1. Lời mở đầu
Trong 2 bài review lần trước mình đã giới thiệu về DETR và Deformable DETR. Các tác giả tiếp theo đã đưa ra những cải tiến tích cực cho DETR như: DAB-DETR cải tiến bằng việc đưa ra kiểu query mới học trực tiếp anchor bằng query , hay như DN-DETR cải tiến bằng việc thêm noise để tăng tốc độ huấn luyện mô hình,… DINO đã kế thừa và cải tiến được những kĩ thuật này để cải tiến hiệu năng.
2. Những kỹ thuật áp dụng trong DINO
2.1 Contrastive Denoising (DN)
DN-DETR được đưa ra và rất hiệu quả trong việc làm ổn định quá trình training và tăng tốc hội tụ. Những sample noise được đưa ra trong DN-DETR đều là positive sample, nhưng mô hình cũng cần biết làm sao để phân biệt negative samples. Cụ thể trong DINO hay các mô hình DETR-like sau này sử dụng lên tới 900 query nhưng chỉ có một vài object trong ảnh nên chủ yếu vẫn là negative sample.
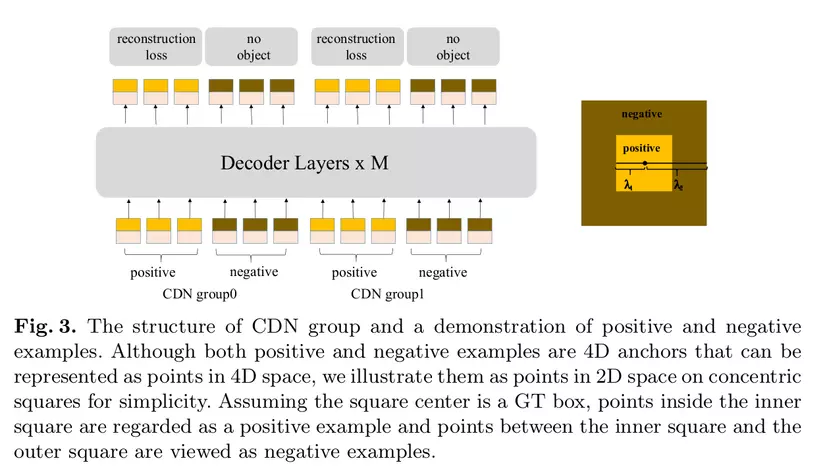
Bởi vậy, nhóm tác giả đã đưa ra một phương pháp huấn luyện mới để xác định negative samples. Như hình trên ta có thể thấy sự cải tiến, không những có positive noise mà còn có cả negative noise. Khi noise được thêm vào nhiều thì coi nó như là 1 negative sample, và nó sẽ được dự đoán là không chứa object khi training. Cùng lúc, khi mà negative sample gần với box thật, nó làm khó mô hình trong việc phân biệt những negative sample khó và làm cho mô hình học cho việc phân biệt giữa positive và negative sample.
2.2 Mix Query Selection
Trong DETR và DN-DETR decoder query là static embeddings và không có bất kì mối liên hệ nào với encoder features được encode từ ảnh. Chúng học anchors (ở DN-DETR và DAB-DETR) hoặc positional queries (ở DETR) trực tiếp từ training data và content query được khởi tạo bằng 0. Deformable DETR học cả positional và content queries, Deformable DETR có một phiên bản cải tiến chọn top K encoder feature từ lớp encoder cuối cùng để làm priors cho decoder queries.
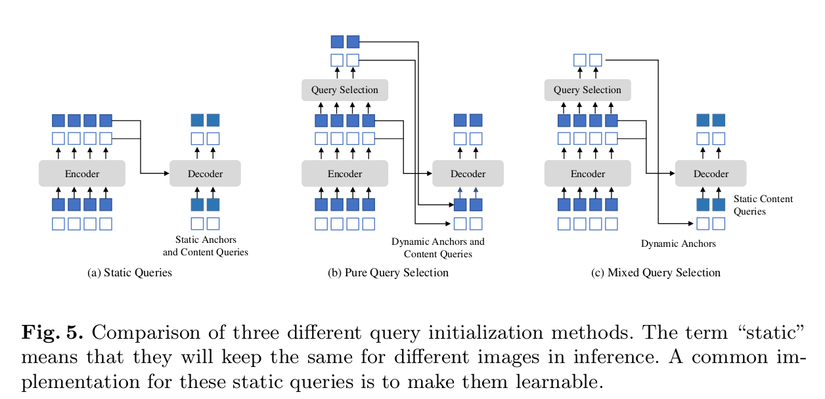
Như hình bên phải trong cùng có thể cho ta thấy là DINO chỉ khởi tạo thông tin position của anchor boxes từ top-K features được chọn và content queries là statics. Tác giả cũng định nghĩa static ở đây nghĩa là nó không thay đổi giữa các ảnh khi inference. Deformable DETR sử dụng top-K feature để refine cả positional queries và content queries trong khi Mix Query Selection chỉ sử dụng top-K feature để refine positional queries và giữ content queries learnable như trước.
