể gói được hết nn món quà, thì trong các thời gian lớn hơn TT tất nhiên cũng có thể gói được hết nn món quà (chính là tính chất (1)(1) của định lý chính). Vì thế, chỉ cần quy về tìm kiếm các thời gian trên đoạn [1,T−1][1, T – 1]. Ngược lại, nếu trong thời gian TT không thể gói hết nn món quà, thì cần tìm kiếm kết quả trên đoạn [T+1,max(ti)][T + 1, text{max}(t_i)]. Liên tục lặp lại quá trình chia đôi đoạn tìm kiếm tới khi hai đầu mút chạm vào nhau, ta thu được kết quả tối ưu.
Cài đặt:
#include<bits/stdc++.h>#defineintlonglong#definetask"Mintime."usingnamespace std;constint maxn =1e6+10;int n, m, t[maxn];voidenter(){
cin >> n >> m;for(int i =1; i <= m;++i)
cin >> t[i];}// Kiểm tra xem có thể gói được n món quà trong thời gian time_val không.boolcheck_valid(int time_val){int presents =0;for(int i =1; i <= m;++i)
presents +=(time_val / t[i]);return presents >= n;}voidsolution(){// Tìm kiếm nhị phân thời gian tối ưu.int best_time =0, l =1, r =1e9+10;while(l <= r){int mid =(l + r)>>1;if(check_valid(mid)){
best_time = mid;
r = mid -1;}else
l = mid +1;}
cout << best_time;}main(){
ios_base::sync_with_stdio(false);
cin.tie(0); cout.tie(0);enter();solution();return0;}Bài toán 2
Với một xâu kí tự S,S, ta định nghĩa ∣S∣|S| là độ dài của xâu đó. Các kí tự trong xâu SS được đánh số thứ tự từ 11 theo chiều từ trái qua phải. Xâu tiền tố độ dài kk của S,S, viết tắt là C(S,k)C(S, k) được định nghĩa như sau:
C(S,k)={S1S2…Sk;với k≤∣S∣.S;với k>∣S∣.C(S, k) = begin{cases}S_1S_2…S_k; text{với } k le |S|.\ S; text{với } k > |S|. end{cases}
Cho trước n (1≤n≤105)n (1 le n le 10^5) xâu kí tự S1,S2,…,SnS_1, S_2,…, S_n có tổng độ dài không vượt quá 10610^6. Với một giá trị kk bất kỳ, ta xây dựng tập các xâu T1,T2,…,Tn;T_1, T_2,…, T_n; với Ti=C(Si,k) (1≤i≤n)T_i = C(S_i, k) (1 le i le n).
Yêu cầu: Tìm giá trị kk nhỏ nhất để tập các phần tử T1,T2,…,TnT_1, T_2,…, T_n là đôi một phân biệt?
Ý tưởng: Bài toán này có thể làm bằng quy hoạch động, tuy nhiên ở đây mình vẫn giới thiệu phương pháp tìm kiếm nhị phân để các bạn hiểu rõ hơn cách áp dụng thuật toán. Nhận xét thấy, nếu như với giá trị kk mà các xâu con độ dài kk đều phân biệt, thì các xâu con độ dài lớn hơn kk cũng sẽ phân biệt (tính chất (1)(1) của định lý chính). Vì vậy, đây là một bài toán thỏa mãn tính chất tìm kiếm nhị phân.
Từ đây, ta tìm kiếm nhị phân giá trị kk nhỏ nhất, ứng với mỗi giá trị k,k, duyệt qua nn xâu để tìm ra xâu con độ dài kk của từng xâu và sử dụng map để kiểm tra xem xâu con đó đã xuất hiện hay chưa. Nếu cả nn xâu con đều phân biệt thì có thể giảm kk xuống, ngược lại tăng kk lên.
Cài đặt:
#include<bits/stdc++.h>usingnamespace std;constint maxn =1e5+10;
string s[maxn];int n, maxl;voidenter(){
ios_base::sync_with_stdio(false);
cin.tie(0); cout.tie(0);
cin >> n;for(int i =1; i = n;++i){
cin >> s[i];
s[i]=' '+ s[i];
maxl =max(maxl,(int)s[i].size()-1);}}// Kiểm tra xem với độ dài k thì đã thu được n xâu con phân biệt hay chưa.boolcheck(int k){
map < string,bool> mark;for(int i =1; i <= n;++i){
string st =(mid <=(int)s[i].size()-1)? s[i].substr(1, mid): s[i];if(mark[st])returnfalse;
mark[st]=true;}returntrue;}voidsolve(){// Tìm kiếm nhị phân giá trị k tốt nhất.int l =1, r = maxl +1, res =0;while(l <= r){int mid =(l + r)>>1;if(!check(mid))
l = mid +1;else{
res = mid;
r = mid -1;}}
cout << res;}intmain(){enter();solve();return0;}V. Tài liệu tham khảo
Nguồn: viblo.asia