Cơ chế Attention là gì?
Trong lĩnh vực ML, DL, bài toán dịch máy với mạng neural (Neural Machine Translation) chắc hẳn không còn xa lạ gì với mọi người. Ý tưởng đơn giản nhất để giải quyết bài toán này là sử dụng mô hình Sequence to Sequence, với 2 khối encoder và decoder, mỗi khối chỉ sử dụng lớp embedding và mạng hồi tiếp mà thôi. Với mỗi chuỗi nguồn đầu vào input, chúng được mã hóa bởi mạng hồi tiếp trong khối encoder để trở thành 1 trạng thái ẩn, sau đó được truyền đển bộ giải mã để sinh chuỗi đích.
Như vậy, trạng thái ẩn cuối cùng phải tải toàn bộ thông tin của chuỗi nguồn, nhưng 1 token trong chuỗi đích có thể chỉ liên quan đến một vài token trong chuỗi nguồn. Ví dụ: Tiếng Anh chúng ta có chuỗi nguồn “Hello world” và chuỗi đích dịch sang tiếng Việt là “Xin chào thế giời”. “Xin chào” được ánh xạ trực tiếp từ “Hello” và “thế giới” được ánh xạ trực tiếp từ “world”. Mặc dù khối decoder đã phần nào chọn được thông tin tương ứng từ trạng thái ẩn của khối encoder, nhưng có vẻ là chưa đủ. Cơ chế Attention (tập trung) có thể giải quyết vấn đề này 1 cách tốt hơn.
Để hiểu 1 cách chi tiết nhất, mọi người có thể tham khảo bài viết của anh Huy Hoàng với tựa đề [Machine Learning] Attention, Attention, Attention, …!
Cơ chế attention có thể được coi là 1 phép gộp tổng quát, nó gộp các đầu vào dựa trên các hệ số khác nhau. Thành phần quan trọng nhất là tầng attention (attention layer). Đầu vào của tầng này là 1 câu truy vấn (query), nó trả về kết quả dựa trên bộ nhớ là tập các cặp key-value đã được mã hóa
Cụ thể, bộ nhớ tầng tập trung có n cặp key-value. Với mỗi vector truy vấn q, tầng tập trung sẽ trả về đầu ra o

Nonparametric và Parametric
Từ hình ảnh trong phần 1, mình cùng xây dựng công thức tính đầu ra o dựa trên 1 câu truy vấn q và các cặp key-value được lưu trong bộ nhớ.
Cách tính được chia làm 2 loại: Một loại chỉ sử dụng các đầu vào có sẵn và loại còn lại là dùng thêm các hệ số để có thể huấn luyện được. Còn được gọi là Nonparametric (phi tham số) và Parametric (Có tham số).
Nonparametric
Một công thức tính kiểu nonparametric được lên ý tưởng bởi Nadaraya và Watson. Giả sử hàm tính là ff, câu truy vấn là 1 biến xx, các cặp giá trị key-value là xi−yix_i-y_i, công thức như sau:
f(x)=∑i=1nK(x−xi)∑j=1nK(x−xj)yif(x) = sum_{i=1}^{n} {frac {K(x – x_i)} {sum_{j=1}^n K(x – x_j)}}y_i
Với K là 1 kernel. Công thức trên được gọi là hồi quy hạt nhân Nadaraya-Watson.
Viết gọn lại công thức trên như sau:
f(x)=∑i=1nα(x,xi)yif(x) = sum_{i = 1}^n {alpha(x, x_i) y_i}
Với hàm αalpha bất kỳ, chúng ta lại có 1 cách tính attention riêng. Chúng ta cũng gọi hàm αalpha này là 1 hàm tính điểm giữa câu truy vấn q và khóa xi, gọi là Attention Scoring
Ví dụ, với 1 kernel dạng Gaussian, chúng ta có 1 cách tính cụ thể như sau:
f(x)=∑i=1nsoftmax(−12(x−xi)2)yif(x) = sum_{i=1}^n softmax({-frac 1 2 {(x – x_i)} ^2}) y_i
Parametric
Với cách tính nonparametric như trên, đây sẽ là một phương pháp tối ưu khi có bộ dữ liệu một cách ‘đầy đủ’. Tuy nhiên, chúng ta hoàn toàn có thể thêm các đối số để phục vụ việc học.