2.3 Look forward twice
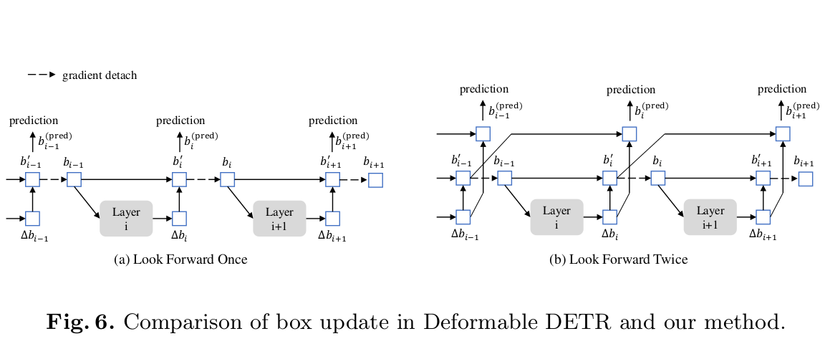
Tác giả đã đưa ra cách đưa ra dự đoán box mới. Interative box refinement ở Deformable DETR ngăn lan truyền ngược để ổn định quá trình huấn luyện. Và cách Deformable DETR thực hiện được nhóm tác giả gọi là “look forward once”. Sở dĩ nó được đặt tên là “look forward once” bởi vì tham số ở layer i chỉ được cập nhật dựa trên loss của box bi. Tuy nhiên tác giả DINO lại nhận ra rằng là những thông tin của box ở phía sau có thể hữu dụng cho việc điều chỉnh box ở phía trước lân cận nó. Vậy nên tác giả đưa ra phương thức cập nhật mới là tham số ở layer i sẽ được cập nhật bởi losses ở cả layer i và layer (i+1).
box dự đoán bi(pred)b_i^{(pred)} được dự đoán bởi 2 thành phần: 1 là box khởi đạo bi−1b_{i-1} và offset ΔbiDelta b_i
3. Kết quả của DINO ấn tượng thế nào
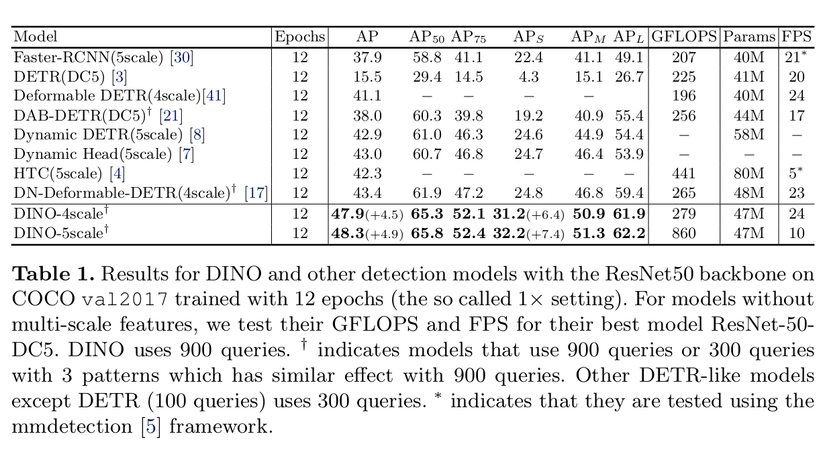
DINO đã cải thiện +4.5 AP so với DN-Deformabled-DETR với cùng settinglaf ResNet-50 với 4-scale featuremap và cải thiện +4.9 AP khi sử dụng 5-scale. Và đặc biệt hiệu quả với những object có kích thước nhỏ +6.4 AP với 4-scale và +7.4 AP với 5-scale.
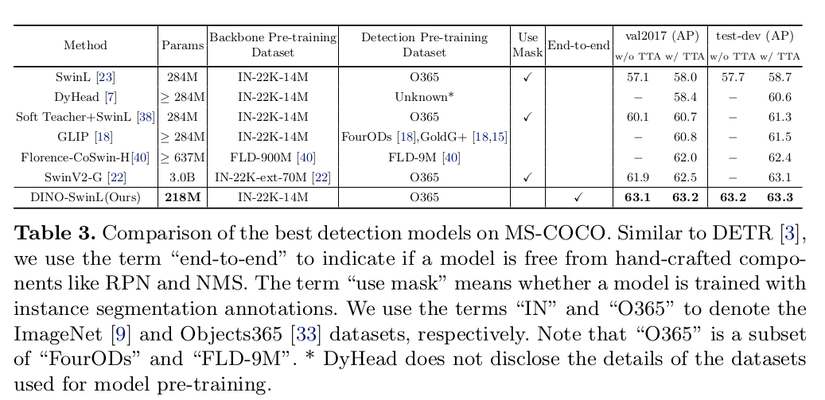
Lần đầu tiên end-to-end Transformer detector đạt SOTA trên leaderboad.
4. Tham khảo
End-to-End Object Detection with Transformers: DETR
Deformable DETR: Deformable Transformers for End-to-End Object Detection
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
Nguồn: viblo.asia