Đơn giản nhất trong công thức cuối cùng của phần trước, chúng ta chỉ cần thêm 1 đối số ww là có ngay 1 công thức mới:
f(x)=∑i=1nsoftmax(−12((x−xi)w)2)yif(x) = sum_{i=1}^n softmax({-frac 1 2 {((x – x_i)w)} ^2}) y_i
Các hàm tính Attention Scoring
Để dễ theo dõi, mình sẽ giới thiệu qua lần lượt các hàm tính Attention Scoring hay chính là hàm αalpha đi từ kiểu nonparametric đến parametric.
Đầu vào hàm αalpha mình gọi là q thay cho xx và kibold k_i thay cho xix_i
Scaled Dot-Product
Đây là 1 hàm αalpha kiểu nonparametric.
Hàm này giả định câu truy vấn có cùng kích thước chiều với khóa, cụ thể q,ki∈Rdbold {q, k_i} in Bbb R ^ d với mọi ii. Sau đó, lấy tích vô hướng giữa câu truy vấn và khóa sau đó chia cho dsqrt d để làm giảm ảnh hưởng của số chiều dd lên kết quả.
Chính vì thế hàm này còn gọi là nhân tích vô hướng.
α(q,k)=⟨q,k⟩/dalpha(bold {q, k}) = lang bold {q, k} rang / sqrt {d}
Mở rộng lên từ câu truy vấn và khóa 1 chiều, chúng ta có thể tổng quát lên thành các giá trị truy vấn và khóa đa chiều. Giả sử, Q∈Rm×dbold Q in Bbb R ^ {m times d} có mm câu truy vấn và K∈Rn×dbold K in Bbb R ^ {n times d} có nn khóa thì chúng ta có mnmn điểm số được tính như sau:
α(Q,K)=QK⊤/dalpha(bold {Q, K}) = bold {QK^top} / sqrt d
Code ví dụ cho phần này như sau:
class DotProductAttention(nn.Module):
def __init__(self, dropout):
super(DotProductAttention, self).__init__()
self.dropout = nn.Dropout()
def forward(self, queries, keys, values, valid_lens=None):
# queries.shape = (batch_size, n_queries, d)
# keys.shape = (batch_size, n_keys, d)
# values.shape = (batch_size, n_keys, value_size)
# valid_lens.shape = (batch_size, ) or (batch_size, n_queries)
d = queries.shape[-1]
scores = torch.bmm(queries, keys.transpose(1, 2)) / math.sqrt(d)
# scores.shape = (batch_size, n_queries, n_keys)
self.alpha_func = masked_softmax(scores, valid_lens) # shape as shape of scores
return torch.bmm(self.dropout(self.alpha_func), values)
# shape = (batch_size, n_queries, value_size)
queries = torch.normal(0, 1, (2, 1, 2))
keys = torch.ones((2, 10, 2))
values = torch.arange(40, dtype=torch.float32).reshape(1, 10, 4).repeat(2, 1, 1)
valid_lens = torch.Tensor([2, 6])
attention = DotProductAttention(dropout=0.5)
attention.eval()
attention(queries, keys, values, valid_lens)
Nói qua 1 chút về cách tính hàm softmax trong công thức trên. Toán tử softmax trong công thức nhận đầu vào là 1 tensor 3 chiều. Tensor này là 1 sequence đã mã hóa và trong đó có 1 số token ở cuối làm nhiều vụ padding cho sequence đó, tức là các token dạng này sẽ bị loại bỏ do không có ý nghĩa. Chính vì thế phải có thêm 1 tensor gọi là valid_lens để xác định chiều dài các token mang ý nghĩa.
Mình có thêm 1 hàm mask_softmax để làm nhiệm vụ này:
def masked_softmax(X, valid_lens):
# X is tensor 3D
if valid_lens is None:
return F.softmax(X, dim=-1)
else:
mask = torch.zeros_like(X)
if valid_lens.dim() == 1:
for i, valid_len in enumerate(valid_lens.long()):
mask[i][:, :valid_len] = X[i][:, :valid_len]
elif valid_lens.dim() == 2:
for i in range(valid_lens.shape[0]):
for j, valid_len in enumerate(valid_lens[i].long()):
mask[i, j][:valid_len] = X[i, j][:valid_len]
return F.softmax(mask, dim=-1)
Multilayer perceptron (MLP)
Đây là 1 hàm αalpha kiểu parametric
Hàm này đơn giản là thêm các trọng số để học gồm:
- Wq∈h×dqbold W_q in Bbb {h times d_q} tương ứng với câu truy vấn qbold q
- Wk∈h×dkbold W_k in Bbb {h times d_k} tương ứng với khóa kbold k
- Wv∈1×hbold W_v in Bbb {1 times h}

Chúng ta có công thức hàm αalpha như sau:
α(k,q)=Wv tanh(Wkk+Wqq)alpha (bold {k, q}) = bold W_v space tanh(bold W_k bold k + bold W_q bold q)
Code ví dụ cho phần này như sau:
class MLPAttention(nn.Module):
def __init__(self, key_size, query_size, num_hiddens, dropout):
super(AdditiveAttention, self).__init__()
self.W_k = nn.Linear(key_size, num_hiddens, bias=False)
self.W_q = nn.Linear(query_size, num_hiddens, bias=False)
self.w_v = nn.Linear(num_hiddens, 1, bias=False)
self.dropout = nn.Dropout(p=dropout)
def forward(self, queries, keys, values, valid_lens):
# queries.shape = (batch_size, n_queries, query_size)
# keys.shape = (batch_size, n_keys, key_size)
# values.shape = (batch_size, n_keys, value_size)
# valid_lens.shape = (batch_size, )
queries, keys = self.W_q(queries), self.W_k(keys)
features = queries.unsqueeze(2) + keys.unsqueeze(1)
scores = self.w_v(features).squeeze(-1)
self.alpha_func = masked_softmax(scores, valid_lens=valid_lens)
return torch.bmm(self.dropout(self.alpha_func), values)
# shape = (batch_size, n_queries, value_size)
queries = torch.normal(0, 1, (2, 1, 20))
keys = torch.ones((2, 10, 2))
values = torch.arange(40, dtype=torch.float32).reshape(1, 10, 4).repeat(2, 1, 1)
valid_lens = torch.Tensor([2, 6])
attention = MLPAttention(key_size=2, query_size=20, num_hiddens=8, dropout=0.1)
attention.eval()
attention(queries, keys, values, valid_lens)
Multi-Head
Đây cũng là 1 hàm αalpha dạng parametric
Trên thực tế, với cùng 1 tập các câu truy vấn và các cặp key-value, có thể chúng ta muốn mô hình kết hợp các kiến thức từ các hành vi khác nhau trong cùng 1 đầu vào như trên.
Thay vì chỉ sử dụng 1 không gian n×dqn times d_q để biểu diễn qbold q và n×dkn times d_k để biểu diễn kbold k, thì ta có thể tách các không gian biểu diễn trên thành các không gian nhỏ hơn và thực hiện các hành vi trên mỗi không gian đó.
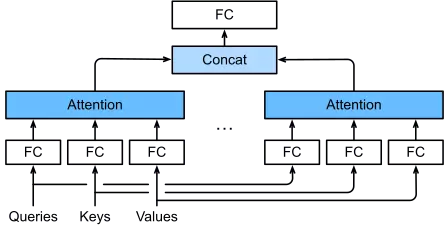
Tách không gian biểu diễn q,k,vbold {q, k, v} thành các không gian con, mỗi không gian này được gọi là 1 head. Trên mỗi head chúng ta thực hiện cơ chế attention trên bộ q,k,vbold {q, k, v} tương ứng. Sau khi có kết quả ở mỗi head, chúng ta tiến hành nối chúng lại và đưa qua 1 lớp fully connected.
Công thức tổng quát như sau:
hi=f(Wqiq,Wkik,Wviv)h_i = f(bold {W_q^i q}, bold {W_k^i k}, bold {W_v^i v})
Ở đây, việc chia thành các không gian con với các đối số Wbold W đều được học. ff là 1 hàm tính attention như các phần bên trên và thông thường sẽ sử dụng hàm αalpha là Scaled dot product. hih_i là kết quả tính attention trên mỗi head, chúng sẽ được nối lại và đưa qua 1 lớp fully connected để thu được kết quả.
Code ví dụ cho phần này:
def transpose_qkv(X, num_heads):
X = X.reshape(X.shape[0] * num_heads, X.shape[1], int(X.shape[2] / num_heads))
# X.shape = (batch_size * num_heads, n, X_size / num_heads)
return X
def transpose_output(X, num_heads):
X = X.reshape(int(X.shape[0] / num_heads), X.shape[1], X.shape[2] * num_heads)
# X.shape = (batch_size / num_heads, n, X_size * num_heads)
return X
class MultiHeadAttention(nn.Module):
def __init__(self, key_size, query_size, value_size,
num_hiddens, num_heads, dropout, bias=False, **kwargs):
super(MultiHeadAttention, self).__init__(**kwargs)
self.num_heads = num_heads
self.attention = DotProductAttention(dropout)
self.W_q = nn.Linear(query_size, num_hiddens, bias=bias)
self.W_k = nn.Linear(key_size, num_hiddens, bias=bias)
self.W_v = nn.Linear(value_size, num_hiddens, bias=bias)
self.W_o = nn.Linear(num_hiddens, num_hiddens, bias=bias)
def forward(self, queries, keys, values, valid_lens):
# queries.shape = (batch_size, n_queries, query_size)
# keys.shape = (batch_size, n_keys, key_size)
# values.shape = (batch_size, n_keys, value_size)
# valid_lens.shape = (batch_size, ) or (batch_size, n_queries)
queries = transpose_qkv(self.W_q(queries), self.num_heads)
keys = transpose_qkv(self.W_k(keys), self.num_heads)
values = transpose_qkv(self.W_v(values), self.num_heads)
if valid_lens is not None:
valid_lens = valid_lens.repeat_interleave(repeats=self.num_heads, dim=0)
output = self.attention(queries, keys, values, valid_lens)
output_concat = transpose_output(output, self.num_heads)
return self.W_o(output_concat)
# shape = (batch_size, n_queries, num_hiddens)
batch_size, n_queries, n_keys, valid_lens = 2, 4, 6, torch.Tensor([3, 2])
num_hiddens, num_heads = 100, 5
queries = torch.rand(batch_size, n_queries, num_hiddens)
keys = torch.rand(batch_size, n_keys, num_hiddens)
values = torch.rand(batch_size, n_keys, num_hiddens)
attention = MultiHeadAttention(key_size=num_hiddens, query_size=num_hiddens,
value_size=num_hiddens, num_hiddens=num_hiddens,
num_heads=num_heads, dropout=0.5)
attention(queries, keys, values, valid_lens)
Kết thúc
- Trên này là khái niệm về attention và 1 số cách tính Attention Scoring mà mình đã trình bày
- Attention là 1 lớp nhỏ được sử dụng trong mô hình lớn.
- Một số mô hình sử dụng cơ chế attention như:
- Bahdanau Attention: Là 1 mô hình sequence to sequence đơn giản và kết hợp sử dụng cơ chế attention
- Transformer: Mô hình vận dụng chủ yếu cơ chế attention.
- Sử dụng cơ chế attention thường cho kết quả tốt hơn so với không sử dụng chúng.
Tài liệu tham khảo
Nguồn: viblo.asia